初识机器学习——吴恩达《Machine Learning》学习笔记(十)
应用机器学习的建议
决定下一步做什么(Deciding what to try next)
调试学习算法
机器学习诊断
评估假设(Evaluating a hypothesis)
将dataset分为训练集和测试集,一般按照training set和test set比例为7:3来划分,注意,需要对这些数据进行随机划分。
线性回归——计算测试集误差

logistic回归——计算测试集误差

模型选择和训练、验证、测试集(Model selection and training/validation/test set)
将数据分为训练集、验证集、测试集。随机分配,其比例分别为6:2:2。

用训练集训练θ参数,用交叉验证集选择模型。

多个模型中,选择验证误差(线性回归就是J(θ))最小的那个模型。最后用测试集估计被选择的模型泛化误差(generalization error,推广误差)。

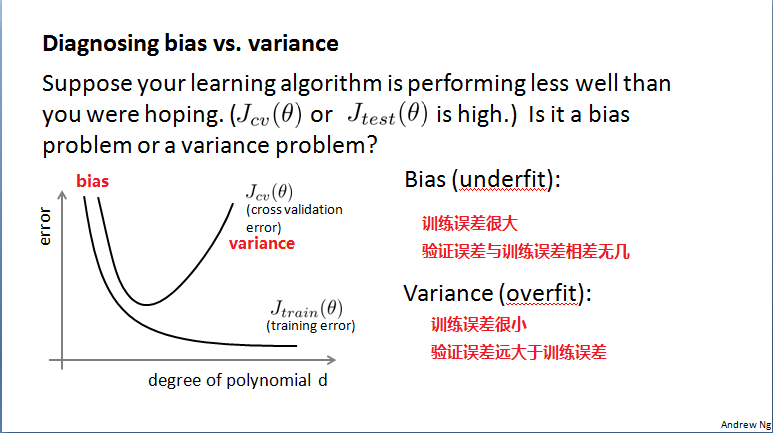
诊断偏差与方差(Diagnosing bias vs variance)
偏差(underfit):训练、验证误差都大。验证误差约等于训练误差。
方差(overfit):训练误差很小,但是验证误差远大于训练误差。
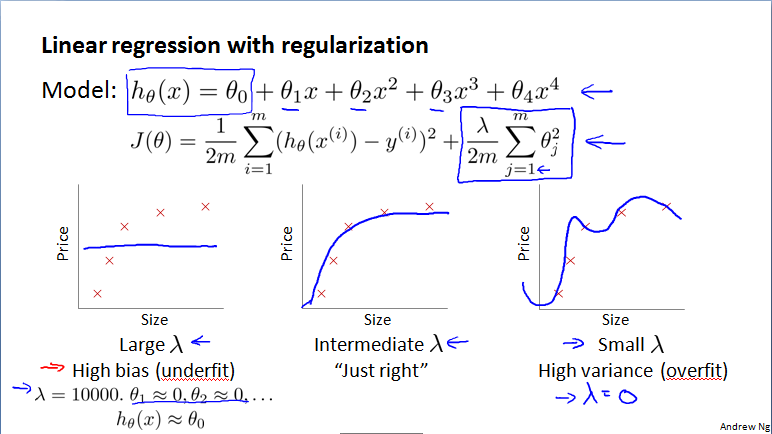
正则化和偏差、方差
正则化与偏差、方差
 、
、
选择正则化参数
1、逐步尝试不同的λ,通过训练集,获得各个λ的θ参数;
2、利用这些参数获得验证集的误差,选择误差最小的那个模型;
3、通过测试集评估泛化误差。

