计算机组成原理--数据表示2
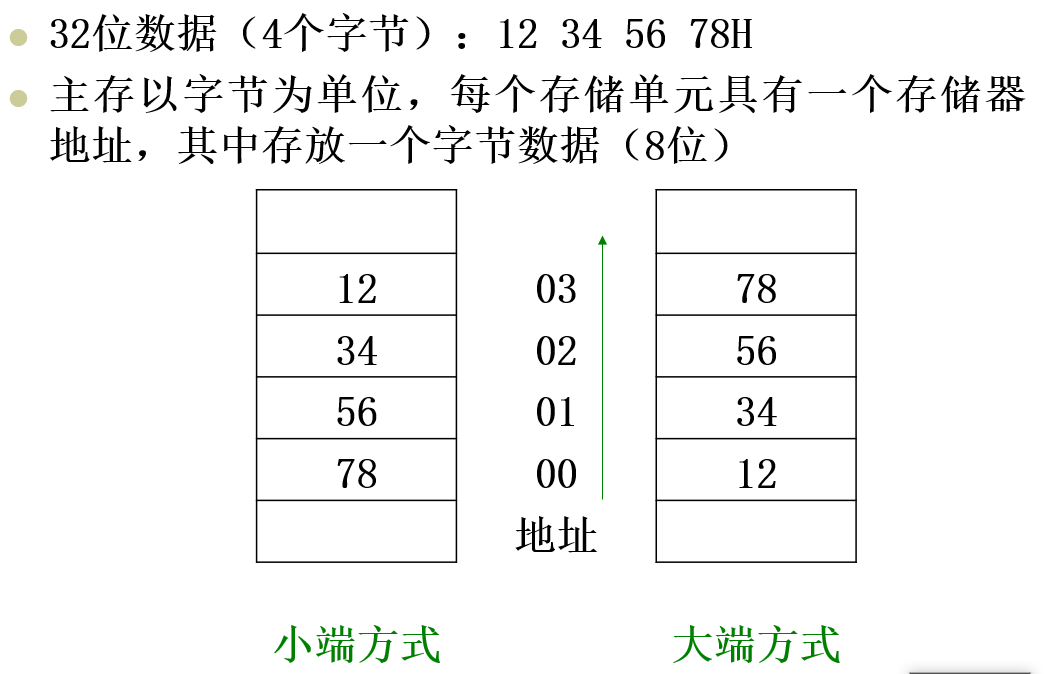
小端方式与大端方式
1) 大端模式(Big-endian)是指将数据的低位(比如 1234 中的 34 就是低位)放在内存的高地址上,而数据的高位(比如 1234 中的 12 就是高位)放在内存的低地址上。这种存储模式有点儿类似于把数据当作字符串顺序处理,地址由小到大增加,而数据从高位往低位存放。
2) 小端模式(Little-endian)是指将数据的低位放在内存的低地址上,而数据的高位放在内存的高地址上。这种存储模式将地址的高低和数据的大小结合起来,高地址存放数值较大的部分,低地址存放数值较小的部分,这和我们的思维习惯是一致,比较容易理解。
数据校验
基本原理:增加冗余码
码距:合法编码之间不同二进制位数的最小值
例如:
0011
0001的码距为1,一位错误时无法识别
码距与检错、纠错能力:
- 码距 d>=e+1:检查e个错误
- 码距 d>=2t+1:纠正t个错误
- 码距 d>=e+t+1:同时检查e个错误,并纠正t个错误。(e>=t)
PS:这里说下我的理解,增加码距就是增加非法编码的数量,看到非法编码就算检查出错误了,而非法编码距离哪个合法编码比较近就认为正确的应该是什么(简单理解,可参考下面的图),也就是可以纠正错误
这里看到过一个好的几何理解图,仔细品味下:
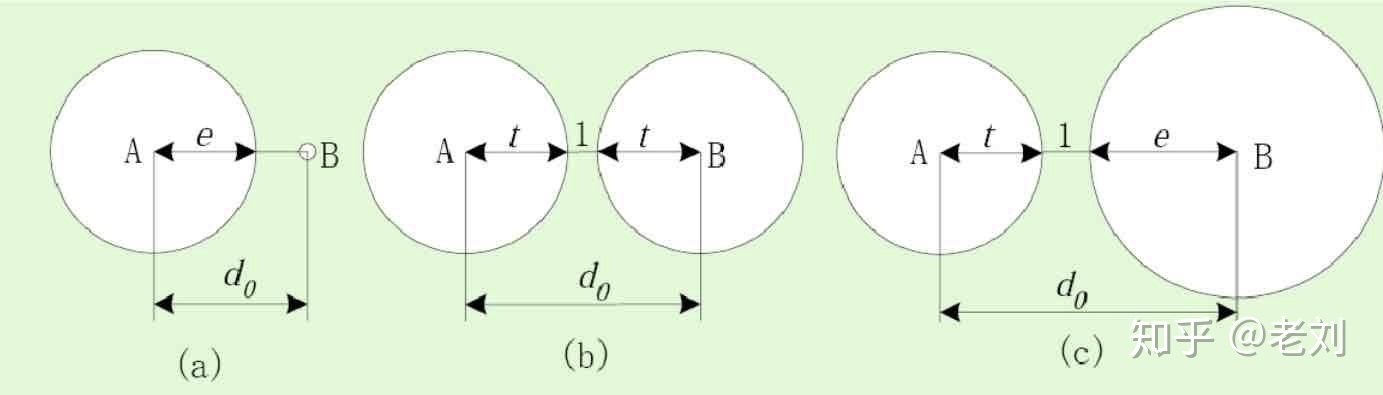
