

大数据笔记Hadoop
XSheel7远程连接工具
远程上传下载文件Xftp7
==========
001 大数据概念
1: 大数据(big data):值无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发现力和流程优化能力的海量,高增长率和多样化的信息资产.
2:数据存储单元:bit, Byte,KB,MB, GB, TB,PB,EB,ZB,YB,BB,NB,DB.
1Byte = 8bit
1KB = 1024 Byte
1MB = 1024KB
1G = 1024M
1T = 1024G
1P = 1024T
3:大数据主要解决数据的存储和海量数据的分析计算问题.
002 大数据特点
1:Volume (大量)--数据量更大
2:Velocity(高速)--数据量增长速度快,互联网技术普及,手机活跃用户量,抖音,快手,等小视频
3:Variety(多样):相对于以往便于存储的以数据/文本为主的结构化数据,非结构化数据越来越多,包括网络日志,音频,视频,图片,地理位置信息等
4:Value(低价值密度)--价值密度的高低与数据总量的大小成反比.--是否能够快速的对有价值的数据进行"提纯"愈来愈重要.
003 大数据应用场景
1 仓储物流
2 零售 经典案例(啤酒+纸尿裤)
3 旅游
4 商品推荐广告
5 保险
6 金融
7 房地产
8 环保
9 人工智能
004 大数据发展前景
1 政策支持
2 人才缺口大
3 大学开设相关专业(知网关于大数据方面的论文从理论->偏实际应用方面)
4 薪资待遇高
005 大数据部门业务流程
1 产品人员提需求(统计总用户数,日活跃用户数,回流用户数等)-->
2 数据部门搭建数据平台,分析数据指标
3 数据可视化(报表展示,邮件发送,大屏幕展示等)
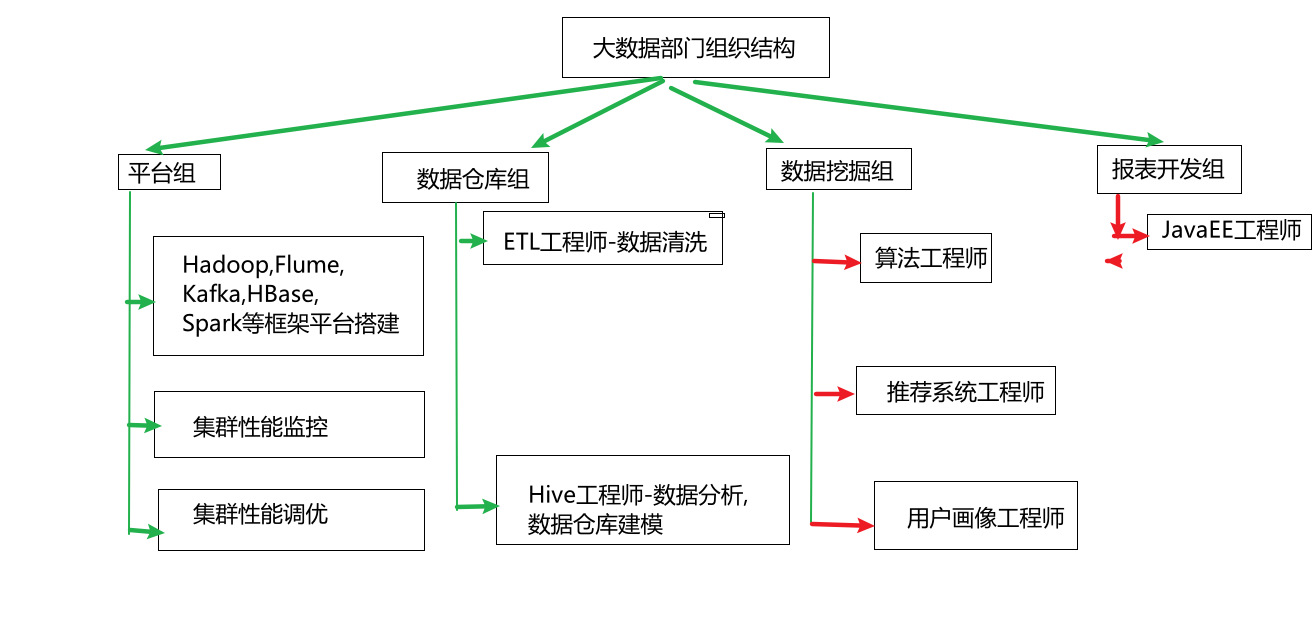
006 大数据部门组织结构(重点)
007 Hadoop是什么
1:Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2:主要解决,海量数据的存储和海量数据的分析计算问题.
3:广义上来说, Hadoop通常是指一个更广泛的概念---Hadoop生态圈.
008 Hadoop发展历史
--请参看网络--
创始人:Doug Cutting
三大论文:
GFS-->HDFS
Map-Reduce--->MR
BigTable-->HBase
009 Hadoop三大发行版本
Hadoop三大发行版本 Apache,Cloudera,Hortonworks.
