# 特别鸣谢:
Alex的博客:https://pythonav.com/wiki/detail/6/88/
Alex的b站视频:https://www.bilibili.com/video/BV1F54114761?p=5&spm_id_from=pageDriver
一句话概述
引用计数为主,标记清除、分代回收为辅
1 引用计数
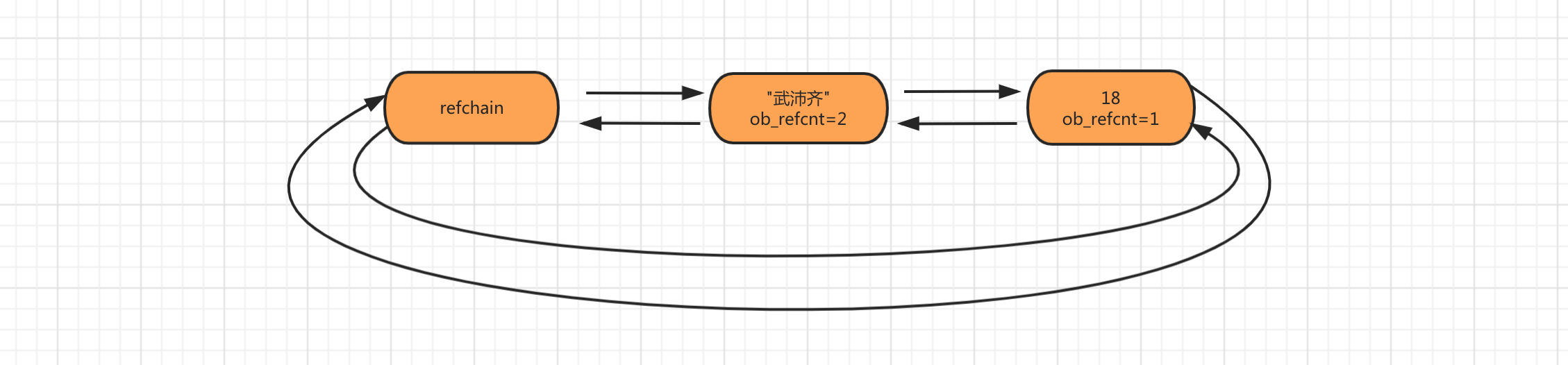
1.1 refchain
# 在Python的C源码中有一个名为refchain的环状双向链表。Python程序中只要创建对象都会把这个对象添加到refchain这个链表中。
# 类型封装结构
refchain中所有对象内部都至少包含以下4个元素[上一个对象,下一个对象,ob_refcnt,类型]。然后根据不同的数据类型,有不同的值存储方案(c源码中规定的),这里不深入了。
# 例如:
age = 18
name = "武沛齐"
![image]()
1.2 引用计数
# 在refchain中的所有对象内部都有一个ob_refcnt用来保存当前对象的引用计数器,顾名思义就是自己被引用的次数。
# 当值被多次引用时候,不会在内存中重复创建数据,而是引用计数器+1 。 当对象被销毁时候同时会让引用计数器-1,如果引用计数器为0,则将对象从refchain链表中摘除,同时在内存中进行销毁(暂不考虑缓存等特殊情况)。
2 标记删除
2.1 循环引用
# 引用计数的不足
引用计数器进行垃圾回收非常方便和简单,但他还是存在循环引用的问题,导致无法正常的回收一些数据。
# 举例
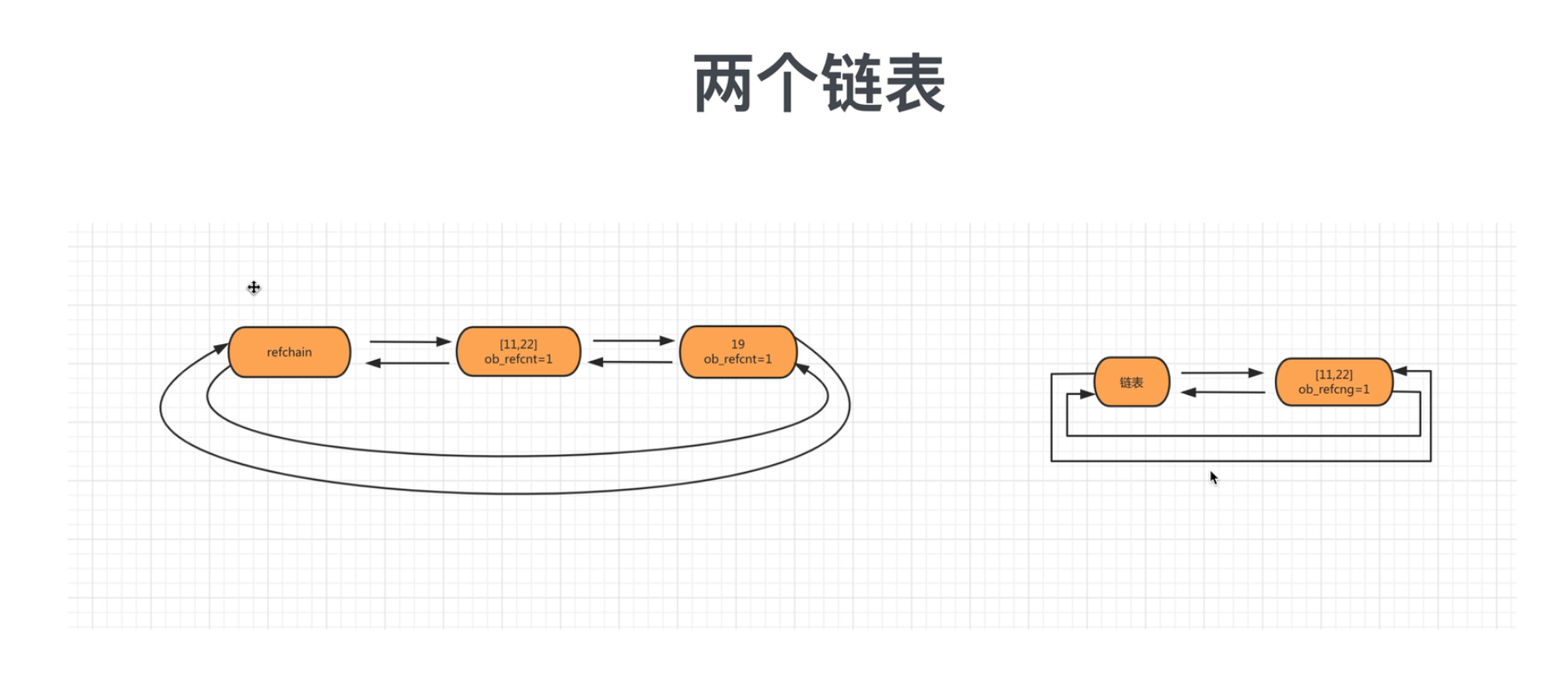
v1 = [11,22,33]
v2 = [44,55,66]
v1.append(v2)
v2.append(v1)
del v1
del v2
