
python 3 day3
一、python 3 day3
本节内容
1. 函数基本语法及特性
2. 参数与局部变量
3. 返回值
嵌套函数
4.递归
5.匿名函数
6.函数式编程介绍
7.高阶函数
8.内置函数
注意:字符串时不可以被修改的。列表可以嵌套任何东西。
1. 集合
主要作用:
- 去重(常用)
- 关系测试, 交集\差集\并集\反向(对称)差集
![]()

例如:


如果现在有两个列表,要取出这两个列表中相同值,应该如何操作呢?很简单,使用集合中的取交集intersection即可:


这两组列表还可以求并集(即将两个列表组合为同一个集合并去重),也很简单,使用union即可:
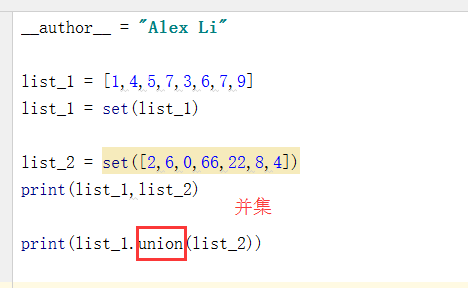

除此之外,还可以取这两个列表的差集(in list_1 but not in list_2)


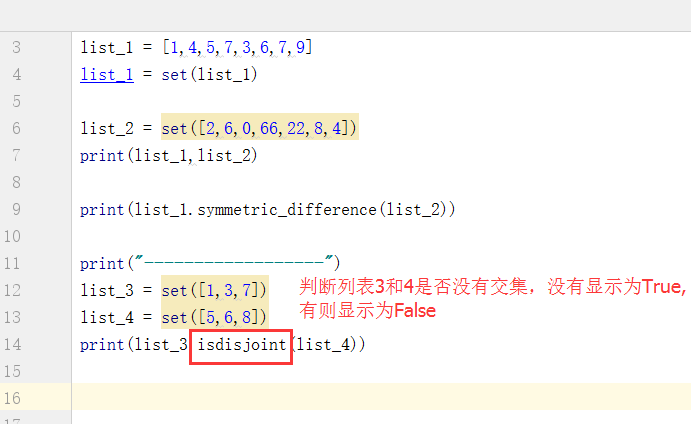
下面介绍如何使用issubset和issuperset判断一个列表是否为另一个列表的子集或者父集,返回结果只有真或者假:


例如新增一个列表,判断该列表是否为列表1或者列表2 的子集:

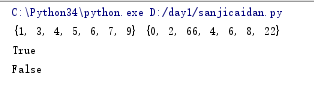
还有一个叫做对称差集(把两个列表中互相都没有的值取出来)



以上均为使用英文单词来写关系测试,实际上我们也可以用运算符来简单写关系测试,如图所示,不再赘述。

注意:集合不像列表,列表中插入数据使用append,但集合中添加一项使用add,添加多项使用update。使用remove可以删除第一项,
2. 元组
只读列表,只有count, index 2 个方法
作用:如果一些数据不想被人修改, 可以存成元组,比如身份证列表
3. 字典
key-value对
- 特性:
- 无顺序
- 去重
- 查询速度快,比列表快多了
- 比list占用内存多
为什么会查询速度会快呢?因为他是hash类型的,那什么是hash呢?
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法
dict会把所有的key变成hash 表,然后将这个表进行排序,这样,你通过data[key]去查data字典中一个key的时候,python会先把这个key hash成一个数字,然后拿这个数字到hash表中看没有这个数字, 如果有,拿到这个key在hash表中的索引,拿到这个索引去与此key对应的value的内存地址那取值就可以了。
上面依然没回答这样做查找一个数据为什么会比列表快,对不对? 呵呵,等我课上揭晓。
4. 字符编码
先说python2
- py2里默认编码是ascii
- 文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么?
- 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了
- 在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
- utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk
再说python3
- py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,干的漂亮
- 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以
- 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我擦,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,你能看出哪个字符对应哪段2进制么?什么?自己换算,得了吧,你连超过2位数的数字加减运算都费劲,还还是省省心吧。
- 那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名(python2里的str就是bytes, py3里的str是unicode),没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'\xe4\xbd\xa0\xe5\xa5\xbd' bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
最后,编码is a piece of fucking shit, noboby likes it.
5、文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作(文件句柄:即文件的内存对象,包含文件名、字符集、文件大小、在硬盘上的起始位置)
- 关闭文件
现有文件如下 :
Oh, yesterday when I was young
噢 昨日当我年少轻狂
So many, many songs were waiting to be sung
有那么那么多甜美的曲儿等我歌唱
So many wild pleasures lay in store for me
有那么多肆意的快乐等我享受
And so much pain my eyes refused to see
还有那么多痛苦 我的双眼却视而不见
There are so many songs in me that won't be sung
我有太多歌曲永远不会被唱起
I feel the bitter taste of tears upon my tongue
我尝到了舌尖泪水的苦涩滋味
The time has come for me to pay for yesterday
终于到了付出代价的时间 为了昨日
When I was young
当我年少轻狂
基本操作
f = open('lyrics') #打开文件
first_line = f.readline()print('first line:',first_line) #读一行print('我是分隔线'.center(50,'-'))data = f.read()# 读取剩下的所有内容,文件大时不要用print(data) #打印文件f.close() #关闭文件打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
6.函数基本语法及特性
函数是什么?
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
(1)语法定义

总结:当一个函数/过程没有使用return显示的定义返回值时,python解释器会隐式的返回None,所以在python中即便是过程也可以算作函数。

总结:返回数值=0,返回None;
返回数值=1,返回object;
返回数值>1,返回tuple。
6.函数调用
参数
(1)形参和实参
形参:形式参数,不是实际存在,是虚拟变量。在定义函数和使用函数体的时候使用形参,目的是在函数调用时接收实参(实参个数、类型应与形参一一对应)
实参:实际参数,调用函数时传给函数的参数,可以是变量、常量、表达式,传给函数。
区别:形参是虚拟的,不占用内存空间,形参变量只有在被调用时才分配内存单元,实参是一个变量,占用内存空间,数据传送单向,实参传给形参,不能形参传给实参。
1.位置参数和关键字(标准调用:实参和形参位置一一对应;关键字调用:位置无需固定)
关键参数:正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
非固定参数:若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
2.默认参数:这个参数在调用时不指定,那默认就是xx,指定了的话,就用你指定的值。
3.参数组:


#默认参数特点:调用函数的时候,默认参数可有可无(非必须传递)
#用途:1.默认安装值 2.连接数据库的端口号

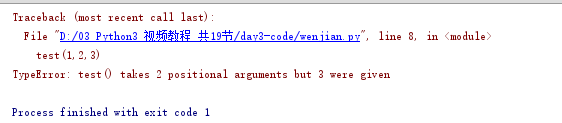
args接收N个位置参数,转换成元组形式



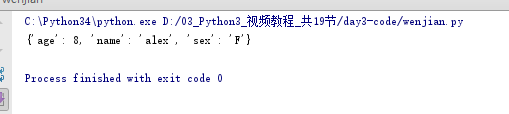
7.前向引用
函数action体内嵌套某一函数logger,该logger的声明必须早于action,否则报错。


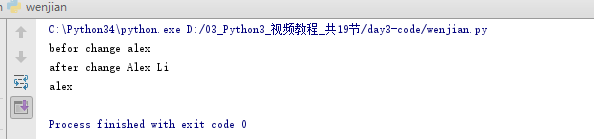
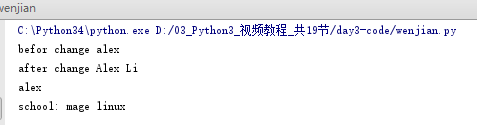
全局与局部变量

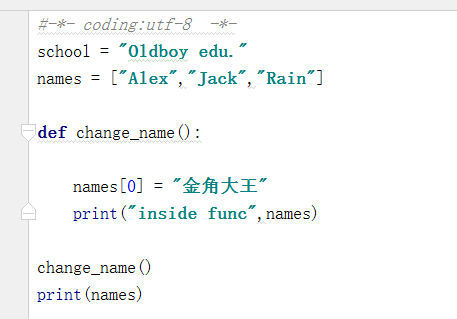
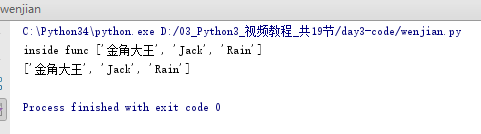
8.返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
9.嵌套函数
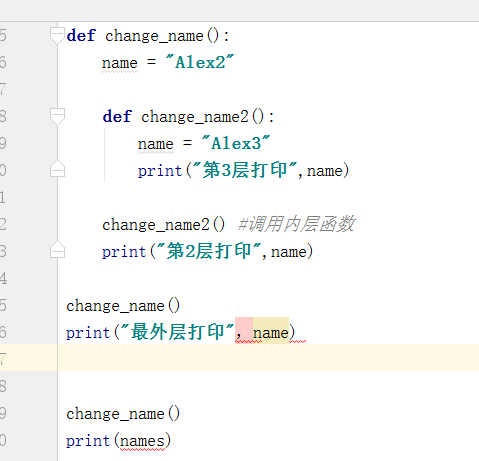
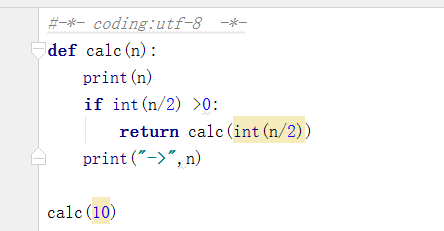
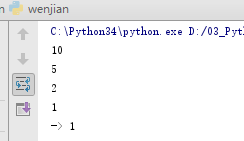
10.递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。(类似贪吃蛇)

输出结果为:
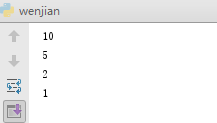
11..高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号