[系统集成] 部署 mesos-exporter 和 prometheus 监控 mesos task
前几天我在mesos平台上基于 cadvisor部署了 influxdb 和 grafana,用于监控 mesos 以及 docker app 运行信息,发现这套监控系统不太适合 mesos + docker 的架构,原因是:
1)mesos task id 和 docker container name 不一致
cadvisor 的设计基于 docker host,没有考虑到mesos 数据中心;
cadvisor 用 docker name(docker ps能看到)来标记抓取的数据,而 mesos 用 task id(在mesos ui 或者metrics里能看到) 来标记正在运行的任务。mesos task 的类型可以是 docker 容器,也可以是非容器。mesos task id 与docker container name 的命名也是完全不一样的。
上述问题导致 cadvisor 抓取到数据后,用户难以识别属于哪个 mesos task
2)cadvisor 和 grafana 不支持报警
经过查询资料,发现 mesos-exporter + prometheus + alert-manager 是个很好的组合,可以解决上述问题:
mesos-exporter 是 mesosphere 开发的工具,用于导出 mesos 集群包括 task 的监控数据并传递给prometheus;prometheus是个集 db、graph、statistic 于一体的监控工具;alert-manager 是 prometheus 的报警工具
搭建方法:
1. build mesos-exporter
git clone https://github.com/mesosphere/mesos_exporter.git cd mesos_exporter docker build -f Dockerfile -t mesosphere/mesos-exporter .
2. docker pull prometheus, alert-manager
3. 部署 mesos-exporter, alert-manager, prometheus
mesos-exporter:
{
"id": "mesos-exporter-slave",
"instances": 6,
"cpus": 0.2,
"mem": 128,
"args": [
"-slave=http://127.0.0.1:5051",
"-timeout=5s"
],
"constraints": [
["hostname","UNIQUE"],
["hostname", "LIKE", "slave[1-6]"]
],
"container": {
"type": "DOCKER",
"docker": {
"image": "172.31.17.36:5000/mesos-exporter:latest",
"network": "HOST"
},
"volumes": [
{
"containerPath": "/etc/localtime",
"hostPath": "/etc/localtime",
"mode": "RO"
}
]
}
}
请打开slave 防火墙的9110/tcp 端口
alert-manager:
{
"id": "alertmanager",
"instances": 1,
"cpus": 0.5,
"mem": 128,
"constraints": [
["hostname","UNIQUE"],
["hostname", "LIKE", "slave[1-6]"]
],
"labels": {
"HAPROXY_GROUP":"external",
"HAPROXY_0_VHOST":"alertmanager.test.com"
},
"container": {
"type": "DOCKER",
"docker": {
"image": "172.31.17.36:5000/alertmanager:latest",
"network": "BRIDGE",
"portMappings": [
{ "containerPort": 9093, "hostPort": 0, "servicePort": 0, "protocol": "tcp" }
]
},
"volumes": [
{
"containerPath": "/etc/localtime",
"hostPath": "/etc/localtime",
"mode": "RO"
},
{
"containerPath": "/etc/alertmanager/config.yml",
"hostPath": "/var/nfsshare/alertmanager/config.yml",
"mode": "RO"
},
{
"containerPath": "/alertmanager",
"hostPath": "/var/nfsshare/alertmanager/data",
"mode": "RW"
}
]
}
}
prometheus:
{
"id": "prometheus",
"instances": 1,
"cpus": 0.5,
"mem": 128,
"args": [
"-config.file=/etc/prometheus/prometheus.yml",
"-storage.local.path=/prometheus",
"-web.console.libraries=/etc/prometheus/console_libraries",
"-web.console.templates=/etc/prometheus/consoles",
"-alertmanager.url=http://alertmanager.test.com"
],
"constraints": [
["hostname","UNIQUE"],
["hostname", "LIKE", "slave[1-6]"]
],
"labels": {
"HAPROXY_GROUP":"external",
"HAPROXY_0_VHOST":"prometheus.test.com"
},
"container": {
"type": "DOCKER",
"docker": {
"image": "172.31.17.36:5000/prometheus:latest",
"network": "BRIDGE",
"portMappings": [
{ "containerPort": 9090, "hostPort": 0, "servicePort": 0, "protocol": "tcp" }
]
},
"volumes": [
{
"containerPath": "/etc/localtime",
"hostPath": "/etc/localtime",
"mode": "RO"
},
{
"containerPath": "/etc/prometheus",
"hostPath": "/var/nfsshare/prometheus/conf",
"mode": "RO"
},
{
"containerPath": "/prometheus",
"hostPath": "/var/nfsshare/prometheus/data",
"mode": "RW"
}
]
