度小满面试题20190923
1. 一面
1. SpringBoot 注解以及自动配置(生效条件)
@SpringBootApplication
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan
@Configuration
1、@SpringBootApplication
@SpringBootApplication注解是Spring Boot的核心注解,它其实是一个组合注解.
/** @SpringBootApplication注解的源码
@Target(ElementType.TYPE)注解的作用目标
@Retention(RetentionPolicy.RUNTIME) 注解的保留位置
@Documented 注解将被包含在javadoc中
@Inherited 子类可以继承父类中的该注解
@SpringBootConfiguration 修饰Spring Boot的配置
@EnableAutoConfiguration 开启自动配置
@ComponentScan(excludeFilters = @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class))
该注解会自动扫描包路径下面的所有@Controller、@Service、@Repository、@Component 的类,不配置包路径的话,在Spring Boot中默认扫描@SpringBootApplication所在类的同级目录以及子目录下的相关注解。
**/
用在 Spring Boot 主类上,标识这是一个 Spring Boot 应用,用来开启 Spring Boot 的各项能力。 这个注解就是 @SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan 这三个注解的组合,也可以用这三个注解来代替 @SpringBootApplication注解。 2、@EnableAutoConfiguration 允许 Spring Boot 自动配置注解,开启这个注解之后,Spring Boot 就能根据当前类路径下的包或者类来配置 Spring Bean。 如:当前类路径下有 Mybatis 这个 JAR 包,MybatisAutoConfiguration 注解就能根据相关参数来配置 Mybatis 的各个 Spring Bean。 3、@Configuration 这是 Spring 3.0 添加的一个注解,用来代替 applicationContext.xml 配置文件,所有这个配置文件里面能做到的事情都可以通过这个注解所在类来进行注册。 4、@SpringBootConfiguration 这个注解就是 @Configuration 注解的变体,只是用来修饰是 Spring Boot 配置而已,或者可利于 Spring Boot 后续的扩展。 5、@ComponentScan 这是 Spring 3.1 添加的一个注解,用来代替配置文件中的 component-scan 配置,开启组件扫描,即自动扫描包路径下的 @Component 注解进行注册 bean 实例到 context 中。6、@Conditional 这是 Spring 4.0 添加的新注解,用来标识一个 Spring Bean 或者 Configuration 配置文件,当满足指定的条件才开启配置。 7、@ConditionalOnBean 组合 @Conditional 注解,当容器中有指定的 Bean 才开启配置。 8、@ConditionalOnMissingBean 组合 @Conditional 注解,和 @ConditionalOnBean 注解相反,当容器中没有指定的 Bean 才开启配置。 9、@ConditionalOnClass 组合 @Conditional 注解,当容器中有指定的 Class 才开启配置。 10、@ConditionalOnMissingClass 组合 @Conditional 注解,和 @ConditionalOnMissingClass 注解相反,当容器中没有指定的 Class 才开启配置。 11、@ConditionalOnWebApplication 组合 @Conditional 注解,当前项目类型是 WEB 项目才开启配置。 enum Type { /** * Any web application will match. */ ANY, /** * Only servlet-based web application will match. */ SERVLET, /** * Only reactive-based web application will match. */ REACTIVE } 12、@ConditionalOnNotWebApplication 组合 @Conditional 注解,和 @ConditionalOnWebApplication 注解相反,当前项目类型不是 WEB 项目才开启配置。 13、@ConditionalOnProperty 组合 @Conditional 注解,当指定的属性有指定的值时才开启配置。 14、@ConditionalOnExpression 组合 @Conditional 注解,当 SpEL 表达式为 true 时才开启配置。 15、@ConditionalOnJava 组合 @Conditional 注解,当运行的 Java JVM 在指定的版本范围时才开启配置。 16、@ConditionalOnResource 组合 @Conditional 注解,当类路径下有指定的资源才开启配置。 17、@ConditionalOnJndi 组合 @Conditional 注解,当指定的 JNDI 存在时才开启配置。 18、@ConditionalOnCloudPlatform 组合 @Conditional 注解,当指定的云平台激活时才开启配置。 19、@ConditionalOnSingleCandidate 组合 @Conditional 注解,当指定的 class 在容器中只有一个 Bean,或者同时有多个但为首选时才开启配置。 20、@ConfigurationProperties 用来加载额外的配置(如 .properties 文件),可用在 @Configuration 注解类,或者 @Bean注解方法上面。 21、@EnableConfigurationProperties 一般要配合 @ConfigurationProperties 注解使用,用来开启对 @ConfigurationProperties注解配置 Bean 的支持。 22、@AutoConfigureAfter 用在自动配置类上面,表示该自动配置类需要在另外指定的自动配置类配置完之后。 如 Mybatis 的自动配置类,需要在数据源自动配置类之后。 @AutoConfigureAfter(DataSourceAutoConfiguration.class) public class MybatisAutoConfiguration {}
23、@AutoConfigureBefore 这个和 @AutoConfigureAfter 注解使用相反,表示该自动配置类需要在另外指定的自动配置类配置之前。 24、@Import 这是 Spring 3.0 添加的新注解,用来导入一个或者多个 @Configuration 注解修饰的类,这在 Spring Boot 里面应用很多。 25、@ImportResource 这是 Spring 3.0 添加的新注解,用来导入一个或者多个 Spring 配置文件,这对 Spring Boot 兼容老项目非常有用,因为有些配置无法通过 Java Config 的形式来配置就只能用这个注解来导入。
2. SpringMVC过滤器&拦截器
(1)过滤器(Filter):它依赖于servlet容器。
在实现上,基于函数回调,
它可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次。
使用过滤器的目的,是用来做一些过滤操作,获取我们想要获取的数据,
比如:在Javaweb中,对传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者Controller进行业务逻辑操作。
通常用的场景是:在过滤器中修改字符编码(CharacterEncodingFilter)、在过滤器中修改HttpServletRequest的一些参数(XSSFilter(自定义过滤器)),如:过滤低俗文字、危险字符等。 web.xml <filter> <filter-name>encoding</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>UTF-8</param-value> </init-param> <init-param> <param-name>forceEncoding</param-name> <param-value>true</param-value> </init-param> </filter> <filter-mapping> <filter-name>encoding</filter-name> <servlet-name>/*</servlet-name> </filter-mapping> (2)拦截器(Interceptor):它依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。
