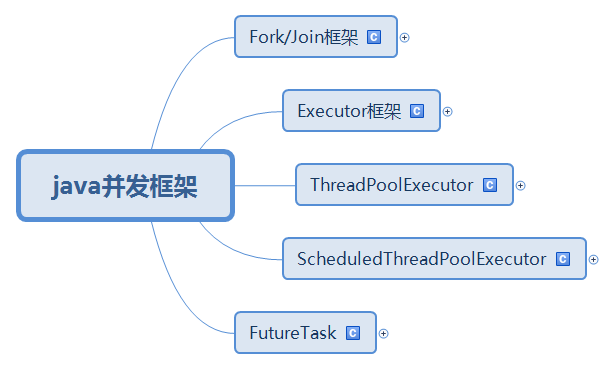
1 java并发框架
2 Fork/Join框架
3 定义
4 一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架
5 核心思想
6 分治
7 fork分解任务,join收集任务
8 工作窃取算法
9 定义
10 工作窃取算法work-stealing: 某个线程从其他队列里窃取任务来执行
11 背景
12 将一个不较大的任务分割为若干个互不依赖的子任务,为了减少线程之间的竞争,把这些子任务分别放到不同的队列里,并未每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。
13 执行快的线程帮助执行慢的线程执行任务,提升整个任务效率
14 为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列
15 窃取任务线程永远从双端队列的尾部拿任务执行
16 被窃取任务线程永远从双端队列的头部拿任务执行
17 优点
18 充分利用线程进行并行计算,减少了线程间的竞争
19 缺点
20 在某些情况下还是存在竞争,比如双端队列里只有一个任务时,并且该算法会消耗了更多的资源,比如创建多个线程和多个双端队列
21 Fork/Join框架设计
22 2大步骤
23 分割任务
24 fork类把大任务分割成子任务,子任务继续分割,直到子任务足够小
25 执行任务并合并结果
26 分割的子任务放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
27 核心类
28 ForkJoinTask
29 子类,用于继承
30 继承子类 RecursiveAction
31 用于没有返回结果的任务
32 继承子类 RecursiveTask
33 用于有返回结果的任务
34 方法
35 fork
36 分解任务
37 join
38 合并任务结果
39 isCompletedAbnormally()
40 检查任务是否已经抛出异常或已经被取消了
41 getException()
42 获取异常
43 ForkJoinWorkerThread
44 执行任务的工作线程
45 ForkJoinPool
46 执行任务ForkJoinTask的线程池,ForkJoinTask需要通过ForkJoinPool来执行
47 submit(task);
48 内部结构
49 ForkJoinTask数组
50 存放任务
51 ForkJoinWorkerThread数组
52 执行任务
53 Executor框架
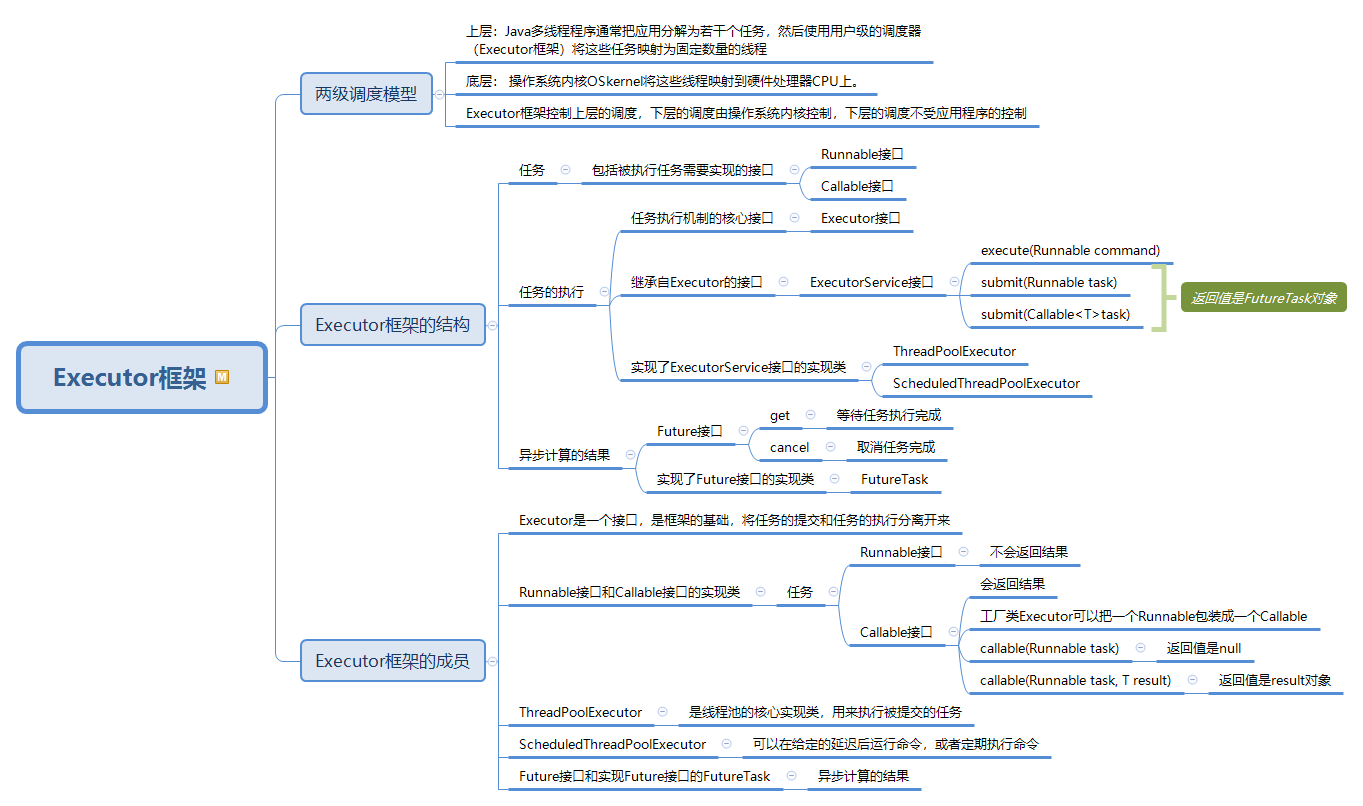
54 两级调度模型
55 上层:Java多线程程序通常把应用分解为若干个任务,然后使用用户级的调度器(Executor框架)将这些任务映射为固定数量的线程
56 底层: 操作系统内核OSkernel将这些线程映射到硬件处理器CPU上。
57 Executor框架控制上层的调度,下层的调度由操作系统内核控制,下层的调度不受应用程序的控制
58 Executor框架的结构
59 任务
60 包括被执行任务需要实现的接口
61 Runnable接口
62 Callable接口
63 任务的执行
64 任务执行机制的核心接口
65 Executor接口
66 继承自Executor的接口
67 ExecutorService接口
68 execute(Runnable command)
69 submit(Runnable task)
70 submit(Callable<T>task)
71 返回值是FutureTask对象
72 实现了ExecutorService接口的实现类
73 ThreadPoolExecutor
74 ScheduledThreadPoolExecutor
75 异步计算的结果
76 Future接口
77 get
78 等待任务执行完成
79 cancel
80 取消任务完成
81 实现了Future接口的实现类
82 FutureTask
83 Executor框架的成员
84 Executor是一个接口,是框架的基础,将任务的提交和任务的执行分离开来
85 Runnable接口和Callable接口的实现类
86 任务
87 Runnable接口
88 不会返回结果
89 Callable接口
90 会返回结果
91 工厂类Executor可以把一个Runnable包装成一个Callable
92 callable(Runnable task)
93 返回值是null
94 callable(Runnable task, T result)
95 返回值是result对象
96 ThreadPoolExecutor
97 是线程池的核心实现类,用来执行被提交的任务
98 ScheduledThreadPoolExecutor
99 可以在给定的延迟后运行命令,或者定期执行命令
100 Future接口和实现Future接口的FutureTask
101 异步计算的结果
102 ThreadPoolExecutor
103 是线程池的核心实现类,用来执行被提交的任务
104 线程池的创建
105 ThreadPoolExecutor
106 corePoolSize
107 线程池中核心线程的数量。当提交一个任务时,线程池会新建一个线程来执行任务,直到当前线程数等于corePoolSize。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
108 maximumPoolSize
109 线程池中允许的最大线程数。线程池的阻塞队列满了之后,如果还有任务提交,如果当前的线程数小于maximumPoolSize,则会新建线程来执行任务。注意,如果使用的是无界队列,该参数也就没有什么效果了。
110 keepAliveTime
111 线程空闲的时间。线程的创建和销毁是需要代价的。线程执行完任务后不会立即销毁,而是继续存活一段时间:keepAliveTime。默认情况下,该参数只有在线程数大于corePoolSize时才会生效。
112 unit
113 keepAliveTime的单位。TimeUnit
114 workQueue
115 用来保存等待执行的任务的阻塞队列,等待的任务必须实现Runnable接口。我们可以选择如下几种:
116 分类
117 ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO。
118 LinkedBlockingQueue:基于链表结构的有界阻塞队列,FIFO。
119 SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作,反之亦然。
120 PriorityBlockingQueue:具有优先界别的无界阻塞队列。
121 threadFactory
122 用于设置创建线程的工厂。可以通过线程工厂给每个创建出来的线程设置更有意义的名字,该对象可以通过Executors.defaultThreadFactory()
123 handler
