Tesseract OCR 安装尝试
1、简介
Tesseract是一个图像识别项目,将图中的文字识别出来。将一个.jpg .png 等等 的图片作为输入,.txt作为识别内容输出
2、环境
windows 10,Tesseract 4.1.0
3、安装
你可以通过项目github地址下载源码然后进行编译,也可以通过下载二进制安装包进行安装(下面介绍)
安装包下载地址
官方下载 但总是被禁
我的百度网盘
链接:https://pan.baidu.com/s/1ZHcKZd3eAELbQIY3wKS93w
提取码:1qrw
1、下载后打开安装包

到

选择自己需要的语言,英语是默认就带的,我选了中文的 Chinese(Simplified)
继续无脑下一步安装,如果无法下载语言包,
可以自行下载语言包 语言包
可以在我的网盘中下载

将这些语言包放在安装后的Tesseract-OCR\tessdata 文件夹下 (我的地址 E:\Program Files\Tesseract-OCR\tessdata)
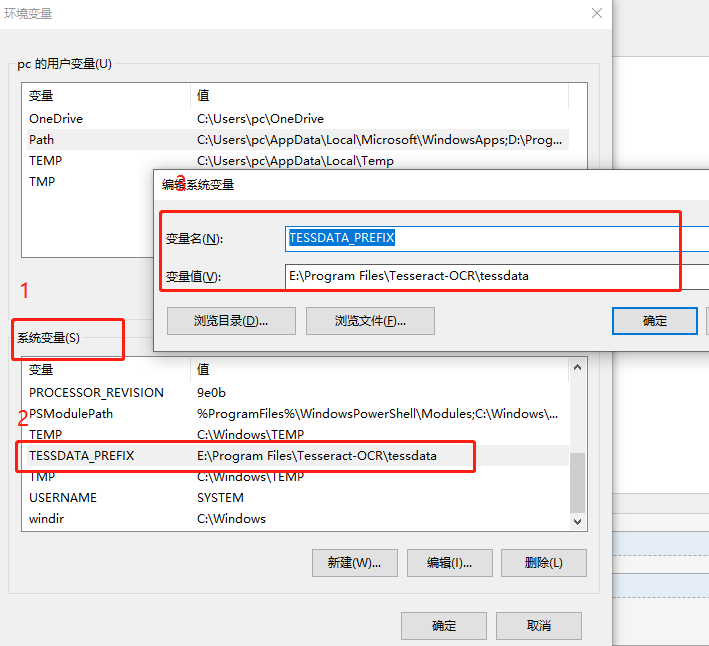
2、需要设置一下环境变量
在环境变量Path中,添加Tesseract的路径

在环境变量中配置一下语言包的路径 TESSDATA_PREFIX E:\Program Files\Tesseract-OCR\tessdata
3、尝试
打开cmd命令行
tesseract -help

证明环境变量配置成功
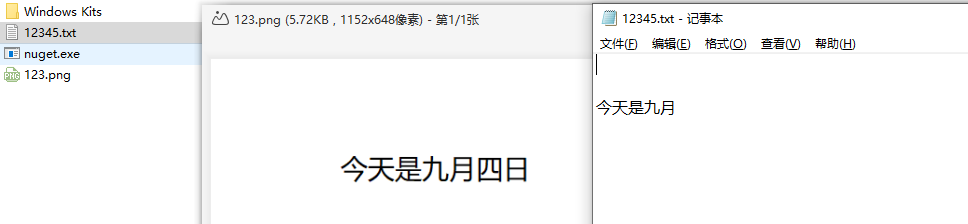
这时找一个图片

将其保存在D:\下叫123.png
cmd运行
tesseract d:\123.png d:\12345 -l chi_sim
tesseract [图片地址] [输出文字地址] -l [语言包]