

用pandas探索你的数据(五)-合并数据
在数据处理和分析中,数据的合并是一项关键任务。Pandas 提供了丰富的工具来处理不同来源的数据,并将它们合并成一个更大的数据集。在这篇文章中,我们将深入探讨 Pandas 中两个重要的数据合并函数:pd.concat() 和 pd.merge()。
首先,我们将通过一系列的步骤和示例来学习如何使用这些函数。然后,我们将深入解释每个函数的详细用法,包括参数和常见的用例。无论您是数据科学家、数据分析师还是对数据处理感兴趣的任何人,这篇文章都将为您提供处理和合并数据的实用技能。
探索虚拟姓名数据
步骤1 导入必要的库
# 运行以下代码 import numpy as np import pandas as pd
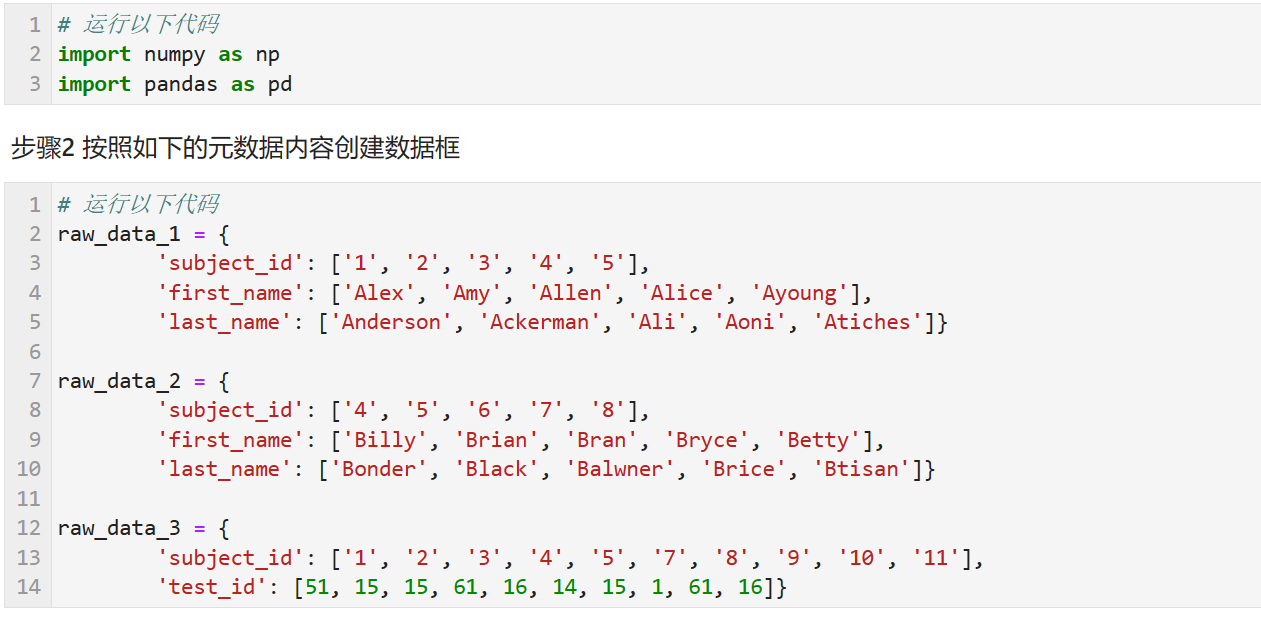
步骤2 按照如下的元数据内容创建数据框
# 运行以下代码 raw_data_1 = { 'subject_id': ['1', '2', '3', '4', '5'], 'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']} raw_data_2 = { 'subject_id': ['4', '5', '6', '7', '8'], 'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']} raw_data_3 = { 'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'], 'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
步骤3 将上述的数据框分别命名为data1, data2, data3
# 运行以下代码 data1 = pd.DataFrame(raw_data_1, columns = ['subject_id', 'first_name', 'last_name']) data2 = pd.DataFrame(raw_data_2, columns = ['subject_id', 'first_name', 'last_name']) data3 = pd.DataFrame(raw_data_3, columns = ['subject_id','test_id'])
步骤4 将data1和data2两个数据框按照行的维度进行合并,命名为all_data
# 运行以下代码 all_data = pd.concat([data1, data2]) all_data
| subject_id | first_name | last_name | |
|---|---|---|---|
| 0 | 1 | Alex | Anderson |
| 1 | 2 | Amy | Ackerman |
| 2 | 3 | Allen | Ali |
| 3 | 4 | Alice | Aoni |
| 4 | 5 | Ayoung | Atiches |
| 0 | 4 | Billy | Bonder |
| 1 | 5 | Brian | Black |
| 2 | 6 | Bran | Balwner |
| 3 | 7 | Bryce | Brice |
| 4 | 8 | Betty | Btisan |
步骤5 将data1和data2两个数据框按照列的维度进行合并,命名为all_data_col
# 运行以下代码 all_data_col = pd.concat([data1, data2], axis = 1) all_data_col
| subject_id | first_name | last_name | subject_id | first_name | last_name | |
|---|---|---|---|---|---|---|
| 0 | 1 | Alex | Anderson | 4 | Billy | Bonder |
| 1 | 2 | Amy | Ackerman | 5 | Brian | Black |
| 2 | 3 | Allen | Ali | 6 | Bran | Balwner |
| 3 | 4 | Alice | Aoni | 7 | Bryce | Brice |
| 4 | 5 | Ayoung | Atiches | 8 | Betty | Btisan |
步骤6 打印data3
# 运行以下代码 data3
| subject_id | test_id | |
|---|---|---|
| 0 | 1 | 51 |
