MonoNeRF: Learning Generalizable NeRFs from Monocular Videos without Camera Poses
1. 论文简介
论文题目:MonoNeRF: Learning Generalizable NeRFs from Monocular Videos without Camera Poses
Paper地址:chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://openreview.net/pdf?id=OTZyQCwgNL
发表刊物:ICML
发表时间:2023
发表作者:Yang Fu, Ishan Misra, Xiaolong Wawng
发表单位:University of California, FAIR, Meta AI.
2. 科学问题及动机
虽然NeRF已经取得了较大的成功,但构建NeRF需要准确的使用真实相机姿态,并且一个场景需要构建一个NeRF,泛化性不足,同时训练耗时。
有一些方法通过在多个场景训练然后再单个场景上fine-tune来解决泛化的问题,但需要相机位姿。
另一些 方法不需要相机位姿,但针对的是单个场景的,泛化性不足。
也就是相机位姿的需求和场景的限制没能同步解决。
这背后的一个基本原因是:以自我监督的方式跨场景执行校准非常具有挑战性。
3. 核心工作
提出了一个广义的神经辐射场- MonoNeRF,它可以在静态场景中移动的大规模单目视频上进行训练,而不需要任何深度和相机姿势的ground truth。
MonoNeRF遵循基于自动编码器的架构,其中编码器估计单目深度和相机姿态,解码器基于深度编码器特征构建多平面NeRF表示,并使用估计的相机渲染输入帧。
学习由重构误差监督。
一旦模型被学习,它可以应用于多种应用,包括深度估计、相机姿态估计和单图像新视图合成。
4. 工作细节
提出了一种新的泛化NeRF,称为MonoNeRF,它可以从静态场景中运动的单目视频中学习,而不使用任何相机ground truth。
我们的关键观点是,现实世界的视频通常伴随着缓慢的镜头变化(连续性),而不是呈现不同的视点。
根据这一观察结果,我们建议在大规模的现实世界视频上训练一个基于autoencoder的模型。
给定输入视频帧,我们的框架使用深度编码器对每帧执行单目深度估计(鼓励保持一致),并使用摄像机姿态编码器估计每两个连续帧之间的相对摄像机姿态。
深度编码器特征和相机姿态是中间解纠缠表示。
对于每个输入帧,我们用深度编码器特征构造一个NeRF表示,并根据估计的相机姿态渲染它来解码另一个输入帧。
我们利用渲染帧和输入帧之间的重构损失来训练模型。
然而,单独使用重建损失很容易导致一个平凡的解决方案,因为估计的单目深度、相机姿势和NeRF表示不一定在相同的尺度上。
我们提出的一个关键技术贡献是在训练期间提出一种新的刻度校准方法来校准这三种表示。
我们的框架的优点是:(i)与NeRF不同,它不需要3D相机姿势注释(例如,通过SfM计算);(ii)在大规模视频数据集上进行泛化训练,从而实现更好的迁移。
5. 实现细节
整个框架是以自监督的方式在做。
1. 输入为3张连续的图像;
2. 提取其中一张图像(应该是中间帧)的feature和depth; 计算中间帧和前后两帧之间的相机位姿;
3. 然后类似于MINE中的方法,将feats和不同的采样depth喂入decoder来构造planar neural radiance field;
4. 然后可以可以通过渲染来生成新视野图像和depth;

5.1 相机位姿估计
s为中间帧图像,t为前一帧或者后一帧图像,估计中间帧到前一帧或者后一帧的位姿;
![]()
5.2 source view下的图像depth生成
![]()
5.3 多平面NeRF构造
框架图处画得不是多清晰,可以参考MINE得生成过程。在![]() 区间采样深度
区间采样深度![]() ,然后结合feats结合di在每个d处生成一个平面,用
,然后结合feats结合di在每个d处生成一个平面,用![]() 表示,c表示RGB值,σ表示体素密度(volume density)。
表示,c表示RGB值,σ表示体素密度(volume density)。
可以参考图2。

