
Datawhale - Pandas(下)--task02 文本数据
一,先有个整体的概念:
这一章是关于文本数据,以前在EXCEL里,文本类型就是string字符串,所以这里也先介绍下string,因为和object很像,也很容易出错,所以对比着介绍的;接下来是string的一系列操作:拆分和拼接(以前只知道拼接是“+”);string的替换;子串匹配和提取。
二、string类型
1、string 和 object的区别
① 字符存取方法(string accessor methods,如str.count)会返回相应数据的Nullable类型,而object会随缺失值的存在而改变返回类型
② 某些Series方法不能在string上使用,例如: Series.str.decode(),因为存储的是字符串而不是字节
③ string类型在缺失值存储或运算时,类型会广播为pd.NA,而不是浮点型np.nan
2、string的转换,需要先别的类型转为str 型 object, 再转为string 类型。
三、拆分和拼接
1、str.split 方法
s = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'], dtype="string")
s.str.split('_')
0 [a, b, c]
1 [c, d, e]
2 <NA>
3 [f, g, h]
Note:split后的类型是object,因为现在Series中的元素已经不是string,而包含了list,且string类型只能含有字符串;对于str方法可以进行元素的选择,如果该单元格元素是列表,那么str[i]表示取出第i个元素,如果是单个元素,则先把元素转为列表在取出;expand参数控制了是否将列拆开,n参数代表最多分割多少次。
2、str.cat 方法

但是,这里:对于两个Series合并而言,是对应索引的元素进行合并。不太理解。
三、替换
替换不可避免要用正则表达式,简单的会,难得还不会。
广义上的替换,就是指str.replace函数的应用,fillna是针对缺失值的替换。
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca','', np.nan, 'CABA', 'dog', 'cat'],dtype="string")

四、子串匹配与提取
1、str.extract 方法
pd.Series(['10-87', '10-88', '10-89'],dtype="string").str.extract(r'([\d]{2})-([\d]{2})')
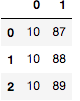
2、 str.extractall 方法
与extract只匹配第一个符合条件的表达式不同,extractall会找出所有符合条件的字符串,并建立多级索引(即使只找到一个)¶
3. str.contains和str.match
五,练习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号