
20201215 王馨瑶 2019-2020-2 《python程序设计》实验四报告
20201215 王馨瑶 2019-2020-2 《python程序设计》实验四报告
1. 实验内容和源码链接
这次实验的构想是爬取网易云华语音乐热评并可视化,分为三步走:
-
从网页爬取每个华语歌单的id
-
通过歌单id获取歌单中每首歌的URL
-
从每首歌的首页爬取热评
-
评论可视化
实验中用到的部分库:(新认识了好多)
| ----------库---------- | -------------------------------------------------功能---------------------------------------------- |
|---|---|
| logging | 日志,感觉是一个有调调的库!通过格式化输出,我在屏幕上就能根据自己的需要在屏幕上显示程序进程,在这次实验中我用来显示爬虫进程 |
| PyQuery | html解析,类似bs4 |
| requests | 让HTML说人话 |
| pandas | python中的Excel |
| jieba.analyse | 提取句子关键字 |
| matplotlib.pyplo | 数据可视化 |
| numpy | 利用matplotlib+numpy绘制多种绘图 |
| PIL | 图像处理库 |
| wordcloud | 根据词条可视化 |
| random | 随机数 |
| time | 时间戳、进程延迟等 |
源码链接:
2.实验过程
def main():
detail_list = []
url_01 = get_list()
for l in url_01:
logging.info('detail url is %s', l)
detail_list_part = scrape_detail(l)
detail_list.extend(detail_list_part) # 列表合并,得到最后的完整歌单信息列表
time.sleep(5 + random.random())
save_date(detail_list)
2.1 爬取华语歌单id,通过歌单id和API获取每个歌单中的所有歌曲的URL
2.1.1 观察网页URL规律
先来观察一下要爬的网页

点击不同的页码数观察url的变化
