kvmclock代码学习
Linux源码版本: 5.3.0
guest os中的kvmclock驱动
kvmclock_init()函数主要做了以下几件事:
-
确定了各vcpu要使用的MSR
-
将各vcpu在kvmclock中实际使用的数据结构pvclock_vsyscall_time_info的物理地址利用write_msr写到属于每个vcpu的MSR
-
将1GHz的kvmclock作为clocksource注册到系统clocksource中
void __init kvmclock_init(void)
{
u8 flags;
if (!kvm_para_available() || !kvmclock) // 若不支持kvmclock则直接return
return;
if (kvm_para_has_feature(KVM_FEATURE_CLOCKSOURCE2)) { // 查询是否支持新的kvmclock msr
msr_kvm_system_time = MSR_KVM_SYSTEM_TIME_NEW;
msr_kvm_wall_clock = MSR_KVM_WALL_CLOCK_NEW;
} else if (!kvm_para_has_feature(KVM_FEATURE_CLOCKSOURCE)) { // 如果只支持旧的kvmclock msr,则直接return
return;
}
if (cpuhp_setup_state(CPUHP_BP_PREPARE_DYN, "kvmclock:setup_percpu",
kvmclock_setup_percpu, NULL) < 0) { // hp:hotplug, BP:bootstrap启动 启动热插拔主核的动态准备
return;
}
pr_info("kvm-clock: Using msrs %x and %x",
msr_kvm_system_time, msr_kvm_wall_clock); // msr_kvm_system_time:kvm_system_time使用的msr
// msr_kvm_wall_clock:kvm_wall_clock使用的msr
this_cpu_write(hv_clock_per_cpu, &hv_clock_boot[0]); // 将hv_clock_boot数组第一个元素的地址(虚拟地址)赋值
// 给local cpu变量hv_clock_per_cpu
/* 将vcpu0的hv_clock_per_cpu物理地址写入msr_kvm_system_time指向的msr中 */
kvm_register_clock("primary cpu clock");
pvclock_set_pvti_cpu0_va(hv_clock_boot); // 将hv_clock_boot的数组地址写入pvti_cpu0_va中,pvti_cpu0_va是一个pvti类型的指针
if (kvm_para_has_feature(KVM_FEATURE_CLOCKSOURCE_STABLE_BIT)) // KVM_FEATURE_CLOCKSOURCE_STABLE_BIT时钟源稳定指示bit
pvclock_set_flags(PVCLOCK_TSC_STABLE_BIT); // 半虚拟化时钟TSC是否稳定指示bit,什么作用呢?
flags = pvclock_read_flags(&hv_clock_boot[0].pvti); // 确定vcpu0的pvti结构的flags
kvm_sched_clock_init(flags & PVCLOCK_TSC_STABLE_BIT); // 进行时钟调度初始化,sched_clock()用于时钟调度、时间戳,及利用硬件计数器
// 的延时以提供一个精确的延迟时钟源
/* 注册各种回调函数 */
x86_platform.calibrate_tsc = kvm_get_tsc_khz; // tsc_khz为Host的pTSCfreq,指向host TSC频率的指针
x86_platform.calibrate_cpu = kvm_get_tsc_khz;
x86_platform.get_wallclock = kvm_get_wallclock; // wallclock:获得系统boot时的秒数和纳秒数(绝对时间,自1970)
x86_platform.set_wallclock = kvm_set_wallclock;
#ifdef CONFIG_X86_LOCAL_APIC
x86_cpuinit.early_percpu_clock_init = kvm_setup_secondary_clock; // 注册各非vcpu0的时钟,将各vCPU0的vptihv_clock_per_cpu写入各
// 自的msr_kvm_system_time指向的msr中
#endif
x86_platform.save_sched_clock_state = kvm_save_sched_clock_state; // 保存sched_clock的状态,事实什么都没做
x86_platform.restore_sched_clock_state = kvm_restore_sched_clock_state;
machine_ops.shutdown = kvm_shutdown;
#ifdef CONFIG_KEXEC_CORE
machine_ops.crash_shutdown = kvm_crash_shutdown;
#endif
kvm_get_preset_lpj(); // lpj:loops_per_jiffy
/*
* X86_FEATURE_NONSTOP_TSC is TSC runs at constant rate
* with P/T states and does not stop in deep C-states.
*
* Invariant TSC exposed by host means kvmclock is not necessary:
* can use TSC as clocksource.
*
*/
if (boot_cpu_has(X86_FEATURE_CONSTANT_TSC) &&
boot_cpu_has(X86_FEATURE_NONSTOP_TSC) &&
!check_tsc_unstable())
kvm_clock.rating = 299;
clocksource_register_hz(&kvm_clock, NSEC_PER_SEC); // 1Ghz的kvmclock source的注册
pv_info.name = "KVM";
}
注册为x86_platform.xxxx的函数有3个,分别为kvm_get_tsc_khz,kvm_get/set_wallclock。
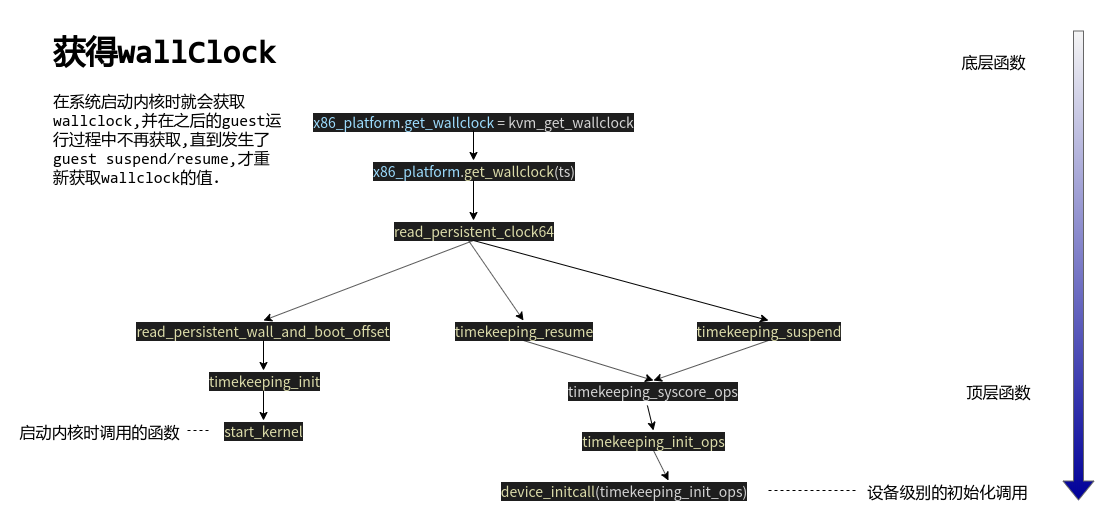
kvm_get_wallclock()
/*
* The wallclock is the time of day when we booted. Since then, some time may
* have elapsed since the hypervisor wrote the data. So we try to account for
* that with system time
*/
static void kvm_get_wallclock(struct timespec64 *now)
{
wrmsrl(msr_kvm_wall_clock, slow_virt_to_phys(&wall_clock)); // 将wall_clock(pvclock_wall_clock类型)对应的物理地址写入对应msr
preempt_disable();
// wallclock的时间存于now
pvclock_read_wallclock(&wall_clock, this_cpu_pvti(), now); // 将host写入的wallclock读出来
preempt_enable();
}
/* wallclock的内容在该函数之前已经被host写入
*
*
*/
void pvclock_read_wallclock(struct pvclock_wall_clock *wall_clock,
struct pvclock_vcpu_time_info *vcpu_time,
struct timespec64 *ts)
{
u32 version;
u64 delta;
struct timespec64 now;
/* get wallclock at system boot */
do {
version = wall_clock->version;
rmb(); /* fetch version before time */
/*
* Note: wall_clock->sec is a u32 value, so it can
* only store dates between 1970 and 2106. To allow
* times beyond that, we need to create a new hypercall
* interface with an extended pvclock_wall_clock structure
* like ARM has.
*/
now.tv_sec = wall_clock->sec; // 读取wallclock时间,该时间不是完整时间
now.tv_nsec = wall_clock->nsec; // 还需要加上后面的delta, 即vm过去的时间
rmb(); /* fetch time before checking version */
} while ((wall_clock->version & 1) || (version != wall_clock->version));
delta = pvclock_clocksource_read(vcpu_time); /* time since system boot */
delta += now.tv_sec * NSEC_PER_SEC + now.tv_nsec;
now.tv_nsec = do_div(delta, NSEC_PER_SEC);
now.tv_sec = delta;
set_normalized_timespec64(ts, now.tv_sec, now.tv_nsec);
}
struct pvclock_wall_clock {
u32 version;
u32 sec;
u32 nsec;
} __attribute__((__packed__));
kvm_get_tsc_khz()
// 以kHz为基础获得tsc count
static unsigned long kvm_get_tsc_khz(void)
{
setup_force_cpu_cap(X86_FEATURE_TSC_KNOWN_FREQ);
return pvclock_tsc_khz(this_cpu_pvti());
}
// 将pv_tsc_khz根据local cpu的pvti的tsc_shift和tsc_to_system_mul做校准
unsigned long pvclock_tsc_khz(struct pvclock_vcpu_time_info *src)
{
u64 pv_tsc_khz = 1000000ULL << 32;
do_div(pv_tsc_khz, src->tsc_to_system_mul);
if (src->tsc_shift < 0)
pv_tsc_khz <<= -src->tsc_shift;
else
pv_tsc_khz >>= src->tsc_shift;
return pv_tsc_khz;
}
guest中设置时间的代码框架
内核获取wallclock
static struct pvclock_wall_clock wall_clock __bss_decrypted; // 静态全局变量wall_clock,存储于bss段
static void kvm_get_wallclock(struct timespec64 *now)
{
wrmsrl(msr_kvm_wall_clock, slow_virt_to_phys(&wall_clock)); // 将wall_clock的物理地址写入到MSR_KVM_WALL_CLOCK, 触发wrmsr_vmexit
preempt_disable();
pvclock_read_wallclock(&wall_clock, this_cpu_pvti(), now);
preempt_enable();
}
kvm_get_wallclock函数的第一个语句就会触发wrmsr_vmexit, 进而经过一系列的调用:
handle_wrmsr=>kvm_set_msr=>kvm_x86_ops->set_msr=>vmx_set_msr=>kvm_set_msr_common
int kvm_set_msr_common(struct kvm_vcpu *vcpu, struct msr_data *msr_info)
{
u64 data = msr_info->data;
...
case MSR_KVM_WALL_CLOCK_NEW:
case MSR_KVM_WALL_CLOCK:
vcpu->kvm->arch.wall_clock = data;
kvm_write_wall_clock(vcpu->kvm, data);
break;
...
