【RabbitMQ】网络分区
网络分区意义
RabbitMQ 集群的网络分区的容错性并不是很高,一般都是使用 Federation 或者 Shovel 解决广域网中的使用问题。不过即使是在局域网环境下,网络分区也不可能完全避免,网络设备(比如中继设备、网卡)出现故障也会导致网络分区。当出现网络分区时,不同分区里的节点会认为不属于自身所在分区的节点都已经挂(down)了,对于队列、交换器、绑定的操作仅对当前分区有效。在 RabbitMQ 的默认配置下,即使网络恢复了也不会自动处理网络分区带来的问题。RabbitMQ 3.1 版本开始会自动探测网络分区,并且提供了相应的配置来解决这个问题。
当一个集群发生网络分区时,这个集群会分成两个部分或者更多,它们各自为政,互相都认为对方分区内的节点已经挂了,包括队列、交换器及绑定等元数据的创建和销毁都处于自身分区内,与其他分区无关。如果原集群中配置了镜像队列,而这个镜像队列又牵涉两个或者更多个网络分区中的节点时,每一个网络分区中都会出现一个 master 节点,对于各个网络分区,此队列都是相互独立的。当然也会有一些其他未知的、怪异的事情发生。当网络恢复时,网络分区的状态还是会保持,除非采取了一些措施去解决它。
RabbitMQ 网络分区带来的影响大多是负面的,极端情况下不仅会造成数据丢失,还会影响服务的可用性。那为什么RabbitMQ 还要引入网络分区的设计理念呢?其中一个原因就与它本身的数据一致性复制原理有关,RabbitMQ 采用的镜像队列是一种环形的逻辑结构 ,如下图所示:
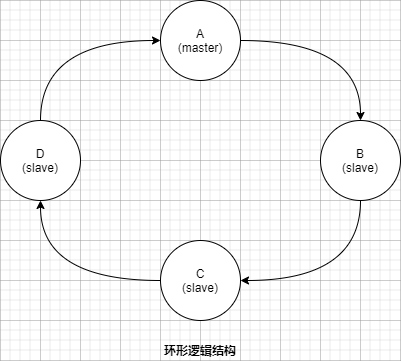
图中为某队列配置了4 个镜像,其中A 节点作为 master 节点,其余B、C、D 节点为 slave 节点,4 个镜像节点组成一个环形结构。
假如需要确认(ack)一条消息,先会在A 节点即master 节点上执行确认命令,之后转向B 节点,然后是C 节点,最后由D 将执行操作返回给A 节点,这样才真正确认了一条消息,之后才可以继续相应的处理。
这种复制原理与ZooKeeper 的Quorum 原理不同,它可以保证更强的一致性。在这种一致性数据模型下,如果出现网络波动或者网络故障等异常情况,那么整个数据链的性能就会大大降低。如果C 节点网络异常,那么整个 A -> B -> C -> D -> A 数据链就会被阻塞,继而相关服务也会被阻塞,所以这里就需要引入网络分区来将异常的节点剥离出整个分区,以确保 RabbitMQ 服务的可用性及可靠性。等待网络恢复之后,可以进行相应的处理来将此前的异常节点加入集群中。
网络分区判定
RabbitMQ 集群节点内部通信端口默认为25672 ,两两节点之间都会有信息交互,如果某节点出现网络故障,或者是端口不通,会致使与此节点的交互出现中断,这里就会有个超时判定机制,继而判定网络分区。
对于网络分区的判定是与 net_ticktime 参数息息相关的,此参数默认值为60 秒。注意与heartbeat_time 的区别heartbeat_time 是指客户端与 RabbitMQ 服务之间通信的心跳时间,针对 5672 端口而言。如果发生超时则会有 net_tick_timeout 的信息报出RabbitMQ 集群内部的每个节点之间会每隔四分之一的 net_ticktime 次应答(tick)。如果有任何数据被写入节点中,则此节点被认为已经被应答(ticked)了。如果连续4 次,某节点都没有被 ticked,则可以判定此节点已处于 “down” 状态,其余节点可将此节点剥离出当前分区。
将连续4 次的 tick 时间记为 T,那么T 的取值范围为 0.75 * net_ticktime < T < 1.25 * net_ticktime。下图可以形象地描绘出这个取值范围的缘由:
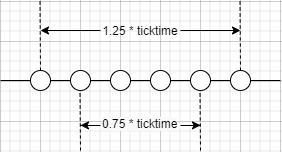
图中每个节点代表一次 tick 判定的时间戳,在2 个临界值 0.75 * net_ticktime 和
1.25 * net_ticktime 之间可以连续执行4 次的 tick 判定。默认情况下,在 45s < T < 75s 之间会判定出net_tick_timeout。
