【Python】羊毛获取小工具
前言
最近沉迷薅羊毛,然后想第一时间得到新的消息。 不过说实话第一时间是不存在的,除非跟商家直接对接。 于是乎只能靠微博啊,企鹅群等,看别人发的新信息了。 那么做一个简单的爬虫,定时爬一下消息应该挺不错的。
明确目标
要想一直知道什么羊毛,那么就需要不断去获取信息,刷新的第一时间就反应给用户。
伪代码逻辑如下:
1
|
|
核心功能就是获得羊毛和清洗数据,提醒用户。其他的东西都属于一个处理逻辑,要根据需求来灵活变化。
获取信息
寻找目标
判断爬取目标
一开始想爬的是PC版 围脖 ,然后解析信息。 发现PC版 围脖 的信息,不好抓,抓了也不好解析。于是为了减少工作量,决定要去爬手机版的围脖。
分析数据包
在浏览器的开发者模式下打开我们要找的对象地址示例,看数据交互找一下我们要用到的东西。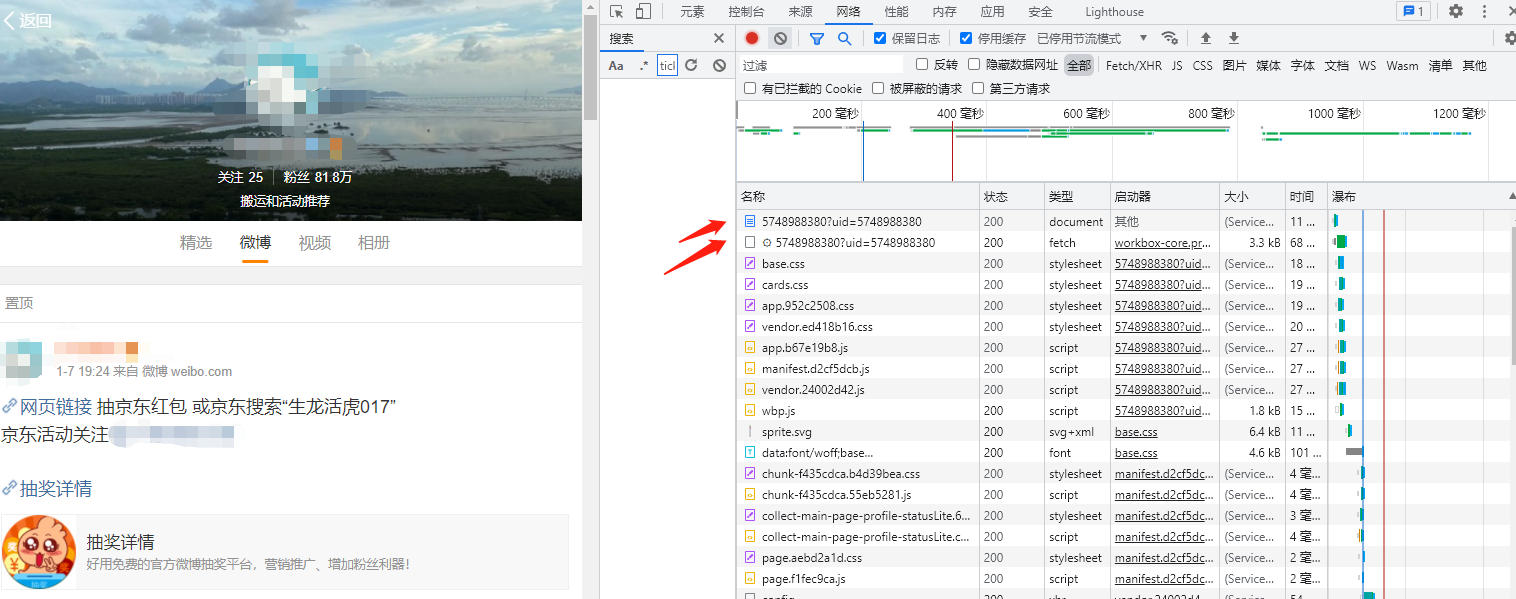
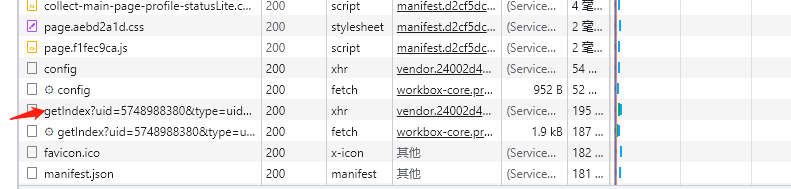
一个个观察参考,可以过滤一下数据包,选择Fetch/XHR,过滤成数据请求。
观察到了一个api接口,请求了用户的某些数据。

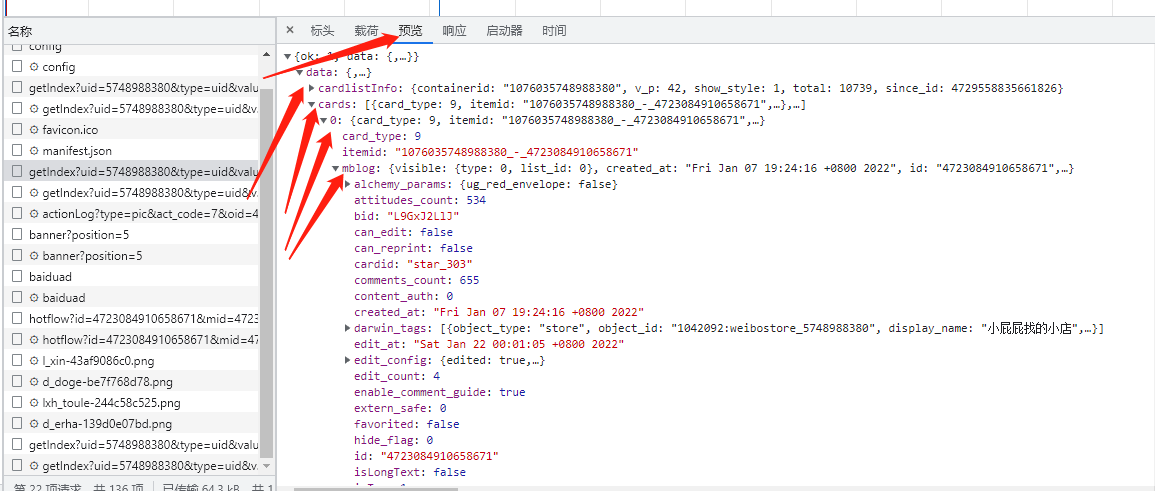
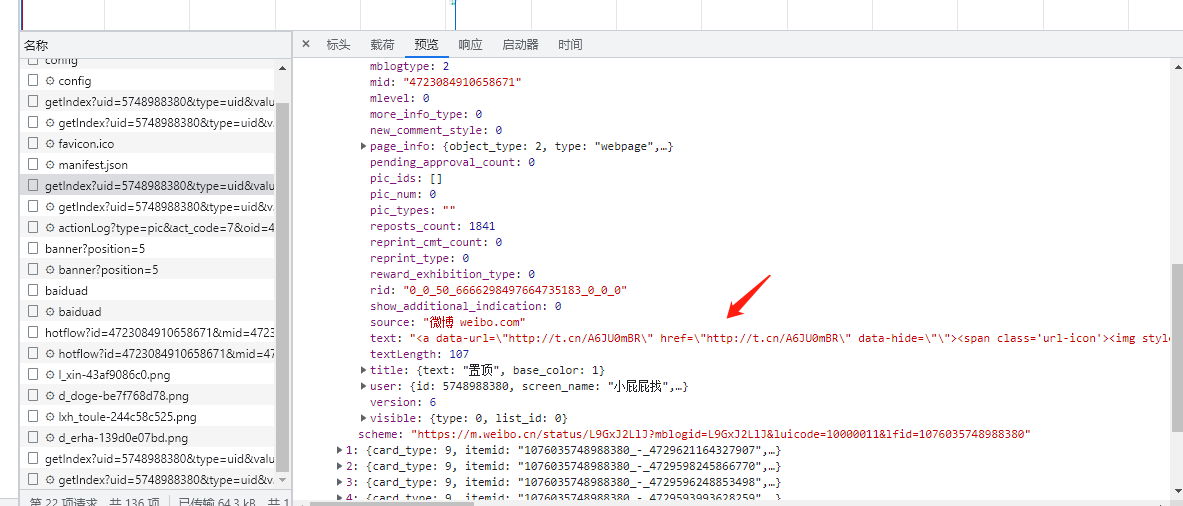
在观察其获得的data,可以找到一些博主下面的微博
而且在一个list中,按顺序排列,里面有每条微博的信息。
1
|
|
这是这版本想要的部分信息,具体想要什么,还是要看需求。
代码处理
核心逻辑