Apache 版本最原始,最基础,对入门学习最好
Apache Hadoop
官网地址:http://hadoop.apache.org/
下载地址:http://archive.apache.org/dist/hadoop/common/
11
下载网址:http://archive.apache.org/dist/hadoop/common/
010 Hadoop优势(4高)
1 高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失.
2 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点
3 高效性:在MapReduce思想下,Hadoop是并行工作的,以加快任务处理速度.
4 高容错性:能够自动将失败的任务重新分配.
Hadoop组成(面试重点)
011 Hadoop1.x和Hadoop2.x的区别
解耦
Hadoop1.x组成: MapReduce(计算+资源调度);HDFS(数据存储);Common(辅助工具);
Hadoop2.x组成:MapReduce(计算);Yarn(资源调度); HDFS(数据存储); Common(辅助工具);
在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大,在Hadoop2.x时代,增加了Yarn.Yarn只负责资源的调度,MapReduce只负责运算.----解耦
012 HDFS架构概述
1:NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(文件生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.
2:DataNode(dn):在本地文件系统存储文件块数据,以及数据的效验和.
3:Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照.
简答记:NameNode存储的是目录,DataNode存储的是具体数据,Secondary NameNode是用来辅助NameNode的.
103 YARN架构概述
1 ResourceManager(RM)主要作用