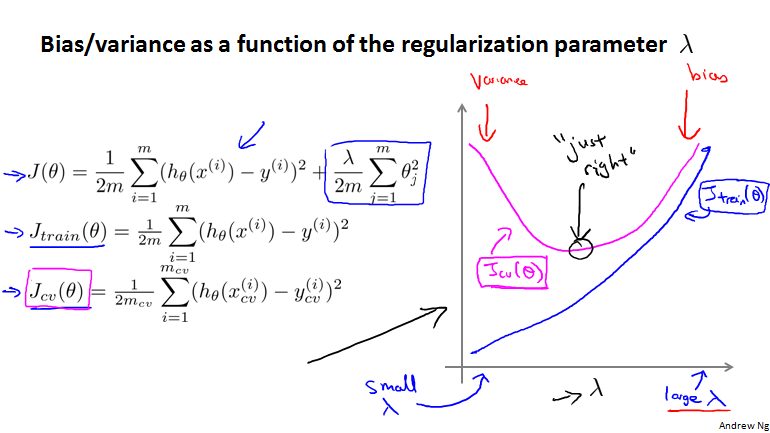
正则化与偏差、方差的函数图像分析
学习曲线(learning curves)
学习曲线
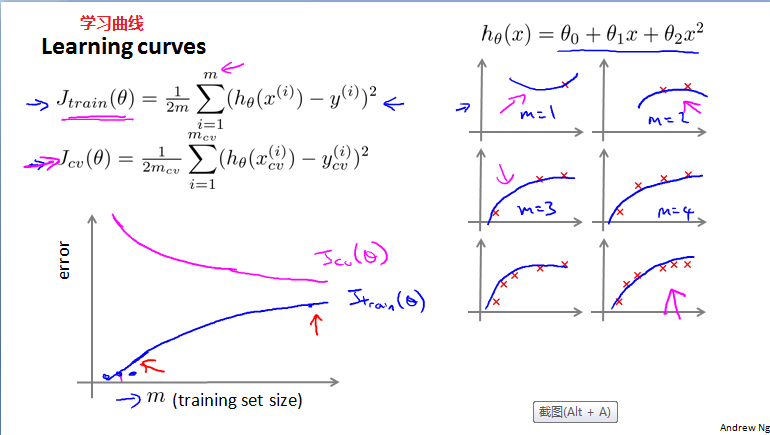
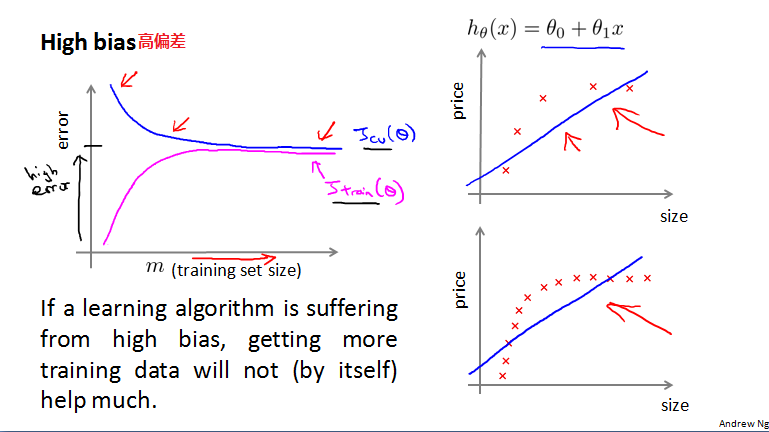
高偏差:如果学习曲线遭受高偏差,增加训练集数据对结果并没有多大的帮助。随着训练集数据量增大,训练集和验证集的误差将会很接近,且都很大。
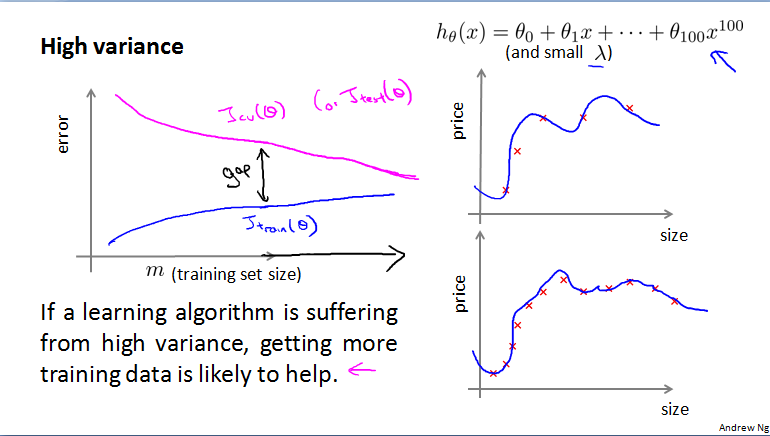
高方差:如果是高方差问题,误差学习曲线中,验证集和训练集的误差曲线之间会有很大的间隙,随训练集的增加,间隙将会减小。用更多的训练集数据可能会有帮助。
决定接下来做什么(Deciding what to do next)
1、获取更多的训练集数据 --解决高方差
2、减少特征集数量 --解决高方差
3、选用更多的特征集 --解决高偏差
4、增加多项式特征(属于增加特征集) --解决高偏差
5、减少正则化系数 --解决高偏差
6、增加正则化系数 --解决高方差

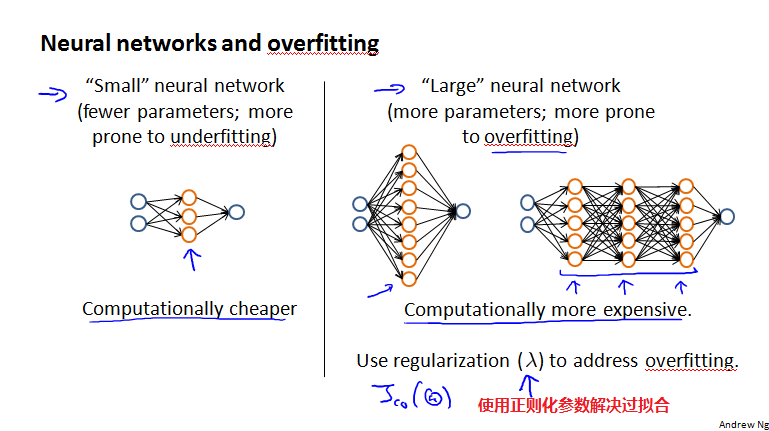
神经网络与过拟合