
【每周小项目】使用 puppeteer 插件爬取动态网站
0. 前言
这两天对爬虫开始感兴趣,最开始是源于天涯的一个房价神贴,盖了上万层,追着读了好久。天涯网页端的“只看楼主”需要会员,手机端可以“只看楼主”,但是体验不太好,记录也不方便,于是决定把楼主发言单独爬下来,既可以保存,也可以检索。
最开始想法很简单,对每一页进行元素检索,发帖人与楼主名字匹配的,就把里面的content拷出来。
首先在网上找到的工具是cheerio插件,它在读取网站之后,将网站内容存下来,通过元素选择器进行内容选取。在使用递归后,还能解决翻页问题。
事实上也确实如此,通过简单几步操作,就把楼主的发言保存了下来,也让我对爬虫产生了兴趣。
问题
cheerio确实简单好用,在应对简单静态网页时没有问题。但对付具备一定反爬机制的网站就无能为力了。比如cheerio解决翻页问题,靠的是动态修改url链接。但是有的网站,比如我最爱的煎蛋,它的网页链接页码是乱码,就没办法实现自动翻页。再比如有的房产网站,在罗列在售资源时,为了用户体验,使用了懒加载,只有将页面滚动到底部后,才能触发加载。
以上种种实际上就是cheerio对于网页操作是无能为力的。
解决
在网上查找对付懒加载的方法时,发现了puppeteer插件。谷歌浏览器在17年自行开发了Chrome Headless特性,并与之同时推出了puppeteer,本质上就是一个不含界面的浏览器,有点像电脑的终端,所有操作都通过代码进行操作。
这样,我们就可以在对网站进行检索之前,操作指定元素滚动到底部,以触发更多信息。或者在需要翻页的时候,操作代码对翻页按钮进行点击,然后对翻页后的页面进行相关处理。
1. 下载与引包
// 下载
npm i puppeteer
// 引包
const puppeteer = require('puppeteer')
2. 使用步骤
// 将整个操作放置在一个闭包的异步函数中,以便于进行异步操作
(async () => {
// 1. 使用puppetee插件启动一个浏览器,并开启一个新页面
const brower = await puppeteer.launch({
args: ['--no-sandbox'],
dumpio: false,
headless:false, // 默认为true,设为false时,可以显示可视化浏览器界面
})
