Python 基础三 文件 函数
今天回顾一下之前学的文件操作相关知识点,对于文件的操作,主要有一下几部分构成:
一、文件的基础知识
1.文件操作的基本流程
文件操作其实可以分成三大部分:
1.打开文件,获取文件句柄并赋予一个变量
2.通过句柄对文件进行读与写的操作
3.操纵完毕后,关闭文件
下面是一个具体的示例程序:


1.操作完成后自动关闭文件的 with open(‘db’,'r')as f: data = f.read() #一次性将文件中的内容读从磁盘上加载到内存里面 data = f.readline() #每次只读取一行数据 data = f,write() #对文件进行写入的操作 2.需要手动关闭文件的 f = open('db','r') f.read() #对文件进行读取的操作 f.close() #关闭文件
2. 文件的打开模式
文件打开的格式: 文件句柄 = open('文件路径', '模式')
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码。
文件操作的实例:
import time with open('db','r')as f: # line = f.read() #一次性输出到内存中等待调用 # line = f.readline() #每次只能输出一行到内存中 # line = f.readlines() #以列表的形式输出到内存中,每一行都是列表中的一个元素(换行符也是输出的) #line = f.readlines()#以列表的形式输出到内存中,每一行都是列表中的一个元素(换行符也是输出的) for line in f: #通过for 循环来实现一行行的输出,并且取消文件中每一行的换行符操作 data =line.strip() time.sleep(1) print(data)
文件读写操作的常用模式:
with open('db','w')as f:# w模式就是以覆盖的方式写入 f.write('dafkhfkk') with open('db','a')as f: f.write('我是总') # a模式就是以追加的方式写入(只能写到文件的尾部) r或rt 默认模式,文本模式读 rb 二进制文件 w或wt 文本模式写,打开前文件存储被清空 wb 二进制写,文件存储同样被清空 a 追加模式,只能写在文件末尾 a+ 可读写模式,写只能写在文件末尾 w+ 可读写,与a+的区别是要清空文件内容 r+ 可读写,与a+的区别是可以写到文件任何位置
3.open函数详解:
1. open()语法
open(file[, mode[, buffering[, encoding[, errors[, newline[, closefd=True]]]]]])
open函数有很多的参数,常用的是file,mode和encoding
file文件位置,需要加引号
mode文件打开模式,见下面3
buffering的可取值有0,1,>1三个,0代表buffer关闭(只适用于二进制模式),1代表line buffer(只适用于文本模式),>1表示初始化的buffer大小;
encoding表示的是返回的数据采用何种编码,一般采用utf8或者gbk;
errors的取值一般有strict,ignore,当取strict的时候,字符编码出现问题的时候,会报错,当取ignore的时候,编码出现问题,程序会忽略而过,继续执行下面的程序。
newline可以取的值有None, \n, \r, ”, ‘\r\n',用于区分换行符,但是这个参数只对文本模式有效;
closefd的取值,是与传入的文件参数有关,默认情况下为True,传入的file参数为文件的文件名,取值为False的时候,file只能是文件描述符,什么是文件描述符,就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符。
2. Python中file()与open()区别
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,建议使用open
4.文件部分的总结:
文件部分的总结 1,常用的读写方式: r 只读的模式; w 只写的模式(每次写入内容会覆盖掉上一次的内容); a 是在末尾以追加的方式进行写入(不会覆盖之前写入的内容) 2.可读可写的方式: r+ 默认光标在开始的位置,写的是追加的写入 w+ 覆盖的形式写入,想读取内容,必须对seek进行调整 a+ 光标默认在文件的最后的位置,不管光标位置,一定是追加的写入,想读取内容必须对seek 进行调整 3.rb wb ab 二进制的形式进行操作
二、函数的基础知识
1.python中函数定义:函数是逻辑结构化和过程化的一种编程方法。我个人对函数的理解就是:函数其实就是在实现我们的主逻辑过程中的一个个工具,负责一个个具体功能的实现(主要还是处理中间数据为主,返回最终的处理结果返回主逻辑等待调用)
2.Python中:函数的定义基本方法:
def func(x1,x2): x = x1 + x2 return x ret = func(2,3) print(ret) def:定义函数的关键字 func:函数名 ():内可定义形参 "":文档描述(非必要,但是强烈建议为你的函数添加描述信息) x = x1 + x2:泛指代码块或程序处理逻辑 return:定义返回值 调用运行:可以带参数也可以不带 func() ret 接收的是函数return的返回值,若函数没有返回值则ret接收的是None
几点说明:
1编程语言中的函数是通过一个函数名封装好一串用来完成某一特定功能的逻辑,编程语言中的函数传入的参数相同返回值可不一定相同且可以修改其他的全局变量值(因为一个函数a的执行可能依赖于另外一个函数b的结果,b可能得到不同结果,那即便是你给a传入相同的参数,那么a得到的结果也肯定不同)。
2.函数式编程就是:先定义一个数学函数(数学建模),然后按照这个数学模型用编程语言去实现它。
3.使用函数编程的几点优点:
3.1.代码重用
3.2.保持一致性,易维护
3.3.可扩展性
4.函数的参数问题:
def func(x1,x2): x = x1 + x2 return x ret = func(2,3) print(ret) 此函数中x1,x2 就是形式参数,而2,3就是实际参数。
x,y 就是说的形参;a,b就是实参分配内存空间,调用结束后就是释放分配的内存空间, # so,形参只有在函数内部有效,函数调用结束后返回主函数后就不能使用此形参变量 #3.2实际参数可以是常量、变量、表达式、函数等,无论是什么,他们必须有确定的值,以便把参数传递给形式参数。 while True: a=int(input('亲输入a:')) b=int(input('亲输入b:')) def tank(x,y): res = x**y return res c = tank(a,b) print(c)
5.函数值的传递问题:
#1、位置参数(参数是一一对应的) def function(x,c,z): y = x+c+z return y res = function(2,3,4) print(res) #2、关键字调用(无需对应,自己指定) def function(x,c,z): y = x+c+z return y res = function(c=2,x=3,z=4) print(res) #3、#传递默认参数(当实际参数没有指定值时就使用x4=5,若有指定的时候就 用指定的数值) def func(x1,x2,x4=5): x = x1 + x2 +x4 return x ret = func(2,3) print(ret) #10 def func(x1,x2,x4=5): x = x1 + x2 +x4 return x ret = func(2,3,10) print(ret) #15 #4.3、万能参数使用 #4.3.1 args返回的是一个元组类型,kwargs返回的是一个字典类型 def function(x,*args,**kwargs): y =x return y,args,kwargs res = function(1,2,3,4,5,a =5,b =3) print(res) # (1, (2, 3, 4, 5), {'a': 5, 'b': 3}) #
6.全局变量与局部标量
# #5.1若函数体内没有global 关键字,
# # 则优先读取局部变量,若没有局部变量则向上一个层级去找;可以读取全局变量
# # 但是不能对全局变量进行赋值操作,ge:name ='kjk'
# #5.2 若函数体内有global 关键字,
# #此时的变量本质就是全局变量,可以读取和赋值操作
name = '就是你' def func1(): name ='a' def func2(): global name name = 'b' print(name) func2() print(name) print(name) func1() print(name) # 执行结果: # 就是你 # b # a # b
