前端异常监控
前端监控包括 行为监控、异常监控、性能监控,这里主要讨论异常监控。对于前端而言,和后端处于同一个监控系统中,前端有自己的监控方案,后端也有自己的监控方案,但两者并不分离,因为一个用户在操作应用的过程中如果出现异常,有可能是前端引起,也有可能是后端引起,需要有一个机制,将前后端串联起来,使监控本身统一于监控系统。因此,即使只讨论前端异常监控,其实也不能严格区分前后端界限,而要根据实际系统的设计,在最终的报表中体现出监控对开发和业务的帮助。
一般而言,一个监控系统,大致可以分为四个阶段:日志采集。日志存储、统计与分析、报告和警告。

采集阶段:收集异常日志,先在本地做一定的处理,采取一定的方案上报到服务器。
存储阶段:后端接收前端上报的异常日志,经过一定处理,按照一定的存储方案存储。
分析阶段:分为机器自动分析和人工分析。
- 机器自动分析:通过预设的条件和算法,对存储的日志信息进行统计和筛选,发现问题,触发报警。
- 人工分析:通过提供一个可视化的数据面板,让系统用户可以看到具体的日志数据,根据信息,发现异常问题根源。
报警阶段:分为告警和预警。
- 告警按照一定的级别自动报警,通过设定的渠道,按照一定的触发规则进行。
- 预警则在异常发生前,提前预判,给出警告。
前端异常
前端异常是指用户使用 Web 应用时无法快速得到符合预期结果的情况,不同的异常带来的后果程度不同,轻则引起用户使用不悦,重则导致产品无法使用,使用户丧失对产品的认可。
前端异常分类
根据异常代码的后果程度,对前端异常的表现分为如下几类

1、出错:界面呈现的内容与用户预期的内容不符,例如点击进入非目标界面,数据不准确,出现的错误提示不可理解,界面错位,提交后跳转到错误界面等情况。这类异常出现时,虽然产品本身功能还能正常使用,但用户无法达成自己的目标。
2、呆滞:界面出现操作后没有反应的现象,例如点击按钮无法提交,提示成功后无法继续操作。这类异常出现时,产品已经存在界面级局部不可用现象。
3、损坏:界面出现无法实现操作目的的现象,例如点击无法进入目标界面,点击无法查看详情内容等。这类异常出现时,应用部分功能无法被正常使用。
4、假死:界面出现卡顿,任何功能都无法使用的现象。例如用户无法登陆导致无法使用应用内功能,由于某个遮罩层阻挡且不可关闭导致无法进行任何后续操作。这类异常出现时,用户很可能杀死应用。
5、崩溃:应用出现经常性自动退出或无法操作的现象。例如间歇性 crash,网页无法正常加载或加载后无法进行任何操作。这类异常持续出现,将导致用户流失,影响产品生命力。
异常错误原因分类
1、逻辑错误
- 业务逻辑判断条件错误
- 事件绑定顺序错误
- 调用栈时序错误
- 错误的操作js对象
2、数据类型错误
- 将null视作对象读取 property
- 将undefined视作数组进行遍历
- 将字符串形式的数字直接用于加运算
- 函数参数未传
3、语法错误
4、网络错误
- 网络速度慢
- 服务端未返回数据单仍 200,前端按正常进行数据遍历
- 提交数据时网络中断
- 服务端500错误时,前端未做任何错误处理
5、系统错误
- 内存不够用
- 磁盘塞满
- 壳不支持API
- 不兼容
异常采集
采集内容
当异常出现的时候,我们需要知道异常的具体信息,根据异常的具体信息来决定采用什么样的解决方案。
1、用户信息
出现异常时该用户的信息,例如该用户在当前时刻的状态、权限等,以及需要区分用户可多终端登录时,异常对应的是哪一个终端。
2、行为信息
用户进行声明操作时产生了异常:
- 所在的界面路径;
- 执行了什么操作;
- 操作时使用了哪些数据;
- 当时的API吐了什么数据给客户端;
- 如果是提交操作,提交了什么数据
- 上一个路径
- 上一个行为日志记录ID等
3、异常信息
产生异常的代码信息:用户操作的DOM元素节点、异常级别、异常类型、异常描述、代码stack信息等
4、环境信息
网络环境、设备型号和标识码、操作系统版本、客户端版本、API接口版本等
异常捕获
前端捕获异常分为全局捕获和单点捕获。全局捕获代码集中,易于管理;单点捕获作为补充,对某些特殊情况进行捕获,但分散,不利于管理。
1、全局捕获
通过全局的接口,将捕获代码集中写在一个地方,可以利用的接口有:
- window.addEventListener('error') 、window.addEventListener('unhandledrejection') 、document.addEventListener('click') 等
- 框架级别的全局监听,例如 axios 中使用 interceptor 进行拦截,vue、react 都有自己的错误采集接口
- 通过对全局函数进行封装包裹,实现在调用该函数时自动捕获异常
- 对实例方法重写(Patch),在原有功能基础上包裹一层,例如对console.error 进行重写,在使用方法不变的情况下也可以异常捕获
2、单点捕获
在业务代码中对单个代码块进行包裹,或在逻辑流程中打点,实现由针对性的异常捕获
- try ... catch
- 专门写一个函数来收集异常信息,在异常发生时,调用该函数
- 专门写一个函数来包裹其他函数,得到一个新函数,该新函数运行结果和原函数一模一样,只是在发生异常时可以捕获异常
跨域脚本异常
由于浏览器安全策略限制,跨域脚本报错时,无法直接获取错误的详细信息,只能得到一个 Script Error。例如,我们会引入第三方依赖,或者将自己的脚本放在 CDN 时。
解决Script Error 的方法:
方案一:
- 将 js 内联到HTML中
- 将 js 文件 与HTML放在同域下
方案二:
为页面上script标签添加crossorigin属性
被引入脚本所在服务器响应头中,增加 Access-Control-Allow-Origin 来支持跨域资源共享
异常录制
对于一个异常,仅仅拥有该异常的信息还不足以完全抓住问题的本质,因为异常发生的位置,并不一定是异常根源所在的位置。我们需要对异常现场进行还原,才能复原问题全貌,甚至避免类似问题再其他界面中发生。这里需要引进一个概念,就是 “异常录制”。录制通过 “时间” “空间” 两个维度记录异常发生前到发生的整个过程,对于找到异常根源更有帮助。
所谓的 “异常录制”,实际上就是通过技术手段,收集用户的操作过程,对用户的每一个操作都进行记录,在发生异常时,把一定时间区间内的记录重新运行,形成影响进行播放,让调试者无需向用户询问,就能看到用户当时的操作过程。
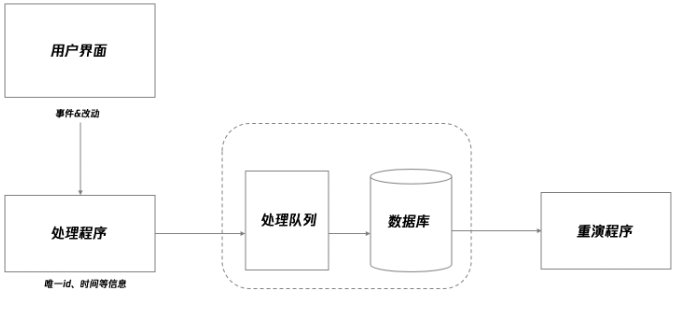
用户在界面上的操作产生的events 和 mutation被产品收集起来,上传到服务器,经过队列处理按顺序存放到数据库中。当需要进行异常重现的时候,将这些记录从数据库中取出,采用一定的技术方案,顺序播放这些记录,即可实现异常还原。
异常级别
一般而言,我们会将收集信息的级别分为 info、warn、error等,并在此基础上进行扩展。
当我们监控到异常发生时,可以将该异常划分到“重要---紧急” 模型找那个分为 A、B、C、D 四个等级。有些异常,虽然发生了,但是并不影响用户的正常使用,用户其实并没有感知到,虽然理论上应该修复,但是实际上相对于其他异常而言,可以放在后面进行处理。
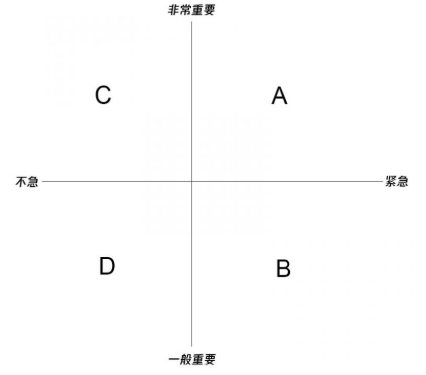
一般而言,越靠近右上角的异常会越快通知,保证相关人员能最快接收到信息,并进行处理。A级异常需要快速响应,甚至需要相关负责人知悉。
整理与上报方案
上面已经提到,除了异常报错信息本身,我们还需要记录用户操作日志,以实现场景复原。这就涉及到上报的量和频率问题。如果任何日报都立即上报,这无异于自造的 DDOS 攻击。因此,我们需要合理的上报方案。下面会介绍4种上报方案,但实际我们不会仅限于其中一种,而是经常同时使用,对不同级别的日志选择不同的上报方案。
前端存储日志
前面提到,我们并不单单采集异常本身日志,而且还会采集与异常相关的用户行为日志。单纯一条异常日志并不能帮助我们快速定位问题根源,找到解决方案。但如果要收集用户的行为日志,又要采取一定的技巧,而不能用户每一个操作后,就立即将该行为日志传到服务器,对于具有大量用户同时在线的应用,如果用户一操作就立即上传日志,无异于对日志服务器进行DDOS攻击。因此,我们先将这些日志存储在用户客户端本地,达到一定条件之后,再同时打包上传一组日志。
https://cdc.tencent.com/2018/09/13/frontend-exception-monitor-research/
1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号