124 RejectedExecutionHandler,线程池的拒绝策略。所谓拒绝策略,是指将任务添加到线程池中时,线程池拒绝该任务所采取的相应策略。当向线程池中提交任务时,如果此时线程池中的线程已经饱和了,而且阻塞队列也已经满了,则线程池会选择一种拒绝策略来处理该任务。
125 四种拒绝策略
126 AbortPolicy:直接抛出异常,默认策略;
127 CallerRunsPolicy:用调用者所在的线程来执行任务;
128 DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
129 DiscardPolicy:直接丢弃任务;
130 当然我们也可以实现自己的拒绝策略,例如记录日志、持久化存储不能处理的任务等等,实现RejectedExecutionHandler接口自定义即可。
131 工厂类Executors创建3种类型的ThreadPoolExecutor
132 SingleThreadExecutor
133 使用单个worker线程的Executor
134 应用场景
135 适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的应用场景
136 特点
137 corePool和maximumPoolSize均被设置为1
138 使用的是相当于无界的有界阻塞队列LinkedBlockingQueue,所以带来的影响和FixedThreadPool一样。
139 FixedThreadPool
140 固定线程数的线程池
141 应用场景
142 为了满足资源管理的需求,需要限制当前线程数量的应用场景
143 适用于负载比较重的服务器
144 特点
145 corePoolSize 和 maximumPoolSize都设置为创建FixedThreadPool时指定的参数nThreads,意味着当线程池满时且阻塞队列也已经满时,如果继续提交任务,则会直接走拒绝策略
146 默认的拒绝策略,即AbortPolicy,则直接抛出异常。
147 keepAliveTime设置为0L,表示空闲的线程会立刻终止。
148 workQueue则是使用LinkedBlockingQueue,但是没有设置范围,那么则是最大值(Integer.MAX_VALUE),这基本就相当于一个无界队列了。
149 无界队列对线程池的影响
150 1. 当线程池中的线程数量等于corePoolSize 时,如果继续提交任务,该任务会被添加到无界阻塞队列workQueue中,因此线程中的线程数不会超过corePoolSize
151 2. 由于1,使用无界队列时的 maximumPoolSize是一个无效参数
152 3. 由于1和2,使用无界队列时的 keepAliveTime 是一个无效参数
153 4. 不会拒绝任务
154 CachedThreadPool
155 根据需要创建新线程,是大小无界的线程池
156 应用场景
157 适用于执行很多的短期异步任务的小程序
158 适用于负载较轻的服务器
159 特点
160 corePool为0,maximumPoolSize为Integer.MAX_VALUE,这就意味着所有的任务一提交就会加入到阻塞队列中。
161 keepAliveTime这是为60L,unit设置为TimeUnit.SECONDS,意味着空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。
162 阻塞队列采用的SynchronousQueue,每个插入操作都必须等待另一个线程对应的移除操作,此处把主线程提交的任务传递给空闲线程去执行。
