


粒子群优化算法
粒子群算法作为一种优化算法,在很多领域都有应用。所谓优化,是对一个问题求出它足够好的解,目前的优化算法很多,如蚁群算法,遗传算法等。粒子群算法相对于这些算法来说,它更简单,而且有很快的收敛速度。在水文模型参数优化算法中,粒子群优化算法是近期使用最高效的方法。
关于粒子群优化-Particle Swarm Optimization (PSO)的详细介绍参照http://www.zhizhihu.com/html/y2011/3568.html,其提供了IDL、C、Matlab、Java版本的code。
算法步骤:
1.首先确定粒子个数与迭代次数。
2.对每个粒子随机初始化位置与速度。
3.采用如下公式更新每个粒子的位置与速度。
Px = Px+Pv*t; %位置更新公式
Pv = Pv+(c1*rand*(Gx-Px))+(c2*rand(PBx-Px)); %速度更新
其中,c1,c2是加速因子,Gx是粒子群中最佳粒子的位置,PBx为当前粒子最佳位置。
4. 每次迭代,首先检查新粒子适应度是否高于原最优适应度,如果高于则对自己的位置和适应度进行更新。然后再判断此粒子适应度是否高于全局最优粒子,如果高于则更新全局最优粒子适应度和位置。
个人理解,其本质是遍历搜索的原理(减少了运算量)。参数优化的关键是目标函数,及如何确定适应度,参数边界条件。
【转】
Matlab:
pso_main.m
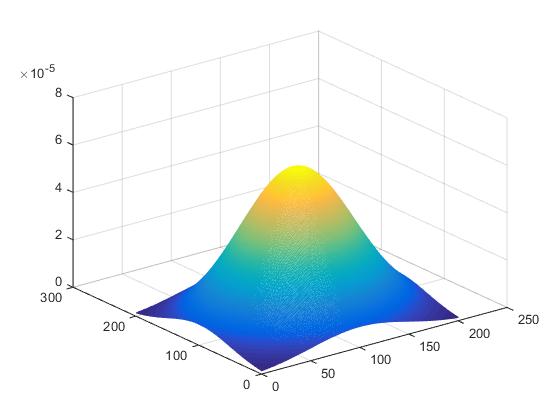
1 clear all;close all;clc; 2 3 [x y]=meshgrid(-100:100,-100:100); 4 sigma=50; 5 img = (1/(2*pi*sigma^2))*exp(-(x.^2+y.^2)/(2*sigma^2)); %目标函数,高斯函数 6 mesh(img); 7 hold on; 8 n=10; %粒子群粒子个数 9 10 %初始化粒子群,定义结构体 11 %结构体中八个元素,分别是粒子坐标,粒子速度,粒子适应度,粒子最佳适应度,粒子最佳坐标 12 par=struct([]); 13 for i=1:n 14 par(i).x=-100+200*rand(); %[-100 100]对x位置随机初始化 15 par(i).y=-100+200*rand(); %[-100 100]对y位置随机初始化 16 par(i).vx=-1+2*rand(); %[-1 1]对vx速度随机初始化 17 par(i).vy=-1+2*rand(); %[-1 1]对vy速度随机初始化 18 par(i).fit=0; %粒子适应度为0初始化 19 par(i).bestfit=0; %粒子最佳适应度为0初始化 20 par(i).bestx=par(i).x; %粒子x最佳位置初始化 21 par(i).besty=par(i).y; %粒子y最佳位置初始化 22 end 23 par_best=par(1); %初始化粒子群中最佳粒子 24 25 for k=1:10 26 plot3(par_best.x+100,par_best.y+100,par_best.fit,'g*'); %画出最佳粒子的位置,+100为相对偏移 27 for p=1:n 28 [par(p),par_best]=update_par(par(p),par_best); %更新每个粒子信息 29 end 30 end
update_par.m
1 function [par par_best]=update_par(par,par_best) 2 3 %Px=Px+Pv*t,这里t=1,Px为当前粒子的位置,Pv为当前粒子的速度 4 par.x=par.x+par.vx; 5 par.y=par.x+par.vy; 6 7 par.fit=compute_fit(par); %计算当前粒子适应度 8 9 %Pv=Pv+(c1*rand*(Gx-Px))+(c2*rand*(PBx-Px)) 10 %这里c1,c2为加速因子 11 %Gx为具有最佳适应度粒子的位置 12 %PBx为当前粒子的最佳位置 13 c1=1; 14 c2=1; 15 par.vx=par.vx+c1*rand()*(par_best.x-par.x)+c2*rand()*(par.bestx-par.x); 16 par.vy=par.vy+c1*rand()*(par_best.y-par.y)+c2*rand()*(par.besty-par.y); 17 18 if par.fit>par.bestfit %如果当前粒子适应度要好于当前粒子最佳适应度 19 par.bestfit=par.fit; %则更新当前粒子最佳适应度 20 par.bestx=par.x; %更新当前粒子最佳位置 21 par.besty=par.y; 22 if par.bestfit>par_best.fit %如果当前粒子最佳适应度好于最佳粒子适应度 23 par_best.fit=par.bestfit; %则更新最佳粒子适应度 24 par_best.x=par.x; %更新最佳粒子位置 25 par_best.y=par.y; 26 end 27 end 28 29 end
compute_fit.m
1 function re=compute_fit(par) 2 x=par.x; 3 y=par.y; 4 sigma=50; 5 if x<-100 || x>100 || y<-100 || y>100 6 re=0; %超出范围适应度为0 7 else %否则适应度按目标函数求解 8 re= (1/(2*pi*sigma^2))*exp(-(x.^2+y.^2)/(2*sigma^2)); 9 end 10 end
Python:

