redis集群某节点连接数偏高问题处理
背景
接收到监控推送的告警,redis集群某节点连接数偏高,触发告警阈值,但该项目明显没有大流量访问,最近也没有更新程序,虽然对生产暂时不会产生影响,但隐患毕竟是隐患,需排查。
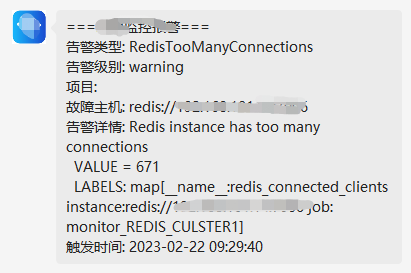 #
#
排查
排查下hotkeys

命令不可用,redis-server的maxmemory-policy参数设置为LFU。而生产的淘汰策略是volatile-lru

换个思维,查看下谁在连接
redis-cli -p 端口 -a XXXXXX info |grep connected

是客户端的连接,集群前面有N个predixy代理,顺便找某个代理节点看下有百来个连接
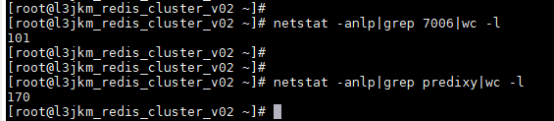
查看具体的客户端连接信息
client list
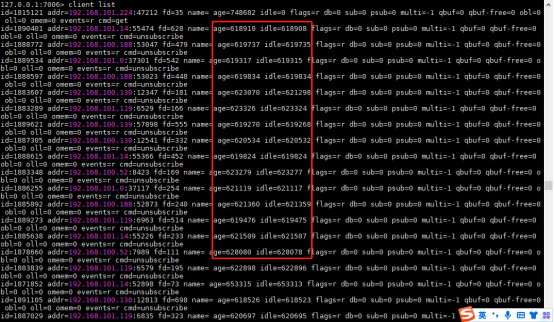
addr:客户端的地址和端口
fd:套接字所使用的文件描述符
age:以秒计算的已连接时长
idle:以秒计算的空闲时长
flags:客户端 flag
db:该客户端正在使用的数据库 ID
sub:已订阅频道的数量
psub:已订阅模式的数量
multi:在事务中被执行的命令数量
qbuf:查询缓冲区的长度(字节为单位, 0 表示没有分配查询缓冲区)
qbuf-free:查询缓冲区剩余空间的长度(字节为单位, 0 表示没有剩余空间)
obl:输出缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区)
oll:输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里)
omem:输出缓冲区和输出列表占用的内存总量
events:文件描述符事件
cmd:最近一次执行的命令
发现客户端的idle空闲时长太长,连接池维持了太多的连接
问题找到了。很简单,配置一下过timeout时间就好了。
处理
查看下默认连接timeout时间
config get timeout
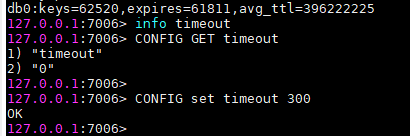
配置过期时间,设置个300秒
CONFIG set timeout 300
问题解决:

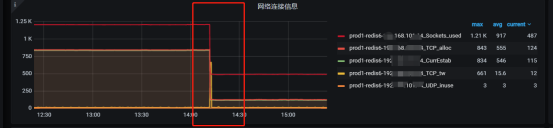
思考:
虽然问题解决了,这样排查算失败的。刚才计算了单个predixy节点到7006的连接数为101个。忘记计算程序连接到predixy代理点端口的连接数。
所以到底的程序的问题还是代理的问题,继续排查。。。。
从配置出发
predixy.conf

cluster.conf
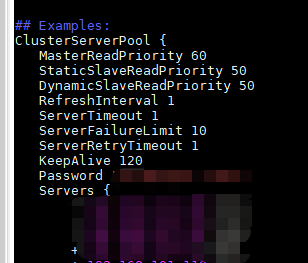
ServerTimeout: 请求在predixy中最长的处理/等待时间,如果超过该时间redis还没有响应的话,那么predixy会关闭同redis的连接,并给客户端一个错误响应,对于blpop这种阻塞式命令,该选项不起作用,为0则禁止此功能,即如果redis不返回就一直等待,不指定的话为0
ServerFailureLimit: 一个redis实例出现多少次才错误以后将其标记为失效,不指定的话为10
ServerRetryTimeout: 一个redis实例失效后多久后去检查其是否恢复正常,不指定的话为1秒
KeepAlive: predixy与redis的连接tcp keepalive时间,为0则禁止此功能,不指定的话为0
生产的redis.conf

从配置上看,不管是predixy还是redis都有配置tcp keepalive的超时时间,所以问题大概率还是出在程序上,可能是连接池过大而且重复被触发多个连接。
无法溯源也就无法知道是哪个研发的锅,毕竟是生产,该来还是会来,等下一次的出现再接着排查。
总结:
还是要有比较严谨逻辑的排查思路,有代理就要多一层考虑,解决问题也不能急于求成,不然锅甩不出去。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?