163 SynchronousQueue是一个没有元素的阻塞队列,加上corePool = 0 ,maximumPoolSize = Integer.MAX_VALUE,这样就会存在一个问题,如果主线程提交任务的速度远远大于CachedThreadPool的处理速度,则CachedThreadPool会不断地创建新线程来执行任务,这样有可能会导致系统耗尽CPU和内存资源,所以在使用该线程池是,一定要注意控制并发的任务数,否则创建大量的线程可能导致严重的性能问题。
164 重要操作
165 offer
166 主线程执行offer操作与空闲线程执行的poll操作配对成功后,主线程把任务交给空闲线程执行
167 execute
168 执行任务
169 poll
170 让空闲线程在SynchronousQueue中等待60s,如果等待到新任务则执行,否则,空闲线程将终止
171 向线程池提交任务
172 execute()
173 用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功
174 工作原理
175 1. 如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(执行这一步骤需要获取全局锁)
176 2. 如果运行的线程等于或多于corePoolSize(完成预热之后),则将任务加入BlockingQueue,这一步不需要全局锁
177 3. 如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务 (执行这一步骤需要获取全局锁)
178 4. 如果创建的线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExcution()方法
179 submit()
180 用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过它可以判定任务是否执行成功。
181 future.get()方法用来获取返回值,它会阻塞当前线程直到任务完成
182 future.get(long timeout, TimeUnit unit) 方法会阻塞当前线程一段时间后立即返回,这时候可能任务没有执行完
183 关闭线程池
184 原理
185 遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断地的任务可能永远无法终止
186 方法
187 shutdown
188 只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程
189 shutdownNow
190 首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,任务不一定要执行完
191 合理配置线程池
192 任务的性质
193 CPU密集型任务
194 N(cpu)+1 个线程的线程池
195 IO密集型任务
196 2*N(cpu) 个线程的线程池
197 混合型任务
198 拆分成一个CPU密集型任务和一个IO密集型任务
199 任务的优先级
200 高
201 中
202 低
203 用PriorityBlockingQueue
204 任务的执行时间
205 长
206 中
207 短
208 任务的依赖性
209 是否依赖其他系统资源,比如数据库连接
210 等待返回结果的时间越长,CPU空闲时间越长,那么线程数应该设置的越大,以便更好利用线程池
211 建议使用有界队列。有界队列能够提高系统的稳定性和预警能力 ,无界队列会直接撑爆内存,导致系统不可用