| 1 | 2 | 15 |
| 2 | 3 | 15 |
| 3 | 4 | 61 |
| 4 | 5 | 16 |
| 5 | 7 | 14 |
| 6 | 8 | 15 |
| 7 | 9 | 1 |
| 8 | 10 | 61 |
| 9 | 11 | 16 |
步骤7 按照subject_id的值对all_data和data3作合并
# 运行以下代码 pd.merge(all_data, data3, on='subject_id')
| subject_id | first_name | last_name | test_id | |
|---|---|---|---|---|
| 0 | 1 | Alex | Anderson | 51 |
| 1 | 2 | Amy | Ackerman | 15 |
| 2 | 3 | Allen | Ali | 15 |
| 3 | 4 | Alice | Aoni | 61 |
| 4 | 4 | Billy | Bonder | 61 |
| 5 | 5 | Ayoung | Atiches | 16 |
| 6 | 5 | Brian | Black | 16 |
| 7 | 7 | Bryce | Brice | 14 |
| 8 | 8 | Betty | Btisan | 15 |
步骤8 对data1和data2按照subject_id作连接
# 运行以下代码 pd.merge(data1, data2, on='subject_id', how='inner')
| subject_id | first_name_x | last_name_x | first_name_y | last_name_y | |
|---|---|---|---|---|---|
| 0 | 4 | Alice | Aoni | Billy | Bonder |
| 1 | 5 | Ayoung | Atiches | Brian | Black |
步骤9 找到 data1 和 data2 合并之后的所有匹配结果
# 运行以下代码 pd.merge(data1, data2, on='subject_id', how='outer')
| subject_id | first_name_x | last_name_x | first_name_y | last_name_y | |
|---|---|---|---|---|---|
| 0 | 1 | Alex | Anderson | NaN | NaN |
| 1 | 2 | Amy | Ackerman | NaN | NaN |
| 2 | 3 | Allen | Ali | NaN | NaN |
| 3 | 4 | Alice | Aoni | Billy | Bonder |
| 4 | 5 | Ayoung | Atiches | Brian | Black |
| 5 | 6 | NaN | NaN | Bran | Balwner |
| 6 | 7 | NaN | NaN | Bryce | Brice |
| 7 | 8 | NaN | NaN | Betty | Btisan |
总结
总结:
在本练习中,我们使用Pandas进行了合并操作,主要涉及以下要点:
-
使用
pd.concat函数可以按行维度合并两个数据框。例如,将data1和data2合并为all_data,使用pd.concat([data1, data2])。 -
使用
pd.concat函数的axis参数可以按列维度合并两个数据框。例如,将data1和data2按列维度合并为all_data_col,使用pd.concat([data1, data2], axis=1)。 -
使用
pd.merge函数可以按照指定的列(如subject_id)对两个数据框进行合并。例如,按照subject_id对all_data和data3合并,使用pd.merge(all_data, data3, on='subject_id')。 -
在合并操作中,可以使用
how参数指定合并的方式,包括inner(内连接,保留两个数据框的交集)、outer(外连接,保留两个数据框的并集)等。 -
合并操作可以帮助我们根据共享的列值将不同数据框中的信息整合在一起,从而进行更复杂的数据分析和处理。
pd.concat() 是 Pandas 中用于合并数据的函数之一,它通常用于按行或列方向将多个数据框连接在一起。以下是对 pd.concat() 函数的详细解释:
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
参数说明:
objs:要合并的对象,通常是一个包含多个数据框的列表或元组。axis:指定合并的方向,可以是 0(默认,按行方向)或 1(按列方向)。join:指定合并时的连接方式,可以是'outer'(默认,取并集)或'inner'(取交集)。ignore_index:如果为True,则在合并时重置索引,默认为False,保留原始索引。keys:创建一个层次化索引,用于标识每个原始数据框的来源。levels:指定多层索引的级别名称。names:为多层索引的级别指定名称。verify_integrity:如果为True,则检查合并后的数据是否唯一,如果有重复的索引,将引发异常,默认为False。sort:如果为True,则对合并后的数据进行排序,默认为False。copy:如果为True,则复制数据而不修改原始对象,默认为True。
pd.concat() 返回一个合并后的新数据框,不会修改原始数据框。
使用示例:
-
合并两个数据框按行方向(默认方式):
result = pd.concat([df1, df2]) -
合并两个数据框按列方向:
result = pd.concat([df1, df2], axis=1) -
创建多层索引:
result = pd.concat([df1, df2], keys=['df1', 'df2']) -
重置索引:
result = pd.concat([df1, df2], ignore_index=True)
pd.concat() 是一个非常有用的函数,用于在数据处理中将多个数据框合并在一起,以便进行分析和操作。
pd.merge() 是 Pandas 中用于合并数据的函数之一,它通常用于将两个数据框(DataFrame)按照指定的列或索引进行连接操作。以下是对 pd.merge() 函数的详细解释:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
参数说明:
left:左侧的数据框(DataFrame)。right:右侧的数据框(DataFrame)。how:连接方式,可选值有'left'(左连接,默认),'right'(右连接),'outer'(外连接),'inner'(内连接)。on:连接列名,如果左右两侧的数据框都有相同列名,可以使用这个参数指定列名进行连接。left_on:左侧数据框的连接列名,用于指定左侧数据框的连接列。right_on:右侧数据框的连接列名,用于指定右侧数据框的连接列。left_index:如果为True,则使用左侧数据框的索引进行连接。right_index:如果为True,则使用右侧数据框的索引进行连接。sort:如果为True,则在连接之前对数据进行排序,默认为False。suffixes:如果左右两侧数据框有相同列名,可以使用suffixes参数添加后缀以区分这些列,默认为('_x', '_y')。copy:如果为True,则复制数据而不修改原始对象,默认为True。indicator:如果为True,则在结果中添加一个特殊的列_merge,用于表示每行的合并方式,默认为False。validate:用于验证连接操作的有效性,可选值有'one_to_one','one_to_many','many_to_one','many_to_many'。
pd.merge() 返回一个合并后的新数据框,不会修改原始数据框。
使用示例:
-
内连接两个数据框,使用相同列名连接:
result = pd.merge(left_df, right_df, on='key_column', how='inner') -
左连接两个数据框,指定左侧数据框的连接列和右侧数据框的连接列:
result = pd.merge(left_df, right_df, left_on='left_key', right_on='right_key', how='left') -
连接时使用左侧数据框的索引:
result = pd.merge(left_df, right_df, left_index=True, right_on='key_column', how='inner') -
添加后缀以区分相同列名的列:
result = pd.merge(left_df, right_df, on='key_column', suffixes=('_left', '_right'))
pd.merge() 是一个强大的数据连接工具,可用于合并不同来源的数据,进行数据分析和处理。根据不同的连接需求,可以选择不同的连接方式和参数。
本文由mdnice多平台发布


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义