(https://music.163.com/#/discover/playlist/?order=hot&cat=华语&limit=35&offset=0)
(https://music.163.com/#/discover/playlist/?order=hot&cat=华语&limit=35&offset=35)
(https://music.163.com/#/discover/playlist/?order=hot&cat=华语&limit=35&offset=70)
(https://music.163.com/#/discover/playlist/?order=hot&cat=华语&limit=35&offset=105)
URL格式:...&limit=35&offset=25n
2.1.2 API方法
找到每页歌单界面的URL规律后,就可以开始爬虫了,寻找需要的相关数据并存储在excel表格中
对于如何在茫茫数据中找到自己需要的数据很是头疼,网上冲浪的时候查找到了这个用api的方法,只需要获得歌单ID,通过API就可以获得所有关于歌单的详细内容。虽然不是很理解他的原理。。。。但是照搬下来很好用!【大拇指】
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序,与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
后面对于热评的获取,也是只需要获得歌曲ID,再用网易云热评API即可得到详细的歌曲热评

例如这就是对某个歌单用API获取的JSON格式页面
复制到下面这个JSON在线解析工具,看得更清晰一些
JSON在线 | JSON解析格式化—SO JSON在线工具
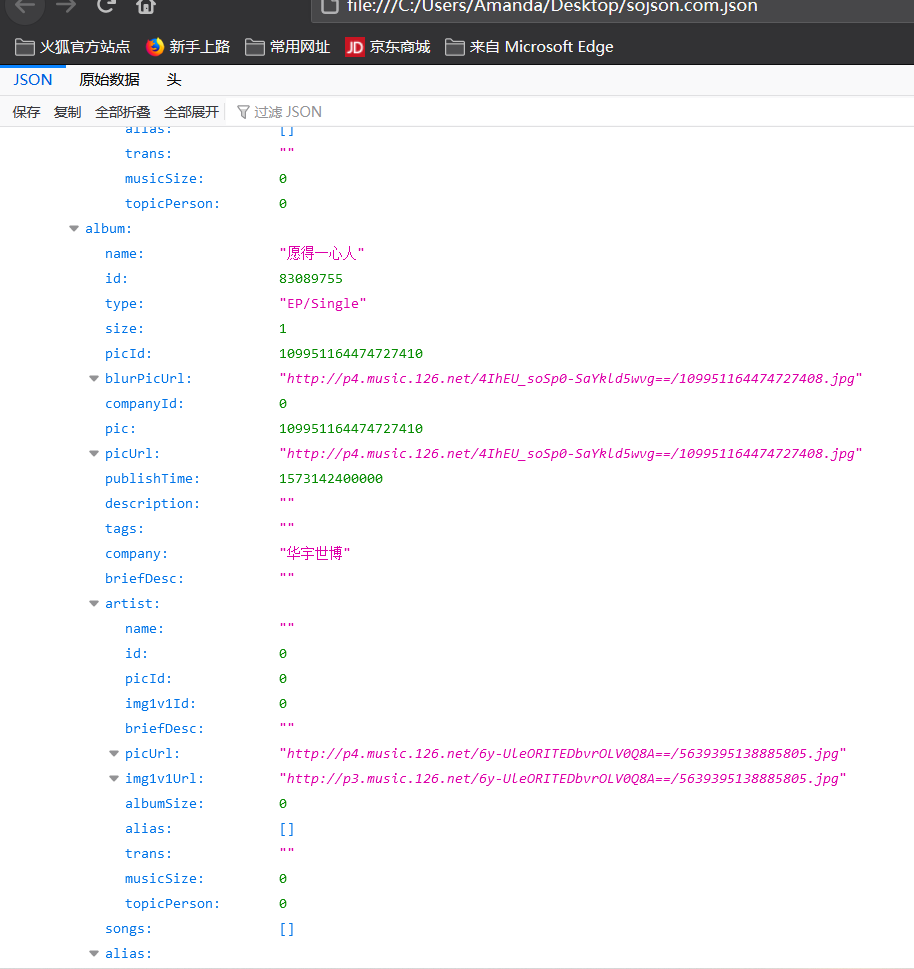
解析后的样子舒服多了。从这里面可以观察到在tracks目录下,代表下标的0,1,2,3……数字下有name,和id,即为歌单包含的歌曲名字和id。这里注意不要错弄成歌手的名字和ID了。


2.1.3 获取每个歌曲URL并存入列表
通过之前获取的网页URL规律,爬取当前页面的包含的歌单的ID,再根据API获取每个歌单中每个歌曲的URL,添加到列表中来。(详细内容请看代码和其注释)
按规律改变“page”得到相应URL,进入scrape_index(URL)函数,返回值是该页面的html,遍历html,通过attr方法获取属性,得到歌曲的url,注意这里的URL需要替换成符合API要求的格式,将URL加入列表。
