python 正则表达式与JSON字符串
目录
手册地址:
https://www.runoob.com/regexp/regexp-metachar.html
在线工具:
http://c.runoob.com/front-end/854
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配(一个字符串是否与我们所设定这样的字符序列相匹配)。
快速检索文本,实现一些替换文本的操作
- 检查一串数字是否电话号码
- 检测一个字符串是否是email
- 把一个文本里指定的单词替换为另外一个单词
注意:
能使用底层包里自带的函数解决问题(string,strings,strcnov),首先使用库函数,其次再选择正则表达式(不好理解).
概括单字符集 匹配单字符

import re
# 概括单字符集
a = 'Python 11\t11Java&678p\nh\rp'
# \d 匹配任意数字,等价于 [0-9]。 \D 匹配任意非数字
# \w 匹配数字字母下划线 \W 匹配非数字字母下划线
# \s 匹配任意空白字符,等价于 [\t\n\r\f]。 \S 匹配任意非空字符
# . 匹配换行符之外\n的其它所有字符 - 匹配范围 a-zA-Z0-9
r1 = re.findall('\d',a)
r2 = re.findall('[0-9]',a) #匹配任何数字。类似于 [0123456789]
w1 = re.findall('\D',a)
w2 = re.findall('[^0-9]',a) #匹配除了数字外的字符
print(r1) #['1', '1', '1', '1', '6', '7', '8']
print(r2) #['1', '1', '1', '1', '6', '7', '8']
print(w1) #['P', 'y', 't', 'h', 'o', 'n', ' ', '\t', 'J', 'a', 'v', 'a', '&', 'p', '\n', 'h', '\r', 'p']
print(w2) #['P', 'y', 't', 'h', 'o', 'n', ' ', '\t', 'J', 'a', 'v', 'a', '&', 'p', '\n', 'h', '\r', 'p']
x1 = re.findall('\w',a)
x2 = re.findall('[A-Za-z0-9_]',a) #匹配数字字母下划线
x3 = re.findall('\W',a) #非匹配数字字母下划线
x4 = re.findall('[^A-Za-z0-9_]',a)
print(x1) # ['P', 'y', 't', 'h', 'o', 'n', '1', '1', '1', '1', 'J', 'a', 'v', 'a', '6', '7', '8', 'p', 'h', 'p']
print(x2) # ['P', 'y', 't', 'h', 'o', 'n', '1', '1', '1', '1', 'J', 'a', 'v', 'a', '6', '7', '8', 'p', 'h', 'p']
print(x3) #[' ', '\t', '&', '\n', '\r']
print(x4) #[' ', '\t', '&', '\n', '\r']
y1 = re.findall('\s',a)
y2 = re.findall('\S',a)
print(y1) #[' ', '\t', '\n', '\r']
print(y2) #['P', 'y', 't', 'h', 'o', 'n', '1', '1', '1', '1', 'J', 'a', 'v', 'a', '&', '6', '7', '8', 'p', 'h', 'p']
匹配字符集
import re
a = 'c0c++7Java8c9Python6Javascript'
# 使用python的内置函数
print(a.find('Python')>-1) # 输出 True 如果没有匹配到返回-1,否则返回第一个匹配到的位置
print('Python' in a) # 输出 True
# 使用正规表达式
r=re.findall('Python',a) #['Python']
print(r)
if len(r)>0:
print('ok')
else:
print('no')
# 输出:
# True
# True
# ['Python']
# ok
普通字符与元字符
- 普通字符 'Python'
- 元字符
\d
正则表达式 - 元字符
下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为:
https://www.runoob.com/regexp/regexp-metachar.html