- 处理客户请求
- 监控NodeManager
- 启动或监控ApplicationMaster
- 资源的分配与调度
2 NodeManager(NM)主要作用如下
- 管理单个节点
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
3 ApplicationMaster(AM)作用如下
- 负责数据的切分
- 为应用程序申请资源并分配给内部的任务
- 任务的监控与容错
4 Container
- Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存,CPU,磁盘,网络等.
104 MapReduce架构概述
MapReduce 将计算过程分为两个阶段:Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
105 大数据技术生态体系
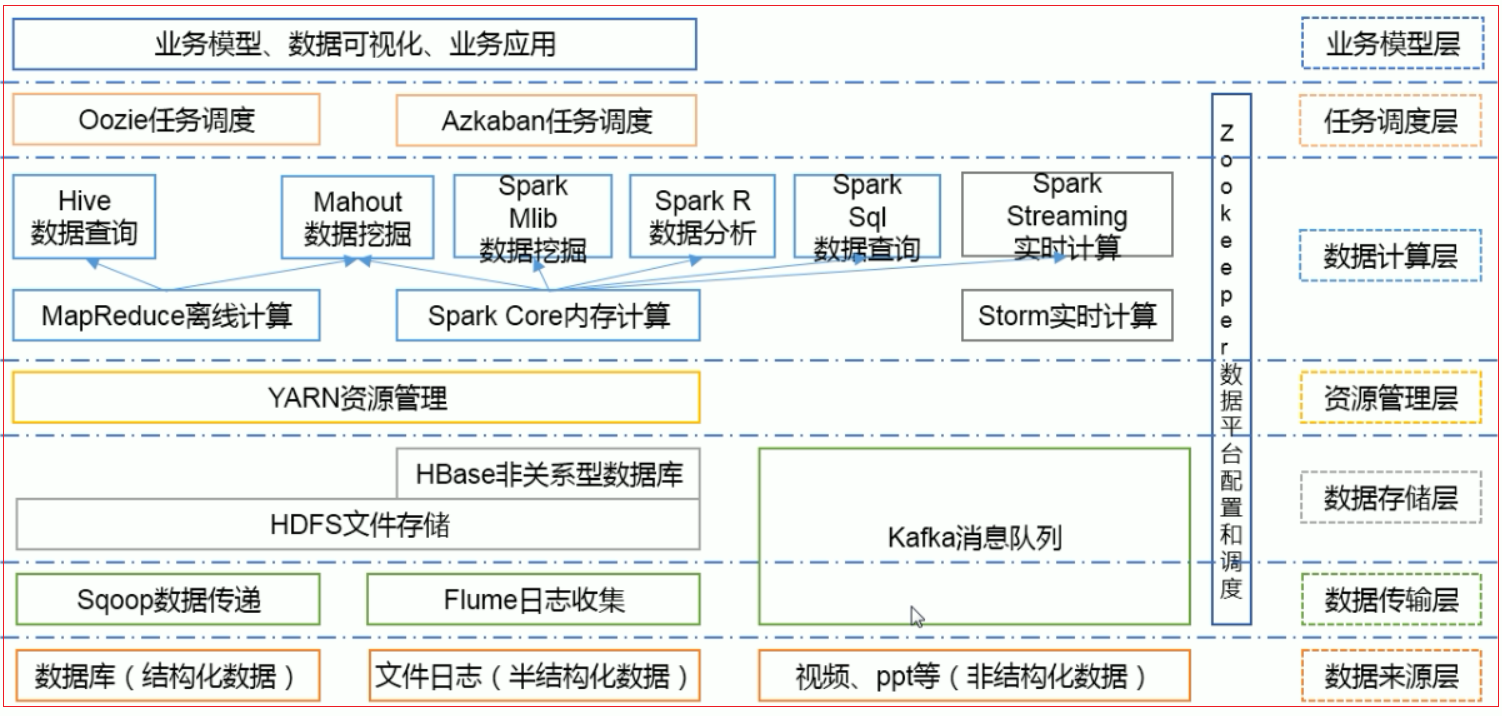
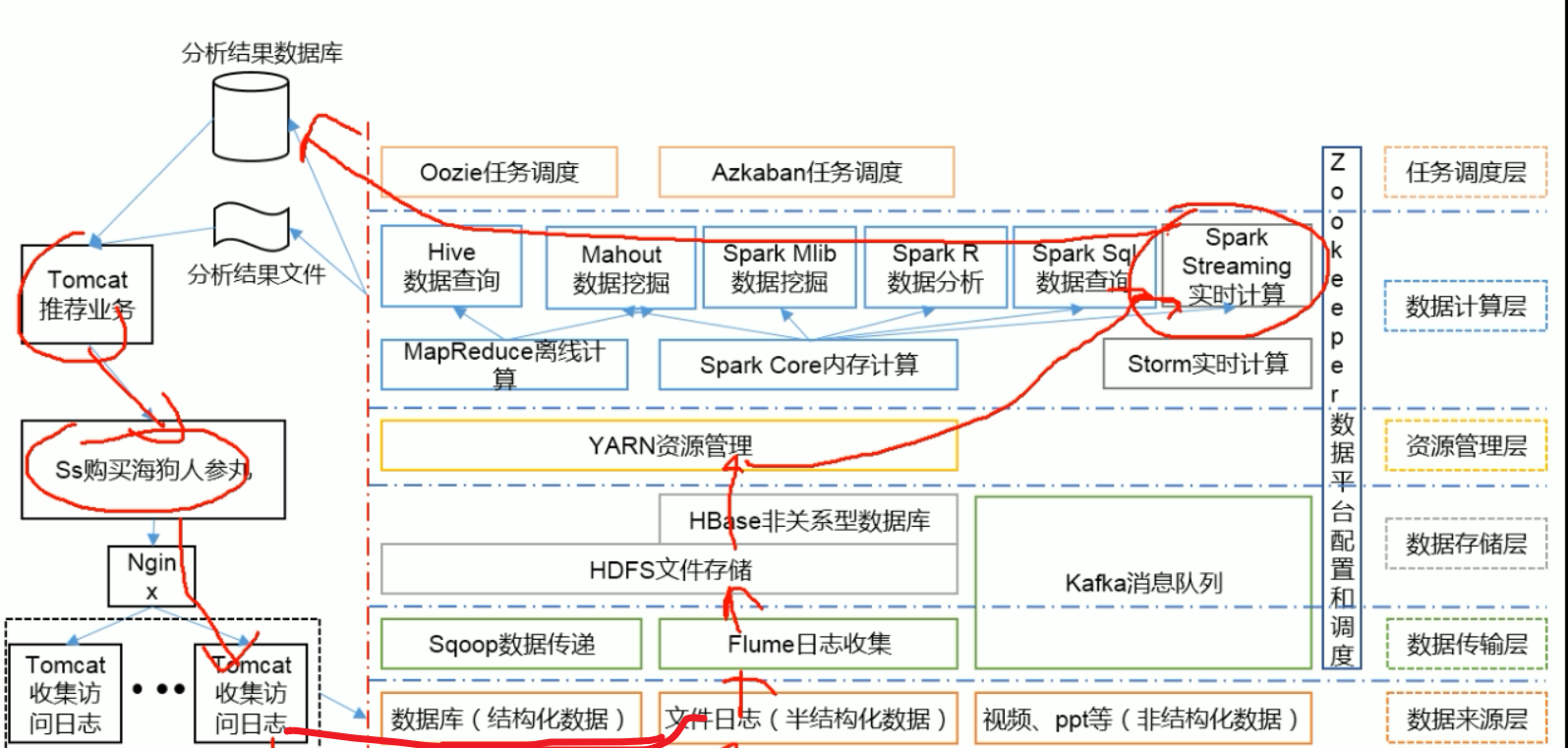
016 推荐系统框架
第三章 Hadoop运行环境搭建
017 虚拟机环境准备
018 安装JDK
019 安装Hadoop
020 Hadoop目录结构
第四章 Hadoop运行模式
本地运行模式
021 官方Grep案例 检索
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
022 官方WordCount案例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
伪分布式运行模式 Pseudo-Distributed Operation
022 启动HDFS并运行MapReduce程序
Configuration
Use the following:
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
----不要频繁的格式操作.
格式化NameNode(第一次启动时格式化,以后就不要总格式化)
再次格式化之前,先查看jps 查看进程是否全部关闭,确保关闭后---然后删除data和logs目录