def get_list():
list_01 = []
url = 'https://music.163.com/discover/playlist/?order=hot&cat=%E5%8D%8E%E8%AF%AD&limit=35&offset={page}'
for page in range(0, 35, 35): # 跑一页试试,如果跑全部,改为 range(0,1295,35)
url1 = url.format(page=page)
list = []
for i in scrape_index(url1): # generator 遍历之后的i的类型仍然是qyquery类型
i_url = i.attr('href') # attr 方法来获取属性
'''
获取歌单和评论均用了网易云音乐get请求的API,快速高效!
网易云歌单API
https://music.163.com/api/playlist/detail?id={歌单ID}
热评获取API
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit=20&offset=0
'''
detail_url = f'https://music.163.com/api{i_url.replace("?", "/detail?")}' # 获取的url还需要替换一下符合API要求的格式
list.append(detail_url)
list_01.extend(list) # extend 对列表合并
time.sleep(5 + random.random()) # 文明爬虫
return list_01
其中scrape_index表示爬虫该url所有内容,如果返回状态为200则进入到parse_index函数中对获取到的html进行解析。如果返回状态非200则通过日志显示相应的异常信息。
def scrape_index(url):
response = requests.get(url, headers=headers)
logging.info('scrape index %s...', url) # 不需要再url前加%,而是,
try:
if response.status_code == 200:
return parse_index(response.text) # 传到parse_index 方法中获取歌单url列表