在实现上,基于Java的反射机制,属于面向切面编程(AOP)的一种运用,就是在service或者一个方法前,调用一个方法,或者在方法后,调用一个方法,比如动态代理就是拦截器的简单实现,在调用方法前打印出字符串(或者做其它业务逻辑的操作),也可以在调用方法后打印出字符串,甚至在抛出异常的时候做业务逻辑的操作。
由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI)进行一些业务操作,同时一个拦截器实例在一个controller生命周期之内可以多次调用。
但是缺点是只能对controller请求进行拦截,对其他的一些比如直接访问静态资源的请求则没办法进行拦截处理。
登陆验证
SpringMVC的配置文件 <mvc:interceptors> <mvc:interceptor> <mvc:mapping path="/**" /> <bean class="com.scorpios.atcrowdfunding.web.LoginInterceptor"></bean> </mvc:interceptor> <mvc:interceptor> <mvc:mapping path="/**" /> <bean class="com.scorpios.atcrowdfunding.web.AuthInterceptor"></bean> </mvc:interceptor> </mvc:interceptors> 总结 (1)Filter需要在web.xml中配置,依赖于Servlet; (2)Interceptor需要在SpringMVC中配置,依赖于框架; (3)Filter的执行顺序在Interceptor之前,具体的流程见下图;
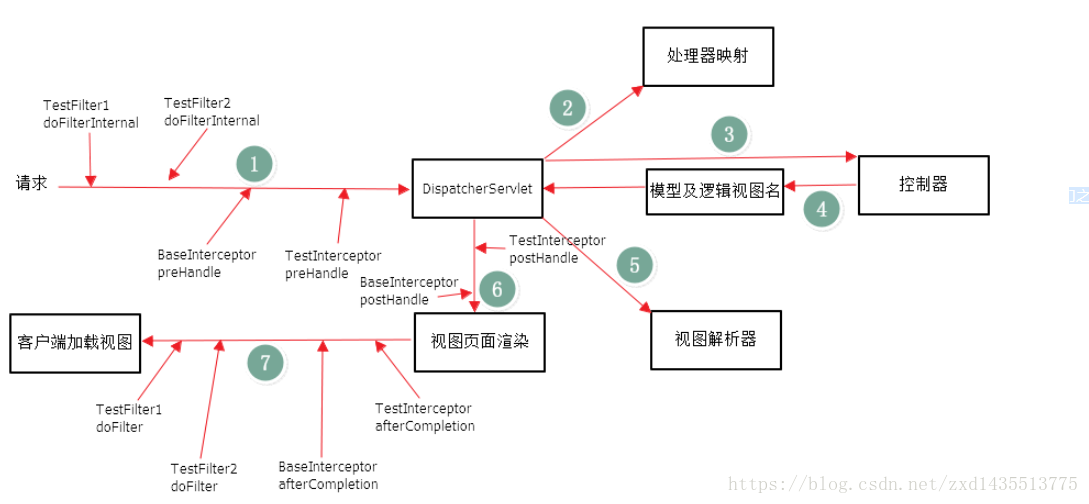
(4)区别:拦截器(Interceptor)是基于Java的反射机制,而过滤器(Filter)是基于函数回调。
从灵活性上说拦截器功能更强大些,Filter能做的事情,都能做,而且可以在请求前,请求后执行,比较灵活。
Filter主要是针对URL地址做一个编码的事情、过滤掉没用的参数、安全校验(比较泛的,比如登录不登录之类),
太细的话,还是建议用interceptor。不过还是根据不同情况选择合适的。
3. Hibernate && Mybatis
1. Hibernate防止Sql注入
1.对参数名称named parameter进行绑定: String hql = "from InventoryTask it where it.orgId=:orgId"; Session session = getSession(); Query query=session.createQuery(hql); query.setString("orgId",orgId); List list = query.list(); if(list!=null&&list.size()!=0){ return (InventoryTask)list.get(0); }else{ return null; } 2.对参数位置positional parameter进行邦定: String hql = "from InventoryTask it where it.orgId=?,it.orgName"; Session session = getSession(); Query query=session.createQuery(hql); query.setString("0",orgId); query.setString(1,orgName) List list = query.list(); if(list!=null&&list.size()!=0){ return (InventoryTask)list.get(0); }else{ return null; } 3.setParameter()方法: Query query=session.createQuery(hql); query.setParameter(“name”,name,Hibernate.STRING);
4.setProperties()方法: Entity entity=new Entity(); entity.setXx(“xx”); entity.setYy(100); Query query=session.createQuery(“from Entity c where c.xx=:xx and c.yy=:yy ”); query.setProperties(entity); 5.HQL拼接方法,这种方式是最常用,而且容易忽视且容易被注入的,通常做法就是对参数的特殊字符进行过滤,推荐使用 Spring工具包的StringEscapeUtils.escapeSql()方法对参数进行过滤: import org.apache.commons.lang.StringEscapeUtils; public static void main(String[] args) { String str = StringEscapeUtils.escapeSql("'"); System.out.println(str); } StringEscapeUtils.escapeSql(); /** * <p>Escapes the characters in a <code>String</code> to be suitable to pass to * an SQL query.</p> * * <p>For example, * <pre>statement.executeQuery("SELECT * FROM MOVIES WHERE TITLE='" + * StringEscapeUtils.escapeSql("McHale's Navy") + * "'");</pre> * </p> * * <p>At present, this method only turns single-quotes into doubled single-quotes * (<code>"McHale's Navy"</code> => <code>"McHale''s Navy"</code>). It does not * handle the cases of percent (%) or underscore (_) for use in LIKE clauses.</p> * * see http://www.jguru.com/faq/view.jsp?EID=8881 * @param str the string to escape, may be null * @return a new String, escaped for SQL, <code>null</code> if null string input */ public static String escapeSql(String str) { if (str == null) { return null; } return StringUtils.replace(str, "'", "''"); } //输出结果:''
2. Mybatis 防止Sql注入
#{}:#{}是经过预编译的,是安全的,相当于JDBC中的PreparedStatement。
${}:是未经过预编译的,仅仅是取变量的值,是非安全的,存在SQL注入。
在编写MyBatis的映射语句时,尽量采用“#{xxx}”这样的格式。若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止SQL注入攻击。
3. Mybatis # $
#{} : 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符,一个 #{ } 被解析为一个参数占位符 。
${}: 仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换。
1、#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。
如:where username=#{username},如果传入的值是111,那么解析成sql时的值为where username="111", 如果传入的值是id,则解析成的sql为where username="id".
