03 elasticsearch学习笔记-IK分词器?
1. 什么是IK分词器

2. 下载IK分词器
下载地址,版本要和ES的版本对应上
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.3.1
注意下载zip版本
下载完毕后,放入到我们的elasticsearch/plugins/ik插件目录里即可

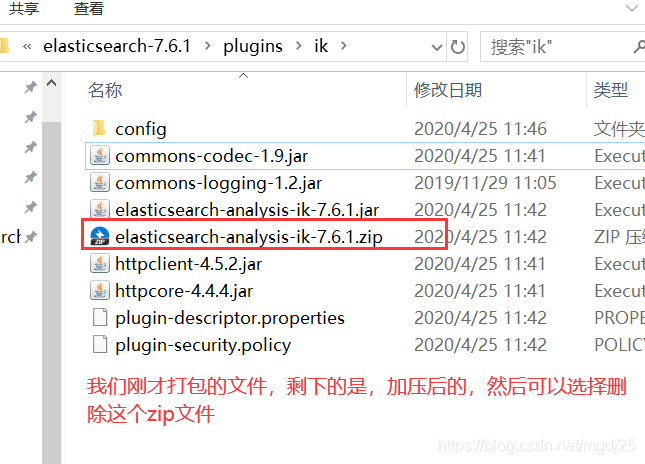
-
重启观察ES,可以看到IK分词器被加载了!

-
elasticsearch-plugin可以通过这个命令查看加载进来的插件

docker下载的安装的查看方法
root@haima-PC:/usr/local/docker/efk/docker_compose_efk# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c43439e99ff0 docker_compose_efk_fluentd "/bin/entrypoint.sh …" 29 seconds ago Up 27 seconds 5140/tcp, 0.0.0.0:24224->24224/tcp, 0.0.0.0:24224->24224/udp docker_compose_efk_fluentd_1
00eda4c1585d docker_compose_efk_kibana "/usr/local/bin/dumb…" 29 seconds ago Up 26 seconds 0.0.0.0:5601->5601/tcp docker_compose_efk_kibana_1
6e2e42f9e3ca docker.elastic.co/elasticsearch/elasticsearch:7.3.1 "/usr/local/bin/dock…" 31 seconds ago Up 29 seconds 0.0.0.0:9200->9200/tcp, 9300/tcp docker_compose_efk_elasticsearch_1