else:
logging.error('invaild status is %s while scraping url %s', response.status_code, url)
except Exception:
logging.error('error occurred while scraping %s', url, exc_info=True) # exc_info=True:会将异常异常信息添加到日志消息中
parse_index函数:解析html。这里为了返回多个值,使用了items函数,返回可遍历的元组数组
def parse_index(html):
doc = pq(html) # 用pyquery进行解析
a = doc('#m-pl-container .dec .s-fc0') #对应div .对应class
a1 = a.items() # 对于返回值是多个元素,然后对每个元素做处理的,需要调用items方法,返回的generator类型,可以通过for循环去取值
return a1
2.2 遍历URL列表,爬取歌曲名字、id等信息存入列表
遍历歌曲列表中的URL,爬虫,若成功,进入parse_detail函数,返回名字和id列表;再通过save_date函数,将歌曲名字和id添加到CSV文件中
def scrape_detail(url):
response = requests.get(url, headers=headers)
logging.info('scraping detail %s...', url)
try:
if response.status_code == 200:
logging.info('detail url is succeed ')
return parse_detail(response.json()) # API获取的内容返回的是json格式
else:
logging.error('invaild status is %s while scraping url %s', response.status_code, url)
except Exception:
logging.error('error occurred while scraping %s', url, exc_info=True)
def save_date(list):
df1 = pd.DataFrame(list)