}
static void kvm_write_wall_clock(struct kvm *kvm, gpa_t wall_clock)
{
...
// 这里的boot time为host系统启动时间
getboottime64(&boot); // 获取host的boot time并写入boot变量
if (kvm->arch.kvmclock_offset) {//对host boot time做一些调整
struct timespec64 ts = ns_to_timespec64(kvm->arch.kvmclock_offset);
boot = timespec64_sub(boot, ts);
}
wc.sec = (u32)boot.tv_sec; /* overflow in 2106 guest time */
wc.nsec = boot.tv_nsec;
wc.version = version;
// 更新guest的wallclock
kvm_write_guest(kvm, wall_clock, &wc, sizeof(wc)); // 将wc即host boot time的内容写入guest的wallclock中
...
}
kvm_write_wall_clock()函数执行完毕之后,guest可以在全局变量wall_clock中找到host系统的boot time.
内核更新wallclock
void getboottime64(struct timespec64 *ts)
{
struct timekeeper *tk = &tk_core.timekeeper;
ktime_t t = ktime_sub(tk->offs_real, tk->offs_boot); // 做时间校准 tk->offs_real- tk->offs_boot
*ts = ktime_to_timespec64(t); // 转换一下时间格式
}
重要语句为struct timekeeper *tk = &tk_core.timekeeper;而tk_core的定义为:
/*
* The most important data for readout fits into a single 64 byte
* cache line.
*/
static struct {
seqcount_t seq;
struct timekeeper timekeeper;
} tk_core ____cacheline_aligned = {
.seq = SEQCNT_ZERO(tk_core.seq),
};
所以tk_core是一个结构体变量, 存储于静态区,且同时只能有一个cpu访问该变量.
getboottime64()读取tk_core.timekeeper的offs_real和offs_boot内容,那么tk_core.timekeeper的内容在哪里设置的呢?在内核代码中找到了更新tk->offs_boot内容的代码:
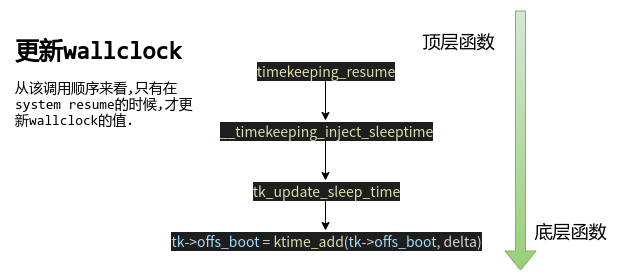
static inline void tk_update_sleep_time(struct timekeeper *tk, ktime_t delta)
{
tk->offs_boot = ktime_add(tk->offs_boot, delta); // tk->offs_boot += delta
/*
* Timespec representation for VDSO update to avoid 64bit division
* on every update.
* VDSO: 有些syscall使用很频繁,但每次syscall都要进行从用户态到内核态的切换,开销很大,就将此类syscall的结果存储在
* 一个共享区域中,每次syscall直接读取结果即可,降低了开销
* VDSO的全称为: virtual dynamic share object
*/
tk->monotonic_to_boot = ktime_to_timespec64(tk->offs_boot); // monotonic_to_boot是offs_boot的VDSO形式
// 是为了加速访问offs_boot
}
tk_update_sleep_time()的核心语句为tk->offs_boot = ktime_add(tk->offs_boot, delta);,delta是什么,从哪里来,需要在内核代码中查找tk_update_sleep_time()的调用位置和参数意义.
static void __timekeeping_inject_sleeptime(struct timekeeper *tk,
const struct timespec64 *delta)
{
...
// 设置tk中的CLOCK_REALTIME时间,并记录误差
tk_xtime_add(tk, delta); // 该函数内容为: tk->xtime_sec += delta->tv_sec;
// tk->tkr_mono.xtime_nsec += delta->tv_nsec << tk->tkr_mono.shift;
// xtime_sec: 以秒为单位的当前CLOCK_REALTIME时间
// tkr: timekeeping read, 用于读出时间的结构体.
// tkr_mono.xtime_nsec 读出时间肯定存在误差, xtime_nsec是读出时间的ns级误差
...
tk_update_sleep_time(tk, timespec64_to_ktime(*delta));
...
}
在__timekeeping_inject_sleeptime()中还是看不到delta的取值,继续找.
void timekeeping_resume(void)
{
struct timekeeper *tk = &tk_core.timekeeper;
struct clocksource *clock = tk->tkr_mono.clock;
unsigned long flags;
struct timespec64 ts_new, ts_delta;
u64 cycle_now, nsec;
bool inject_sleeptime = false;
read_persistent_clock64(&ts_new); // 读取新的wallclock到ts_new
clockevents_resume(); // 继续时钟事件
clocksource_resume(); // 继续时钟源
raw_spin_lock_irqsave(&timekeeper_lock, flags);
write_seqcount_begin(&tk_core.seq);
/*
* After system resumes, we need to calculate the suspended time and
* compensate it for the OS time. There are 3 sources that could be
* used: Nonstop clocksource during suspend, persistent clock and rtc
* device.
*
* One specific platform may have 1 or 2 or all of them, and the
* preference will be:
* suspend-nonstop clocksource -> persistent clock -> rtc
* The less preferred source will only be tried if there is no better
* usable source. The rtc part is handled separately in rtc core code.
*/
cycle_now = tk_clock_read(&tk->tkr_mono); // 获得当前时间
nsec = clocksource_stop_suspend_timing(clock, cycle_now); // 获得suspend的总时间
if (nsec > 0) {
ts_delta = ns_to_timespec64(nsec);
inject_sleeptime = true;
} else if (timespec64_compare(&ts_new, &timekeeping_suspend_time) > 0) {
ts_delta = timespec64_sub(ts_new, timekeeping_suspend_time);
inject_sleeptime = true;
}
if (inject_sleeptime) {
suspend_timing_needed = false;
__timekeeping_inject_sleeptime(tk, &ts_delta); // 原来delta指的是suspend的时间
}
}
我们一路追溯的delta原来是suspend的时间,画出回溯图:
内核初始化wallclock
现在我们知道,内核如何获取wallclock,是靠x86_platform.get_wallclock,我们也知道,内核如何更新wallclock,是在系统suspend之后,resume之前,利用__timekeeping_inject_sleeptime()修改tk_core的内容,修改了wallclock.
但是,系统初始化时,wallclock肯定就被设置了,那么wallclock是如何被初始化的呢?猜测在timekeeping_init相关的函数中.
void __init timekeeping_init(void)
{
...
read_persistent_wall_and_boot_offset(&wall_time, &boot_offset); // 读取walltime和bootOffset到这俩变量
...
}
void __weak __init
read_persistent_wall_and_boot_offset(struct timespec64 *wall_time,
struct timespec64 *boot_offset)
{
read_persistent_clock64(wall_time); // 读取walltime
*boot_offset = ns_to_timespec64(local_clock());
}
/* not static: needed by APM */
void read_persistent_clock64(struct timespec64 *ts)
{
x86_platform.get_wallclock(ts);
}
是不是很熟悉,x86_platform.get_wallclock(ts);在kvm中,x86_platform.get_wallclock = kvm_get_wallclock,在host上,x86_platform.get_wallclock = vrtc_get_time.
void vrtc_get_time(struct timespec64 *now)
{
u8 sec, min, hour, mday, mon;
unsigned long flags;
u32 year;
spin_lock_irqsave(&rtc_lock, flags);
while ((vrtc_cmos_read(RTC_FREQ_SELECT) & RTC_UIP))
cpu_relax();
sec = vrtc_cmos_read(RTC_SECONDS);
min = vrtc_cmos_read(RTC_MINUTES);
hour = vrtc_cmos_read(RTC_HOURS);
mday = vrtc_cmos_read(RTC_DAY_OF_MONTH);
mon = vrtc_cmos_read(RTC_MONTH);
year = vrtc_cmos_read(RTC_YEAR);
spin_unlock_irqrestore(&rtc_lock, flags);
/* vRTC YEAR reg contains the offset to 1972 */
year += 1972;
pr_info("vRTC: sec: %d min: %d hour: %d day: %d "
"mon: %d year: %d\n", sec, min, hour, mday, mon, year);
now->tv_sec = mktime64(year, mon, mday, hour, min, sec);
now->tv_nsec = 0;
}
可以看到,walltime的值包含了年月日时分秒,读取自rtc_cmos时钟中.