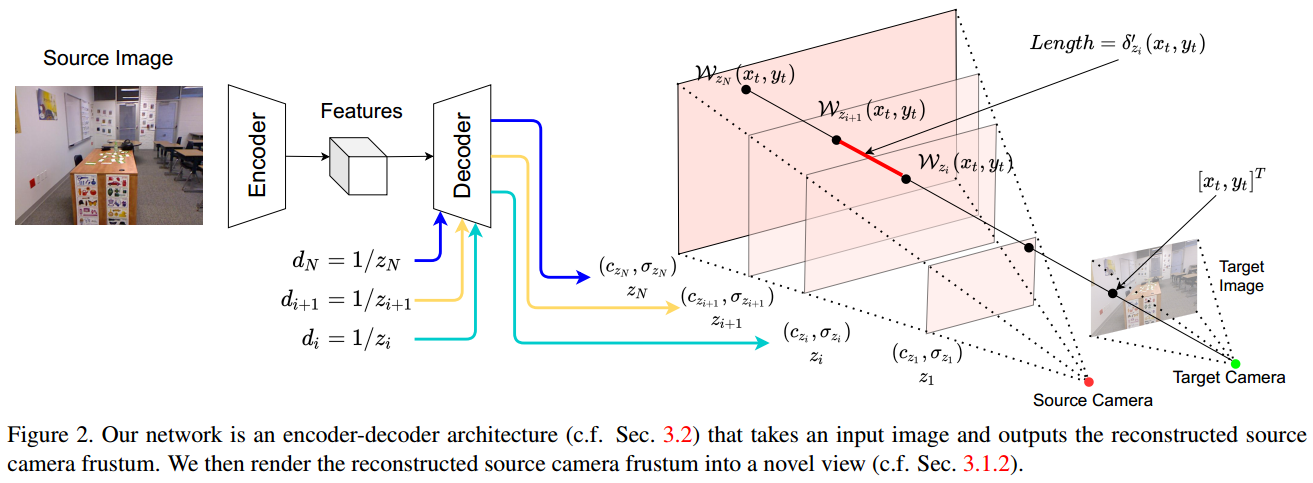
5.4 渲染生成新视角图像
这里α就是σ; 其实就是NeRF得渲染公式;
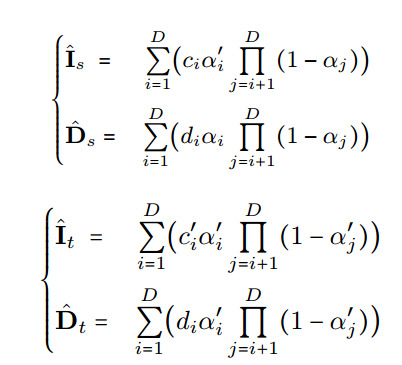
因为在5.3中生成的是source view的,因此需要建立target view与source view的位置关联。
通过warp操作。建立关联后,对于每一个target图像的像素都能在MPI NeRF中找到对应的![]() ,由此渲染出对应的图像和depth。
,由此渲染出对应的图像和depth。
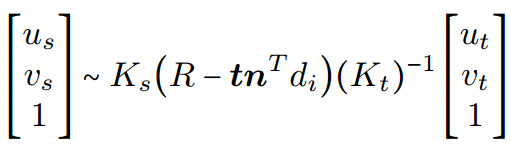

5.5 Loss
总的损失函数:
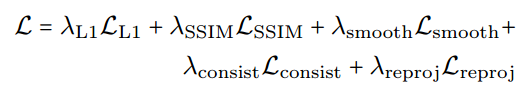
包括渲染得到的target图像和真实target图像的L1 loss和SSIM loss, 以及smoothloss;

还有渲染depth和直接预测depth的一致性损失:
![]()
以及深度估计中通过warp插值得到的源图像和真实源图像的投影loss:
![]()
6. 结语
努力去爱周围的每一个人,付出,不一定有收获,但是不付出就一定没有收获! 给街头卖艺的人零钱,不和深夜还在摆摊的小贩讨价还价。愿我的博客对你有所帮助(*^▽^*)(*^▽^*)!
如果客官喜欢小生的园子,记得关注小生哟,小生会持续更新(#^.^#)(#^.^#)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号