1
|
|
到最后save_json_list里面就是要存本次获取到的数据了。
时间处理方法
timeanalysis方法是用于处理获取到的数据里面混乱的时间
数据里面获取到的时间如Fri Jan 07 19:24:16 +0800 2022,这样的格式我们是没法很好得去转换成符合人类的语言
于是就有了这个处理方法
1
|
|
文字信息处理方法
get_detailpage方法是用来处理text里面的东西的,由于写在核心逻辑里面,会显得很乱。
而且转发微博和原创微博都是同类型的数据,处理的方法一样,既然可以重复调用,那么就只做一次。
由于我们要获得羊毛信息,那么肯定是要得到商品信息,商品链接。价格有没有,就直接能在商品信息中获得。
所以结构估计就是
- 商品1信息+url
- 商品2信息+url
- 商品3信息+url
一般来说,就算一条微博里面有多个商品羊毛,那么也会是商品1,商品2…这样的格式。
那我们就要过滤并输出商品信息+URL的结构
那么我们就要输出这种结构的内容。
处理方法如下:
1
|
|
这一段处理方法一定是有更好的操作的。但是暂时也想不出好用点的方法。于是就先将就着。
图片处理方法
此外我们还需要把图片信息提取,不然只有文字,用户可能不知道是什么样子的东西,究竟想不想要。
1
|
|
结语
当处理图片、处理时间、处理文字的情况都完成后,其他的就是一些筛选逻辑了。
具体的内容就不分享了,实际需求实际分析。
以上内容可能合理可能不合理,仅供参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号