01 python爬虫-bs4
爬虫原理
- 模拟浏览器的行为,通过网络请求将目标网页抓取后本地
- 使用一定的匹配规则,将目标网页中需要的数据攫取出来,把不需要的过滤掉。
- 根据需要,把提取出来的数据存储到磁盘中(json\csv\excel\数据库)。
目标
https://movie.douban.com/cinema/nowplaying/changsha/
要爬取的目标源代码
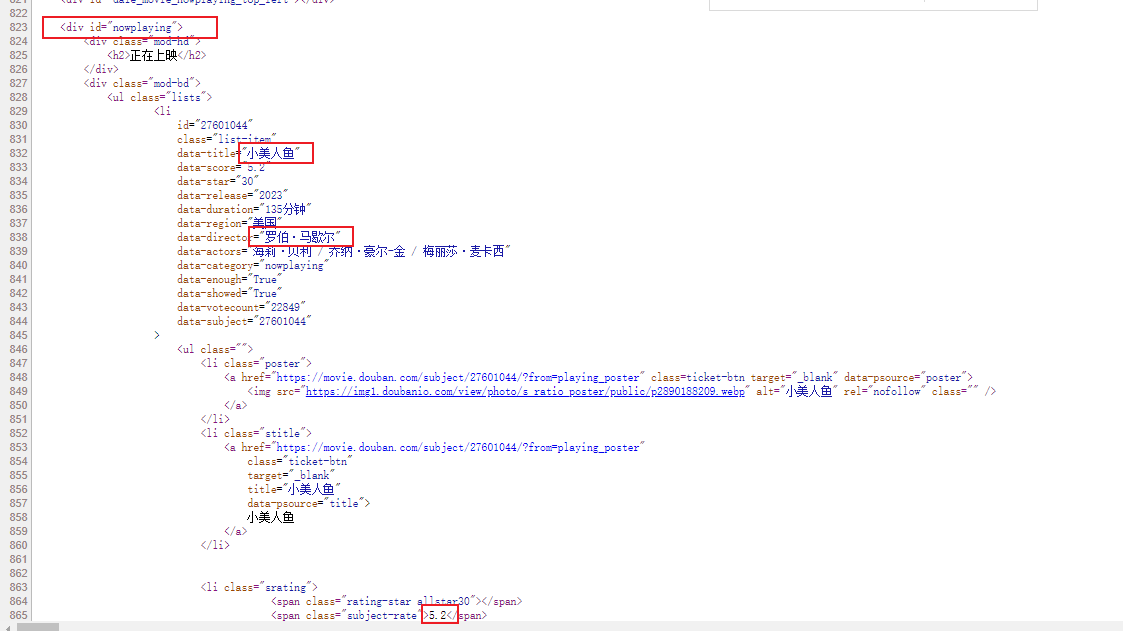
代码
import requests
import json
import csv
from bs4 import BeautifulSoup
# pip install bs4 -i 清华源
def get_page():
q_url = 'https://movie.douban.com/cinema/nowplaying/changsha/'
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 UOS'
}
r = requests.get(q_url, headers=headers)
r.encoding = 'utf-8'
res = r.text
return res
def parser_text(content):
# 把页面源代码交给BeautifulSoup进行处理,生成bs对象
# 从bs对象中查找数据
# find(标签,属性=值)
# find_all(标签,属性=值)
soup = BeautifulSoup(content, 'html.parser')
# 找属性id=nowplaying的div 下的 class=list-item 的所有li find找一个 find_all找所有
# li_list = soup.find('div', attrs={'id': 'nowplaying'}).find_all('li', class_="list-item")
# attrs 和 class_ 是一个意思,此时可以避免class关键字
li_list = soup.find('div', attrs={'id': 'nowplaying'}).find_all('li', attrs={"class": "list-item"})
movice_list = list()
for li in li_list:
moviceKV = {}
moviceKV['title'] = li.get('data-title')
moviceKV['data_actors'] = li.get('data-actors') # 作者
img = li.find('img') # 找li标签下的img标签
moviceKV['img'] = img.get('src') # 获取src的值
# 下载图片
save_data_b(moviceKV['img'])
# 评分
subject_rate_span = li.find('span', attrs={'class': 'subject-rate'})
if subject_rate_span is None:
moviceKV['subject_rate'] = "暂无评论"
else:
moviceKV['subject_rate'] = subject_rate_span.text # 取span中的值
movice_list.append(moviceKV)
# print("======" * 10)
return movice_list
# 存为json
def save_data_json(data_list):
with open('douban.com.json', 'w', encoding='utf-8') as fp:
json.dump(data_list, fp, ensure_ascii=False)
# 存为CSV
def save_data_csv(data_list):
headers = data_list[0].keys() # 获取标题
with open('test2.csv', 'w', newline='', encoding='utf-8') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
f_csv.writerows(data_list)
# 下载图片 、 mp4 、 zip 都可以这样下载
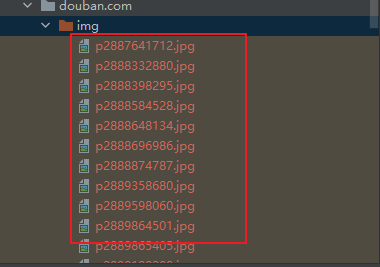
def save_data_b(url):
# https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2892635176.jpg
r = requests.get(url)
img_name = url.split("/")[-1] # p2892635176.jpg
if __name__ == '__main__':
# 获取页面源代码
text = get_page()
# 解析源代码,获取需要的信息
data_list = parser_text(text)
# 存为json数据
# save_data_json(data_list)
# 存为csv数据
save_data_csv(data_list)
结果
生成的csv
title,data_actors,img,subject_rate
温柔壳,王子文 / 尹昉 / 咏梅,https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2892635176.jpg,7.5
小美人鱼,海莉·贝利 / 乔纳·豪尔-金 / 梅丽莎·麦卡西,https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2890188209.jpg,5.2
下载的图片
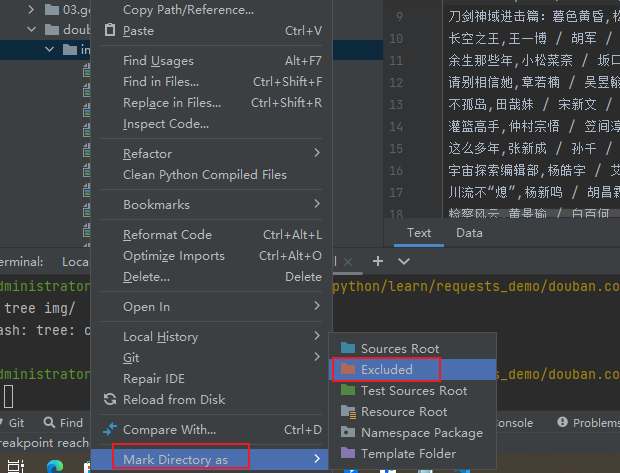
注意:
下载图片时把 img 文件夹标记为忽略 PyCharm 索引,不然爬取过程中,会越来越卡
操作方法
[Haima的博客]
http://www.cnblogs.com/haima/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号