}
}
4. prometheus 配置
prometheus.yml
# my global config
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
# scrape_timeout is set to the global default (10s).
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
# - "first.rules"
# - "second.rules"
scrape_configs:
- job_name: 'mesos-slaves'
scrape_interval: 5s
metrics_path: '/metrics'
scheme: 'http'
target_groups:
- targets: ['172.31.17.31:9110', '172.31.17.32:9110', '172.31.17.33:9110', '172.31.17.34:9110', '172.31.17.35:9110', '172.31.17.36:9110']
- labels:
group: 'office'
待补充 ...
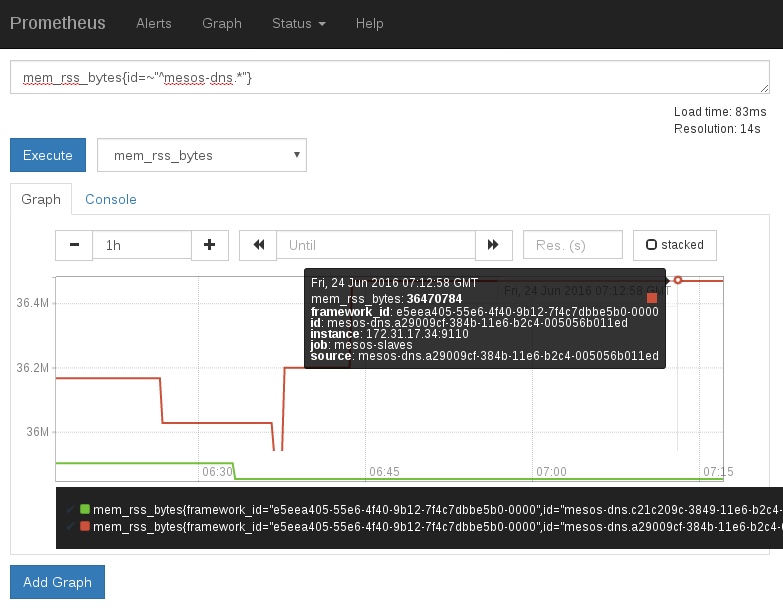
5. 报警设置
待补充 ...
6. 与 grafana 集成
prometheus的 graph 功能不太完善,可以与 grafana 集成,让 grafana 承担 graph 功能。
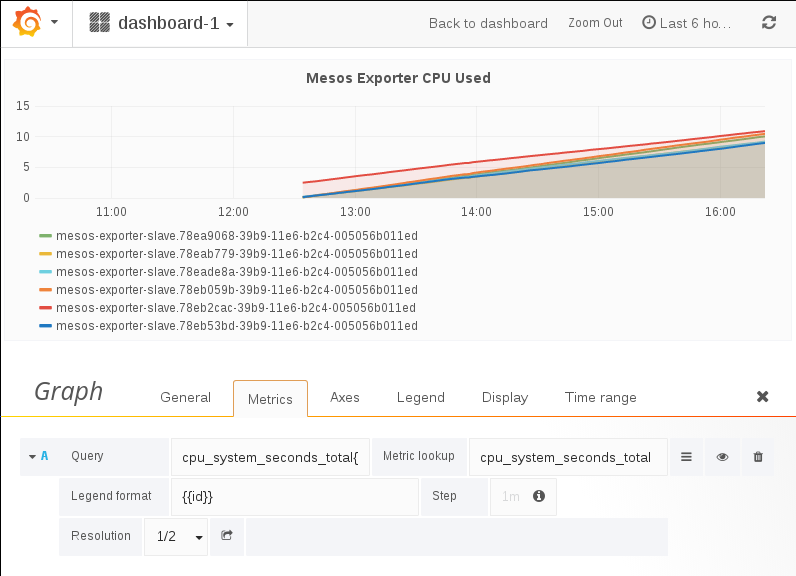
data source 设置:

7. 附:mesos metrics 和 statics 地址
http://master1:5050/metrics/snapshot
http://slave4:5051/metrics/snapshot
http://master1:5050/master/state.json
http://slave4:5051/monitor/statistics.json
用户可以基于上述页面的数据,编写自己的监控程序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号