df2 = pd.concat([df, df1])
df3 = df2.drop_duplicates(subset=None, keep='first', inplace=False)
df3.to_csv('music_163_02.csv', index_label="index_label", encoding='utf-8-sig') # index_label索引列的列标签
def parse_detail(html):
list_02 = []
jobs = html['result']['tracks']
for j in jobs:
dic = {}
dic['name'] = j['name'] # 创建 字典
dic['id'] = j['id']
list_02.append(dic)
return list_02
2.2从每首歌的首页爬取热评
2.2.1 main函数:
遍历含有歌曲信息的csv文件,生成每个歌曲首页的URL,以URL为参数进入scrape_comment函数,返回值是关于评论的列表。
extend() 函数用于在列表末尾一次性追加另一个序列中的多个值
通过extend函数将列表合并。
将列表转为DataFrame数据结构,加入到csv文件中。
def main():
df = pd.read_csv('music_163_02.csv', header=0) # 对上个保存的歌曲的ID的csv的内容提取,header= 0:第一行作为column
data_comment = []
for index, row in df.iterrows(): # 数据框中的行进行迭代的一个生成器,它返回每行的索引及一个包含行本身的对象。
name = row['name']
'''
网易云音乐获取热评的API
limit:返回数据条数(每页获取的数量),默认为20,可以自行更改
offset:偏移量(翻页),offset需要是limit的倍数
type:搜索的类型
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit=20&offset=0
'''
url = f'http://music.163.com/api/v1/resource/comments/R_SO_4_{row["id"]}?limit=20&offset=0' # 本文只爬取首页(第一页)的热评
data1 = scrape_comment(url, name)