2、$将传入的数据直接显示生成在sql中。
如:where username=${username},如果传入的值是111,那么解析成sql时的值为where username=111;
如果传入的值是;drop table user;,则解析成的sql为:select id, username, password, role from user where username=;drop table user;
3、#方式能够很大程度防止sql注入,$方式无法防止Sql注入。
4、$方式一般用于传入数据库对象,例如传入表名.
5、一般能用#的就别用$,若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止sql注入攻击。
6、在MyBatis中,“${xxx}”这样格式的参数会直接参与SQL编译,从而不能避免注入攻击。但涉及到动态表名和列名时,只能使用“${xxx}”这样的参数格式。所以,这样的参数需要我们在代码中手工进行处理来防止注入。
【结论】在编写MyBatis的映射语句时,尽量采用“#{xxx}”这样的格式。若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止SQL注入攻击。
4. Mybatis 实现 in
foreach语句实现IN查询 /** foreach语句中, collection属性的参数类型可以使:List、数组、map集合 collection: 必须跟mapper.java中@Param标签指定的元素名一样 item: 表示在迭代过程中每一个元素的别名,可以随便起名,但是必须跟元素中的#{}里面的名称一样。 index:表示在迭代过程中每次迭代到的位置(下标) open:前缀, sql语句中集合都必须用小括号()括起来 close:后缀 separator:分隔符,表示迭代时每个元素之间以什么分隔 */ 1)如果是list,所以collention里就要写list, 2)如果是array,则就要写array。 3)当查询的参数有多个时,有两种方式可以实现,一种是使用@Param("xxx")进行参数绑定,另一种可以通过Map来传参数。 4)如果是item表示的就是查询的参数,因为是对象,所以就要获取其属性值,也就是object.userId。 1. list List<User> selectByIdList(List idList); <select id="selectByIdList" resultMap="BaseResultMap"> SELECT <include refid="Base_Column_List" /> from t_user WHERE id IN <foreach collection="list" item="id" index="index" open="(" close=")" separator=","> #{id} </foreach> </select> 2. array List<User> selectByIdArray(String[] idList); <select id="selectByIdArray" resultMap="BaseResultMap"> SELECT <include refid="Base_Column_List" /> from t_user WHERE id IN <foreach collection="array" item="id" index="index" open="(" close=")" separator=","> #{id} </foreach> </select> 3. 多个参数:当查询的参数有多个时,有两种方式可以实现,一种是使用@Param("xxx")进行参数绑定,另一种可以通过Map来传参数
1)@Param("xxx")方式 List<User> selectByNameAndIdArray(@Param("name")String name, @Param("ids")String[] idList); <select id="selectByNameAndIdArray" resultMap="BaseResultMap"> SELECT <include refid="Base_Column_List" /> from t_user WHERE name=#{name,jdbcType=VARCHAR} and id IN <foreach collection="idList" item="id" index="index" open="(" close=")" separator=","> #{id} </foreach> </select> 2)Map方式 Map<String, Object> params = new HashMap<String, Object>(2); params.put("name", name); params.put("idList", ids); mapper.selectByIdMap(params); <select id="selectByIdMap" resultMap="BaseResultMap"> select <include refid="Base_Column_List" /> from t_user where name = #{name} and ID in <foreach item="item" index="index" collection="idList" open="(" separator="," close=")"> #{item} </foreach> </select>