212 用PriorityBlockingQueue ,让执行时间短的任务先执行
213 线程池的监控
214 方便出问题时,可以根据线程池的使用情况,快速定位问题
215 参数
216 taskCount
217 线程池需要执行的任务数量
218 completedTaskCount
219 线程池在运行过程中已经完成的任务数量
220 largestPoolSize
221 线程池曾将创建过的最大线程数量。如果该数字等于线程池的最大大小,表示线程池曾经满过
222 getPoolSize
223 线程池的线程数量
224 getActiveCount
225 获取活动的线程数
226 重写方法
227 beforeExecute()
228 任务执行前
229 afterExecute()
230 任务执行后
231 terminated()
232 线程池关闭前
233 ScheduledThreadPoolExecutor
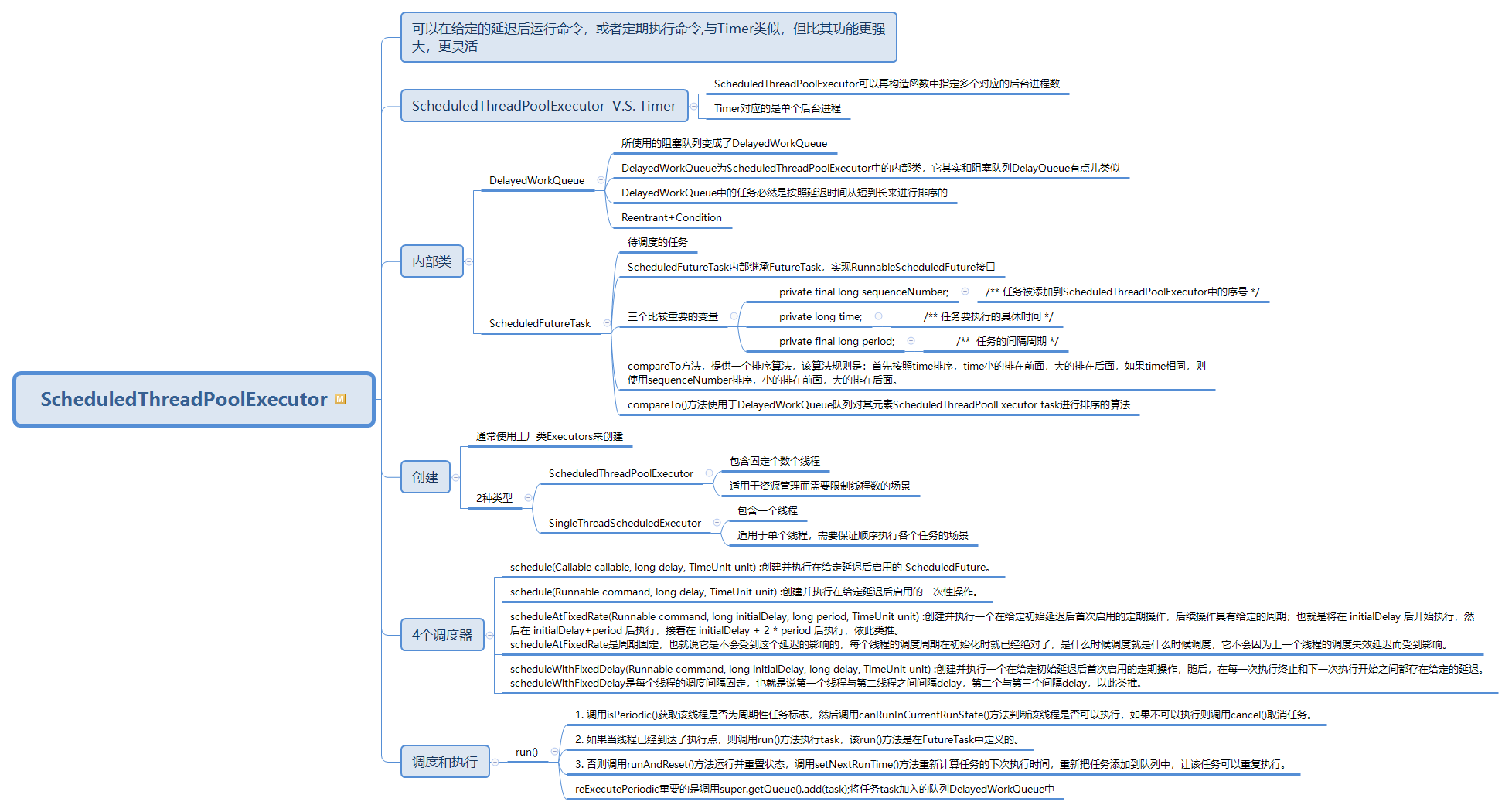
234 可以在给定的延迟后运行命令,或者定期执行命令,与Timer类似,但比其功能更强大,更灵活
235 ScheduledThreadPoolExecutor V.S. Timer
236 ScheduledThreadPoolExecutor可以再构造函数中指定多个对应的后台进程数
237 Timer对应的是单个后台进程
238 内部类
239 DelayedWorkQueue
240 所使用的阻塞队列变成了DelayedWorkQueue
241 DelayedWorkQueue为ScheduledThreadPoolExecutor中的内部类,它其实和阻塞队列DelayQueue有点儿类似
242 DelayedWorkQueue中的任务必然是按照延迟时间从短到长来进行排序的
243 Reentrant+Condition
244 ScheduledFutureTask
245 待调度的任务
246 ScheduledFutureTask内部继承FutureTask,实现RunnableScheduledFuture接口
247 三个比较重要的变量
248 private final long sequenceNumber;
249 /** 任务被添加到ScheduledThreadPoolExecutor中的序号 */
250 private long time;
251 /** 任务要执行的具体时间 */
252 private final long period;
253 /** 任务的间隔周期 */
254 compareTo方法,提供一个排序算法,该算法规则是:首先按照time排序,time小的排在前面,大的排在后面,如果time相同,则使用sequenceNumber排序,小的排在前面,大的排在后面。
255 compareTo()方法使用于DelayedWorkQueue队列对其元素ScheduledThreadPoolExecutor task进行排序的算法
256 创建
257 通常使用工厂类Executors来创建
258 2种类型
259 ScheduledThreadPoolExecutor
260 包含固定个数个线程
261 适用于资源管理而需要限制线程数的场景
262 SingleThreadScheduledExecutor
263 包含一个线程
264 适用于单个线程,需要保证顺序执行各个任务的场景
265 4个调度器