data_comment.extend(data1)
df1 = pd.DataFrame(data_comment)
df1.to_csv('hotComments_06p.csv', encoding='utf-8-sig') # 是utf-8-sig 而不是utf-8
logging.info('scraping id %s', index)
time.sleep(random.random()) # 文明爬虫
2.2.2 scrape_comment函数
scrape_comment函数:爬虫该URL页面,如果成功,进入parse_comment函数,对于获取的html进行解析,返回值是关于评论的列表。
def scrape_comment(url, name):
logging.info('scraping comments %s', url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return parse_comment(response.json(), name) # 网易云热评API返回的是json格式
else:
logging.error('invaild status_code %s while scraping %s', response.status_code, url)
except Exception:
logging.error('can not scraping %s', url)
2.2.3 parse_comment函数
def parse_comment(html, name):
data = []
jobs = html['hotComments']
for job in jobs:
dic = {}
dic['nickname'] = job['user']['nickname']
dic['userid'] = job['user']['userId']
dic['content'] = job['content'].replace('\n', '') # 对换行符进行替换
dic['likecount'] = job['likedCount']
dic['time'] = stampToTime(job['time']) # 时间戳的转换
dic['name'] = name
data.append(dic)
return data
2.3评论可视化
(详细过程见代码中的注释)
import matplotlib.pyplot as plt
import pandas as pd
import jieba
import jieba.analyse
import numpy as np
from PIL import Image
from wordcloud import WordCloud
'''
读取刚刚爬好的热评文件
df1 = pd.read_csv('hotComments_06.csv',index_col = 0)
ERROR: Buffer overflow caught -缓冲区溢出
发现也是因为csv文件中单个item内有\r,即回车符
解决方法:lineterminator=”\n”:让\n作为换行符即可
'''
df3 = pd.read_csv('hotComments_06p.csv', index_col=0, lineterminator='\n')
# 空格的影响会导致打字内容一样,但却被判为不一样
# 用strip()方法去除开头或则结尾的空格
df3['content1'] = df3['content'].apply(lambda x: x.strip())
# 有些句子中有\r,因为我们以\n作为换行符,所以这些\r不属于文本,需要去掉
df3['content1'] = df3['content'].apply(lambda x: x.replace('\r', ''))
df4 = df3.drop(['content'], axis=1)
df4.rename(columns={'content1': 'content'}, inplace=True)
segments = []
for index, row in df4.iterrows():
content = row[5]
words = jieba.analyse.textrank(content, topK=3, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
for w in words: # 对分词好后的words进行提取,并且关联一个1,方便进行计数
segments.append({'word': w, 'counts': 1})
df_w = pd.DataFrame(segments)