5. mybais count
resultType
mybatis返回count(*)的整数值
int selectNums(); <select id="selectNums" resultType="java.lang.Integer"> select count(*) from tableName </select>
6. mybatis中传入String类型参数
1. 在接口参数里加上mybatis中的@param注解(优先) List<User> findUserByName(@Param("name")String name); <select id="findUserByName" parameterType="java.lang.String" resultType="com.entity.User"> SELECT id,name FROM t_user where id = '1' <if test="name!= null and name!= ''"> AND name LIKE concat('%',#{name},'%') </if> </select> 2. 在xml的if里用"_parameter" 代表参数 List<User> findUserByName(String name); <select id="findUserByName" parameterType="java.lang.String" resultType="com.entity.User"> SELECT id,name FROM t_user where id = '1' <if test="_parameter!= null and _parameter!= ''"> AND name LIKE concat('%',#{name},'%') </if> </select> _parameter不能区分多个参数,而@param能。所以@param能传多个这样的参数
注意看,是在if test=验证的时候发生的 “There is no getter for property named in ‘class java.lang.String’”,而并非是and username = #{username} 的时候发生的错误。
4. ThreadLocal
ThreadLocl 主要用于线程安全地共享某个变量
1. 底层
ThreadLocalMap Entry(ThreadLocal<?>, Object) 什么是ThreadLocal? /*** ThreadLocal类顾名思义可以理解为线程本地变量。
也就是说如果定义了一个ThreadLocal,每个线程往这个ThreadLocal中读写是线程隔离,互相之间不会影响的。
它提供了一种将可变数据通过每个线程有自己的独立副本从而实现线程封闭的机制。 **/ 它大致的实现思路是怎样的? /*** Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,
也就是说每个线程有一个自己的ThreadLocalMap。
ThreadLocalMap有自己的独立实现,可以简单地将它的key视作ThreadLocal,value为代码中放入的值(实际上key并不是ThreadLocal本身,而是它的一个弱引用)。
每个线程在往某个ThreadLocal里塞值的时候,都会往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。 **/
2. ThreadLocal和线程池
线程池(核心线程,销毁线程)
副作用(脏数据,内存溢出)
ThreadLocl 主要用于线程安全地共享某个变量
ThreadLocl 主要会产生脏数据和内存泄露。这两个问题通常是在线程池的线程中使用ThreadLocal 引发的,因为线程池有线程复用和内存常驻两个特点。
1.脏数据
线程复用会产生脏数据。由于线程池会重用Thread对象,那么与Thread绑定的类静态属性也会被重用。
如果在实现线程run() 方法中不显示的调用remove() 清理与线程相关的ThreadLocal 信息。
如果先一个线程不调用set() 设置初始值,那么就get() 到重用信息,包括ThreadLocl 所关联线对象的值。
2.内存泄露
在源码注释中提示使用static 关键字来修改ThreadLocal。
在此场景下,寄希望于ThreadLocal对象失去引用后,触发弱引用机制来回收Entry 的Value 就不现实了。