对函数即是变量的理解:
def action(): print 'in the action' logger() action() 报错NameError: global name 'logger' is not defined def logger(): print 'in the logger' def action(): print 'in the action' logger() action() def action(): print 'in the action' logger() def logger(): print 'in the logger' action()
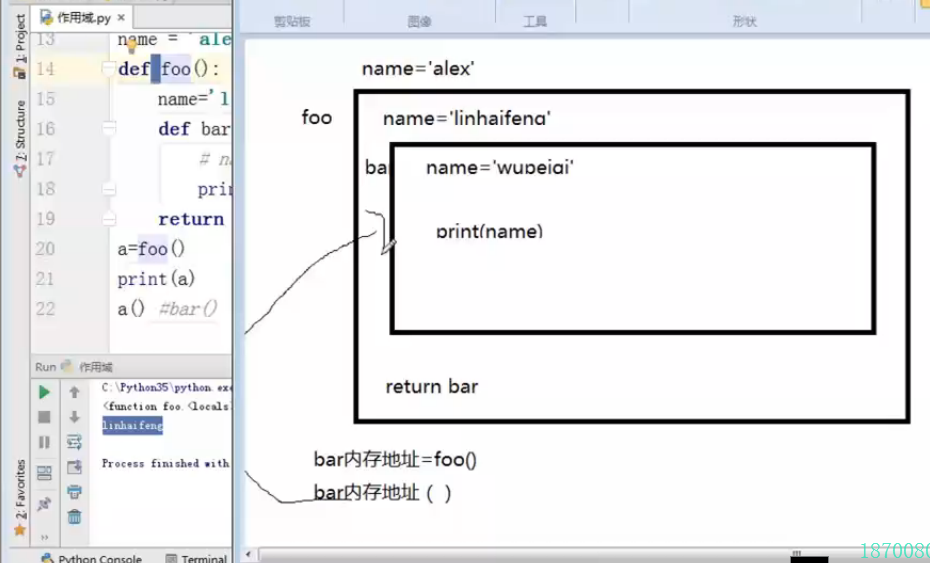
7.递归调用:如果一个函数在其本身内部调用自己这就叫做递归函数,若果在函数内部调用函数(def 里面还有 def 这样的叫函数嵌套)
递归调用的例子:
#6.1 实例一 # def func(n): # print(n) # if int(n/2) == 0: # return # res = func(int((n/2))) # return res # # a = func(10) # print(a,) 输出结果为: 10 5 2 1 None
实现的步骤为: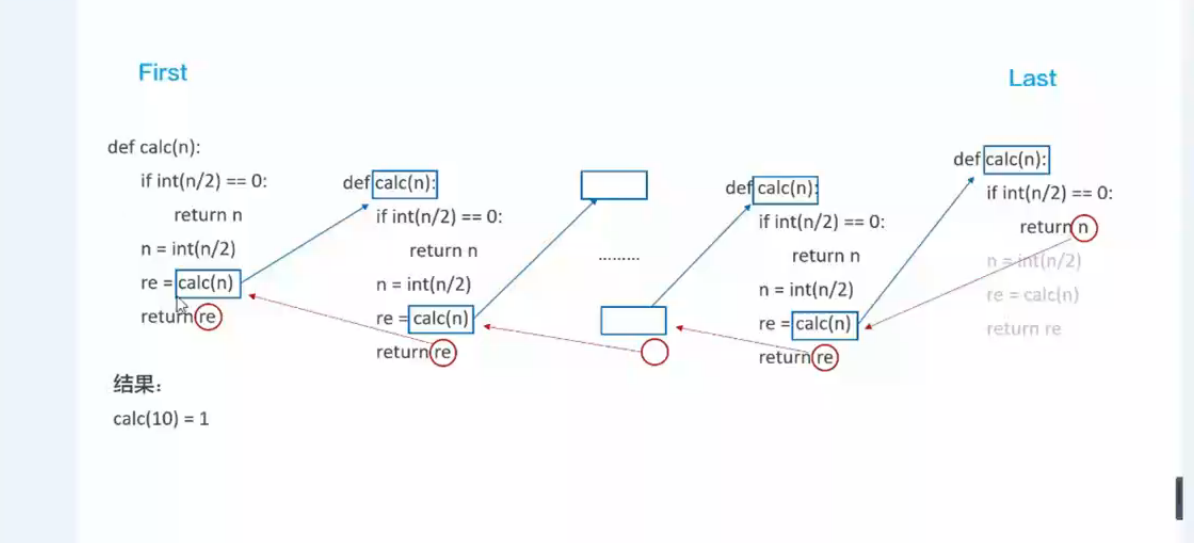
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
8.匿名函数:匿名函数就是不需要显示的指定函数
lamdba函数:ret = lamdba 变量1,变量2.....:表达式 将表达式计算的结果返回给ret
#这段代码 def calc(n): return n**n print(calc(10)) #换成匿名函数 calc = lambda n:n**n print(calc(10))
9.函数式编程:
9.1 高阶函数
满足俩个特性任意一个即为高阶函数
1.函数的传入参数是一个函数名
2.函数的返回值是一个函数名
#1.返回值中包含函数名 def test1(): print('in the test1') def test(): print('in the test') return test1 res = test() print(res) ret =res() print(ret)
in the test
<function test1 at 0x02199588>
in the test1
None
#1.2 name = 'alex' def foo(): name = 'linhaifeng' def bar(): name = 'wupeiqi' print(name) return bar print(name) a = foo() print(a) b =a() print(b) 输出结果: alex <function foo.<locals>.bar at 0x005E94B0> wupeiqi None
map函数:
#函数方法实现map函数 将列表中的每个元素平方再返回这个列表 ''' num_l = [1,2,3,4,5,6] def map_test(array): ret = [] for i in num_l: ret.append(i**2) return ret ret = map_test(num_l) print(ret) #终极版本 # num_l = [1,2,3,4,5,6,7,8] # # def map_test(func,arry): #func = lambda表达式 arry = num_l # ret = [] # for i in arry: # res = func(i) #add_one(实现) # ret.append(res) # return ret # # res = map_test(lambda x:x+1,num_l) # print(res) # msg = 'linghaifeng' # print(list(map(lambda x:x.upper(),msg)))