举个例子:比如一共有8位,码距为1则检查不出任何错误,因为所有编码都是合法编码。如果码距为2,那合法编码应该像 00000000,00000011,00001100,00001111这样,那如果出现00000001这样的非法编码就出错了,可检查一位错,但如果两位同时错了,则有可能又跳到另一个合法编码上了,就检查不出2位错。
那如果码距是3,那合法编码应该像 00000000,00000111,00111000,00111111 这样,那如果出现一位错 00000001,或者两位错00000011,都是非法编码,都能检查出错误,并且此时可以纠正00000001为00000000,纠正00000011为00000111。但是三位同时错就检查不出了。
常见校验策略:奇偶校验,CRC校验,海明校验
ps:海明编码最强视频演示教程:https://www.youtube.com/watch?v=373FUw-2U2k
奇偶校验:https://www.youtube.com/watch?v=bq9JHjSfnJI
奇偶校验码浅谈
见链接:https://www.cnblogs.com/dushikang/p/8334776.html
十进制数串
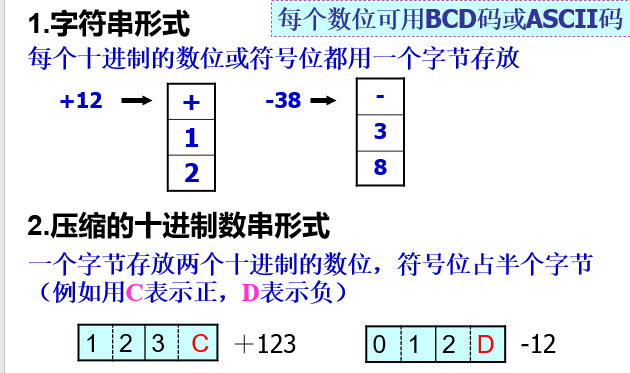
引用:https://blog.csdn.net/qq_43511405/article/details/105890427
BCD码

BCD码分类
(1)BCD码分为有权和无权两类:
- 有权BCD码:8421码,2421码,5421码,...
- 无权BCD码:余3码,格雷码,...