在上例中,如果不进行remove() 操作,那么这个线程执行完成后,通过ThreadLocal 对象持有的string对象是不会被释放的。
以上两个问题解决的办法很简单,就是每次用完ThreadLocal 时,必须调用remove() 方法清理。
5. Volatile

6. synchronized
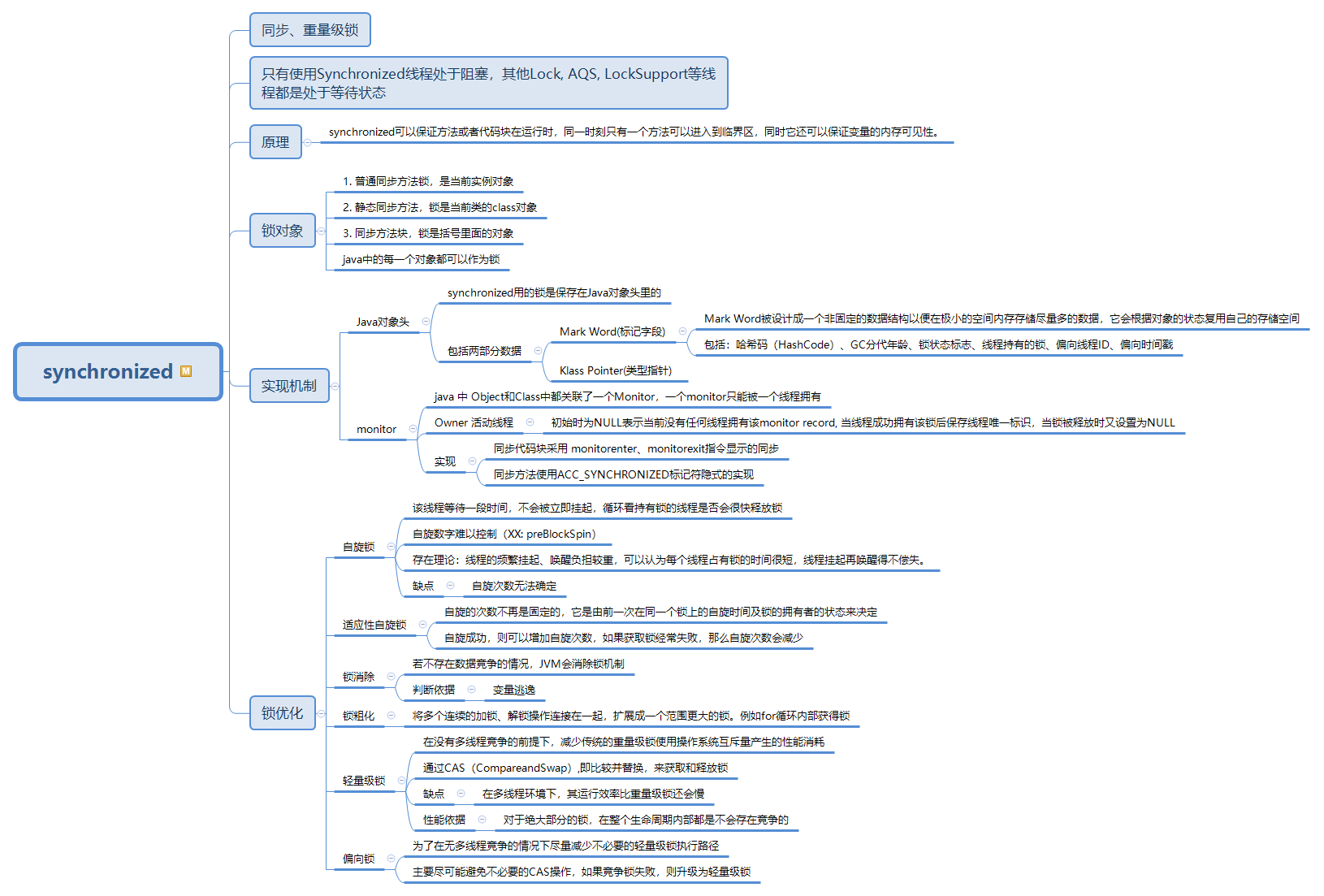 Lock与synchronized有以下区别:
Lock与synchronized有以下区别:
- Lock是一个接口,而synchronized是关键字。
- synchronized会自动释放锁,而Lock必须手动释放锁。
- Lock可以让等待锁的线程响应中断,而synchronized不会,线程会一直等待下去。
- 通过Lock可以知道线程有没有拿到锁,而synchronized不能。
- Lock能提高多个线程读操作的效率。
- synchronized能锁住类、方法和代码块,而Lock是块范围内的
7. CAS

8. CountDownLatch

https://www.cnblogs.com/haimishasha/p/11198482.html
9. 公平锁 & 非公平锁
公平锁:FIFO 获取不到锁的时候,会自动加入队列,等待线程释放后,队列的第一个线程获取锁 非公平锁: 获取不到锁的时候,会自动加入队列,等待线程释放锁后所有等待的线程同时去竞争
它们的差别在于非公平锁会有更多的机会去抢占锁。
可重入: 同一个线程可以反复获取锁多次,然后需要释放多次 synchronized 是非公平锁,可以重入。
ReentrantLock内部拥有一个Sync内部类,该内部类继承自AQS,该内部类有两个子类FairSync和NonfairSync,分别代表了公平锁和非公平锁,ReentrantLock默认使用非公平锁
/**
* true 表示 ReentrantLock 的公平锁
*/
private ReentrantLock lock = new ReentrantLock(true);
10. HTTPS
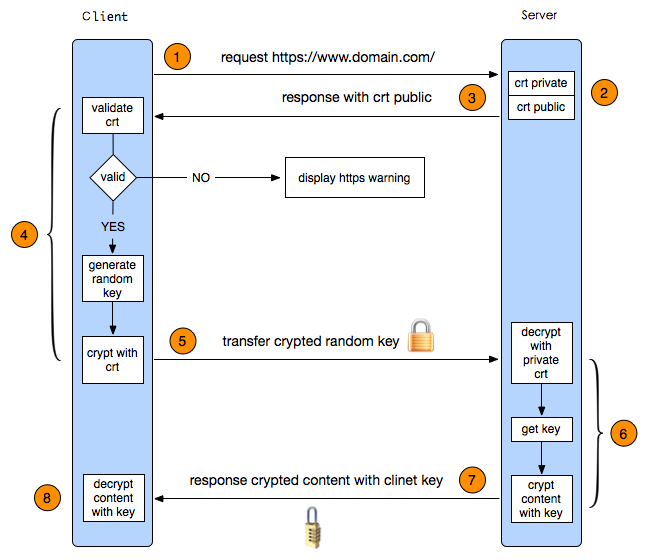
一个HTTPS请求实际上包含了两次HTTP传输,可以细分为8步。 1. 客户端发起HTTPS请求:请求携带了浏览器支持的加密算法和哈希算法
客户端向服务器发起HTTPS请求,连接到服务器的443端口。
2. 服务端的配置:服务器收到请求,选择浏览器支持的加密算法和哈希算法。
服务器端有一个密钥对,即公钥和私钥,是用来进行非对称加密使用的,服务器端保存着私钥,不能将其泄露,公钥可以发送给任何人。采用HTTPS协议的服务器必须要有一套数字证书。 3. 传送证书:服务器将自己的CA 证书(公钥)发送给客户端。 这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。 4. 客户端解析证书(TLS)
客户端收到服务器端的公钥之后,会对公钥进行检查,验证其合法性,
如果发现发现公钥有问题,那么HTTPS传输就无法继续。
如果公钥合格,那么客户端会生成一个随机值,这个随机值就是用于进行对称加密的密钥,我们将该密钥称之为client key,即客户端密钥,这样在概念上和服务器端的密钥容易进行区分。
然后用服务器的公钥对客户端密钥进行非对称加密,这样客户端密钥就变成密文了,
至此,HTTPS中的第一次HTTP请求结束。 这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随即值。然后用证书对该随机值进行加密。就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。 5. 传送加密信息
客户端会发起HTTPS中的第二个HTTP请求,将加密之后的客户端密钥发送给服务器。 这部分传送的是用证书加密后的随机值R(私钥),目的就是让服务端得到这个随机值R,以后客户端和服务端的通信就可以通过这个随机值R来进行加密解密了。 6. 服务端解密信息
服务器接收到客户端发来的密文之后,会用自己的私钥对其进行非对称解密,解密之后的明文就是客户端密钥(随机数 R),
然后把内容用客户端密钥随机数 R进行对称加密,这样数据就变成了密文。 服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。
所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。 7. 传输加密后的信息
然后服务器将加密后的密文发送给客户端。(服务器以随机数 R 为密钥把传输内容使用对称加密算法加密并传输给浏览器)。 这部分信息是服务端用私钥加密后的信息,可以在客户端被还原 8. 客户端解密信息
客户端收到服务器发送来的密文,用客户端密钥(随机数 R)对其进行对称解密,得到服务器发送的数据。这样HTTPS中的第二个HTTP请求结束,整个HTTPS传输完成。 客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容。整个过程第三方即使监听到了数据,也束手无策。