那么,结论就来了,guest的kvmclock的wallclock来自于RTC时钟, 且该wallclock由所有vcpu共享,如果vcpu想获得wallclock,就得写属于自己的msr_wall_clock.每当wallclock的内容更新,所有vcpu都能读到最新wallclock,而不是只有写msr_wall_clock的那个vcpu可以读到.
systemTime的初始化
从kvmclock驱动角度来看,在kvmclock_init()中,,就将vcpu0和其余vcpu的vpti结构的物理地址,通过write msr写到了各自的system_time_msr中.
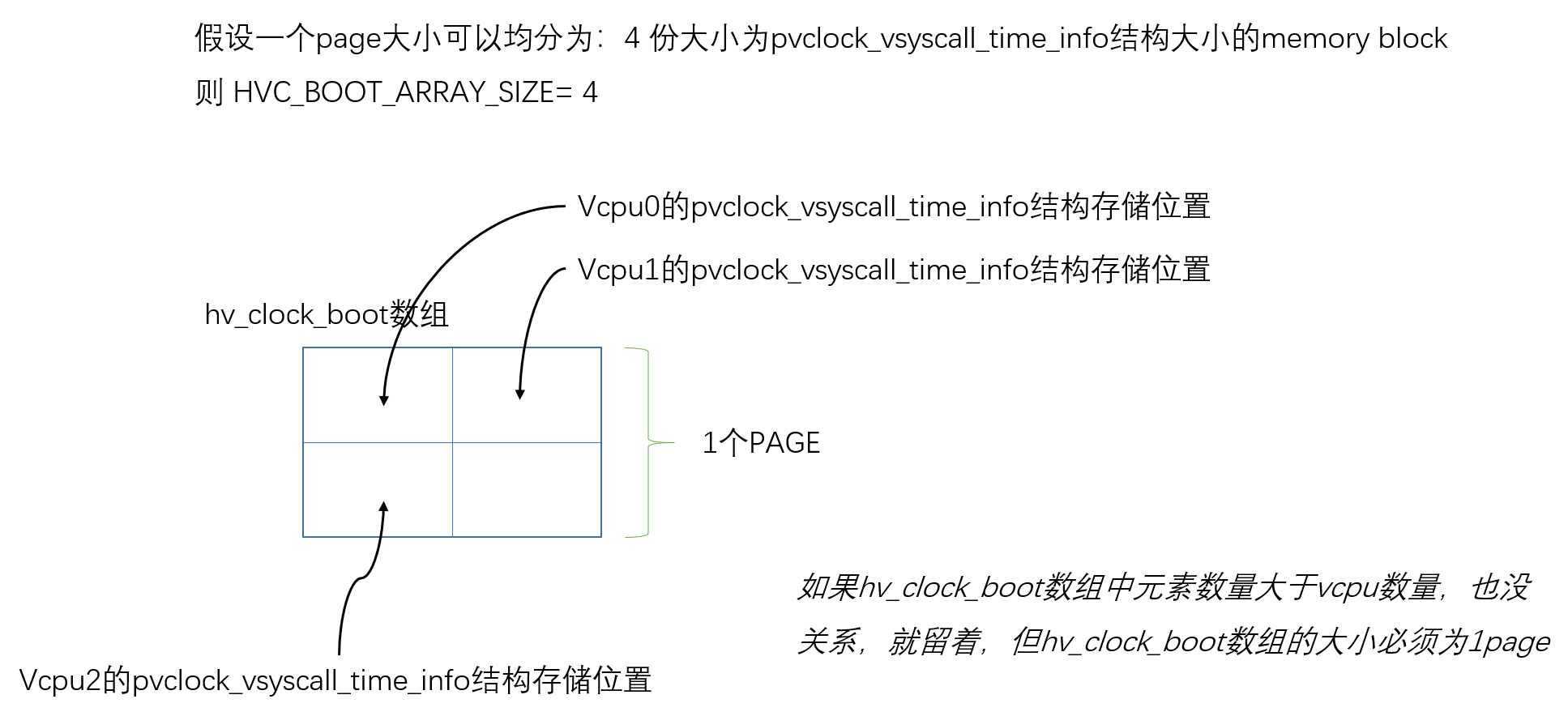
static DEFINE_PER_CPU(struct pvclock_vsyscall_time_info *, hv_clock_per_cpu);
#define HVC_BOOT_ARRAY_SIZE \
(PAGE_SIZE / sizeof(struct pvclock_vsyscall_time_info)) // 表示一个page能放多少个pvti结构
static struct pvclock_vsyscall_time_info
hv_clock_boot[HVC_BOOT_ARRAY_SIZE] __bss_decrypted __aligned(PAGE_SIZE); // pvti结构数组
void __init kvmclock_init(void)
{
...
// 获得msr_system_time和msr_wall_clock
msr_kvm_system_time = MSR_KVM_SYSTEM_TIME_NEW;
msr_kvm_wall_clock = MSR_KVM_WALL_CLOCK_NEW;
...
this_cpu_write(hv_clock_per_cpu, &hv_clock_boot[0]); // 将pvti结构数组中的第一个元素地址给hv_clock_per_cpu
kvm_register_clock("primary cpu clock"); // 将hv_clock_per_cpu的物理地址写入对应system_time_msr
pvclock_set_pvti_cpu0_va(hv_clock_boot); // pvti_cpu0_va = hv_clock_boot, 将hv_clock_boot地址作为cpu0的pvti地址
#ifdef CONFIG_X86_LOCAL_APIC
x86_cpuinit.early_percpu_clock_init = kvm_setup_secondary_clock; // 在smp_init中,调用kvm_register_clock初始化除cpu0以外的cpu时钟, 也因此将各自的hv_clock_per_cpu的物理地址传入了对应的system_time_msr
#endif
...
clocksource_register_hz(&kvm_clock, NSEC_PER_SEC);// 注册1GHz的kvmclock作为一个clocksource
}
static void kvm_setup_secondary_clock(void)
{
kvm_register_clock("secondary cpu clock");
}
static void kvm_register_clock(char *txt)
{
struct pvclock_vsyscall_time_info *src = this_cpu_hvclock();
u64 pa;
if (!src)
return;
pa = slow_virt_to_phys(&src->pvti) | 0x01ULL; // 确保pvti结构的bit0为1
wrmsrl(msr_kvm_system_time, pa); // 将该cpu的pvti结构的物理地址通过写msr的方式写入对应msr_kvm_system_time
pr_info("kvm-clock: cpu %d, msr %llx, %s", smp_processor_id(), pa, txt);
}
现在我们知道了,在kvmclock_init()中,会用写msr的方式,将各cpu的pvti结构的物理地址写入各自对应的system_time_msr, 这里要追溯两条线索:
一条线索向上,找出在何时调用kvmclock_init()进而将cpu0的pvti结构的物理地址写入对应msr,以及何时调用x86_cpuinit.early_percpu_clock_init,将其余cpu的pvti结构的物理地址写入对应msr.
另一条线索向下,当guest kernel中发生写msr时,会导致wrmsr_vmexit,研究在该vmexit中,会怎样处理对应msr.
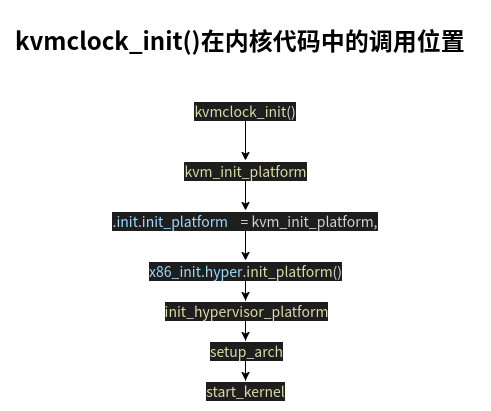
可以看到,在guest启动内核时就调用了kvmclock_init(),将vcpu0的pvti结构的物理地址写入了对应msr, 并注册了将其余vcpu的pvti结构的物理地址写入对应msr的回调函数kvm_setup_secondary_clock.
接下来看何时调用x86_cpuinit.early_percpu_clock_init.
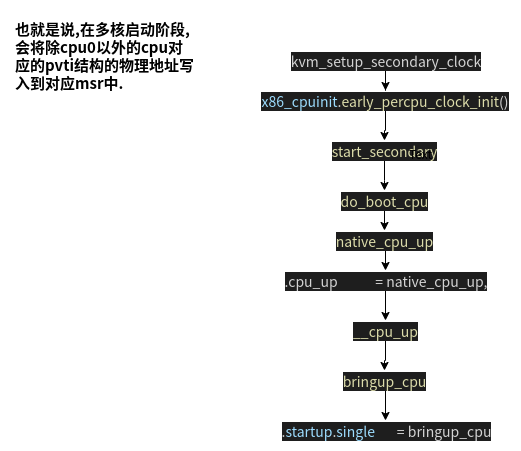
至此,所有vcpu的pvti的物理地址写入msr路径已经搞清楚,接下来看另一条线索,即当写msr动作发生时,触发vmexit,在handle_wrmsr中如何处理system_time. 与wallclock类似,也经历了以下调用过程.
handle_wrmsr=>kvm_set_msr=>kvm_x86_ops->set_msr=>vmx_set_msr=>kvm_set_msr_common
int kvm_set_msr_common(struct kvm_vcpu *vcpu, struct msr_data *msr_info)
{
...
case MSR_KVM_SYSTEM_TIME_NEW:
case MSR_KVM_SYSTEM_TIME: {
struct kvm_arch *ka = &vcpu->kvm->arch;
kvmclock_reset(vcpu); // 将该vcpu的pv_time_enabled标志置为false
// 如果是vcpu0, 那么就将tmp设置为表示是否使用的旧的kvmclock
if (vcpu->vcpu_id == 0 && !msr_info->host_initiated) { // host_initiated在handle_wrmsr()中会被置false
bool tmp = (msr == MSR_KVM_SYSTEM_TIME);
// 如果没有使用旧的kvmclock,则发出KVM_REQ_MASTERCLOCK_UPDATE请求
if (ka->boot_vcpu_runs_old_kvmclock != tmp)
kvm_make_request(KVM_REQ_MASTERCLOCK_UPDATE, vcpu);
ka->boot_vcpu_runs_old_kvmclock = tmp;
}
// 将该vcpu的pvti的物理地址值赋值给该vpcu的arch.time,并发出KVM_REQ_GLOBAL_CLOCK_UPDATE请求
vcpu->arch.time = data;
kvm_make_request(KVM_REQ_GLOBAL_CLOCK_UPDATE, vcpu);
/* we verify if the enable bit is set... */
if (!(data & 1)) // 确保pvti的bit0不为0,如果为0,将不使用kvmclock
break;
if (kvm_gfn_to_hva_cache_init(vcpu->kvm,
&vcpu->arch.pv_time, data & ~1ULL,
sizeof(struct pvclock_vcpu_time_info)))
vcpu->arch.pv_time_enabled = false;
else
vcpu->arch.pv_time_enabled = true;
break;
}
}
即,如果运行的是vcpu0,且是否使用旧的kvmclock msr与当前的boot_vcpu_runs_old_kvmclock标志不一致,那么一定是出了一些什么问题,需要校准MASTERCLOCK,发出KVM_REQ_MASTERCLOCK_UPDATE请求.然后进行普通vcpu的操作.
普通vcpu的操作: 如果运行的是其它vcpu,那么只需要将该vcpu的pvti的物理地址值赋值给该vcpu的arch.time,并发出KVM_REQ_GLOBAL_CLOCK_UPDATE请求(也就是说,vcpu0有可能连续发出两个REQUEST).之后根据kvm_gfn_to_hva_cache_init的结果将pv_time_enabled置为true或false.看一下kvm_gfn_to_hva_cache_init函数.
int kvm_gfn_to_hva_cache_init(struct kvm *kvm, struct gfn_to_hva_cache *ghc,
gpa_t gpa, unsigned long len)
{
struct kvm_memslots *slots = kvm_memslots(kvm); //为vcpu->arch.pv_time从memory中分配一些slots
return __kvm_gfn_to_hva_cache_init(slots, ghc, gpa, len); // 将vcpu->arch.pv_time的cache初始化,赋值,检查有效性
}
static int __kvm_gfn_to_hva_cache_init(struct kvm_memslots *slots,
struct gfn_to_hva_cache *ghc,
gpa_t gpa, unsigned long len)
{
int offset = offset_in_page(gpa); // 获取pvti的物理地址在page中的offset
gfn_t start_gfn = gpa >> PAGE_SHIFT; // 获取pvti的物理地址的起始guest frame number
gfn_t end_gfn = (gpa + len - 1) >> PAGE_SHIFT; // 获取pvti的物理地址的终止guest frame number
gfn_t nr_pages_needed = end_gfn - start_gfn + 1; // 所需的page数量
gfn_t nr_pages_avail;
int r = start_gfn <= end_gfn ? 0 : -EINVAL; // 正常情况下r==0
ghc->gpa = gpa;
ghc->generation = slots->generation; // slots的代数,用于分辨存储的内容为第几代
ghc->len = len;
ghc->hva = KVM_HVA_ERR_BAD;
/*
* If the requested region crosses two memslots, we still
* verify that the entire region is valid here.
*/
while (!r && start_gfn <= end_gfn) { // 确保申请的slots有效
ghc->memslot = __gfn_to_memslot(slots, start_gfn);
ghc->hva = gfn_to_hva_many(ghc->memslot, start_gfn,
&nr_pages_avail); // 为存放pvti的缓存分配对应的host 虚拟地址
if (kvm_is_error_hva(ghc->hva))
r = -EFAULT;
start_gfn += nr_pages_avail;
}
/* Use the slow path for cross page reads and writes. */
if (!r && nr_pages_needed == 1)
ghc->hva += offset;
else
ghc->memslot = NULL;
return r; // 正常情况下return0
}
可以看出,kvm_gfn_to_hva_cache_init(vcpu->kvm,
&vcpu->arch.pv_time, data & ~1ULL,
sizeof(struct pvclock_vcpu_time_info)) 为vcpu->arch.pv_time申请了cache空间(对应host的虚拟地址),将pvti的物理地址写入了该cache的gpa字段.
所以,在分配host虚拟地址成功的情况下,vcpu->arch.pv_time_enabled肯定为true.
综上,在各vcpu启动后,将各vcpu的pvti结构的物理地址写入msr_system_time_i,并开辟缓存空间,用于打通host和guest.
各vcpu的pvti结构只需要一次wrmsr便可与host虚拟地址关联,之后无需wrmsr,host不定期写入pvti的最新值.
guest从pvti结构读取system time
guest从pvti结构读取system time的触发点为上面提到的3种request:
KVM_REQ_MASTERCLOCK_UPDATE
KVM_REQ_GLOBAL_CLOCK_UPDATE
KVM_REQ_CLOCK_UPDATE
那么, guest kernel中什么时候发出这3种REQUEST呢?逐个来看.
三大更新时间请求的触发点
KVM_REQ_MASTERCLOCK_UPDATE
- 当masterclock被使能,就一直发出KVM_REQ_MASTERCLOCK_UPDATE请求,以更新masterclock. 这样情况的代码在kvm_track_tsc_matching中.
masterclock何时可以被使能:
- host clocksource必须为tsc
- vcpus必须有matched tsc,即vcpus的v_tsc必须与host_tsc频率一直
调用路径一共有2条:
第一条为:(由底层函数向顶层函数追溯)
kvm_track_tsc_matching => kvm_write_tsc => kvm_set_msr_common写MSR_IA32_TSC
即在guest os运行过程中,如果出现kvm_set_msr_common(MSR_IA32_TSC), 且满足masterclock使能条件,且masterclock使能,则发出KVM_REQ_MASTERCLOCK_UPDATE请求
第二条为:(由底层函数向顶层函数追溯)
kvm_track_tsc_matching => kvm_write_tsc => kvm_arch_vcpu_postcreate => kvm_vm_ioctl_create_vcpu
即在创建vcpu时,满足masterclock使能条件,且masterclock使能,则发出KVM_REQ_MASTERCLOCK_UPDATE请求.
-
写MSR_KVM_SYSTEM_TIME/MSR_KVM_SYSTEM_TIME_NEW时,如果使用的是新版kvmclock,即写的是MSR_KVM_SYSTEM_TIME_NEW, 则发出KVM_REQ_MASTERCLOCK_UPDATE.这是systemTime的初始化期间的一段.
-
在pvclock_gtod_update_fn中,对所有vcpu发出了KVM_REQ_MASTERCLOCK_UPDATE.而pvclock_gtod_update_fn的调用路径为:
static DECLARE_WORK(pvclock_gtod_work, pvclock_gtod_update_fn);
/*
* Notification about pvclock gtod data update.
*/
static int pvclock_gtod_notify(struct notifier_block *nb, unsigned long unused,
void *priv)
{
struct pvclock_gtod_data *gtod = &pvclock_gtod_data;
struct timekeeper *tk = priv;
update_pvclock_gtod(tk);
/* disable master clock if host does not trust, or does not
* use, TSC based clocksource.
*/
if (!gtod_is_based_on_tsc(gtod->clock.vclock_mode) &&
atomic_read(&kvm_guest_has_master_clock) != 0) // guest clocksource从TSC变为了非TSC时
queue_work(system_long_wq, &pvclock_gtod_work); // 将pvclock_gtod_work放入工作队列
return 0;
}
static struct notifier_block pvclock_gtod_notifier = {
.notifier_call = pvclock_gtod_notify,
};
int kvm_arch_init(void *opaque)
{
pvclock_gtod_register_notifier(&pvclock_gtod_notifier); // 将pvclock_gtod_notifier注册为一个时间更新listener,每当host更新时间, 就会调用pvclock_gtod_notifier进而调用pvclock_gtod_notify
}
即当host更新时间,且kvm发现guest的clocksource从TSC变为非TSC时,发出KVM_REQ_MASTERCLOCK_UPDATE请求.
4.在kvm_arch_hardware_enable中,发现guest tsc发生了倒退,那么向所有vcpu发出KVM_REQ_MASTERCLOCK_UPDATE请求.
KVM_REQ_GLOBAL_CLOCK_UPDATE
-
在kvmclock驱动初始化时,kvmclock_init()中的kvm_register_clock触发wrmsr进而调用kvm_set_msr_common写MSR_KVM_SYSTEM_TIME/MSR_KVM_SYSTEM_TIME_NEW, 发出KVM_REQ_GLOBAL_CLOCK_UPDATE请求
-
在做从vcpu到pcpu(物理cpu)的迁移时,如果guest的tsc不一致,则需要发KVM_REQ_GLOBAL_CLOCK_UPDATE请求.
KVM_REQ_CLOCK_UPDATE
-
kvm_gen_update_masterclock中,对所有vcpu发出KVM_REQ_CLOCK_UPDATE请求.而kvm_gen_update_masterclock为KVM_REQ_MASTERCLOCK_UPDATE请求的handler.
-
在kvmclock_update_fn函数中对所有vcpu发出KVM_REQ_CLOCK_UPDATE请求,kvmclock_update_fn的调用顺序为:
kvm_arch_init_vm() { // 初始化延时作业, 将kvmclock_update_fn注册为kvm->arch.kvmclock_update_work的回调函数 INIT_DELAYED_WORK(&kvm->arch.kvmclock_update_work, kvmclock_update_fn); // 初始化延时作业,将kvmclock_sync_fn注册为kvm->arch.kvmclock_sync_work的回调函数 INIT_DELAYED_WORK(&kvm->arch.kvmclock_sync_work, kvmclock_sync_fn); } static void kvmclock_sync_fn(struct work_struct *work) { // 立即调用kvmclock_update_work->kvmclock_update_fn schedule_delayed_work(&kvm->arch.kvmclock_update_work, 0); schedule_delayed_work(&kvm->arch.kvmclock_sync_work, KVMCLOCK_SYNC_PERIOD); // 300 s后重新调用kvmclock_sync_work->kvmclock_sync_fn } static void kvmclock_update_fn(struct work_struct *work) { kvm_for_each_vcpu(i, vcpu, kvm) { kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); // kvm_guest_time_update() kvm_vcpu_kick(vcpu); // kick a vcpu to sleep. or make a guest mode vcpu into host kernel mode. } }即在kvmclock的同步函数中定义了立即作业(更新kvmclock),和延时作业(同步kvmclock).也就是说,kvm第一次调用同步kvmclock函数后,每300s更新和同步一次kvmclock,每次更新kvmclock时都发出KVM_REQ_CLOCK_UPDATE请求.
-
kvm_gen_kvmclock_update中,对当前vcpu发出KVM_REQ_CLOCK_UPDATE请求,100ms后调用更新kvmclock函数kvmclock_update_fn,后者对所有vcpu发出KVM_REQ_CLOCK_UPDATE请求.kvm_gen_kvmclock_update是KVM_REQ_GLOBAL_CLOCK_UPDATE请求的handler.
static void kvm_gen_kvmclock_update(struct kvm_vcpu *v) { struct kvm *kvm = v->kvm; kvm_make_request(KVM_REQ_CLOCK_UPDATE, v); // 立即发送KVM_REQ_CLOCK_UPDATE请求 schedule_delayed_work(&kvm->arch.kvmclock_update_work, KVMCLOCK_UPDATE_DELAY); // 100ms后触发kvmclock_update_fn } -
kvm_arch_vcpu_load中,如果检测到了外部tsc_offset_adjustment,就发出KVM_REQ_CLOCK_UPDATE请求.即在切换到特定vcpu时,做检测并决定是否发出KVM_REQ_CLOCK_UPDATE请求.
-
kvm_set_guest_paused中,会发出KVM_REQ_CLOCK_UPDATE请求,kvm_set_guest_paused告诉guest kernel,该guest kernel已经被kvm停止了.即在guest kernel pause时,发出KVM_REQ_CLOCK_UPDATE请求.
-
在qemu发出KVM_SET_CLOCK的ioctl时,向所有vcpu发出KVM_REQ_CLOCK_UPDATE请求.qemu设置时钟时,更新guest时钟是理所应当的事情.
-
在__kvmclock_cpufreq_notifier中,对所有vcpu发出了KVM_REQ_CLOCK_UPDATE.因为该函数为cpu频率变化时的回调函数,当host cpu频率变化时,应该重新设置guest的时间.
-
在vmexit时,如果guest的tsc总是追上host的tsc,说明guest的tsc频率高于host的tsc频率,需要重新校准guest的时间.因此向当前vcpu发出KVM_REQ_CLOCK_UPDATE.
-
kvm_arch_hardware_enable,如果host tsc不稳定,就对所有vcpu发出KVM_REQ_CLOCK_UPDATE请求.而kvm_arch_hardware_enable的调用路径为:
kvm_arch_hardware_enable => hardware_enable_nolock => kvm_starting_cpu
=> kvm_resume
也就是说,在kvm启动vcpu和恢复vcpu的运行时,都需要发出KVM_REQ_CLOCK_UPDATE以调整时间.
三大请求的处理
在确定了各更新时间的请求的triger点之后,接下来看一下这些请求的handler究竟针对请求做了哪些处理.
3种请求均在vcpu_enter_guest(),即进入non-root之前做处理.
KVM_REQ_MASTERCLOCK_UPDATE
static void kvm_gen_update_masterclock(struct kvm *kvm)
{
#ifdef CONFIG_X86_64
int i;
struct kvm_vcpu *vcpu;
struct kvm_arch *ka = &kvm->arch;
spin_lock(&ka->pvclock_gtod_sync_lock);
kvm_make_mclock_inprogress_request(kvm); // 发出KVM_REQ_MCLOCK_INPROGRESS请求,让所有vcpu无法进入guest
/* no guest entries from this point */
pvclock_update_vm_gtod_copy(kvm);//确认guest能否使用master_clock(用于vcpu之间的时间同步)
kvm_for_each_vcpu(i, vcpu, kvm)
kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); // 向所有vcpu发出KVM_REQ_CLOCK_UPDATE请求
/* guest entries allowed */
kvm_for_each_vcpu(i, vcpu, kvm)
kvm_clear_request(KVM_REQ_MCLOCK_INPROGRESS, vcpu); // 清除KVM_REQ_MCLOCK_INPROGRESS请求,让所有vcpu进入guest
spin_unlock(&ka->pvclock_gtod_sync_lock);
#endif
}
static void pvclock_update_vm_gtod_copy(struct kvm *kvm)
{
#ifdef CONFIG_X86_64
struct kvm_arch *ka = &kvm->arch;
int vclock_mode;
bool host_tsc_clocksource, vcpus_matched;
vcpus_matched = (ka->nr_vcpus_matched_tsc + 1 ==
atomic_read(&kvm->online_vcpus)); // 表示vcpus的tsc频率是否match
/*
* If the host uses TSC clock, then passthrough TSC as stable
* to the guest.
*/
host_tsc_clocksource = kvm_get_time_and_clockread(
&ka->master_kernel_ns,
&ka->master_cycle_now); // 如果host使用tsc,host_tsc_clocksource为true
// master_kernel_ns为master中记录的host boot以来的时间
// master_cycle_now为master中记录的host的当前tsc取值
ka->use_master_clock = host_tsc_clocksource && vcpus_matched
&& !ka->backwards_tsc_observed
&& !ka->boot_vcpu_runs_old_kvmclock; // backwards_tsc_observed表示是否观察到tsc倒退现象
// boot_vcpu_runs_old_kvmclock表示kvmclock使用旧的MSR
if (ka->use_master_clock)
atomic_set(&kvm_guest_has_master_clock, 1); // 如果use_master_clock为1,就将kvm_guest_has_master_clock设为1
vclock_mode = pvclock_gtod_data.clock.vclock_mode;
trace_kvm_update_master_clock(ka->use_master_clock, vclock_mode,
vcpus_matched);
#endif
}
可以看到,对于KVM_REQ_MASTERCLOCK_UPDATE请求,kvm做了两件事情,一件事情是确认guest能否使用master_clock(用于vcpu之间的时间同步),另一件事情是对所有vcpu发出了更基本的请求,即KVM_REQ_CLOCK_UPDATE请求(在KVM_REQ_CLOCK_UPDATE的处理中说明).
KVM_REQ_GLOBAL_CLOCK_UPDATE
static void kvm_gen_kvmclock_update(struct kvm_vcpu *v)
{
struct kvm *kvm = v->kvm;
kvm_make_request(KVM_REQ_CLOCK_UPDATE, v); // 立即发送KVM_REQ_CLOCK_UPDATE请求
schedule_delayed_work(&kvm->arch.kvmclock_update_work,
KVMCLOCK_UPDATE_DELAY); // 100ms后触发kvmclock_update_fn
}
对于KVM_REQ_GLOBAL_CLOCK_UPDATE请求, kvm首先对当前vcpu发送了更基本请求,即KVM_REQ_CLOCK_UPDATE请求,在发出请求后100ms,调用kvmclock_update_fn,kvmclock_update_fn的作用是对所有vcpu发出KVM_REQ_CLOCK_UPDATE请求.
也就是说,KVM_REQ_GLOBAL_CLOCK_UPDATE的处理为:
- 向当前vcpu发送KVM_REQ_CLOCK_UPDATE请求
- 向所有vcpu发送KVM_REQ_CLOCK_UPDATE请求,并kick所有vcpu.
KVM_REQ_CLOCK_UPDATE
从上面的两种请求的处理可以看到,上面两种请求都以来基础请求KVM_REQ_CLOCK_UPDATE,因此KVM_REQ_CLOCK_UPDATE的处理非常重要.
static int kvm_guest_time_update(struct kvm_vcpu *v)
{
unsigned long flags, tgt_tsc_khz;
struct kvm_vcpu_arch *vcpu = &v->arch;
struct kvm_arch *ka = &v->kvm->arch;
s64 kernel_ns;
u64 tsc_timestamp, host_tsc;
u8 pvclock_flags;
bool use_master_clock;
kernel_ns = 0;
host_tsc = 0;
/*
* If the host uses TSC clock, then passthrough TSC as stable
* to the guest.
*/
spin_lock(&ka->pvclock_gtod_sync_lock);
use_master_clock = ka->use_master_clock;
if (use_master_clock) { // 如果host使用tsc clock,直接将tsc传递给guest即可
host_tsc = ka->master_cycle_now; // 将master的cycle_now记为host_tsc (tsc数)
kernel_ns = ka->master_kernel_ns; // 将master的kernel_ns记为kernel_ns (master的kernel 纳秒数) host boot以来的时间
}
spin_unlock(&ka->pvclock_gtod_sync_lock);
/* Keep irq disabled to prevent changes to the clock */
local_irq_save(flags);
tgt_tsc_khz = __this_cpu_read(cpu_tsc_khz); // 读取当前vcpu的tsc值
if (unlikely(tgt_tsc_khz == 0)) { // 如果当前vcpu的tsc值无效,则发出KVM_REQ_CLOCK_UPDATE请求
local_irq_restore(flags);
kvm_make_request(KVM_REQ_CLOCK_UPDATE, v);
return 1;
}
if (!use_master_clock) {//如果host不使用tsc clock,
host_tsc = rdtsc(); // 通过手动读取tsc的值获得host的tsc值
kernel_ns = ktime_get_boottime_ns(); // 获得host kernel boot以来的时间
}
tsc_timestamp = kvm_read_l1_tsc(v, host_tsc); // 将host tsc的值通过scale和offset得到当前时间戳
/*
* We may have to catch up the TSC to match elapsed wall clock
* time for two reasons, even if kvmclock is used.
* 1) CPU could have been running below the maximum TSC rate
* 2) Broken TSC compensation resets the base at each VCPU
* entry to avoid unknown leaps of TSC even when running
* again on the same CPU. This may cause apparent elapsed
* time to disappear, and the guest to stand still or run
* very slowly.
*/
if (vcpu->tsc_catchup) {
u64 tsc = compute_guest_tsc(v, kernel_ns); // 通过host boot以来的时间,计算理论guest tsc
if (tsc > tsc_timestamp) { // 如果理论guest tsc比经过调整的host tsc大
adjust_tsc_offset_guest(v, tsc - tsc_timestamp);//将offset调整为原offset+tsc-tsc_timestap
tsc_timestamp = tsc; // 将tsc赋值给当前时间戳,使其保持一致
}
}
local_irq_restore(flags);
/* With all the info we got, fill in the values */
if (kvm_has_tsc_control) // 如果支持tsc scaling
tgt_tsc_khz = kvm_scale_tsc(v, tgt_tsc_khz); // 将当前vcpu的tsc值做scale
if (unlikely(vcpu->hw_tsc_khz != tgt_tsc_khz)) { // 如果当前vcpu的tsc与vcpu记录的硬件tsc值不同,则调整tsc scale值
kvm_get_time_scale(NSEC_PER_SEC, tgt_tsc_khz * 1000LL,
&vcpu->hv_clock.tsc_shift,
&vcpu->hv_clock.tsc_to_system_mul);
vcpu->hw_tsc_khz = tgt_tsc_khz;
}
// 向pvti类型的hv_clock赋值
vcpu->hv_clock.tsc_timestamp = tsc_timestamp;
vcpu->hv_clock.system_time = kernel_ns + v->kvm->arch.kvmclock_offset;
vcpu->last_guest_tsc = tsc_timestamp;
/* If the host uses TSC clocksource, then it is stable */
pvclock_flags = 0;
if (use_master_clock)
pvclock_flags |= PVCLOCK_TSC_STABLE_BIT;
vcpu->hv_clock.flags = pvclock_flags;
if (vcpu->pv_time_enabled) // 如果使用半虚拟化(kvmclock)
kvm_setup_pvclock_page(v); // 就将pv_clock的内容拷贝到pv_clock
if (v == kvm_get_vcpu(v->kvm, 0))
kvm_hv_setup_tsc_page(v->kvm, &vcpu->hv_clock);
return 0;
}
kvm_guest_time_update()做了以下几件事情:
- 获取host的tsc value和host kernel boot以来的ns数
- 读取当前vcpu的tsc value
- 经过一系列的校准,将最终时间赋值给vcpu->hv_clock
- 如果vcpu使能了半虚拟化,就调用kvm_setup_pvclock_page
来看kvm_setup_pvclock_page.
static void kvm_setup_pvclock_page(struct kvm_vcpu *v)
{
...
kvm_write_guest_cached(v->kvm, &vcpu->pv_time,
&vcpu->hv_clock,
sizeof(vcpu->hv_clock)); // 将hv_clock的内容赋值到pv_time中去
...
}
这里的pv_time就是之前我们提到的每个vcpu都有1个的pvti结构.将将hv_clock的内容赋值到pv_time中去,即将最新时间更新到vcpu的pvti结构中去.
system time就这样在pvti结构中被更新了.
host对system time的写入
host对system time的写入一般来说有2种情况,同步写入和异步写入.
同步写入指的是周期性更新guest中system time的值,以和host时间保持一致.
异步写入指的是在特殊事件发生时(如guest suspend时),更新guest中system time的值,防止guest中的时间出错.
host对system time的同步写入
kvm通过pvclock_gtod_register_notifier向timekeeper层注册了一个回调pvclock_gtod_notify(在上面的三大请求trigger点的介绍中有提到),每当Host Kernel时钟更新时(即timekeeping_update被调用时),就会调用pvclock_gtod_notify.
static int pvclock_gtod_notify(struct notifier_block *nb, unsigned long unused,
void *priv)
{
struct pvclock_gtod_data *gtod = &pvclock_gtod_data;
struct timekeeper *tk = priv;
update_pvclock_gtod(tk); // 更新pvclock的内容
/* disable master clock if host does not trust, or does not
* use, TSC based clocksource.
*/
if (!gtod_is_based_on_tsc(gtod->clock.vclock_mode) &&
atomic_read(&kvm_guest_has_master_clock) != 0) // clocksource从TSC变为了非TSC时
queue_work(system_long_wq, &pvclock_gtod_work);
return 0;
}
static struct pvclock_gtod_data pvclock_gtod_data;
static void update_pvclock_gtod(struct timekeeper *tk)
{
struct pvclock_gtod_data *vdata = &pvclock_gtod_data;
u64 boot_ns;
boot_ns = ktime_to_ns(ktime_add(tk->tkr_mono.base, tk->offs_boot));
write_seqcount_begin(&vdata->seq);
/* copy pvclock gtod data */
vdata->clock.vclock_mode = tk->tkr_mono.clock->archdata.vclock_mode;
vdata->clock.cycle_last = tk->tkr_mono.cycle_last; //host时间更新时的clocksource的counter读数
vdata->clock.mask = tk->tkr_mono.mask;
vdata->clock.mult = tk->tkr_mono.mult;
vdata->clock.shift = tk->tkr_mono.shift;
vdata->boot_ns = boot_ns; // host时间更新时的s部分,以ns记
vdata->nsec_base = tk->tkr_mono.xtime_nsec; // host时间更新时的wallclock的ns部分
vdata->wall_time_sec = tk->xtime_sec;// host时间更新时的wallclock的s部分
write_seqcount_end(&vdata->seq);
}
pvclock_gtod_notify()完成了2件事情:
- 调用update_pvclock_gtod更新了pvclock_gtod_data
- 检测host的clocksource是否变为了非tsc,如果变了则将作业pvclock_gtod_work入队
static DECLARE_WORK(pvclock_gtod_work, pvclock_gtod_update_fn);
static void pvclock_gtod_update_fn(struct work_struct *work)
{
struct kvm *kvm;
struct kvm_vcpu *vcpu;
int i;
mutex_lock(&kvm_lock);
list_for_each_entry(kvm, &vm_list, vm_list)
kvm_for_each_vcpu(i, vcpu, kvm)
kvm_make_request(KVM_REQ_MASTERCLOCK_UPDATE, vcpu);
atomic_set(&kvm_guest_has_master_clock, 0);
mutex_unlock(&kvm_lock);
}
可以看到pvclock_gtod_work的实际函数pvclock_gtod_update_fn的作用为:
向所有vcpu发出KVM_REQ_MASTERCLOCK_UPDATE,而后者经过层层调用,更新每个vcpu的pvti结构中的时间数据.
也就是说,每当Host Kernel时钟更新时,如果使用master_clock,kvm会更新每个vcpu的pvti时间.内核的代码中使用tk_clock_read读取clocksource当前counter,但是没有发现上下文中有对读取时间的cpu的限制.
host对system time的异步写入
host对system time的异步写入通过qemu实现,利用kvm_vm_ioctl(KVM_SET_CLOCK),与kvm发生交互.
而kvm中,KVM_SET_CLOCK的ioctl的定义如下:
case KVM_SET_CLOCK: {
struct kvm_clock_data user_ns;
u64 now_ns;
r = -EFAULT;
if (copy_from_user(&user_ns, argp, sizeof(user_ns)))
goto out;
r = -EINVAL;
if (user_ns.flags)
goto out;
r = 0;
/*
* TODO: userspace has to take care of races with VCPU_RUN, so
* kvm_gen_update_masterclock() can be cut down to locked
* pvclock_update_vm_gtod_copy().