RabbtMQ 不仅会将队列、交换器及绑定等信息存储在 Mnesia 数据库中,而且许多围绕网络分区的一些细节也都和这个 Mneia 的行为相关。如果一个节点不能在T 时间连上另一个节点,那么 Mnesia 通常认为这个节点己经挂了,就算之后两个节点又重新恢复了内部通信,但是这两个节点都会认为对方已经挂了,Mnesia 此时认定了发生网络分区的情况。这些会被记录到RabbitMQ 的服务日志之中如下:
Mnesia('rabbit@node1'): ** ERROR ** mnesia event got
{inconsistent_database, running_partitioned_network, 'rabbit@node2'}
除了通过查看 RabbitMQ 服务日志的方式,还有以下3 种方法可以查看是否出现网络分区:
- 采用 rabbitmqctl 工具来查看,即采用
rabbitmqctl cluster_status,通过这条命令可以看到集群相关信息,未发生网络分区时的情形举例如下:
[{nodes, [{disc, [rabbit@node1,rabbit@node2,rabbit@node3]}]},
{running_nodes, [rabbit@node2,rabbit@node3,rabbit@node1]},
{cluster_name, <<"rabbit@node1">>},
{partitio, []}]
由上面的信息可知,集群中一共有3 个节点,分别为rabbit@node1、rabbit@node2、rabbit@node3。在partitions这一项中没有相关记录,则说明没有产生网络分区。如果partitions 项中有相关容,则说明产生了网络分区,例如:
[{nodes, [{disc, [rabbit@node1,rabbit@node2,rabbit@node3]}]},
{running_nodes, [rabbit@node3,rabbit@node1]},
{cluster_name, <<"rabbit@node1">>},
{partitions, [{rabbit@node3,[rabbit@node2]},{rabbit@node1,[rabbit@node2]}]}]
上面partitions 项中的内容表示:
- rabbit@node3与rabbit@node2 发生了分区,即
- rabbit@node1与rabbit@node2 发生了分区,即
- 通过 Web 管理界面的方式查看。如果发生了网络分区页面会出现警告。推荐采用这种方式来检测是否发生了网络分区。
- 通过 HTTP API 的方式调取节点信息来检测是否发生网络分区,比如通过 curl 命令来调取节点信息:
curl -i -u root:root123 -H "content-type:application/json" -X GET http://localhost:15672/api/nodes
模拟网络分区
正常情况下,很难观察到 RabbitMQ 网络分区的发生。为了更好地理解网络分区,需要采取某些手段将其模拟出来,以便对其进行相应的分析处理,进而在实际应用环境中遇到类似情形可以处理游刃有余。往长远方面讲,也可以采取一些要的手段去规避网络分区的发生,或者可以监控网络分区以及准备相关的处理预案。
模拟网络分区的方式有多种,主要分为以下三大类:
- iptables 封禁/解封 IP 地址或者端口号;
- 关闭/开启网卡;
- 挂起/恢复操作系统;
网络分区的影响
未配置镜像
node1、node2、node3 三个节点组成一个RabbitMQ 集群,且在这三个节点中分别创建queue1、queue2、queue3这三个队列,并且相应的交换器与绑定关系如下:
| 节点名称 | 交换器 | 绑定 | 队列 |
|---|---|---|---|
| node1 | exchange | rk1 | queue1 |
| node2 | exchange | rk2 | queue2 |
| node3 | exchange | rk3 | queue3 |
客户端分别连接node1 和node2 并分别向/从queue1 和queue2 发送/消费消息
| 客户端 | 节点名称 | 交换器 | 绑定 | 队列 |
|---|---|---|---|---|
| client1(producer) | node1 | exchange | rk1 | queue1 |