输出结果为:['L', 'I', 'N', 'G', 'H', 'A', 'I', 'F', 'E', 'N', 'G']
filter函数(出去自己不想要的内容)
#1.原理篇 # movice_people = ['sb_qwe','sb_rty','sb_kjl','fgd'] # # def filter_test(arry): # ret = [] # for p in arry: # if not p.startswith('sb'): # ret.append(p) # return ret # print(filter_test(movice_people)) #通过自制的filter_test函数实现判断以什么结尾的功能 # movice_people1 = ['qwe_sb','dre_sb','dfg','sb_dfg'] # def show_sb(n): # return n.endswith('sb') # # def filter_test(func,arry): # ret = [] # for p in arry: # if not func(p): # ret.append(p) # return ret # # res = filter_test(show_sb,movice_people1) # print(res) #通过lambda函数实现筛选的功能 # def filter_test(func,arry): # ret = [] # for p in arry: # if not func(p): # ret.append(p) # return ret # # res = filter_test(lambda n:n.endswith('sb'),movice_people1) # print(res) #直接通过filter 函数实现筛选功能 # ret = filter(lambda n:n.endswith('sb'),movice_people1) #print(ret) # print(list(ret))#把ret转化成列表的形式 # for i in ret: # print(i) 输出结果为: <filter object at 0x021046F0> ['qwe_sb', 'dre_sb']
reduce函数:就是对数据进行合并,并对数据压缩最后得出一个最终的结果
#1.实现reduce函数的功能 # num_k = [1,2,3,100] # def reduce_test(arry): # res = 0 # for num in arry: # res +=num # return res # print(reduce_test(num_k)) # # #2.实现列表中元素的相乘 # num_k = [1,2,3,4,100] # # def multip(x,y): # return x*y # def reduce_rest(func,arry): # res=arry.pop(0) # for num in arry: # res = func(res,num) # return res # print(reduce_rest(multip,num_k)) # print(reduce_rest(lambda x,y:x*y,num_k))
#3.函数参数含有默认参数的情况(比如在进行自动化安装的时候,不必要的确认值就可以设置成默认参数)
#
# num_k = [1,2,3,4,100]
#
# def reduce_rest(func,arry,init=None):
# if init is None:
# res = arry.pop(0)
# else:
# res = init
# for num in arry:
# res = func(res,num)
# return res
# print(reduce_rest(lambda x,y:x*y,num_k),100)
# print(reduce_rest(lambda x,y:x*y,num_k),)
#
# #4.reduce 函数的使用
# from functools import reduce
# num_h = [1,2,3,100]
# ret =reduce(lambda x,y:x+y,num_h)
# print(ret)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号