266 schedule(Callable callable, long delay, TimeUnit unit) :创建并执行在给定延迟后启用的 ScheduledFuture。
267 schedule(Runnable command, long delay, TimeUnit unit) :创建并执行在给定延迟后启用的一次性操作。
268 scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) :创建并执行一个在给定初始延迟后首次启用的定期操作,后续操作具有给定的周期;也就是将在 initialDelay 后开始执行,然后在 initialDelay+period 后执行,接着在 initialDelay + 2 * period 后执行,依此类推。
269 scheduleAtFixedRate是周期固定,也就说它是不会受到这个延迟的影响的,每个线程的调度周期在初始化时就已经绝对了,是什么时候调度就是什么时候调度,它不会因为上一个线程的调度失效延迟而受到影响。
270 scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) :创建并执行一个在给定初始延迟后首次启用的定期操作,随后,在每一次执行终止和下一次执行开始之间都存在给定的延迟。
271 scheduleWithFixedDelay是每个线程的调度间隔固定,也就是说第一个线程与第二线程之间间隔delay,第二个与第三个间隔delay,以此类推。
272 调度和执行
273 run()
274 1. 调用isPeriodic()获取该线程是否为周期性任务标志,然后调用canRunInCurrentRunState()方法判断该线程是否可以执行,如果不可以执行则调用cancel()取消任务。
275 2. 如果当线程已经到达了执行点,则调用run()方法执行task,该run()方法是在FutureTask中定义的。
276 3. 否则调用runAndReset()方法运行并重置状态,调用setNextRunTime()方法重新计算任务的下次执行时间,重新把任务添加到队列中,让该任务可以重复执行。
277 reExecutePeriodic重要的是调用super.getQueue().add(task);将任务task加入的队列DelayedWorkQueue中
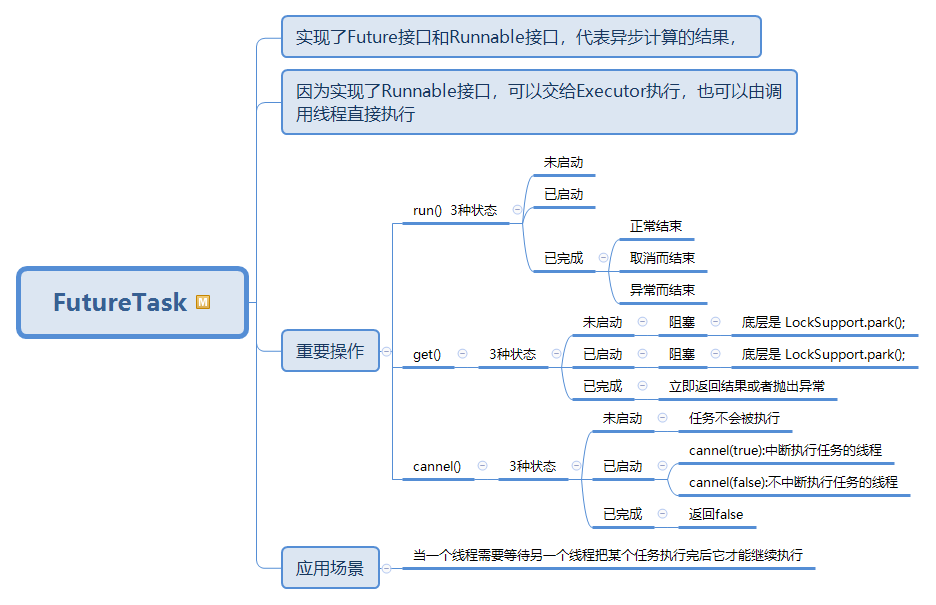
278 FutureTask
279 实现了Future接口和Runnable接口,代表异步计算的结果,
280 因为实现了Runnable接口,可以交给Executor执行,也可以由调用线程直接执行
281 重要操作
282 run() 3种状态
283 未启动
284 已启动
285 已完成
286 正常结束
287 取消而结束
288 异常而结束
289 get()
290 3种状态
291 未启动
292 阻塞
293 底层是 LockSupport.park();
294 已启动
295 阻塞
296 底层是 LockSupport.park();
297 已完成
298 立即返回结果或者抛出异常
299 cannel()
300 3种状态
301 未启动
302 任务不会被执行
303 已启动
304 cannel(true):中断执行任务的线程
305 cannel(false):不中断执行任务的线程
306 已完成
307 返回false
308 应用场景
309 当一个线程需要等待另一个线程把某个任务执行完后它才能继续执行





 浙公网安备 33010602011771号
浙公网安备 33010602011771号