11. QPS过大怎么办?
/** 尽量使用缓存,包括用户缓存,信息缓存等,多花点内存来做缓存,可以大量减少与数据库的交互,提高性能。 用jprofiler等工具找出性能瓶颈,减少额外的开销。 优化数据库查询语句,减少直接使用hibernate等工具的直接生成语句(仅耗时较长的查询做优化)。 优化数据库结构,多做索引,提高查询效率。 统计的功能尽量做缓存,或按每天一统计或定时统计相关报表,避免需要时进行统计的功能。 能使用静态页面的地方尽量使用,减少容器的解析(尽量将动态内容生成静态html来显示)。 解决以上问题后,使用服务器集群来解决单台的瓶颈问题。 */
12. linux基本命令
1. Linux三剑客(grep、sed、awk)
Linux三剑客(grep、sed、awk) grep:文本过滤(模式:pattern)工具,grep, egrep sed:是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中 awk:报告生成器,格式化文本输出,有多种版本:New awk(nawk),GNU awk( gawk) -记住三个命令的运用形式 grep '字符' 文件 sed '命令' 文件 awk '条件{命令}' 文件 -单引号内就是正则表达式的用法 Linux下使用Shell截取文件一部分内容保存到新的文件中 1. 确定有自己业务有关的日志在文件中的行数 grep -n "业务有关的关键字" filename 根据关键字的搜索结果,绿色数字为关键字出现在文件中所在的行数,这样就可以大概估算关键字出现的行的范围了。 2. 截取指定行之间的日志到新的文件中 sed -n '开始行数,结束行数p' 待截取的文件 >> 保存的新文件
2. 授权
chown:用来更改某个目录或文件的用户名和用户组
chmod:用来更改某个目录或文件的访问权限
`ll`命令查看目录下文件 "drwxr-xr-x" 可见一共有十位。-[rw-][r--][r--].其中第一个[-]代表的是类型,其中第一位为d代表目录,每三位代表一个权限位 d:目录 rwx: 可读、可写、可执行 2-4位代表所有者拥有的权限 r-x: 可读、可执行 5-7位代表群组拥有的权限 r-x: 可读、可执行 8-10位代表其他人拥有的权限 十进制表示 /** r : 4 w : 2 x : 1 - : 0 /** 权限操作 /** + 表示添加权限 - 表示删除权限 = 重置权限 修改文件权限 */ 位置 /** u:代表文件所有者(user) g: 代表所有者所在的群组(group) o:代表其他人,但不是u和g(other) a:a和一起指定ugo效果一样 */ /** chmod o+w test.txt :表示给其他人授予写test.txt这个文件的权限 chmod go-rw test.txt : 表示群组和其他人删除对test.txt文件的读写权限 chmod ugo+r test.txt:所有人皆可读取 chmod a+r text.txt:所有人皆可读取 chmod ug+w,o-w text.txt:设为该档案拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入 chmod u+x test.txt: 创建者拥有执行权限 chmod -R a+r ./www/ :将www下的所有档案与子目录皆设为任何人可读取 chmod a-x test.txt :收回所有用户的对test.txt的执行权限 chmod 777 test.txt: 所有人可读,写,执行 */ 修改目录权限 /** chmod 700 /opt/elasticsearch #修改目录权限 chmod -R 744 /opt/elasticsearch #修改目目录以下所有的权限 -R # 以递归方式更改所有的文件及子目录 chown 修改用户组 修改 test.txt 目录所属用户为 root,用户组为 root chown -R root:root test.txt -rw-r--r--. 1 root root 55 8月 24 17:25 test.txt */ 常见权限 /** -rw------- (600) 只有所有者才有读和写的权限。 -rw-r--r-- (644) 只有所有者才有读和写的权限,群组和其他人只有读的权限。 -rw-rw-rw- (666) 每个人都有读写的权限 -rwx------ (700) 只有所有者才有读,写和执行的权限。 -rwx--x--x (711) 只有所有者才有读,写和执行的权限,群组和其他人只有执行的权限。 -rwxr-xr-x (755) 只有所有者才有读,写,执行的权限,群组和其他人只有读和执行的权限。 -rwxrwxrwx (777) 每个人都有读,写和执行的权限 */ 实践 在用Elasticsearch的时候是少不了给添加用户授权 /** chmod 400 test.txt #修改text.txt为可读文件 vi text.txt #执行该命令后,该文件就无法进行写入操作 提示下面信息 -- INSERT -- W10: Warning: Changing a readonly file chmod 777 text.txt -rwxrwxrwx. 1 root root 55 8月 24 17:25 test.txt chmod rwxr--r-- test.txt #异常,不能使用该命令来修改权限 */
3. root权限
方法一:修改 /etc/sudoers 文件,找到下面一行,把前面的注释(#)去掉 ## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL 然后修改用户,使其属于root组(wheel),命令如下: #usermod -g root tommy 修改完毕,现在可以用tommy帐号登录,然后用命令 su – ,即可获得root权限进行操作。 方法二:修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示: ## Allow root to run any commands anywhere root ALL=(ALL) ALL tommy ALL=(ALL) ALL 修改完毕,现在可以用tommy帐号登录,然后用命令 sudo – ,即可获得root权限进行操作。 方法三:修改 /etc/passwd 文件,找到如下行,把用户ID修改为 0 ,如下所示: tommy:x:0:33:tommy:/data/webroot:/bin/bash
4. 查看进程和端口
1、lsof -i:端口号 2、netstat -tunlp|grep 端口号 都可以查看指定端口被哪个进程占用的情况 lsof -i 用以显示符合条件的进程情况,lsof(list open files)是一个列出当前系统打开文件的工具。 lsof -i:端口号,用于查看某一端口的占用情况,比如查看22号端口使用情况,lsof -i:22 netstat -tunlp用于显示tcp,udp的端口和进程等相关情况 netstat -tunlp|grep 端口号,用于查看指定端口号的进程情况,如查看22端口的情况,netstat -tunlp|grep 22
5. 查看全局
1、查看CPU信息 # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 # 查看物理CPU个数 cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l # 查看每个物理CPU中core的个数(即核数) cat /proc/cpuinfo| grep "cpu cores"| uniq # 查看逻辑CPU的个数 cat /proc/cpuinfo| grep "processor"| wc -l # 查看CPU信息(型号) cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c #CPU负载信息,使用top 命令 2、查看内存信息 1)cat /proc/meminfo 2)free 命令 3、查看磁盘信息 1)fdisk -l 2)iostat -x 10 查看磁盘IO的性能
13. 数据库索引最左原则
最左前缀原则
mysql建立多列索引(联合索引)有最左前缀的原则,即最左优先,如:
如果有一个2列的索引(col1,col2),则已经对(col1)、(col1,col2)上建立了索引;
如果有一个3列索引(col1,col2,col3),则已经对(col1)、(col1,col2)、(col1,col2,col3)上建立了索引;
1、b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+树是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道第一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。
2、比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。(这种情况无法用到联合索引)
关于最左前缀的使用,有下面两条说明:
1. 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2. =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
14. B+树
B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一颗B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
B+ 树通常用于数据库和操作系统的文件系统中。 NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。
B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。
B+ 树元素自底向上插入。
所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。(而B 树的叶子节点并没有包括全部需要查找的信息)
所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。(而B 树的非终节点也包含需要查找的有效信息)
/** B树 每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。 B树优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。 B+树 只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。所有非终端节点看成是索引,节点中仅含有其子树根节点最大(或最小)的关键字,不包含查找的有效信息。B+树中所有叶子节点都是通过指针连接在一起。 B+ 树的优点在于: 由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率。 B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。 B和B+树的区别在于,B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。 总结:为什么使用B+树? 1.文件很大,不可能全部存储在内存中,故要存储到磁盘上 2.索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(为什么使用B-/+Tree,还跟磁盘存取原理有关,具体看下边分析) 3.局部性原理与磁盘预读,预读的长度一般为页(page)的整倍数,(在许多操作系统中,页得大小通常为4k) 4.数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样 每个节点只需要一次I/O 就可以完全载入,(由于节点中有两个数组,所以地址连续)。而红黑树这种结构, h 明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性。 为什么B+树比B树更适合做索引? 1.B+树磁盘读写代价更低: B+的内部结点并没有指向关键字具体信息的指针,即内部节点不存储数据。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。 2.B+tree的查询效率更加稳定: 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。 在MySQL中,最常用的两个存储引擎是MyISAM和InnoDB,它们对索引的实现方式是不同的。 MyISAM data存的是数据地址。索引是索引,数据是数据。 InnoDB data存的是数据本身。索引也是数据。 */
15. GC
1. 互相引用会不会清除?