| client2(producer) | node2 | exchange | rk2 | queue2 |
| client3(consumer) | node1 | exchange | rk1 | queue1 |
| client4(consumer) | node2 | exchange | rk2 | queue2 |
在发生网络分区后,node1、node2 存在于两个不同的分区之中,对于消息生产端client1、client2 而言,没有任何异常,消息正常发送也没有消息丢失。消费端client3、client4 也都能正常消费,无任何异常发生。
客户端分别连接node1 和node2 并分别向/从queue2 和queue1 发送/消费消息
| 客户端 | 节点名称 | 交换器 | 绑定 | 队列 |
|---|---|---|---|---|
| client1(producer) | node1 | exchange | rk2 | queue2 |
| client2(producer) | node2 | exchange | rk1 | queue1 |
| client3(consumer) | node1 | exchange | rk2 | queue2 |
| client4(consumer) | node2 | exchange | rk1 | queue1 |
在发生网络分区后,node1、node2 存在于两个不同的分区之中,client1 不能将消息正确地送达到queue2 ,同样client2 不能将消息送达到queue1 中。如果客户端中设置了ReturnListener 来监听 Basic.Return 的信息,并附带有消息重传机制,那么在整个网络分区前后的过程中可以保证发送端的消息不丢失。
在网络分区之前queue1 进程存在于node1 节点中,queue2 进程存在于node2 节点中。
在网络分区之后,在node1 所在的分区并不会创建新的queue2 进程,同样在node2 所在的分区也不会创建新的queue1 的进程。这样在网络分区发生之后,虽然可以通过 rabbitmqctl list_queues name 命令在node1 节点上查看到queue2,但是在node1 上已经没有真实的queue2 进程的存在。
client1 将消息发往交换器exchange 之后并不能路由到queue2 中,因此消息也就不能存储。如果客户端没有设置mandatory 参数并且没有通过ReturnListener 进行消息重试(或者其他措施)来保障消息可靠性,那么在发送端就会有消息丢失。
对于消费端client3、client4,客户端没有异常报错,且可以消费到相关数据,但是此时会有一些怪异的现象发生,比如对于已消费消息的ack 失效。在从网络分区中恢复之后,数据不会丢失。
如果分区之后,重启client3 或者有个新的客户端client5 连接node1 IP 来消费queue2 则会报错。
小结
对于未配置镜像的集群,网络分区发生之后,队列也会伴随着宿主节点而分散在各自的分区之中。对于消息发送方而言,可以成功发送消息,但是会有路由失败的现象,要需要配合mandatory 等机制保障消息的可靠性。对于消息消费方来说,有可能会有诡异、不可预知的现象发生,比如对于已消费消息的ack 会失效。如果网络分区发生之后,客户端与某分区重新建立通信链路,其分区中如果没有相应的队列进程,则会有异常报出。如果从网络分区中恢复之后,数据不会丢失,但是客户端会重复消费。
已配置镜像
如果集群中配置了镜像队列,那么在发生网络分区时,情形比未配置镜像队列的情况复杂得多,尤其是发生多个网络分区的时候。这里先简单地从3 个节点分裂成2 个网络分区的情形展开讨论。如前文所述,集群中有node1、node2、node3 三个节点,分别在这些节点上创建队列queue1、queue2、queue3 并配置镜像队列。采用iptables 的方式将集群模拟分裂[node1,node3] [node2] 这两个网络分区。
镜像队列的相关配置可以参考如下:
ha-mode:exactly
ha-param:2
ha-sync-mode:automatic
首先来分析第一种情况。如下表示,3 个队列的master 镜像和slave 镜像分别做相应分布。
分区之前:
| 队列 | master | slave |
|---|---|---|
| queue1 | node1 | node3 |
| queue2 | node2 | node3 |
| queue3 | node3 | node2 |
分区之后:
[node1,node3]分区:
| 队列 | master | slave |
|---|---|---|
| queue1 | node1 | node3 |
| queue2 | node3 | node1 |
| queue3 | node3 | node1 |
在发生网络分区之后 [node1,node3] 分区中的队列有了新的部署。除了queue1 未发生改变,queue2 于原宿主节点node2 被剥离当前分区,那么node3 提升为master ,同时选择node1 作为slave 。在queue3 重新选择node1 作为其新的slave。
[node2]分区:
| 队列 | master | slave |
|---|---|---|
| queue1 | node1 | node3 |
| queue2 | node2 | [] |
| queue3 | node2 | [] |
对于[node2] 分区而言,queue2、queue3的分布比较容易理解,此分区中只有一个节点,所有slave 列为空。但是对于queue1而言,其部署还是和分区前如出一辙。不管是在网络分区前,还是在网络分区之后,再或者是又从网络分区中恢复,对于queue1而言生产和消费消息都不会受到任何的影响,就如未发生过网络分区一样。对于队列queue2、queue3 情形可以参考上面未配置镜像的相关细节,从网络分区中恢复(即恢复成之前的[node1,node2,node3] 组成的完整分区)之后可能会有数据丢失。
再考虑另一种情形,分区之前如下所示:
分区之前:
| 队列 | master | slave |
|---|---|---|
| queue1 | node1 | node2 |
| queue2 | node2 | node3 |
| queue3 | node3 | node1 |
分区之后:
[node1,node3]分区:
| 队列 | master | slave |
|---|---|---|
| queue1 | node1 | node3 |
| queue2 | node3 | node1 |
| queue3 | node3 | node1 |
[node2]分区:
| 队列 | master | slave |
|---|---|---|
| queue1 | node2 | [] |
| queue2 | node2 | [] |
| queue3 | node3 | node1 |
手动处理网络分区
为了从网络分区中恢复,首先需要挑选一个信任分区,这个分区才有决定Mnesia 内容的权限,发生在其他分区的改变将不会被记录到Mnesia 中而被直接丢弃。在挑选完信任分区之后,重启非信任分区中的节点,如果此时还有网络分区的告警,紧接着重启信任分区中的节点。
这里有3 个要点需要详细阐述:
- 如何挑选信任分区?
- 如何重启节点?
- 重启的顺序有何考究?
如何挑选信任分区?
挑选信任分区一般可以按照这几个指标进行:
- 分区中要有disc 节点;
- 分区中的节点数最多;
- 分区中的队列数最多;
- 分区中的客户端连接数最多;
优先级从前到后,例如信任分区中要有disc 节点;如果有两个或者多个分区满足,则挑选节点数最多的分区作为信任分区;如果又有两个或者多个分区满足,那么挑选队列数最多的分区作为信任分区。依次类推如果有两个或者多个分区对于这些指标都均等,那么可以随机挑选一个分区。
如何重启节点?
RabbitMQ 中有两种重启方式:
- 使用
rabbitmqctl stop命令关闭,然后再用rabbitmq-server -detached命令启动 - 使用
rabbitmqctl stop_app关闭,然后使用rabbitmqctl start_app命令启动。
第一种方式需要同时重启erlang 虚拟机和RabbitMQ 应用,而第二种方式只是重启RabbitMQ 应用。两种方式都可以从网络分区中恢复,但是更加推荐使用第二种方式,包括后面的自动处理网络分区的方式,其内部是采用的第二种方式进行重启节点。
重启的顺序有何考究?