元字符和普通的字符的混用
a = 'abc , acc , adc , aec , afc , ahc'
- 匹配字符串中间是cf的
- 匹配字符串中间 不是cf的
- 匹配字符串中间字母 是c-f的
- 普通字符(方括号两边的)a和c是用来定界的,方括号里面的cf元字符是用来匹配的规则,cf是c或f的关系
import re
# 匹配字符串中间是cf的
a = 'abc , acc , adc , aec , afc , ahc'
r = re.findall('a[cf]c',a) #普通字符a和c是用来定界的,cf元字符是用来匹配的
print(r) #['acc', 'afc']
# 匹配字符串中间 不是cf的
r2 = re.findall('a[^cf]c',a)
print(r2) #['abc', 'adc', 'aec', 'ahc']
# 匹配字符串中间字母 是c-f的
r3 = re.findall('a[c-f]c',a)
print(r3) #['acc', 'adc', 'aec', 'afc']
数量词{整数|*|+|?} 匹配多少次
| 符号 | 含义 |
|---|---|
| 整数 | 匹配指定长度的字母 |
- | 匹配0次或者无限多次
- | 匹配1次或者无限多次
? | 匹配0次或者1次 可以用来过滤单词后面不要的字母,去重

-
{整数} 匹配指定长度的字母
import re # 匹配指定长度的字母 a = 'Python 111\t11Java&678php66javascript\nh\rp' r1 =re.findall('[A-Za-z]{3}',a) # 每次匹配3个长度的字母 print(r1) #['Pyt', 'hon', 'Jav', 'php', 'jav', 'asc', 'rip'] -
{*} 匹配0次或者无限多次
-
{+} 匹配1次或者无限多次
-
{?} 匹配0次或者1次 可以用来过滤单词后面不要的字母,去重
import re # 数量词 a = 'pytho0python1pythonn2' # * 匹配0次或者无限多次 r1 = re.findall('python*',a) print(r1) # 输出 ['pytho', 'python', 'pythonn'] # + 匹配1次或者无限多次 r2 = re.findall('python+',a) print(r2) # 输出 ['python', 'pythonn'] # ? 匹配0次或者1次 r3 = re.findall('python?',a) print(r3) # 输出 ['pytho', 'python', 'python']
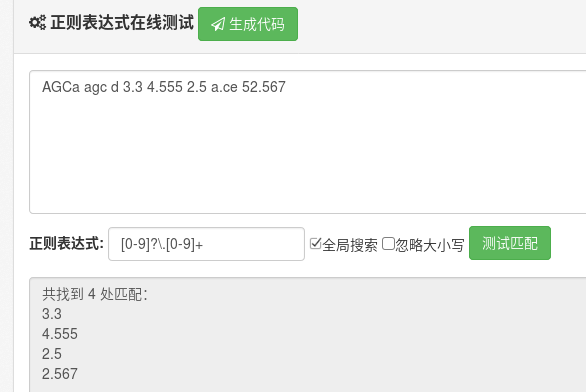
[0-9]?\.[0-9]+ 小数点前匹配0到1次,\是转义小数点,小数点后匹配1次或者无限多次
?在非贪婪模式和数量词使用时是不同的意义
- ?在
非贪婪模里是用来转换贪婪与非贪婪模式的 - ?在
数量词里是表示匹配0次或者1次
a = 'pytho0python1pythonn2'
# ? 在数量词中 匹配0次或者1次
r1 = re.findall('python?',a)
print(r1) # 输出 ['pytho', 'python', 'python']
# ?在`非贪婪模`里
r2 = re.findall('python{1,2}?',a)
print(r2) #['python', 'python']
# `贪婪模`
r2 = re.findall('python{1,2}',a)
print(r2) #['python', 'pythonn']
贪婪模式 匹配指定长度的字符串
import re
# 贪婪模式
a = 'Python 111\t11Java&678php66javascript\nh\rp'
# \d 匹配任意数字,等价于 [0-9]。 \D 匹配任意非数字
# \w 匹配数字字母下划线 \W 匹配非数字字母下划线
# \s 匹配任意空白字符,等价于 [\t\n\r\f]。 \S 匹配任意非空字符
r1 =re.findall('[A-Za-z]{3,10}',a) #贪婪模式 每次匹配3-10个长度的字母
r2 =re.findall('[A-Za-z]{3,}',a) #贪婪模式 每次匹配3到任意个长度的字母
print(r1) #['Python', 'Java', 'php', 'javascript']
print(r1) #['Python', 'Java', 'php', 'javascript']
非贪婪模式 匹配指定长度的字符串
花括号后加上?号表示非贪婪模式
import re
# 非贪婪模式
a = 'Python 111\t11Java&678php66javascript\nh\rp'