循环引用,就看这个循环引用是否挂在根上,
假设挂在根上且这个根还被JVM的Java代码所运行的话,就不会GC掉,假设说这个根已经被释放掉了。这个对象不挂在跟上了。那个这个对象就会被GC掉。
2. java dump文件怎么生成和分析-JVM调优
1. 查看整个JVM内存状态 jmap -heap [pid] 2. 查看JVM堆中对象详细占用情况
jmap -histo [pid] 3. 导出整个JVM 中内存信息,可以利用其它工具打开dump文件分析,例如jdk自带的visualvm工具 jmap -dump:file=文件名.dump [pid] jmap -dump:format=b,file=文件名 [pid] format=b指定为二进制格式文件
3. 可视化工具有哪些
1.JConsole JConsole工具在JDK/bin目录下,启动JConsole后,将自动搜索本机运行的jvm进程,不需要jps命令来查询指定。双击其中一个jvm进程即可开始监控,也可使用“远程进程”来连接远程服务器。 进入JConsole主界面,有“概述”、“内存”、“线程”、“类”、“VM摘要”和"Mbean"六个页签: 2.VisualVM VisualVM是一个集成多个JDK命令行工具的可视化工具。VisualVM基于NetBeans平台开发,它具备了插件扩展功能的特性,通过插件的扩展,可用于显示虚拟机进程及进程的配置和环境信息(jps,jinfo),监视应用程序的CPU、GC、堆、方法区及线程的信息(jstat、jstack)等。VisualVM在JDK/bin目录下。 3.jprofiler
16. 去除ArrayList里面的偶数
迭代器
import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class A1 { public static void main(String[] args) { List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); list.add(4); list.add(6); System.out.println("删除前:" + list); int size = list.size(); Iterator<Integer> it = list.iterator(); for (int i = 0; i < size; i++) { if (it.next() % 2 == 0) { it.remove(); } } System.out.println("删除后:" + list); } }
二面
1. GC
2. 数据库隔离级别以及实现原理
对应隔离级别 1.READ UNCOMMITTED:读未提交,不处理,会出现脏读,不可重复读,幻读。 2.READ COMMITTED:读已提交,只读提交的数据,无脏读,但这种级别会出现读取旧数据的现象,不可重复读,大多数数据库系统的默认隔离级别。 3.REPEATABLE READ:可重复读,加行锁,两次读之间不会有修改,无脏读无重复读;保证了每行的记录的结果是一致的。但是无法解决幻读 4.SERIALIZABLE: 串行化,加表锁,强制事务串行执行,无所有问题,不会出现脏读,不可重复读,幻读。由于他大量加上锁,导致大量的请求超时,因此性能会比较低下,需要数据一致性且并发量不需要那么大的时候才可能考虑这个隔离级别。 隔离级别原理 READ_UNCOMMITED 的原理: 1,事务对当前被读取的数据不加锁; 2,事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级共享锁,直到事务结束才释放。 // 1,事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,能读到事务2对该记录的修改版本,即使该修改尚未被提交。 // 2,事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。 READ_COMMITED 的原理: 1,事务对当前被读取的数据加 行级共享锁(当读到时才加锁),一旦读完该行,立即释放该行级共享锁; 2,事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。 // 1,事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,读到的只能是事务2对其更新前的版本,要不就是事务2提交后的版本。 // 2,事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。 REPEATABLE READ 的原理: 1,事务在读取某数据的瞬间(就是开始读取的瞬间),必须先对其加 行级共享锁,直到事务结束才释放; 2,事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。 // 1,事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,读到的仍然是第一次读取的那个版本。 // 2,事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。 SERIALIZABLE 的原理: 1,事务在读取数据时,必须先对其加 表级共享锁 ,直到事务结束才释放; 2,事务在更新数据时,必须先对其加 表级排他锁 ,直到事务结束才释放。 // 1,事务1正在读取A表中的记录时,则事务2也能读取A表,但不能对A表做更新、新增、删除,直到事务1结束。 // 2,事务1正在更新A表中的记录时,则事务2不能读取A表的任意记录,更不可能对A表做更新、新增、删除,直到事务1结束。