其中,8421码是最常用的有权BCD码。
(2)BCD码又可分为压缩式和非压缩式两类。
8421码
|
十进制数 |
8421码
|
|
0 |
0000 |
|
1 |
0001 |
|
2 |
0010 |
|
3 |
0011 |
|
4 |
0100 |
|
5 |
0101 |
|
6 |
0110 |
|
7 |
0111 |
|
8 |
1000 |
|
9 |
1001 |
其他较常用的BCD码
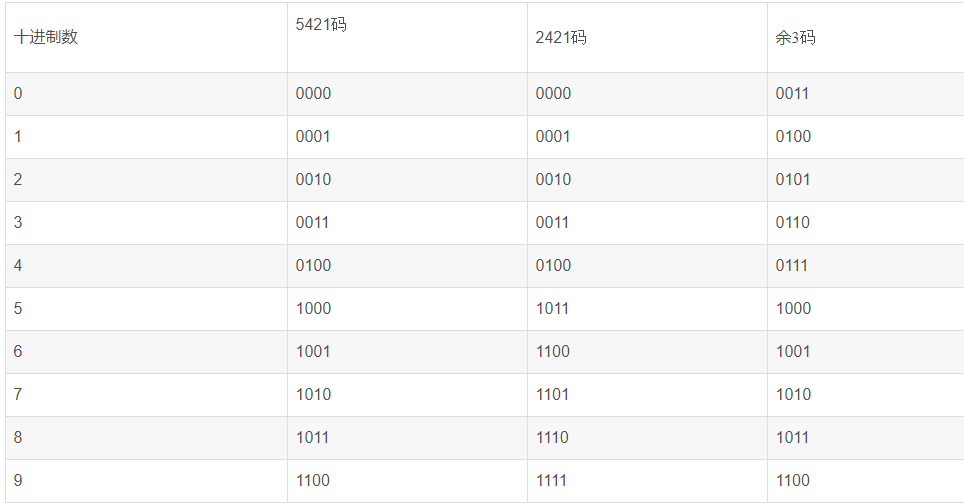
各种BCD码的特点
8421码编码直观,易于理解,最常用
5421码和2421码中大于5的数字都是高位为1,5以下的高位为0
余3码是在8421码基础上加上3,有上溢出和下溢出的空间
BCD码举例
以8421码为例。
(1)十进制数:123
对应的8421码为:0001 0010 0011
(2)8421码:0011 0010 0001
对应的十进制数为:321
8421码的进位
因为8421码中的9为1001,10为0001 0000,可见8421码遇见1001就产生进位。而普通的二进制码,到1111才产生进位10000。