root@haima-PC:/usr/local/docker/efk/docker_compose_efk# docker exec -it docker_compose_efk_elasticsearch_1 bash ./bin/elasticsearch-plugin list
ik
详细查看我github里的readme.md
https://github.com/haimait/docker_compose_efk
3. 使用kibana测试!
查看不同的分词效果
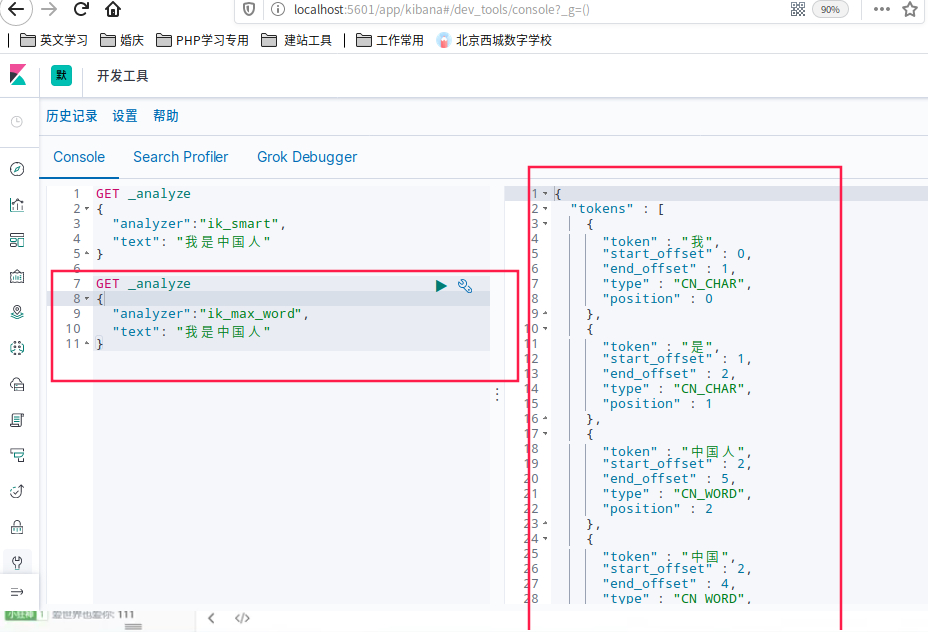
ik_smart和ik_max_word,其中ik_smart为最少切分
GET _analyze
{
"analyzer":"ik_smart",
"text": "我是中国人"
}
划出了3组
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}

ik_max_word为最细粒度划分,穷尽词库的可能
GET _analyze
{
"analyzer":"ik_max_word",
"text": "我是中国人"
}
划出了5组
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
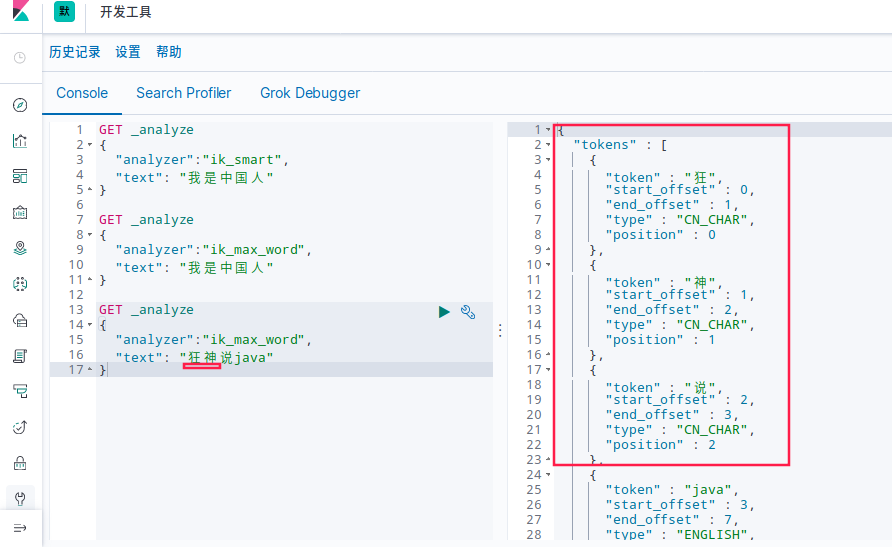
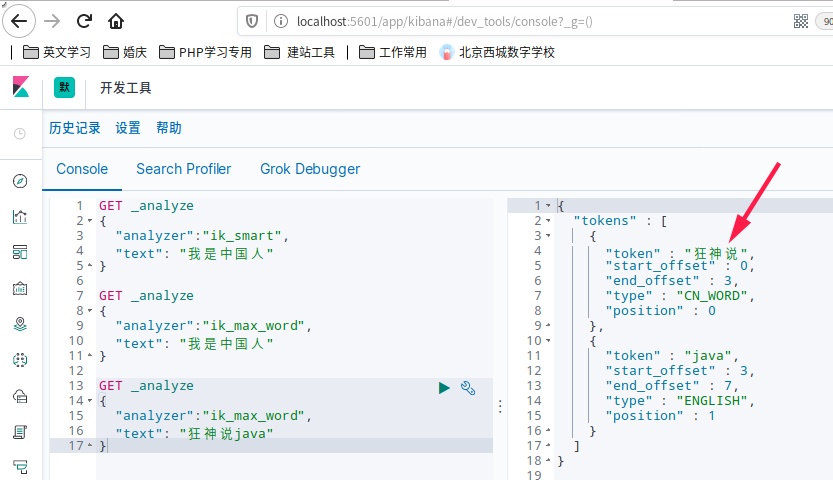
测试狂神说java
发现狂神说被分词器拆分开了,这里我们不想让它拆开,就需要在分词器中添加一个自己的词典,把自己的词放到自己的词典里
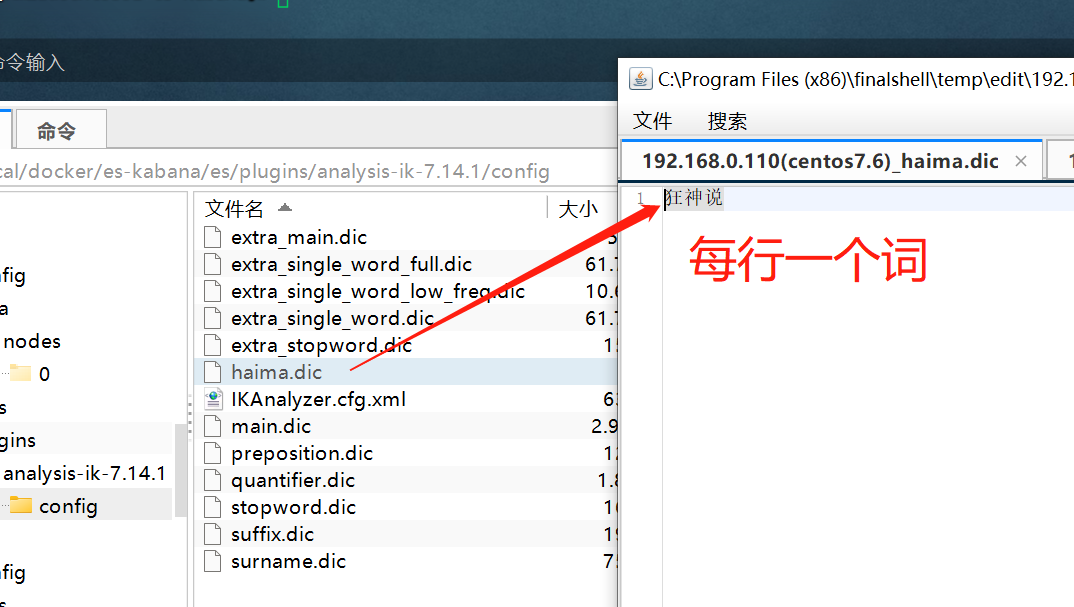
4. 创建自定义词典
- 创建
haima.dic
vim /elasticsearch/es/plugins/ik/config/haima.dic
写入 狂神说
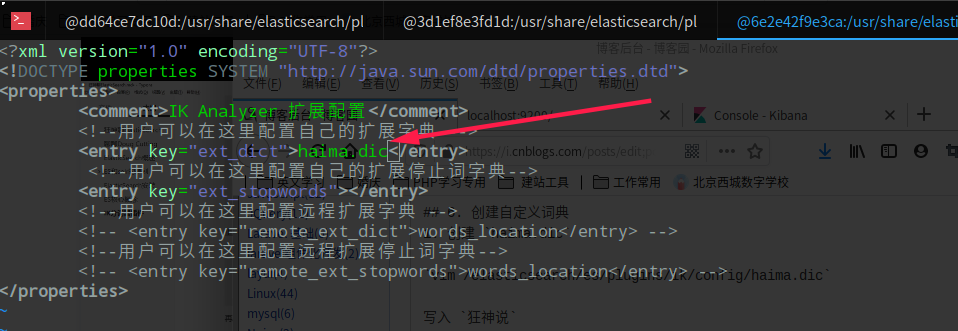
- 把自定义的
haima.dic字典,载入到配置文件里
vim /elasticsearch/es/plugins/ik/config/IKAnalyzer.cfg.xml