const page = await brower.newPage() // 开启一个新页面
// 2. 打开指定网页
await page.goto('http://jandan.net/ooxx', {
waitUntil: 'networkidle2' // 网络空闲说明已加载完毕
});
// 3. 对动态网站进行自动化操作,这一步是其精髓所在
// 由于我们监控的是动态网页,刚打开网页时,所需元素也许还未出现,所以需要进行监听,例如“下一页按钮”
await page.waitForSelector('a.previous-comment-page'); // 括号内是元素选择器
// 当下一页按钮出现时,模拟点击
await page.click('a.previous-comment-page')
// 4. 这时我们可以执行爬取我们需要的数据了,我们可以去审查页面的dom结果,来循环遍历这些数据。
// page.evaluate() 为在浏览器中执行函数,相当于在控制台中执行函数,返回一个 Promise
const result = await page.evaluate(() => {
// 拿到页面上的jQuery
var $ = window.$;
// 在这里进行熟悉的 DOM 操作
// Do something
});
// 5. 关闭浏览器,在console里面打印我们需要的数据
brower.close();
// 6. 对结果进行处理
console.log(result);
})();
3. 爬过的几个坑
page.evaluate 的传参问题
因为打开的这个 page 只是一个木偶,并不是真正的浏览器页面,所以在这个页面上的操作与一般页面上的操作有差异。
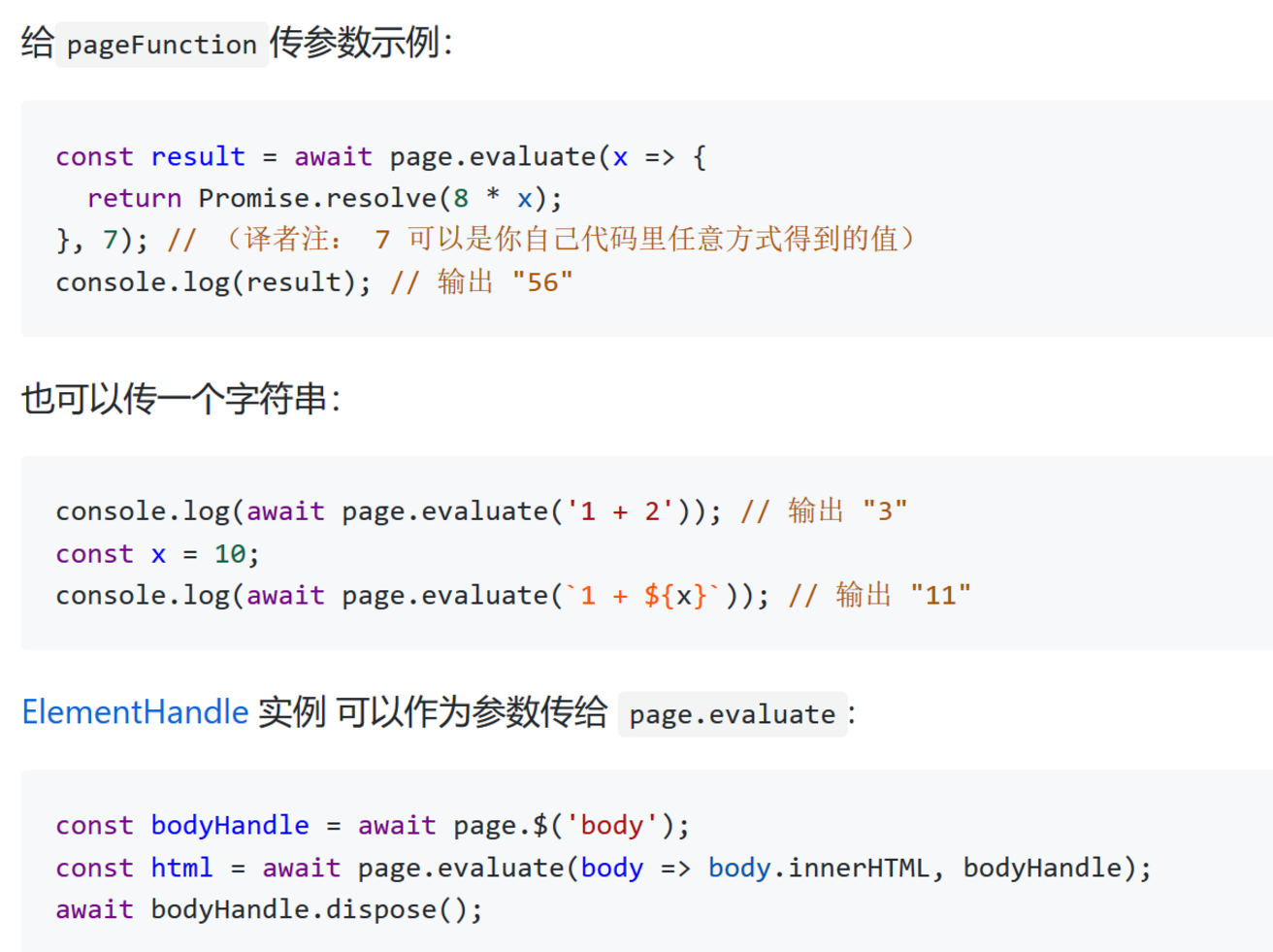
官方文档里说,这个参数是这样的。在实际使用中,可以传一个字符串变量,但是到更复杂一点的,比如‘fs’,自定义外部函数时,都无法读取。
这也是我建议在第6步,对页面操作完成后,统一对结果进行处理。(主要是因为我没有解决这个问题,所以认怂绕开走了……)
元素操作问题
puppeteer中,最重要的函数执行和要素选择都与一般浏览器上操作有些区别,这里有些坑要爬,现在我也说不清楚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号