此时,v1和v2已经不用了,但他们的引用计数仍为1,而且永远不会为0,导致循环引用问题。项目中如果这种代码太多,就会导致内存一直被消耗,直到内存被耗尽,程序崩溃。
2.2 标记删除
# 为了解决循环引用的问题,引入了标记清除技术.
# 实现方案:
在底层又维护了一个链表,专门放入一些可能出现循环引用的数据,然后定期扫描,如果真的存在循环引用,则将双方的引用计数减一,再根据引用计数是否为0来决定是否回收。
# 存在的问题:
1.什么时候扫描?
2.每次扫描耗时久,资源消耗大。
![image]()
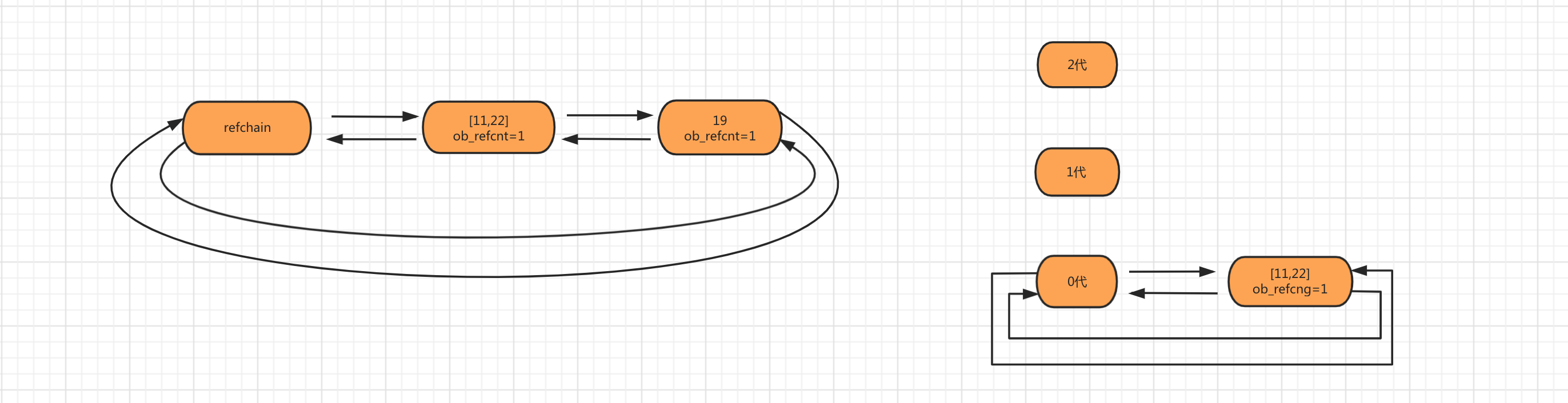
3 分代回收
# 将可能存在循环导入的对象维护成3个链表,当达到阈值时,就会对相应的链表中的每个对象做一次扫描。将循环引用各自减1并且销毁引用计数器为0的对象,最后将引用计数不为0的对象放入下一个链表。
0代:0代中对象达到700个扫描一次
1代:0代扫描10次,1代扫描一次
2代:1代扫描10次,2代扫描一次
![image]()
4 缓存机制(内存管理优化)
4.1 池(int)
# 为了避免重复的创建和销毁,维护了一个池。里面放入了常用的整型数据对象,小数据池范围:-5~257。当我们使用这些整数时,不会重新开辟内存,而是直接引用。
# 当我们不再使用该数据时,数据仍然在池中,应用计数为1,不会被清除。
# 以上说明以整型为例,其它数据类型也有对应的池。
4.2 free_list
# 引用计数器为0时,不会真正销毁对象,而是将他放到一个名为 free_list 的链表中,之后会再创建对象时不会在重新开辟内存,而是在free_list中将之前的对象来并重置内部的值来使用
# 不同的数据类型有不同的free_list链表,这里不深入。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号