- Ploty库也有大量统计可视化方案,并且这些可视化方案具有交互化属性。
- 主要对鸢尾花数据进行处理与可视化。
- 所展示的结果为交互界面的截图情况,这里不能进行交互。
- 类似'species'这个分类标签,使用'Category'分析原始特征数据,如花萼宽带
结果:
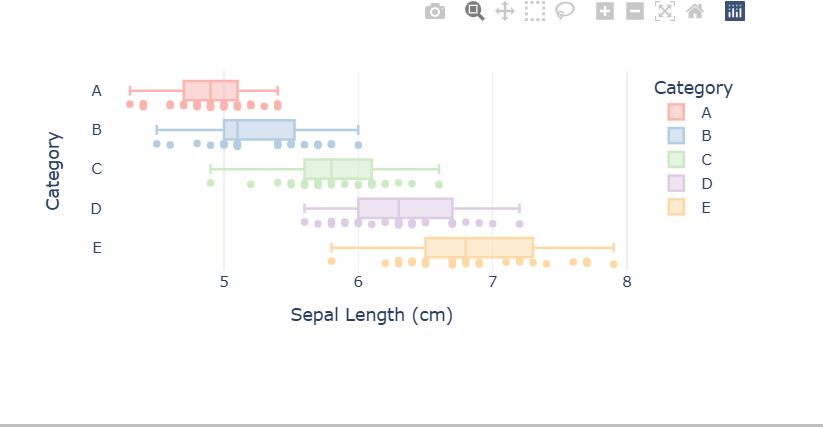
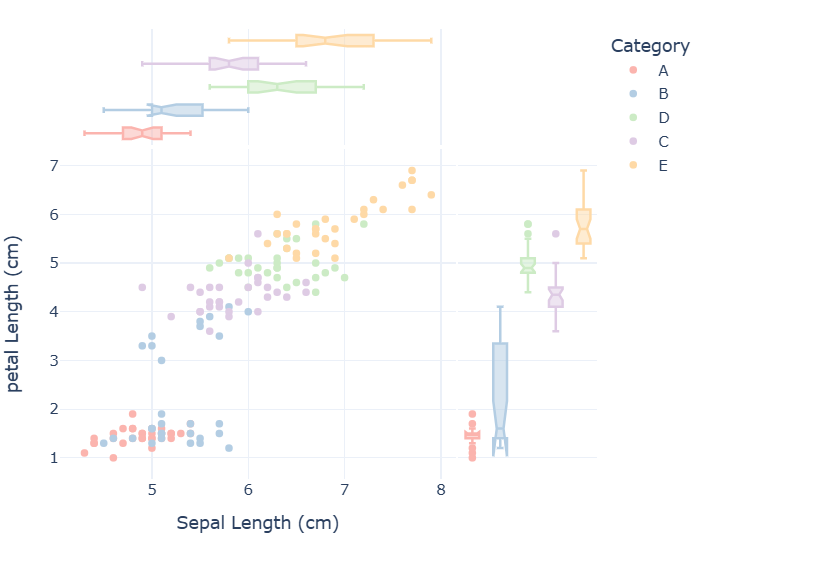
- 因原始数据没有相关的维度,故需要添加相关的维度
- 确定一下钻取顺序情况
- 对其进行可视化
import pandas as pd
import seaborn as sns
import plotly.express as px
df=sns.load_dataset("iris")
df['area']=df['sepal_length']*df['sepal_width']
df['Category']=pd.qcut(df['area'],5,labels=['A','B','C','D','E'])
labels=["{0}~{1} cm".format(i,i+1) for i in range(4,8)]
df["sepal_length_bins"]=pd.cut(df.sepal_length,range(4,9),right=False,labels=labels)
df['bi']=df['sepal_length']/df['sepal_width']
df['Category1']=pd.qcut(df['bi'],4,labels=['ⅰ','ⅱ','ⅲ','ⅳ'])
dims=['species','Category','Category1','sepal_length_bins']
prob_matrix_by_4=df.groupby(dims)['sepal_length'].apply(lambda x:x.count()/len(df))
prob_matrix_by_4=prob_matrix_by_4.reset_index()
prob_matrix_by_4.rename(columns={'sepal_length':'Ratio'},inplace=True)