# \d 匹配任意数字,等价于 [0-9]。 \D 匹配任意非数字
# \w 匹配数字字母下划线 \W 匹配非数字字母下划线
# \s 匹配任意空白字符,等价于 [\t\n\r\f]。 \S 匹配任意非空字符
r1 =re.findall('[A-Za-z]{3,10}?',a) # ?非贪婪模式 每次匹配3个长度的字母
r2 =re.findall('[A-Za-z]{3,}?',a) # ?非贪婪模式 每次匹配3任意个长度的字母
print(r1) #['Pyt', 'hon', 'Jav', 'php', 'jav', 'asc', 'rip']
print(r1) #['Pyt', 'hon', 'Jav', 'php', 'jav', 'asc', 'rip']
边界匹配
- ^ 边界的开始
- $ 边界的结束
# 边界匹配
import re
qq = '100000001'
# 4~8
# ^边界的开始 $边界的结束
r = re.findall('^\d{4,8}$',qq)
print(r) #打印 []
r1 = re.findall('^000',qq)
print(r1) #打印 [] qq不是以0开头的,匹配不到
r2 = re.findall('000$',qq) #qq不是以0结束的,匹配不到
print(r2) #打印 []
组的概念

import re
a = 'PythonPythonPythonPythonPython'
# a里是否有三个Python
##方法一
r = re.findall('PythonPythonPython',a)
print(r) #打印 ['PythonPythonPython']
##方法二
r2 = re.findall('(Python){3}',a) #括号表示组,是并且的关系,匹配时可以有多个组如,'(Python){3}(js)',
print(r2) #打印 ['Python']
##方法三
r3 = re.findall('Python{3}',a) #这种字法只能匹配单个字符(如:a) 不能匹配字符集(如单词:Python)
print(r3) #打印 []
参数匹配
第三个参数,|表示多种模式叠加
.点匹配换行符之外\n的其它所有字符- re.I 不区分大小写
- re.S 表示可以让
.点号匹配包括\n在内的所有字符
import re
a = 'PythonC#\nJavaPHP'
# 匹配出C#\n
r = re.findall('c#.',a)
print(r) #打印 []
r1 = re.findall('c#.', a , re.I)
print(r1) #打印 []
# .匹配换行符之外\n的其它所有字符
# re.I 不区分大小写
# re.S 表示.号匹配包括\n在内的所有字符
r1 = re.findall('c#.', a , re.I | re.S)
print(r1) #打印 ['C#\n']
替换
- 方法一:内置replace函数
- 方法二:正则普通替换
- 方法三:正则用函数替换
import re
a = 'PythonC#JavaC#PHPC#'
#替换C#为GO
##方法一:内置replace函数
#字符串是不能改变的,所以要重新给变量赋值
a1 = a.replace('C#','GO',2) #参数 老的 新的 替换的次数
print(a1) #输出 PythonGOJavaGOPHPC#
##方法二:正则普通替换
a2 = re.sub('C#','GO',a,1) #参数(匹配的规则)老的 新的 原字符串 替换的次数
print(a2) #输出 PythonGOJavaC#PHPC#
##方法三:正则用函数替换
def couvert(value):
print(value)
# 输出 匹配到了三次,所以输出三次
# <re.Match object; span=(6, 8), match='C#'>
# <re.Match object; span=(12, 14), match='C#'>
# <re.Match object; span=(17, 19), match='C#'>
# 每次匹配时拿到match里的值
matched = value.group()
return '!!' + matched + '!!' # 返回每次处理后的match里的值
a3 = re.sub('C#',couvert,a,3)
print(a3) #输出 Python!!C#!!Java!!C#!!PHP!!C#!!
[Haima的博客]
http://www.cnblogs.com/haima/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号