吴恩达深度学习 第四课第二周编程作业_Residual Networks
Residual Networks
参考:https://blog.csdn.net/u013733326/article/details/80250818
欢迎来到本周的第二次作业!您将学习如何使用剩余网络(ResNets)构建非常深的卷积网络。理论上,深度很深的网络可以代表非常复杂的功能;但实际上,他们很难训练。剩余网络,由He等人介绍,允许你训练更深层次的网络比以前实际可行。
在这个作业中,你将:
实现resnet的基本构建块。
把这些构建块放在一起来实现和训练一个最先进的图像分类神经网络。
这项任务将在Keras中完成。
在开始这个问题之前,让我们运行下面的单元来加载所需的包。
import numpy as np from keras import layers from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D from keras.models import Model, load_model from keras.preprocessing import image from keras.utils import layer_utils from keras.utils.data_utils import get_file from keras.applications.imagenet_utils import preprocess_input import pydot from IPython.display import SVG from keras.utils.vis_utils import model_to_dot from keras.utils import plot_model from resnets_utils import * from keras.initializers import glorot_uniform import scipy.misc from matplotlib.pyplot import imshow %matplotlib inline import os os.environ['KERAS_BACKEND'] = 'tensorflow' import keras.backend as K K.set_image_data_format('channels_last') K.set_learning_phase(1)
1 - The problem of very deep neural networks深层网络的麻烦
上周,我们构建了第一个卷积神经网络。最近几年,卷积神经网络变得越来越深,从只从几层(例如AlexNet)到超过一百层。
使用深层网络最大的好处就是它能够完成很复杂的功能,它能够从边缘(浅层)到非常复杂的特征(深层)中不同的抽象层次的特征中学习。然而,使用比较深的网络通常没有什么好处,一个特别大的麻烦就在于训练的时候会产生梯度消失,非常深的网络通常会有一个梯度信号,该信号会迅速的消退,从而使得梯度下降变得非常缓慢。更具体的说,在梯度下降的过程中,当你从最后一层回到第一层的时候,你在每个步骤上乘以权重矩阵,因此梯度值可以迅速的指数式地减少到0(在极少数的情况下会迅速增长,造成梯度爆炸)。
在训练的过程中,你可能会看到开始几层的梯度的大小(或范数)迅速下降到0,如下图:

**Figure 1** : **Vanishing gradient**梯度消失
在前几层中随着迭代次数的增加,学习的速度会下降的非常快。
为了解决这个问题,我们将构建残差网络。
2 - Building a Residual Network 构建一个残差网络
在残差网络中,一个“捷径(shortcut)”或者说“跳跃连接(skip connection)”允许梯度直接反向传播到更浅的层,如下图:

**Figure 2** : A ResNet block showing a **skip-connection**
图像左边是神经网络的主路,图像右边是添加了一条捷径的主路,通过这些残差块堆叠在一起,可以形成一个非常深的网络。
我们在视频中可以看到使用捷径的方式使得每一个残差块能够很容易学习到恒等式功能,这意味着我们可以添加很多的残差块而不会损害训练集的表现。
残差块有两种类型,主要取决于输入输出的维度是否相同,下面我们来看看吧~
2.1 - The identity block 恒等块
恒等块是残差网络使用的的标准块,对应于输入的激活值(比如𝑎[𝑙])与输出激活值(比如𝑎[𝑙+ 2])具有相同的维度。为了具象化残差块的不同步骤,我们来看看下面的图吧~,这里有一个替代的图表显示各个步骤:

**Figure 3** : **Identity block.** Skip connection "skips over" 2 layers.
上图中,上面的曲线路径是“捷径”,下面的直线路径是主路径。在上图中,我们依旧把CONV2D 与 ReLU包含到了每个步骤中,为了提升训练的速度,我们在每一步也把数据进行了归一化(BatchNorm),不要害怕这些东西,因为Keras框架已经实现了这些东西,调用BatchNorm只需要一行代码。 在实践中,我们要做一个更强大的版本:跳跃连接会跳过3个隐藏层而不是两个,就像下图:

**Figure 4** : **Identity block.** Skip connection "skips over" 3 layers.
下面是单独的步骤。
主路径第一部分:
1、第一CONV2D有𝐹1个过滤器,大小为(1, 1),步长为(1, 1)。它的填充方式是“valid”,命名规则是 conv_name_base + '2a'。使用0作为随机初始化的种子。
2、第一个BatchNorm是对channels(通道)的轴进行规范化、归一化。其命名规则为 bn_name_base + '2a'。
3、然后应用ReLU激活函数。它没有命名和超参数。
主路径第二分部分:
1、第二个CONV2D有𝐹2个过滤器,大小为(𝑓,𝑓)和(1,1)的步伐。它的填充方式是“same”,它的命名规则是 conv_name_base + '2b'。使用0作为随机初始化的种子。
2、第二个BatchNorm是通道的轴归一化。它的命名规则为 bn_name_base + '2b'。
3、然后应用ReLU激活函数。它没有名称和超参数。
主路径第三分量:
1、第三CONV2D有𝐹3个过滤器,形状大小为(1,1)和(1,1)的步伐。它的填充方式是“valid”,它的命名方式是 conv_name_base + '2c'。使用0作为随机初始化的种子。
2、第三个BatchNorm是通道的轴归一化。它的名称应该是bn_name_base + '2c'
3、注意,该组件中没有ReLU激活函数。
最后一步:
1、将捷径与输入加在一起
2、然后应用ReLU激活函数。它没有命名和超参数。
接下来我们就要实现残差网络的恒等块了,请务必查看下面的中文手册:


1 # GRADED FUNCTION: identity_block 2 3 def identity_block(X, f, filters, stage, block): 4 """ 5 Implementation of the identity block as defined in Figure 3 实现图3的恒等块 6 7 Arguments: 8 X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev) 输入的tensor类型的数据,维度为( m, n_H_prev, n_W_prev, n_H_prev ) 9 f -- integer, specifying the shape of the middle CONV's window for the main path 整数,指定主路径中间的CONV窗口的维度 10 filters -- python list of integers, defining the number of filters in the CONV layers of the main path 11 整数列表,定义了主路径每层的卷积层的过滤器数量 12 13 stage -- integer, used to name the layers, depending on their position in the network 14 整数,根据每层的位置来命名每一层,与block参数一起使用。 15 block -- string/character, used to name the layers, depending on their position in the network 16 字符串,据每层的位置来命名每一层,与stage参数一起使用。 17 18 Returns: 19 X -- output of the identity block, tensor of shape (n_H, n_W, n_C) 恒等块的输出,tensor类型,维度为(n_H, n_W, n_C) 20 """ 21 22 # defining name basis 定义命名规则 23 conv_name_base = 'res' + str(stage) + block + '_branch' 24 bn_name_base = 'bn' + str(stage) + block + '_branch' 25 26 # Retrieve Filters 获取过滤器 27 F1, F2, F3 = filters 28 29 # Save the input value. You'll need this later to add back to the main path. 保存输入数据,将会用于为主路径添加捷径 30 X_shortcut = X 31 32 # First component of main path 主路径的第一部分 33 ##卷积层 34 X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X) 35 #归一化 36 X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X) 37 #使用relu激活函数 38 X = Activation('relu')(X) 39 40 ### START CODE HERE ### 41 42 # Second component of main path (≈3 lines)主路径的第二部分 43 X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1, 1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed = 0))(X) 44 X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X) 45 X = Activation('relu')(X) 46 47 # Third component of main path (≈2 lines) 48 X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1, 1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X) 49 50 X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X) 51 52 # Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)最后一步,将捷径与输入加在一起 53 X = layers.add([X, X_shortcut]) 54 X = Activation('relu')(X) 55 56 ### END CODE HERE ### 57 58 return X
# tf.reset_default_graph() ops.reset_default_graph with tf.compat.v1.Session() as test: np.random.seed(1) A_prev = tf.compat.v1.placeholder("float", [3, 4, 4, 6]) X = np.random.randn(3, 4, 4, 6) A = identity_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a') test.run(tf.compat.v1.global_variables_initializer()) out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0}) print("out = " + str(out[0][1][1][0])) test.close()
执行结果:

2.2 - The convolutional block 卷积块
我们已经实现了残差网络的恒等块,现在,残差网络的卷积块是另一种类型的残差块,它适用于输入输出的维度不一致的情况,它不同于上面的恒等块,与之区别在于,捷径中有一个CONV2D层,如下图:

**Figure 4** : **Convolutional block**卷积块
捷径中的卷积层将把输入 X 卷积为不同的维度,因此在主路径最后那里需要适配捷径中的维度。比如:把激活值中的宽高减少2倍,我们可以使用1x1的卷积,步伐为2。捷径上的卷积层不使用任何非线性激活函数,它的主要作用是仅仅应用(学习后的)线性函数来减少输入的维度,以便在后面的加法步骤中的维度相匹配。
具体步骤如下:
1、主路径第一部分:
1、第一个卷积层有 F1 个过滤器,其维度为(1, 1),步幅为(s,s),使用 ‘valid’ 的填充方式,命名规则为conv_name_base + '2a'
2、第一个规范层是通道的轴归一化,其命名规则为:bn_name_base + '2a'
3、使用ReLU激活函数,它没有命名规则也没有超参数。
2、主路径的第二部分:
1、第二个卷积层有 F2 个过滤器,其维度为(f,f),步幅为(1, 1),使用‘same’ 的填充方式,命名规则为conv_name_base +'2b'
2、第二个规范层是通道的轴归一化,其命名规则为:bn_name_base + '2b'
3、使用ReLU激活函数,它没有命名规则也没有超参数。
3、主路径的第三部分
1、第三个卷积层有 F3 个过滤器,其维度为(1, 1),步幅为(s,s),使用‘valid’ 的填充方式,命名规则为:conv_name_base + '2c'
2、第三个规范层是通道的轴归一化,命名规则为:bn_name_base + '2c'
3、没有激活函数
4、捷径:
1、此卷积层有 F3 个过滤器,其维度为(1,1),步幅为(s,s),使用‘valid’ 的填充方式,命名规则为:conv_name_base + '1'
2、此规范层是通道的轴归一化,命名规则为:bn_name_base + '1'
5、最后一步:
1、将捷径与输入加在一起
2、使用ReLU激活函数
我们要做的是实现卷积块,请务必查看下面的中文手册:
Keras kernel_initializer 权重初始化的方法
1 # GRADED FUNCTION: convolutional_block 2 3 def convolutional_block(X, f, filters, stage, block, s = 2): 4 """ 5 Implementation of the convolutional block as defined in Figure 4 实现图4的卷积块 6 7 Arguments: 8 X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev) 输入的tensor类型的变量,维度为( m, n_H_prev, n_W_prev, n_C_prev) 9 f -- integer, specifying the shape of the middle CONV's window for the main path 整数,指定主路径中间的CONV窗口的维度 10 filters -- python list of integers, defining the number of filters in the CONV layers of the main path 11 整数列表,定义了主路径每层的卷积层的过滤器数量 12 13 stage -- integer, used to name the layers, depending on their position in the network 14 整数,根据每层的位置来命名每一层,与block参数一起使用。 15 block -- string/character, used to name the layers, depending on their position in the network 16 字符串,据每层的位置来命名每一层,与stage参数一起使用。 17 s -- Integer, specifying the stride to be used 整数,指定要使用的步幅 18 19 Returns: 20 X -- output of the convolutional block, tensor of shape (n_H, n_W, n_C) 卷积块的输出,tensor类型,维度为(n_H, n_W, n_C) 21 """ 22 23 # defining name basis 定义命名规则 24 conv_name_base = 'res' + str(stage) + block + '_branch' 25 bn_name_base = 'bn' + str(stage) + block + '_branch' 26 27 # Retrieve Filters获取过滤器数量 28 F1, F2, F3 = filters 29 30 # Save the input value 保存输入数据 31 X_shortcut = X 32 33 34 ##### MAIN PATH ##### 主路径 35 # First component of main path 主路径第一部分 36 X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (s, s), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X) 37 X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X) 38 X = Activation('relu')(X) 39 40 #Glorot正态分布初始化方法,也称作Xavier正态分布初始化 41 42 ### START CODE HERE ### 43 44 # Second component of main path (≈3 lines) 45 X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1, 1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X) 46 X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X) 47 X = Activation('relu')(X) 48 49 # Third component of main path (≈2 lines) 50 X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X) 51 X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X) 52 53 ##### SHORTCUT PATH #### (≈2 lines) 54 X_shortcut = Conv2D(filters = F3, kernel_size = (1, 1), strides = (s, s), padding = 'valid', name = conv_name_base + '1', kernel_initializer = glorot_uniform(seed=0))(X_shortcut) 55 X_shortcut = BatchNormalization(axis = 3, name = bn_name_base + '1')(X_shortcut) 56 57 # Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines) 58 X = Add()([X, X_shortcut]) 59 X = Activation('relu')(X) 60 61 ### END CODE HERE ### 62 63 return X
# tf.reset_default_graph() ops.reset_default_graph() with tf.compat.v1.Session() as test: np.random.seed(1) A_prev = tf.compat.v1.placeholder("float", [3, 4, 4, 6]) X = np.random.randn(3, 4, 4, 6) A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a') test.run(tf.compat.v1.global_variables_initializer()) out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0}) print("out = " + str(out[0][1][1][0])) test.close()
执行结果:

3 - Building your first ResNet model (50 layers) 构建你的第一个残差网络(50层)
我们已经做完所需要的所有残差块了,下面这个图就描述了神经网络的算法细节,图中的"ID BLOCK"是指标准的恒等块,"ID BLOCK X3"是指把三个恒等块放在一起。

**Figure 5** : **ResNet-50 model**
这个50层的网络的细节如下:
1、对输入数据进行0填充,padding = (3, 3)
2、stage1:
1、卷积层有64个过滤器,其维度为(7, 7),步幅为(2, 2),命名为‘conv1’
2、规范层(BatchNorm)对输入数据进行通道轴归一化
3、最大池化层使用一个(3, 3)的窗口和(2, 2)的步幅
3、stage2:
1.卷积块使用 f = 3个大小为 [64, 64, 256] 的过滤器,f = 3, s = 1, block = ‘a’
2、 2个恒等块使用三个大小为 [64, 64, 256] 的过滤器,f = 3, block = ‘b’、‘c’
4、stage3:
1、卷积块使用 f=3 个大小为 [128, 128, 512] 的过滤器,f = 3, s = 2, block = ‘a’
2、 3个恒等块使用三个大小为[128, 128, 512] 的过滤器,f = 3, block = ‘b’、‘c’、‘d’
5、stage4:
1、卷积块使用f=3个大小为[256,256,1024]的过滤器,f=3,s=2,block=“a”
2、 5个恒等块使用三个大小为[256,256,1024]的过滤器,f=3,block=“b”、“c”、“d”、“e”、“f”
6、stage5:
1、卷积块使用f=3个大小为[512,512,2048]的过滤器,f=3,s=2,block=“a”
2、 2个恒等块使用三个大小为[256,256,2048]的过滤器,f=3,block=“b”、“c”
7、均值池化层使用维度为(2,2)的窗口,命名为“avg_pool”
8、展开操作没有任何超参数以及命名
9、全连接层(密集连接)使用softmax激活函数,命名为:‘fc’ + str(classes)
为了实现这50层的残差网络,我们需要查看一下手册:
1 # GRADED FUNCTION: ResNet50 2 3 def ResNet50(input_shape = (64, 64, 3), classes = 6): 4 """ 5 Implementation of the popular ResNet50 the following architecture: 6 CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3 7 -> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER 8 9 Arguments: 10 input_shape -- shape of the images of the dataset 图像数据集的维度 11 classes -- integer, number of classes 整数,分类数 12 13 Returns: 14 model -- a Model() instance in Keras Keras框架的模型 15 """ 16 17 # Define the input as a tensor with shape input_shape 定义tensor类型的输入数据 18 X_input = Input(input_shape) 19 20 21 # Zero-Padding 0填充 22 X = ZeroPadding2D((3, 3))(X_input) 23 24 # Stage 1 25 X = Conv2D(64, (7, 7), strides = (2, 2), name = 'conv1', kernel_initializer = glorot_uniform(seed=0))(X) 26 X = BatchNormalization(axis = 3, name = 'bn_conv1')(X) 27 X = Activation('relu')(X) 28 X = MaxPooling2D((3, 3), strides=(2, 2))(X) 29 30 # Stage 2 31 X = convolutional_block(X, f = 3, filters = [64, 64, 256], stage = 2, block='a', s = 1) 32 X = identity_block(X, 3, [64, 64, 256], stage=2, block='b') 33 X = identity_block(X, 3, [64, 64, 256], stage=2, block='c') 34 35 ### START CODE HERE ### 36 37 # Stage 3 (≈4 lines) 38 X = convolutional_block(X, f = 3, filters = [128, 128, 512], stage = 3, block = 'a', s = 2) 39 X = identity_block(X, 3, [128, 128, 512], stage = 3, block = 'b') 40 X = identity_block(X, 3, [128, 128, 512], stage = 3, block = 'c') 41 X = identity_block(X, 3, [128, 128, 512], stage = 3, block = 'd') 42 43 # Stage 4 (≈6 lines) 44 X = convolutional_block(X, f = 3, filters = [256, 256, 1024], stage = 4, block = 'a', s = 2) 45 X = identity_block(X, 3, [256, 256, 1024], stage = 4, block = 'b') 46 X = identity_block(X, 3, [256, 256, 1024], stage = 4, block = 'c') 47 X = identity_block(X, 3, [256, 256, 1024], stage = 4, block = 'd') 48 X = identity_block(X, 3, [256, 256, 1024], stage = 4, block = 'e') 49 X = identity_block(X, 3, [256, 256, 1024], stage = 4, block = 'f') 50 51 # Stage 5 (≈3 lines) 52 X = convolutional_block(X, f = 3, filters = [512, 512, 2048], stage = 5, block = 'a', s = 2) 53 X = identity_block(X, 3, [512, 512, 2048], stage = 5, block = 'b') 54 X = identity_block(X, 3, [512, 512, 2048], stage = 5, block = 'c') 55 56 # AVGPOOL (≈1 line). Use "X = AveragePooling2D(...)(X)" 均值池化层 57 X = AveragePooling2D(pool_size = (2, 2), padding = 'same')(X) 58 59 ### END CODE HERE ### 60 61 # output layer 输出层 62 X = Flatten()(X) 63 X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X) 64 65 66 # Create model 创建模型 67 model = Model(inputs = X_input, outputs = X, name='ResNet50') 68 69 return model
然后我们对模型做实体化和编译工作:
model = ResNet50(input_shape = (64, 64, 3), classes = 6) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
现在模型已经准备好了,接下来就是加载训练集进行训练。

**Figure 6** : **SIGNS dataset** 手势数据集
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset() # Normalize image vectors 归一化 X_train = X_train_orig/255. X_test = X_test_orig/255. # Convert training and test labels to one hot matrices Y_train = convert_to_one_hot(Y_train_orig, 6).T Y_test = convert_to_one_hot(Y_test_orig, 6).T print ("number of training examples = " + str(X_train.shape[0])) print ("number of test examples = " + str(X_test.shape[0])) print ("X_train shape: " + str(X_train.shape)) print ("Y_train shape: " + str(Y_train.shape)) print ("X_test shape: " + str(X_test.shape)) print ("Y_test shape: " + str(Y_test.shape))
执行结果:

运行模型两代,batch=32,每代大约3分钟左右。
model.fit(X_train, Y_train, epochs = 2, batch_size = 32)
执行结果:
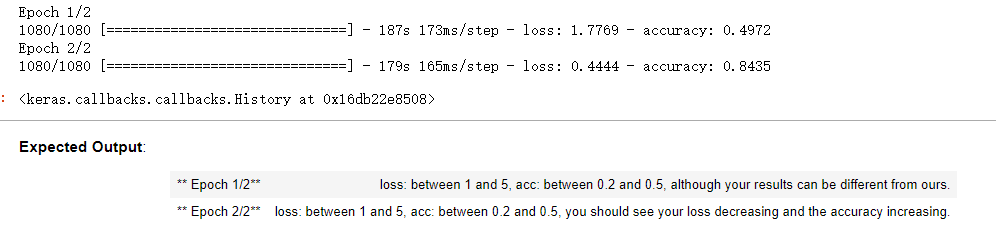
这里第二代的loss和准确度都和预期不一样。。。
我们来评估一下模型:
preds = model.evaluate(X_test, Y_test) print ("Loss = " + str(preds[0])) print ("Test Accuracy = " + str(preds[1]))
执行结果:

额,准确率高的超过预期。。。。
在完成这个任务之后,如果愿意的话,您还可以选择继续训练RESNET。当我们训练20代时,我们得到了更好的性能,但是在得在CPU上训练需要一个多小时。使用GPU的话,博主已经在手势数据集上训练了自己的RESNET50模型的权重,你可以使用下面的代码载并运行博主的训练模型,加载模型可能需要1min。
#加载模型 model = load_model("ResNet50.h5")
然后测试一下博主训练出来的权值:
preds = model.evaluate(X_test,Y_test) print("误差值 = " + str(preds[0])) print("准确率 = " + str(preds[1]))
测试结果:
120/120 [==============================] - 4s 35ms/step 误差值 = 0.108543064694 准确率 = 0.966666662693
4 - Test on your own image (Optional/Ungraded)
如果你愿意,你也可以拍一张自己的手的照片,看看模型的输出。要做到这一点:
1、点击这个笔记本上面一栏的“文件”,然后点击“打开”进入你的Coursera中心。
2、将您的图像添加到此木星笔记本的目录,在“images”文件夹
3、将图像名称写入以下代码
4、运行代码并检查算法是否正确!
img_path = 'images/my_image.jpg' img = image.load_img(img_path, target_size=(64, 64)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) print('Input image shape:', x.shape) my_image = scipy.misc.imread(img_path) imshow(my_image) print("class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] = ") print(model.predict(x))
您还可以通过运行以下代码打印模型的摘要。
model.summary()
最后,运行下面的代码以可视化ResNet50。你也可以通过“File -> Open…”- > model.png”。
plot_model(model, to_file='model.png') SVG(model_to_dot(model).create(prog='dot', format='svg'))
**你应该记住的:** -非常深的“普通”网络在实践中是行不通的,因为它们很难训练,因为梯度会消失。
-跳转连接帮助解决渐变消失的问题。它们还使ResNet块易于学习标识函数。
-有两种主要类型的块:恒等块和卷积块。
-非常深的剩余网络是通过将这些块堆叠在一起而建立起来的。
作者:Agiroy_70
本博客所有文章仅用于学习、研究和交流目的,欢迎非商业性质转载。
博主的文章主要是记录一些学习笔记、作业等。文章来源也已表明,由于博主的水平不高,不足和错误之处在所难免,希望大家能够批评指出。
博主是利用读书、参考、引用、抄袭、复制和粘贴等多种方式打造成自己的文章,请原谅博主成为一个无耻的文档搬运工!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号