fig=px.sunburst(prob_matrix_by_4,path=dims,
values='Ratio',width=800,height=800)
fig.show()
count_matrix=pd.crosstab(index=[df.species,df.Category,df.Category1],
columns=df.sepal_length_bins,values=df.petal_length,aggfunc='count')
count_matrix=count_matrix.stack().reset_index()
count_matrix.rename(columns={0:'count'},inplace=True)
count_matrix=count_matrix[count_matrix['count']!=0]
fig=px.icicle(count_matrix,
path=[px.Constant("all"),
'species','Category','Category1','sepal_length_bins'],
values='count',color_continuous_scale='Blues',
color='count',width=800,height=800)
fig.show()
fig=px.treemap(count_matrix,
path=[px.Constant("all"),
'species','Category','Category1','sepal_length_bins'],
values='count',color_continuous_scale='Blues',
color='count',width=800,height=800)
fig.show()
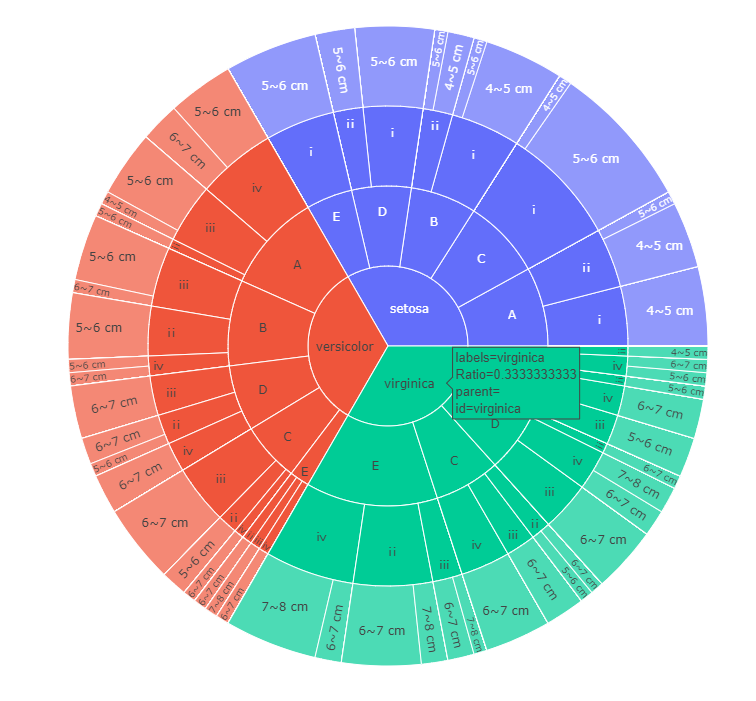
结果:
日冕图:
冰柱图:
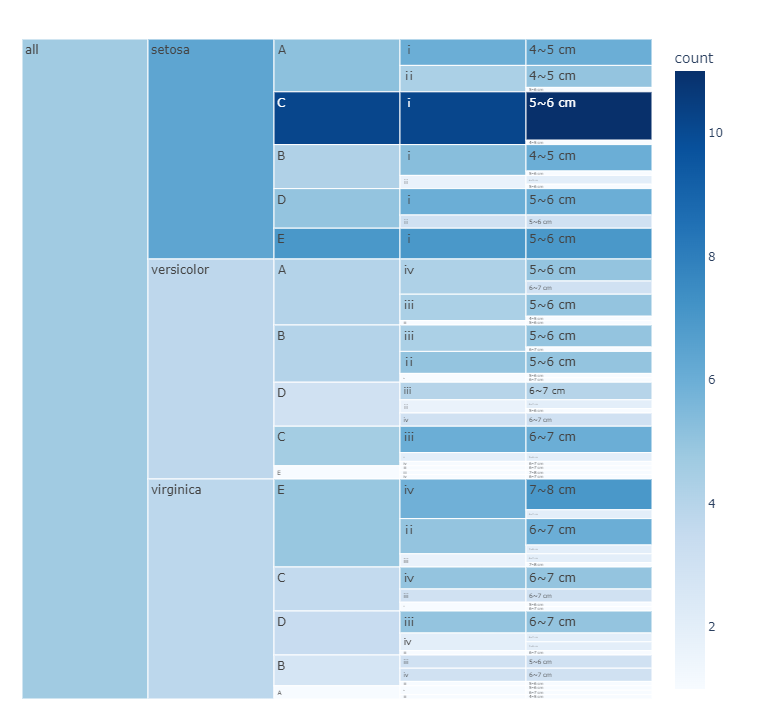
矩形树状图:

__EOF__



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本