数据库锁// 数据库锁出现的目的:处理并发问题 锁分类 从数据库系统角度分为三种:排他锁、共享锁、更新锁。 从程序员角度分为两种:一种是悲观锁,一种乐观锁。 悲观锁按使用性质划分:排他锁、共享锁、更新锁。 悲观锁按作用范围划分:行锁、表锁。 乐观锁实现方式:版本号,时间戳。 数据库规定同一资源上不能同时共存共享锁和排他锁。 一、悲观锁(Pessimistic Lock) 顾名思义,很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人拿这个数据就会block(阻塞),直到它拿锁。传统的关系数据库里用到了很多这种锁机制,比如行锁、表锁、读锁、写锁等,都是在操作之前先上锁。 1. 共享锁(Share Lock) S锁,也叫读锁,用于所有的只读数据操作。共享锁是非独占的,允许多个并发事务读取其锁定的资源。 性质 1. 多个事务可封锁同一个共享页; 2. 任何事务都不能修改该页; 3. 通常是该页被读取完毕,S锁立即被释放。 // 在SQL Server中,默认情况下,数据被读取后,立即释放共享锁。 // 例如,执行查询语句“SELECT * FROM my_table”时,首先锁定第一页,读取之后,释放对第一页的锁定,然后锁定第二页。这样,就允许在读操作过程中,修改未被锁定的第一页。 // 例如,语句“SELECT * FROM my_table HOLDLOCK”就要求在整个查询过程中,保持对表的锁定,直到查询完成才释放锁定。 2. 排他锁(Exclusive Lock) X锁,也叫写锁,表示对数据进行写操作。如果一个事务对对象加了排他锁,其他事务就不能再给它加任何锁了。 性质 1. 仅允许一个事务封锁此页; 2. 其他任何事务必须等到X锁被释放才能对该页进行访问; 3. X锁一直到事务结束才能被释放。 // 产生排他锁的SQL语句如下:select * from ad_plan for update; 3. 更新锁 U锁,在修改操作的初始化阶段用来锁定可能要被修改的资源,这样可以避免使用共享锁造成的死锁现象。 // 因为当使用共享锁时,修改数据的操作分为两步: 1. 首先获得一个共享锁,读取数据, 2. 然后将共享锁升级为排他锁,再执行修改操作。 这样如果有两个或多个事务同时对一个事务申请了共享锁,在修改数据时,这些事务都要将共享锁升级为排他锁。这时,这些事务都不会释放共享锁,而是一直等待对方释放,这样就造成了死锁。 // 如果一个数据在修改前直接申请更新锁,在数据修改时再升级为排他锁,就可以避免死锁。 性质 1. 用来预定要对此页施加X锁,它允许其他事务读,但不允许再施加U锁或X锁; 2. 当被读取的页要被更新时,则升级为X锁; 3. U锁一直到事务结束时才能被释放。 4. 行锁 锁的作用范围是行级别。 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 5. 表锁 锁的作用范围是整张表。 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 6. 页面锁 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。 // 数据库能够确定那些行需要锁的情况下使用行锁,如果不知道会影响哪些行的时候就会使用表锁。 // 举个例子,一个用户表user,有主键id和用户生日birthday。 // 当你使用update … where id=?这样的语句时,数据库明确知道会影响哪一行,它就会使用行锁; // 当你使用update … where birthday=?这样的的语句时,因为事先不知道会影响哪些行就可能会使用表锁。 二、乐观锁(Optimistic Lock) 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以,不会上锁。但是在更新的时候会判断一下在此期间别人有没有更新这个数据,可以使用版本号等机制。 1. 版本号(version) 版本号(记为version):就是给数据增加一个版本标识,在数据库上就是表中增加一个version字段,每次更新把这个字段加1,读取数据的时候把version读出来,更新的时候比较version,如果还是开始读取的version就可以更新了,如果现在的version比老的version大,说明有其他事务更新了该数据,并增加了版本号,这时候得到一个无法更新的通知,用户自行根据这个通知来决定怎么处理,比如重新开始一遍。这里的关键是判断version和更新两个动作需要作为一个原子单元执行,否则在你判断可以更新以后正式更新之前有别的事务修改了version,这个时候你再去更新就可能会覆盖前一个事务做的更新,造成第二类丢失更新,所以你可以使用update … where … and version=”old version”这样的语句,根据返回结果是0还是非0来得到通知,如果是0说明更新没有成功,因为version被改了,如果返回非0说明更新成功。 2. 时间戳(使用数据库服务器的时间戳) 时间戳(timestamp):和版本号基本一样,只是通过时间戳来判断而已,注意时间戳要使用数据库服务器的时间戳不能是业务系统的时间。 3. 待更新字段 待更新字段:和版本号方式相似,只是不增加额外字段,直接使用有效数据字段做版本控制信息,因为有时候我们可能无法改变旧系统的数据库表结构。假设有个待更新字段叫count,先去读取这个count,更新的时候去比较数据库中count的值是不是我期望的值(即开始读的值),如果是就把我修改的count的值更新到该字段,否则更新失败。java的基本类型的原子类型对象如AtomicInteger就是这种思想。 4. 所有字段 所有字段:和待更新字段类似,只是使用所有字段做版本控制信息,只有所有字段都没变化才会执行更新。
3. 乐观锁 & 悲观锁
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
4. 计算机网络
OSI七层
5. 逆时针输出二维矩阵
可以参考 leetcode54螺旋矩阵:https://leetcode-cn.com/problems/spiral-matrix/
class Solution { public List < Integer > spiralOrder(int[][] matrix) { List ans = new ArrayList(); if (matrix.length == 0) return ans; int r1 = 0, r2 = matrix.length - 1; int c1 = 0, c2 = matrix[0].length - 1; while (r1 <= r2 && c1 <= c2) { for (int c = c1; c <= c2; c++) ans.add(matrix[r1][c]); for (int r = r1 + 1; r <= r2; r++) ans.add(matrix[r][c2]); if (r1 < r2 && c1 < c2) { for (int c = c2 - 1; c > c1; c--) ans.add(matrix[r2][c]); for (int r = r2; r > r1; r--) ans.add(matrix[r][c1]); } r1++; r2--; c1++; c2--; } return ans; } }
三面:项目难点
1. 智能体现在哪里?
2. 项目难点是什么?
3. 敏捷开发和传统开发区别是什么?
4. 项目管理的角度提高效率?
5. 印象最深的一次面试?
6. 建议:复盘,及时反省,及时总结,主动分享,扬长避短。