引用:https://blog.csdn.net/yl2isoft/article/details/16916889
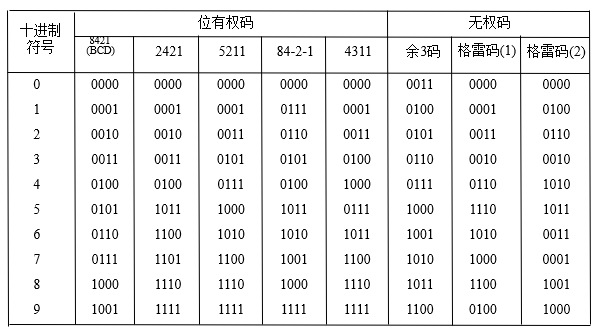
有权码 无权码
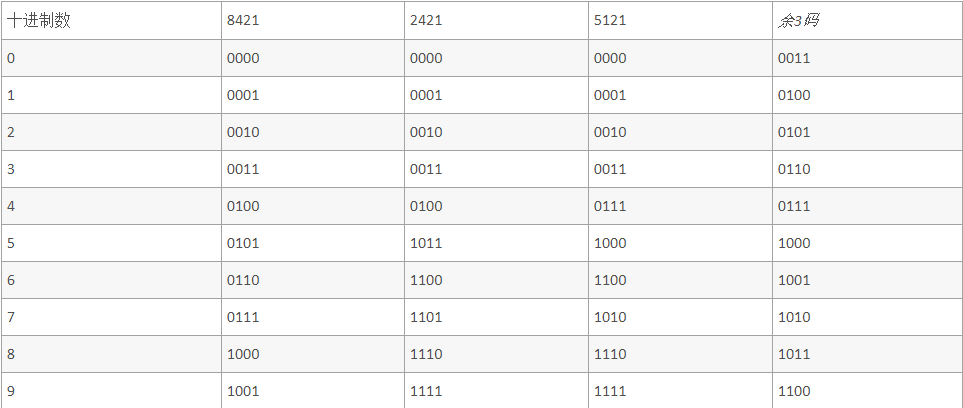
注:有权码,8421,2424,5121,取反对称方式编码
无权码,余3码,在8421上加0011
格雷码

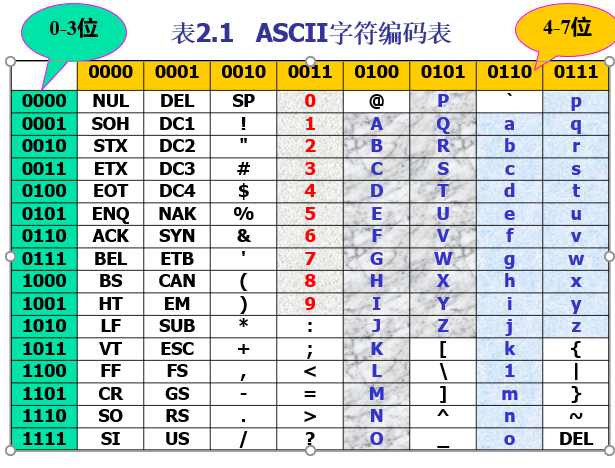
ASCII码

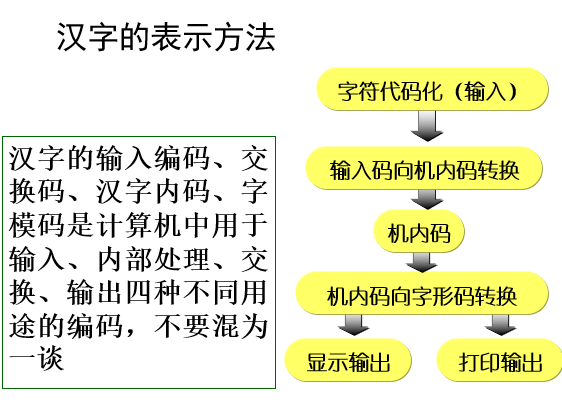
汉字的输入编码

汉字交换码

汉字内码

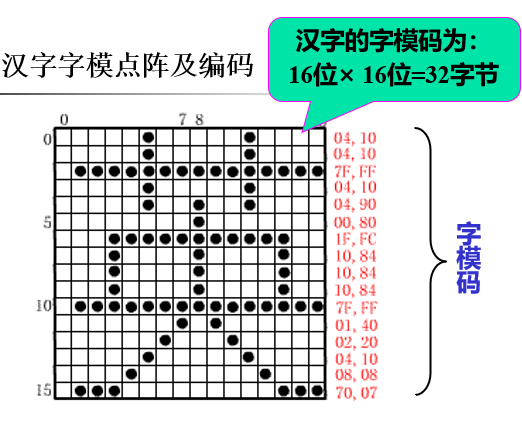
汉字字模点阵及编码
BCD码分类
(1)BCD码分为有权和无权两类:
- 有权BCD码:8421码,2421码,5421码,...
- 无权BCD码:余3码,格雷码,...
其中,8421码是最常用的有权BCD码。
(2)BCD码又可分为压缩式和非压缩式两类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号