*/
kvm_gen_update_masterclock(kvm); // 确认guest能否使用masterclock,并向所有vcpu发出时间更新请求
now_ns = get_kvmclock_ns(kvm); // 读取当前cpu的时间
kvm->arch.kvmclock_offset += user_ns.clock - now_ns; // 确认当前cpu和qemu传入的cpu时间的offset
kvm_make_all_cpus_request(kvm, KVM_REQ_CLOCK_UPDATE); // 利用新的offset对所有vcpu的时间进行更新
break;
}
可以看到,kvm_vm_ioctl(KVM_SET_CLOCK)做了以下几件事情:
- 确认guest能否使用masterclock,并向所有vcpu发出时间更新请求
- 读取当前cpu的时间(根据是否使用masterclock,读取时间的方式不同)
- 计算当前cpu和qemu传入的cpu时间的offset
- 利用新的offset对所有vcpu的时间进行更新
host对system time的异步写入依赖qemu和kvm的交互kvm_vm_ioctl(KVM_SET_CLOCK).
masterclock: 由于我们的kvmclock依赖于Host Boot Time和Host TSC两个量,即使Host TSC同步且Guest TSC同步,在pCPU0和pCPU1分别取两者,前者的差值和后者的差值也可能不相等,并且谁大谁小都有可能,从而可能违反kvmclock的单调性。因此,我们通过只使用一份Master Copy,即Master Clock,来解决这个问题。
---update on 6.1 2020-----
由于对pvclock_gtod_data和各vcpu的pvti结构的更新之间的关系不太清楚,特此研究记录.
与各vcpu的pvti结构对应的host虚拟地址的申请
在kvmclock驱动初始化时,kvmclock_init()中的kvm_register_clock触发wrmsr进而调用kvm_set_msr_common写MSR_KVM_SYSTEM_TIME/MSR_KVM_SYSTEM_TIME_NEW.
在kvm_set_msr_common()中最关键的一句话为:
if (kvm_gfn_to_hva_cache_init(vcpu->kvm,
&vcpu->arch.pv_time, data & ~1ULL,
sizeof(struct pvclock_vcpu_time_info))) // 计算出写入gpa为data时,对应的hva.
// 将hva,gpa,内存区域长度,对应的memslot地址,该memslot对应的generation都存入arch.pv_time中
vcpu->arch.pv_time_enabled = false;
else
vcpu->arch.pv_time_enabled = true;
kvm_gfn_to_hva_cache_init的函数原型为:
int kvm_gfn_to_hva_cache_init(struct kvm *kvm, struct gfn_to_hva_cache *ghc,
gpa_t gpa, unsigned long len);
其中,ghc为gfn_to_hva_cache结构体类型,意义为将guest frame number转化成host virtual address的cache.定义为:
struct gfn_to_hva_cache {
u64 generation; // cache的代数
gpa_t gpa; // guest物理地址
unsigned long hva; // host虚拟地址
unsigned long len; //该cache的大小
struct kvm_memory_slot *memslot; // 该cache对应的kvm memslot地址
};
kvm_gfn_to_hva_cache_init()函数的实现为:
int kvm_gfn_to_hva_cache_init(struct kvm *kvm, struct gfn_to_hva_cache *ghc,
gpa_t gpa, unsigned long len)
{
struct kvm_memslots *slots = kvm_memslots(kvm); // slots为整个kvm memslots的地址
return __kvm_gfn_to_hva_cache_init(slots, ghc, gpa, len);
}
static int __kvm_gfn_to_hva_cache_init(struct kvm_memslots *slots,
struct gfn_to_hva_cache *ghc,
gpa_t gpa, unsigned long len)
{
int offset = offset_in_page(gpa); // 页内offset
/* 虽然gpa只是一个地址,但由于从gpa开始,需要len长度的空间,所以存在起始gfn和终点gfn */
gfn_t start_gfn = gpa >> PAGE_SHIFT; // gpa对应的起始gfn(guest frame number)
gfn_t end_gfn = (gpa + len - 1) >> PAGE_SHIFT; // gpa对应的终点gfn
gfn_t nr_pages_needed = end_gfn - start_gfn + 1; // 所需页的数量
gfn_t nr_pages_avail;
int r = start_gfn <= end_gfn ? 0 : -EINVAL; // r判断起始gfn和终点gfn的有效性
/* 将guest物理地址,memslot的代数,所需存储空间的长度,赋值给gfn_to_hva_cache结构 */
ghc->gpa = gpa;
ghc->generation = slots->generation;
ghc->len = len;
ghc->hva = KVM_HVA_ERR_BAD; // 先将host虚拟地址赋值为无效
//-----------------------------下面开始为gpa找对应的hva,存储到赋值给gfn_to_hva_cache结构中去
/*
* If the requested region crosses two memslots, we still
* verify that the entire region is valid here.
*/
while (!r && start_gfn <= end_gfn) { // 如果请求的空间大小横跨2个memslot,需要确定请求空间的有效性
ghc->memslot = __gfn_to_memslot(slots, start_gfn);
ghc->hva = gfn_to_hva_many(ghc->memslot, start_gfn,
&nr_pages_avail);
if (kvm_is_error_hva(ghc->hva))
r = -EFAULT;
start_gfn += nr_pages_avail;
}
/* Use the slow path for cross page reads and writes. */
if (!r && nr_pages_needed == 1)
ghc->hva += offset;
else
ghc->memslot = NULL;
return r;
}
从上面的分析可以看出,以下这段语句的作用为:从kvm_memslots中申请大小为pvclock_vcpu_time_info结构大小的缓存空间,该缓存空间缓存的是物理地址为data中所存地址中指向的内容,该缓存空间对应的host虚拟地址为hva.
kvm_gfn_to_hva_cache_init(vcpu->kvm,
&vcpu->arch.pv_time, data & ~1ULL,
sizeof(struct pvclock_vcpu_time_info))
在kvmclock驱动初始化写MSR_KVM_SYSTEM_TIME/MSR_KVM_SYSTEM_TIME_NEW时导致的kvm_set_msr_common()中,data就是每个vcpu都有的pvti结构.让pvti有了一个host虚拟地址.
向各vcpu的pvti结构对应的host虚拟地址写入时间
先不论时间从哪里来,肯定会向pvti结构写入时间.
static int kvm_guest_time_update(struct kvm_vcpu *v)
{
...
if (vcpu->pv_time_enabled) // 在kvm_set_msr_common中建立pvti的gpa对应的hva时就使能了
kvm_setup_pvclock_page(v);
}
static void kvm_setup_pvclock_page(struct kvm_vcpu *v)
{
...
kvm_write_guest_cached(v->kvm, &vcpu->pv_time,
&vcpu->hv_clock,
sizeof(vcpu->hv_clock)); // 将hv_clock(pvti结构体类型)写到vcpu的gfn_to_hva_cache结构的hva去,即写到了vcpu的pvti中去
}
int kvm_write_guest_cached(struct kvm *kvm, struct gfn_to_hva_cache *ghc,
void *data, unsigned long len)
{
return kvm_write_guest_offset_cached(kvm, ghc, data, 0, len);
}
int kvm_write_guest_offset_cached(struct kvm *kvm, struct gfn_to_hva_cache *ghc,
void *data, unsigned int offset,
unsigned long len)
{
struct kvm_memslots *slots = kvm_memslots(kvm);
int r;
gpa_t gpa = ghc->gpa + offset;
BUG_ON(len + offset > ghc->len);
if (slots->generation != ghc->generation)
__kvm_gfn_to_hva_cache_init(slots, ghc, ghc->gpa, ghc->len);
if (unlikely(!ghc->memslot))
return kvm_write_guest(kvm, gpa, data, len);
if (kvm_is_error_hva(ghc->hva))
return -EFAULT;
r = __copy_to_user((void __user *)ghc->hva + offset, data, len); // 将数据写入gfn_to_hva_cache的hva地址中去
if (r)
return -EFAULT;
mark_page_dirty_in_slot(ghc->memslot, gpa >> PAGE_SHIFT);
return 0;
}
综上,下面这段语句的意义为:
将vcpu的hv_clock(pvti结构类型)数据写入属于该vcpu的pvti对应的host虚拟地址中去.
kvm_write_guest_cached(v->kvm, &vcpu->pv_time,
&vcpu->hv_clock,
sizeof(vcpu->hv_clock));
pv_clock_gtod_data
pv_clock_gtod_data是一个全局变量, kvm会在每个host的tick时更新该变量的内容.
struct pvclock_gtod_data {
seqcount_t seq;
struct { /* extract of a clocksource struct */
int vclock_mode;
u64 cycle_last;
u64 mask;
u32 mult;
u32 shift;
} clock;
u64 boot_ns;
u64 nsec_base;
u64 wall_time_sec;
};
如何更新的呢?
kvm通过pvclock_gtod_register_notifier向timekeeper层注册了一个回调pvclock_gtod_notify,每当Host Kernel时钟更新时(即timekeeping_update被调用时),就会调用pvclock_gtod_notify,进而调用update_pvclock_gtod更新pvclock_gtod_data的值.
static int pvclock_gtod_notify(struct notifier_block *nb, unsigned long unused,
void *priv)
{
struct pvclock_gtod_data *gtod = &pvclock_gtod_data;
struct timekeeper *tk = priv;
update_pvclock_gtod(tk); // 更新pvclock_gtod_data的内容
/* disable master clock if host does not trust, or does not
* use, TSC based clocksource.