- 重启es服务
root@haima-PC:/usr/local/docker/efk/docker_compose_efk/elasticsearch/es/plugins/ik/config# docker restart docker_compose_efk_elasticsearch_1
docker_compose_efk_elasticsearch_1
- 再看一下分词器,
狂神说已经不会被分开了
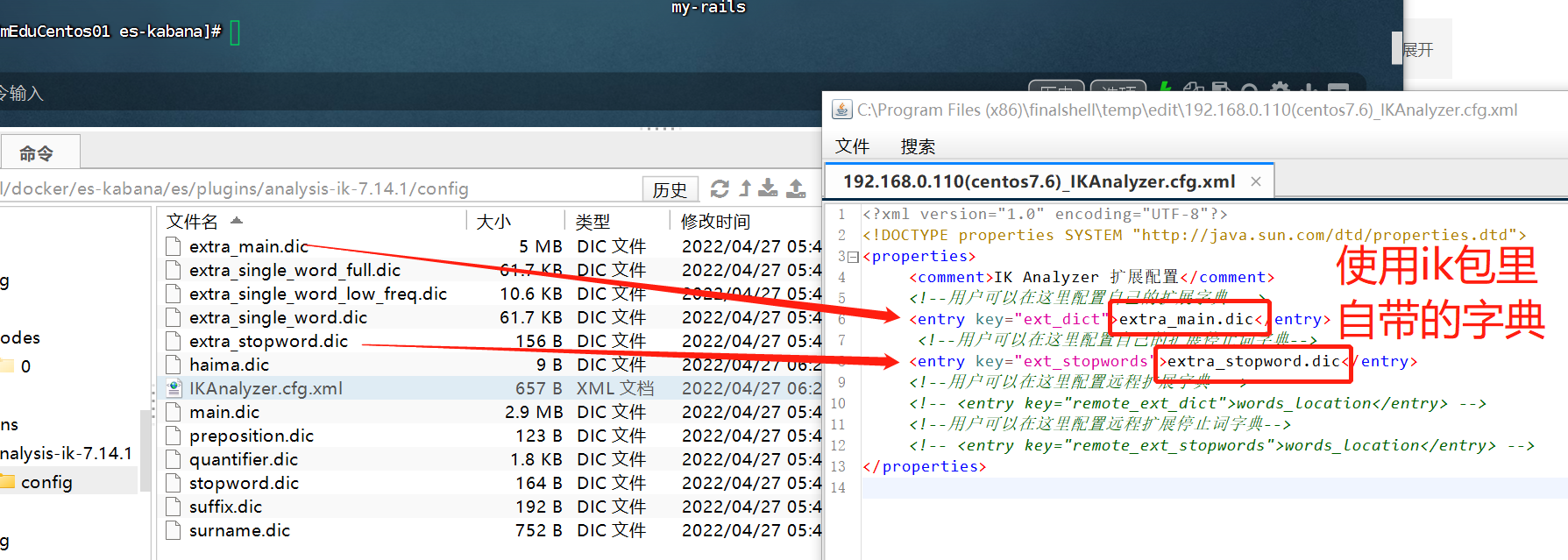
- 使用ik分词包里自带的词典
5. Analysis
analysis(只是一个概念),文本分析是将全文本转换为一系列单词的过程,也叫分词。analysis是通
过analyzer(分词器)来实现的,可以使用Elasticsearch内置的分词器,也可以自己去定制一些分词
器。 除了在数据写入的时候进行分词处理,那么在查询的时候也可以使用分析器对查询语句进行分词。
anaylzer是由三部分组成,例如有
Hello a World, the world is beautifu
Analyzer的处理过程
分词器名称 处理过程
Standard Analyzer 默认的分词器,按词切分,小写处理
Simple Analyzer 按照非字母切分(符号被过滤),小写处理
Stop Analyzer 小写处理,停用词过滤(the, a, this)
Whitespace Analyzer 按照空格切分,不转小写
Keyword Analyzer 不分词,直接将输入当做输出
Pattern Analyzer 正则表达式,默认是\W+(非字符串分隔)
1. Character Filter: 将文本中html标签剔除掉。
2. Tokenizer: 按照规则进行分词,在英文中按照空格分词。
3. Token Filter: 去掉stop world(停顿词,a, an, the, is, are等),然后转换小写
内置分词器
| 分词器名称 | 分词器名称 |
|---|---|
| 分词器名称 | 分词器名称 |
| Simple Analyzer | 按照非字母切分(符号被过滤),小写处理 |
| Stop Analyzer | 小写处理,停用词过滤(the, a, this) |
| Whitespace Analyzer | 按照空格切分,不转小写 |
| Keyword Analyzer | 不分词,直接将输入当做输出 |
| Pattern Analyzer | 正则表达式,默认是\W+(非字符串分隔) |
** 内置分词器示例**
5.2.1 Standard Analyzer
GET _analyze
{
"analyzer": "standard",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.2 Simple Analyzer
GET _analyze
{
"analyzer": "simple",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.3 Stop Analyzer
GET _analyze
{
"analyzer": "stop",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.4 Whitespace Analyzer
GET _analyze
{
"analyzer": "whitespace",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.5 Keyword Analyzer
GET _analyze
{
"analyzer": "keyword",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.6 Pattern Analyzer
GET _analyze
{
"analyzer": "pattern",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
[Haima的博客]
http://www.cnblogs.com/haima/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号