RabbitMQ 的重启顺序也比较讲究,必须在以下两种重启顺序中择其一进行重启操作:
- 停止其他非信任分区中的所有节点,然后再启动这些节点。如果此时还有网络分区的告警,则再重启信任分区中的节点以去除告警。
- 关闭整个集群中的节点,然后再启动每一个节点,这里需要确保启动的第一个节点在
信任的分区之中。
在选择哪种重启顺序之前 首先考虑一下队列“漂移”的现象。所谓的队列“漂移”是在配置镜像队列的情况下才会发生的。在配置镜像的集群中重启会有队列“漂移”的情况发生,造成负载不均衡。
注意:一定要按照前面提及的两种方式择其一进行重启,如果选择挨个节点重启的方式,同样可以处理网络分区,但是这里会有一个严重的问题,即Mnesia 内容权限的归属问题。比如有两个分区[node1,node2] [node3,node4],其中[node1,node2] 为信任分区,此时若按照挨个重启的方式进行重启,比如先重启node3 ,在node3 节点启动之时无法判断其节点的Mnesia 内容是向[node1,node2] 分区靠齐还是向node4 节点靠齐,至此,如果挨个一轮重启之后,最终集群中的Mnesia 数据是[node3 node4] 这个非信任分区,就会造成无法估量的损失。挨个节点重启也有可能会引起二次网络分区的发生。
如果原本配置了镜像队列,从发生网络分区到恢复的过程中队列可能会出现“漂移”的现象。可以重启之前先删除镜像队列的配置,这样能够在一定程度上阻止队列的“过分漂移”,即阻止可能所有队列都“漂移”到一个节点上的情况。
删除镜像队列的配置可以采用 rabbitmqctl 工具删除:
rabbitmqctl clear_policy [-p vhost] {mirror_queue_name}
可以通过 Web 管理界面进行删除,也可以通过 HTTPAPI 的方式进行删除:
curl -s -u {username:password} -X DELETE http://localhost:15672/api/policies/default/{mirror_queue_name}
网络分区处理步骤
- 步骤 1:挂起生产者和消费者进程。这样可以减少消息不必要的丢失,如果进程数过多,情形又比较紧急,也可跳过此步骤。
- 步骤 2:删除镜像队列的配置。
- 步骤 3:挑选信任分区。
- 步骤 4:关闭非信任分区中的节点。采用
rabbitmqctl stop_app命令关闭。 - 步骤 5:启动非信任分区中的节点。采用与步骤4 对应的
rabbitmqctl start_app命令启动。 - 步骤 6:检查网络分区是否恢复,如果已经恢复则转步骤8,如果还有网络分区的报警则转步骤7。
- 步骤 7:重启信任分区中的节点。
- 步骤 8:添加镜像队列的配置。
- 步骤 9:恢复生产者和消费者的进程。
自动处理网络分区
RabbitMQ 提供了三种方法自动地处理网络分区pause-minority 模式、pause-if-all-down 模式和autoheal 模式。默认是 ignore 模式,即不自动处理网络分区,所以在这种模式下,当网络分区的时候需要人工介入。在 rabbitmq.config 配置文件中配置cluster_partition_handling 参数即可实现相应的功能。默认的 ignore 模式的配置如下,注意最后有个点号:
[
{
rabbit, [
{cluster_partition_handling, ignore}
]
}
].
pause-minority 模式
在pause-minority 模式下,当发生网络分区时,集群中的节点在观察到某些节点"down"的时候,会自动检测其自身是否处于"少数派"(分区中的节点小于或者等于集群中一半的节点数),RabbitMQ 会自动关闭这些节点的运作。根据 CAP 原理,这里保障了P,即分区耐受性。这样确保了在发生网络分区的情况下,大多数节点(当然这些节点得在同一个分区中)可以继续运行。"少数派"中的节点在分区开始时会关闭,当分区结束时又会启动。这里关闭是指RabbitMQ 应用的关闭,而Erlang 虚拟机并不关闭,类似于执行了 rabbitmqctl stop_app 命令。处于关闭的节点会每秒检测一次是否可连通到剩余集群中,如果可以则启动自身的应用。相当于执行 rabbitmqctl start_app 命令。
pause-minority 模式相应的配置如下:
[
{
rabbit, [
{cluster_partition_handling, pause-minority}
]
}
].
需要注意的是RabbitMQ 会关闭不是严格意义上的大多数,比如在一个集群中只有两个节点的时候并不适合采用pause-minority 的模式,因为其中任何一个节点失败而发生网络分区时,两个节点都会关闭。当网络恢复时有可能两个节点会自动启动恢复网络分区,也有可能仍保持关闭状态,然而如果集群中的节点数远大于2 个时,pause-minority 模式比 ignore 模式更加可靠,特别是网络分区通常是由单节点网络故障而脱离原有分区引起的。
当对等分区出现时,会关闭这些分区内的所有节点,对于前面的[node1,node2] [node3,node4] 的例子而言,这四个节点上的RabbitMQ 应用都会被关闭,只有等待网络恢复之后,才会自动启动所有的节点以求从网络分区中恢复。
pause-if-all-down 模式
在pause-if-all-down 模式下,RabbitMQ 集群中的节点在和所配置的列表中的任何节点不能交互时才会关闭 语法为 {pause_if_all_down, [nodes], ignore|autoheal},其中[nodes]为受信节点,参考配置如下:
[
{
rabbit, [
{cluster_partition_handling, {pause_if_all_down, ['rabbit@node1'], ignore}}
]
}
].
如果一个节点与 rabbit@node1 节点无法通信时,则会关闭自身的 RabbitMQ 应用。如果是rabbit@node1 本身发生了故障造成网络不可用,而其他节点都是正常的情况下,这种规则会让所有的节点中 RabbitMQ 应用都关闭,待rabbit@node1 中的网络恢复之后,各个节点再启动自身应用以从网络分区中恢复。
pause-if-all-down 模式下有ignore 和autoheal 两种不同的配置。考虑前面pause-minority 模式中提及的一种情形,node1、node2 部署在机架A 上,而node3、node4 部署在机架B,此时配置{cluster_partition_handling,{pause_if_all_down,['rabbit@node1' ,'rabbit@node3'], ignore}},那么当机架A 和机架B 通信出现异常时,由于node1、node2 保持着通信,node3、node4 保持着通信,这4 个节点都不会自行关闭,但是会形成两个分区,所以这样不能实现自动处理的功能。所以如果将配置中的ignore 替换成autoheal 就可以处理此种情形。
autoheal 模式
在autoheal 模式下,当认为发生网络分区时,RabbitMQ 会自动决定一个获胜(winning)的分区,然后重启不在这个分区中的节点来从网络分区中恢复。一个获胜的分区是指客户端连接最多的分区,如果产生一个平局,即有两个或者多个分区的客户端连接数一样多,那么节点数最多的一个分区就是获胜分区,如果此时节点数也一样多,将以节点名称的字典序来挑选获胜分区。
autoheal 模式参考配置如下:
[
{
rabbit, [
{cluster_partition_handling, autoheal}
]
}
].
注意:在autoheal 模式下,如果集群中有节点处于非运行状态,那么当发生网络分区的时候,将不会有任何自动处理的动作。
模式选择
允许RabbitMQ 够自动处理网络分区并不一定会有正面的成效,也有可能会带来更多的问题。网络分区会导致RabbitMQ 集群产生众多的问题,需要对遇到的问题做出一定的选择。如果置RabbitMQ 于一个不可靠的网络环境下,需要使用Federation 或者Shovel。就算从网络分区中恢复了之后,也要谨防发生二次网络分区。
每种模式都有自身的优缺点,没有哪种模式是万无一失的,要根据实际情形做出相应的选择,下面简要概论以下4 个模式:
- ignore 模式:发生网络分区时,不做任何动作,需要人工介入;
- pause-minority 模式:对于对等分区的处理不够优雅,可能会关闭所有的节点。一般情况下,可应用于非跨机架、奇数节点数的集群中;
- pause-if-all-down 模式:对于受信节点的选择尤为考究,尤其是在集群中所有节点硬件配置相同的情况下。此种模式可以处理对等分区的情形;
- autoheal 模式:可以处于各个情形下的网络分区。但是如果集群中有节点处于非运行状态,则此种模式会失效;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号