*/
if (!gtod_is_based_on_tsc(gtod->clock.vclock_mode) &&
atomic_read(&kvm_guest_has_master_clock) != 0) // clocksource从TSC变为了非TSC时
queue_work(system_long_wq, &pvclock_gtod_work);
return 0;
}
static struct pvclock_gtod_data pvclock_gtod_data;
static void update_pvclock_gtod(struct timekeeper *tk)
{
struct pvclock_gtod_data *vdata = &pvclock_gtod_data;
u64 boot_ns;
boot_ns = ktime_to_ns(ktime_add(tk->tkr_mono.base, tk->offs_boot));
write_seqcount_begin(&vdata->seq);
/* copy pvclock gtod data */
vdata->clock.vclock_mode = tk->tkr_mono.clock->archdata.vclock_mode; // 时钟源类型
vdata->clock.cycle_last = tk->tkr_mono.cycle_last; //host时间更新时的clocksource的counter读数
vdata->clock.mask = tk->tkr_mono.mask;
vdata->clock.mult = tk->tkr_mono.mult;
vdata->clock.shift = tk->tkr_mono.shift;
vdata = boot_ns; // host时间更新时,用来获得当前时间的基础时间,以ns记
vdata->nsec_base = tk->tkr_mono.xtime_nsec; // host时间更新时的wallclock的ns部分
vdata->wall_time_sec = tk->xtime_sec;// host时间更新时的wallclock的s部分
write_seqcount_end(&vdata->seq);
}
pvti结构的数据来源vcpu->hv_clock
目前已知:
- kvm在kvm_guest_time_update()中更新各vcpu的pvti结构时,是将当前时间赋值给该函数中的hv_clock,然后将hv_clock的内容写入到pvti结构中去.
- kvm会在host的每个tick,即每次host更新时间时,将时间相关变量更新到全局变量pvclock_gtod_data中
由此推断,hv_clock肯定跟pvclock_gtod_data有一定的关系.下面寻找他们之间的联系.
首先,在kvm_guest_time_update()中会检查是否使用master_clock即use_master_clock的值,根据该bool值的取值,当前时间的获取方式也不同.
kvm中何时决定use_master_clock的值?暂时不做讨论,这里只需要知道use_master_clock为1时,kvm只使用一份host tsc和guest tsc,其它vcpu复制之.
use_master_clock为True
如果use_master_clock为真,则让:
host_tsc = ka->master_cycle_now;
kernel_ns = ka->master_kernel_ns;
那么 ka->master_cycle_now和ka->master_kernel_ns的意义是什么,何时被赋值的?
在pvclock_update_vm_gtod_copy()中,有对master_cycle_now和master_kernel_ns的赋值,以kvm_get_time_and_clockread()形式呈现,kvm_get_time_and_clockread通过do_monotonic_boot()和pvclock_gtod_data中的值来获得master_kernel_ns的值,意义为自host boot 以来的ns数.
而do_monotonic_boot通过vgettsc=>read_tsc,获得master_cycle_now的值,read_tsc通过对比rdtsc指令和pv_clock_gtod_data->clock.cycle_last的返回值,确定tsc value是否后退,如果后退,则返回pv_clock_gtod_data->clock.cycle_last的值,即上一次读取tsc时的值,如果没有后退,则返回rdtsc指令的结果.总之,master_cycle_now代表当前PCPU上的没有后退的tsc值.
// kvm更新master_kernel_ns和master_cycle_now的函数
static void pvclock_update_vm_gtod_copy(struct kvm *kvm)
{
...
host_tsc_clocksource = kvm_get_time_and_clockread(
&ka->master_kernel_ns,
&ka->master_cycle_now);
}
static bool kvm_get_time_and_clockread(s64 *kernel_ns, u64 *tsc_timestamp)
{
...
return gtod_is_based_on_tsc(do_monotonic_boot(kernel_ns,
tsc_timestamp)); // 用do_monotonic_boot获得master_kernel_ns,master_cycle_now.
}
static int do_monotonic_boot(s64 *t, u64 *tsc_timestamp)
{
struct pvclock_gtod_data *gtod = &pvclock_gtod_data;
unsigned long seq;
int mode;
u64 ns;
do {
seq = read_seqcount_begin(>od->seq);
ns = gtod->nsec_base;
ns += vgettsc(tsc_timestamp, &mode);
ns >>= gtod->clock.shift;
ns += gtod->boot_ns;
} while (unlikely(read_seqcount_retry(>od->seq, seq)));
*t = ns;
return mode;
}
// 因为我们的host基本都用tsc,所以走的case是VCLOCK_TSC
static inline u64 vgettsc(u64 *tsc_timestamp, int *mode)
{
...
case VCLOCK_TSC:
*mode = VCLOCK_TSC;
*tsc_timestamp = read_tsc();
v = (*tsc_timestamp - gtod->clock.cycle_last) &
gtod->clock.mask;
break;
}
static u64 read_tsc(void)
{
u64 ret = (u64)rdtsc_ordered();
u64 last = pvclock_gtod_data.clock.cycle_last;
if (likely(ret >= last))
return ret;
/*
* GCC likes to generate cmov here, but this branch is extremely
* predictable (it's just a function of time and the likely is
* very likely) and there's a data dependence, so force GCC
* to generate a branch instead. I don't barrier() because
* we don't actually need a barrier, and if this function
* ever gets inlined it will generate worse code.
*/
asm volatile ("");
return last;
}
pvclock_update_vm_gtod_copy()只在2个kvm代码的2个地方有引用,1是kvm_arch_init_vm(),2是kvm_gen_update_masterclock().后者在2个地方有引用,1是kvm_arch_vm_ioctl(KVM_SET_CLOCK),2是在每次vcpu_enter_guest()时检查到KVM_REQ_MASTERCLOCK_UPDATE请求时.
也就是说,ka->master_kernel_ns和ka->master_cycle_now会在kvm运行的3个地方更新:
- 初始化虚拟机(guest)时
- 每次进入non-root mode检测到KVM_REQ_MASTERCLOCK_UPDATE请求时
- 在userspace(如qemu)主动发起更新时间的请求时
结论: 如果使用master_clock, host_tsc表示当前PCPU上的无回退的TSC值, kenel_ns表示自host启动以来的ns数.也只有use_master_clock为真时,kvm维护的pvclock_gtod_data的内容才会起作用.
use_master_clock为False
如果use_master_clock为假,则让:
host_tsc = rdtsc();
kernel_ns = ktime_get_boottime_ns();
rdtsc()会直接读取当前PCPU的TSC值
ktime_get_boottime_ns()获取自host boot以来的ns数(利用的是host kernel中的timekeeping结构).
结论: 如果不使用master_clock, host_tsc表示当前PCPU(不保证是否回退)的TSC值,kernel_ns表示自host启动以来的ns数.
TSC校准系数的调整及pvti cache的最终赋值
在获得host_tsc和kernel_ns后,利用kvm_read_l1_tsc获得arch层面的tsc_offset和tsc_scale, 并利用这二者对host_tsc进行调整,赋值给tsc_timestamp,那么tsc_timestamp的意义就非常明显了,即"本次计时的TSC时间戳".
tsc_timestamp = kvm_read_l1_tsc(v, host_tsc);
之后将根据vcpu->tsc_catchup的取值,决定是否对arch层面的tsc_offset和tsc_scale进行调整.如果需要调整,根据上面的host_tsc计算此时tsc的理论值是多少,如果理论值比读到的tsc值大,说明guest的tsc_offset和tsc_scale已经无法正确调整host_tsc的值了,需要修正.进而利用理论tsc和当前tsc进行的差值修正guest的tsc_offset和tsc_scale,并将理论tsc值赋值给本次计时的TSC时间戳.
if (vcpu->tsc_catchup) {
u64 tsc = compute_guest_tsc(v, kernel_ns);
if (tsc > tsc_timestamp) {
adjust_tsc_offset_guest(v, tsc - tsc_timestamp);
tsc_timestamp = tsc;
}
}
接下来做了:
- 如果支持TSC_SCALLING Feature, 就利用该feature调整本地vcpu的目标TSC频率.
if (kvm_has_tsc_control)
tgt_tsc_khz = kvm_scale_tsc(v, tgt_tsc_khz);
- 如果本地vcpu的tsc频率与目标tsc频率不同,则重新调整hv_clock的shift和multi系数,以确保本地vcpu的tsc频率与目标tsc频率相等.
if (unlikely(vcpu->hw_tsc_khz != tgt_tsc_khz)) {
kvm_get_time_scale(NSEC_PER_SEC, tgt_tsc_khz * 1000LL,
&vcpu->hv_clock.tsc_shift,
&vcpu->hv_clock.tsc_to_system_mul);
vcpu->hw_tsc_khz = tgt_tsc_khz;
}
之后将本次计时的TSC时间戳,正确的system time(在实际使用时要加上wallclock时间才是标准时间)赋值给hv_clock结构,并将本次计时的时间戳保存在该vcpu的last_guest_tsc变量中.
vcpu->hv_clock.tsc_timestamp = tsc_timestamp;
vcpu->hv_clock.system_time = kernel_ns + v->kvm->arch.kvmclock_offset;
vcpu->last_guest_tsc = tsc_timestamp;
然后在kvm_setup_pvclock_page()中将hv_clock中的值更新到pv_time cache中去,该cache在kvmclock_init => WRITE MSR => handle_wrmsr => kvm_set_msr_common => kvm_gfn_to_hva_cache_init 流程中被分配空间及host虚拟地址,每个vcpu都有一个pv_time cache,其中的gpa指向每个vcpu的pvti结构.
if (vcpu->pv_time_enabled)
kvm_setup_pvclock_page(v); // 将hv_clock中的值赋值到pv_time cache中
以上, 对pvclock_gtod_data和各vcpu的pvti结构的更新之间的关系梳理基本完成.
基本思路遵循:
- 建立pvti结构的cache
- 在每次kvm更新时间时更新cache中的内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号