df_w.to_csv('jieba_01.csv', index=False, encoding='utf-8-sig')
# wordcloud库制作云词
# 将我们之前做的分词列表合并成字符串,以空格连接方便制作云词
text = ' '.join(df_w['word'])
'''
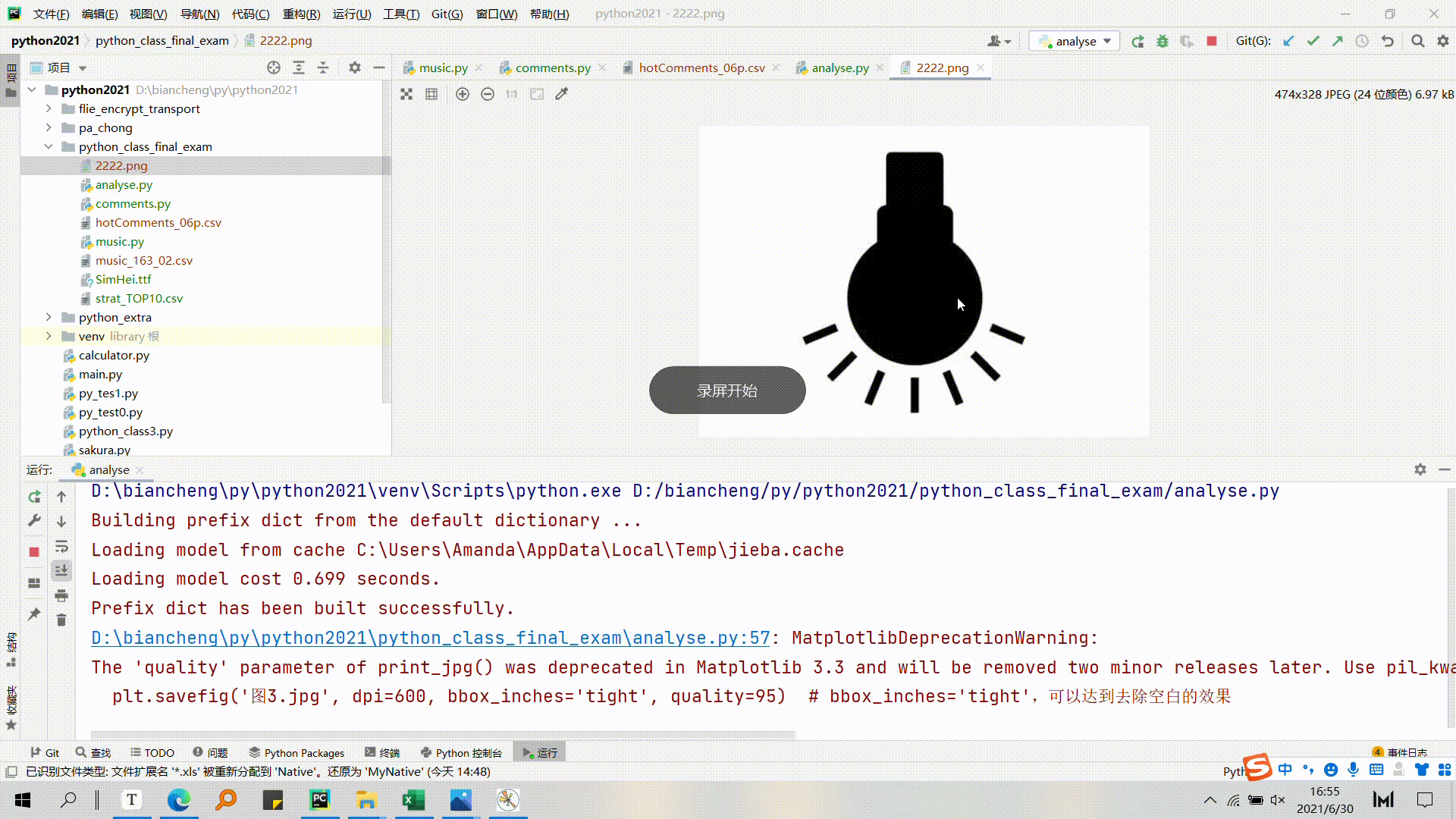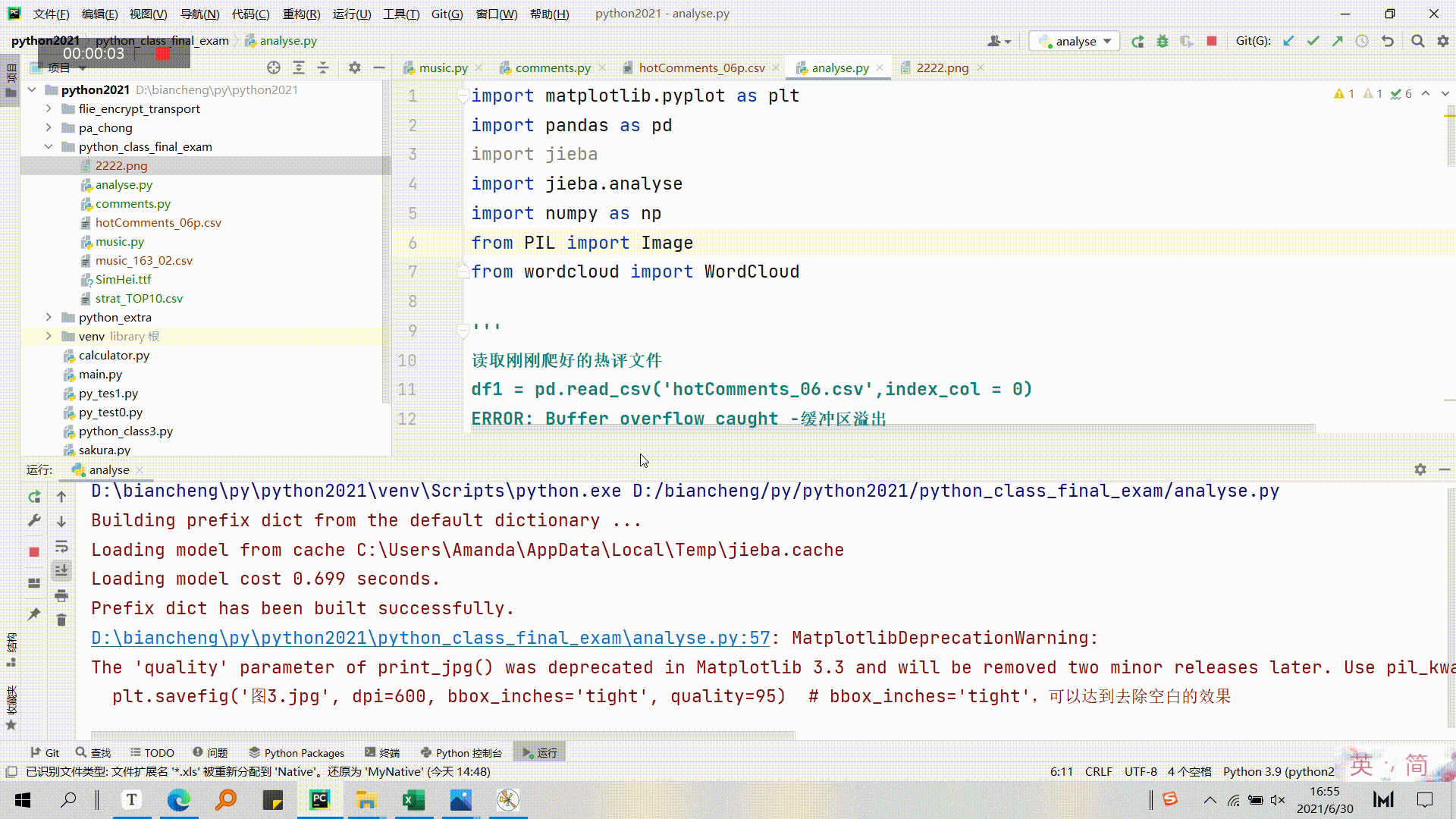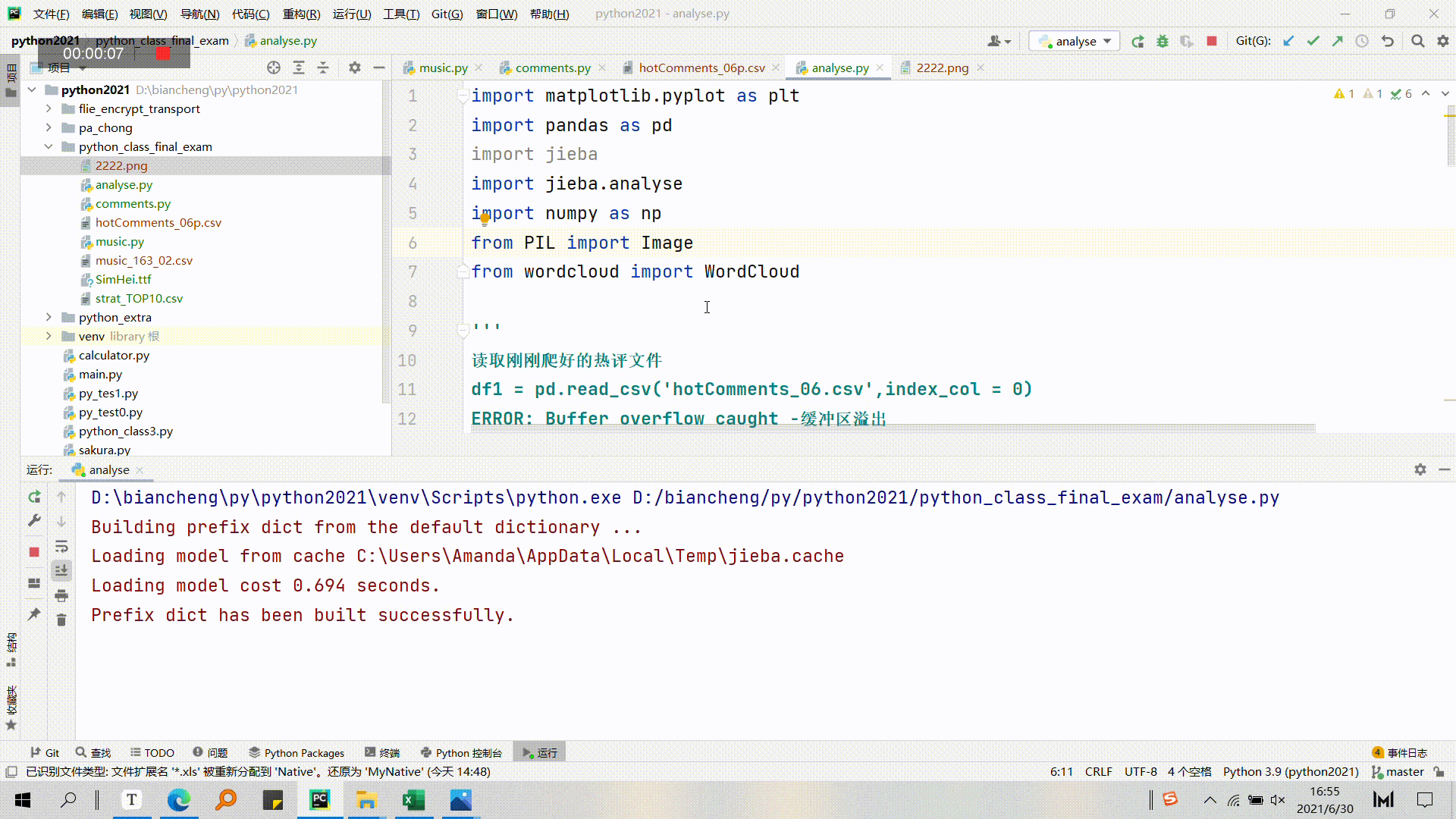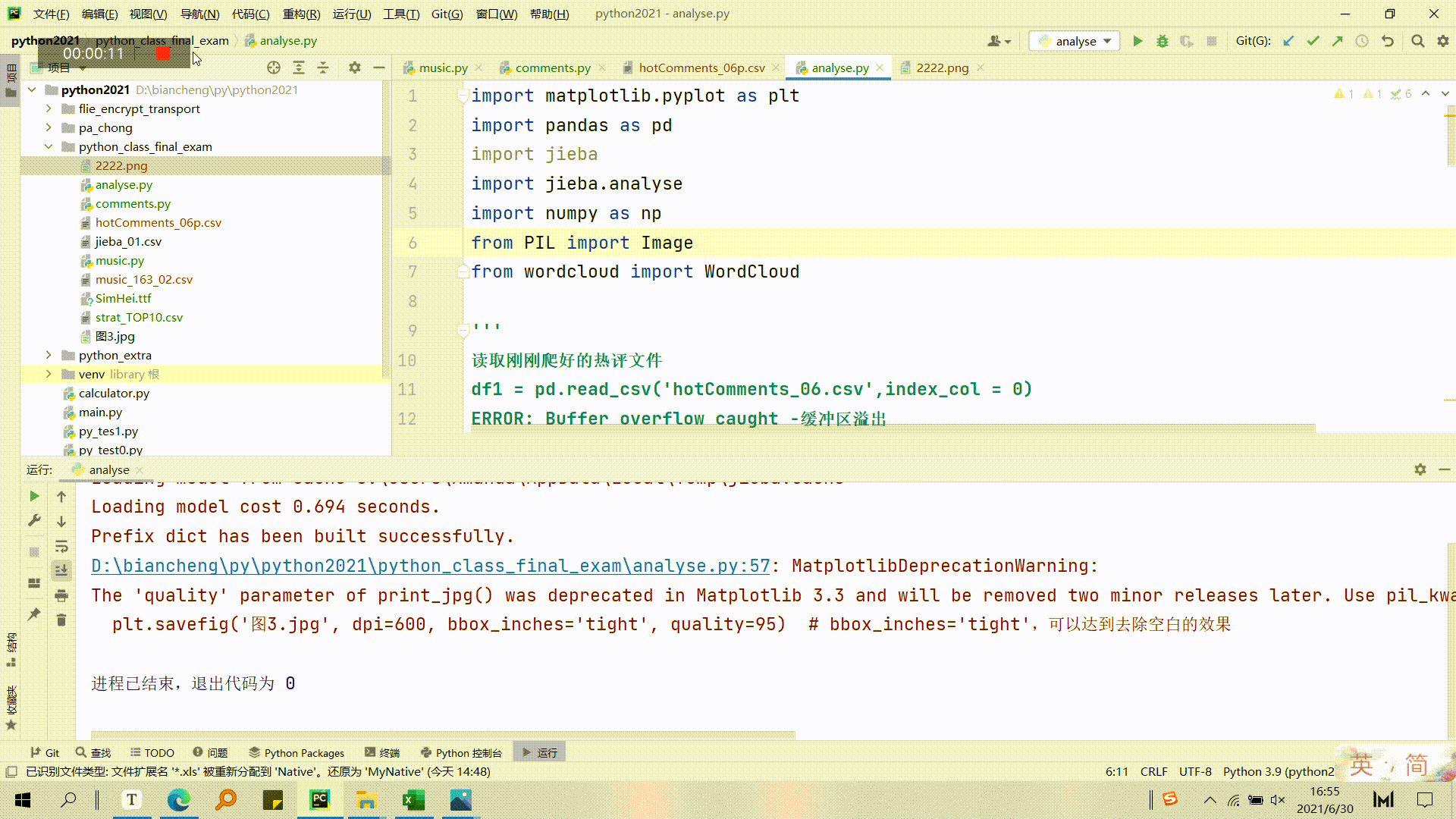
2222.png是一张作为蒙版的图片,需要转换成numy数组才可以用
利用PIL模块读取我们的png文件并转换为numpy数组,作为WordCloud的mask参数传入
'''
mask_cir = np.array(Image.open('2222.png'))
wordc = WordCloud(
background_color='white',
mask=mask_cir,
font_path='SimHei.ttf', # 中文显示的方法,baidu载一个SimHei.ttf字体包即可让云词显示中文
max_words=1000
).generate(text)
plt.imshow(wordc)
plt.axis('off') # 关闭坐标轴,更加美观
plt.savefig('图3.jpg', dpi=600, bbox_inches='tight', quality=95) # bbox_inches='tight',可以达到去除空白的效果
plt.show()
3. 运行结果和运行视频
3.1歌单Excel:

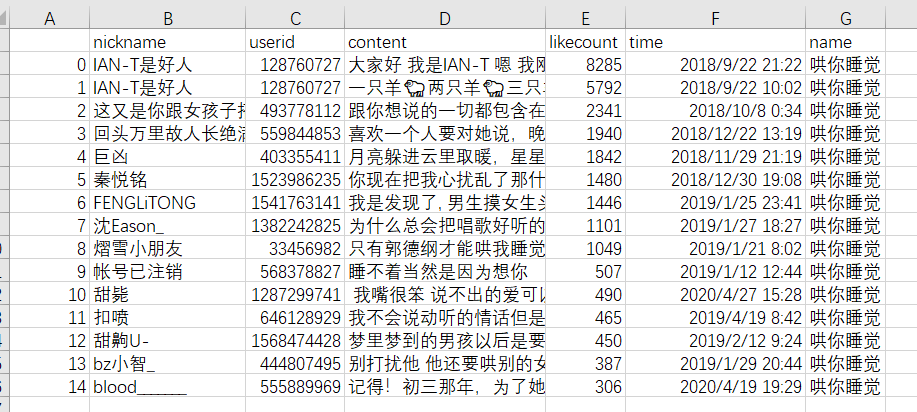
3.2生成的评论Excel

3.3 评论可视化生成的结果

这个形状有一些奇怪。。我感觉是我背景图选的不好=.=
背景图:(还是能看出一点点痕迹的)

3.4运行视频
由于爬虫时间太长了,大概7-8分钟,我提前爬好再录的视频。转换成了gif显示在这里
3.4.1 爬虫华语音乐歌单显示的日志界面,以及生成的歌单(储存歌曲名字和id)

3.4.2 爬取歌曲首页获取热评gif
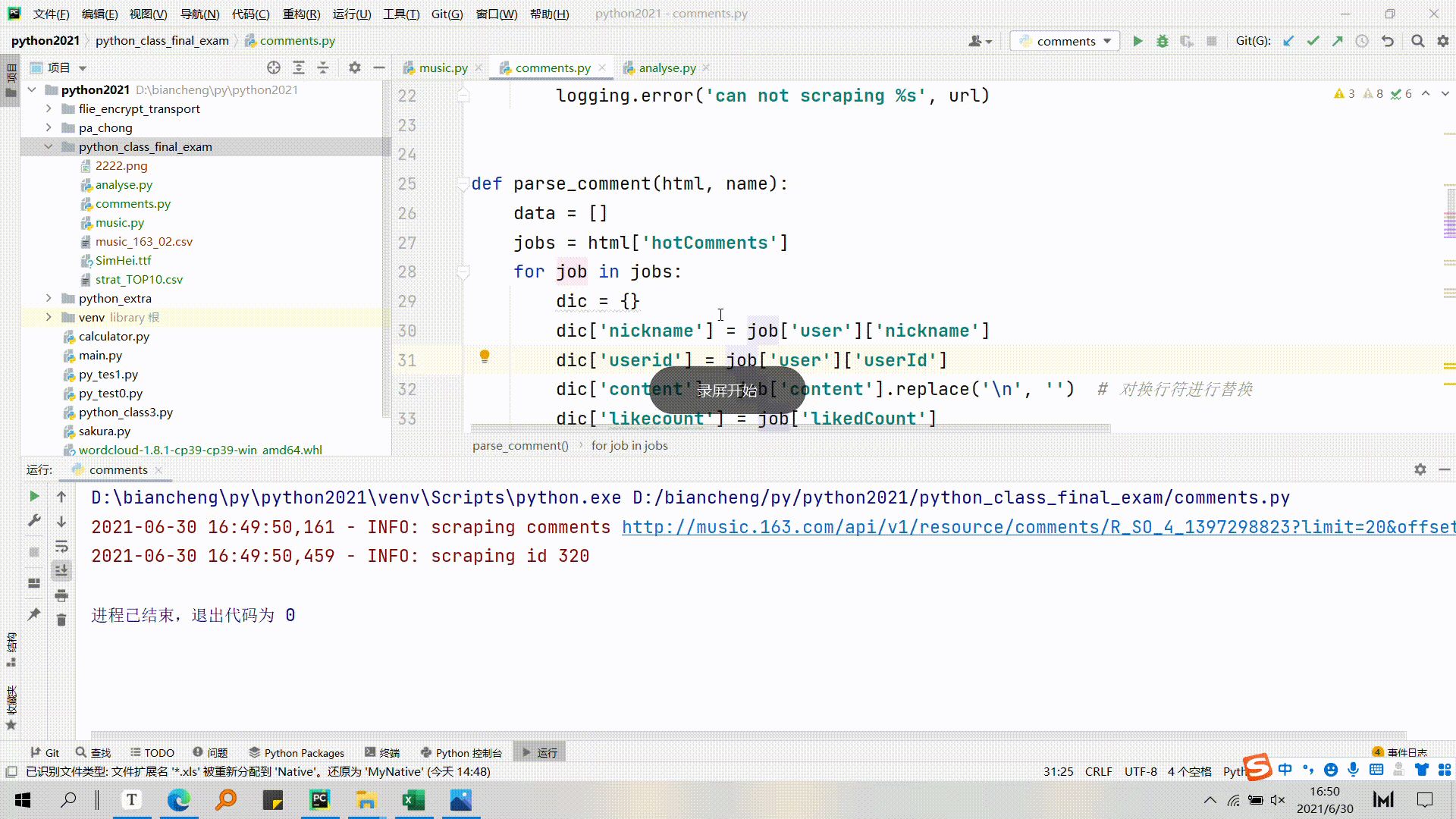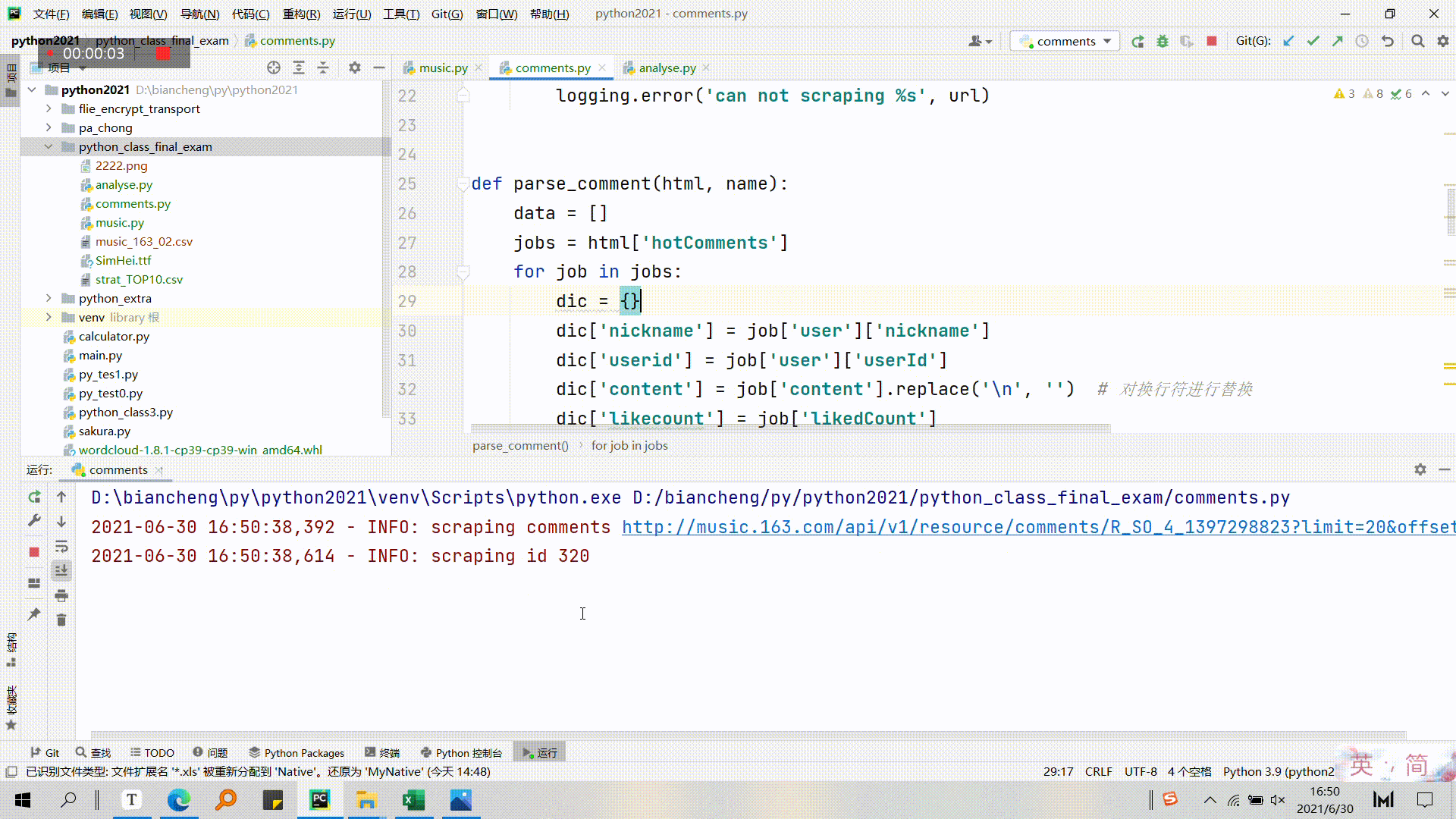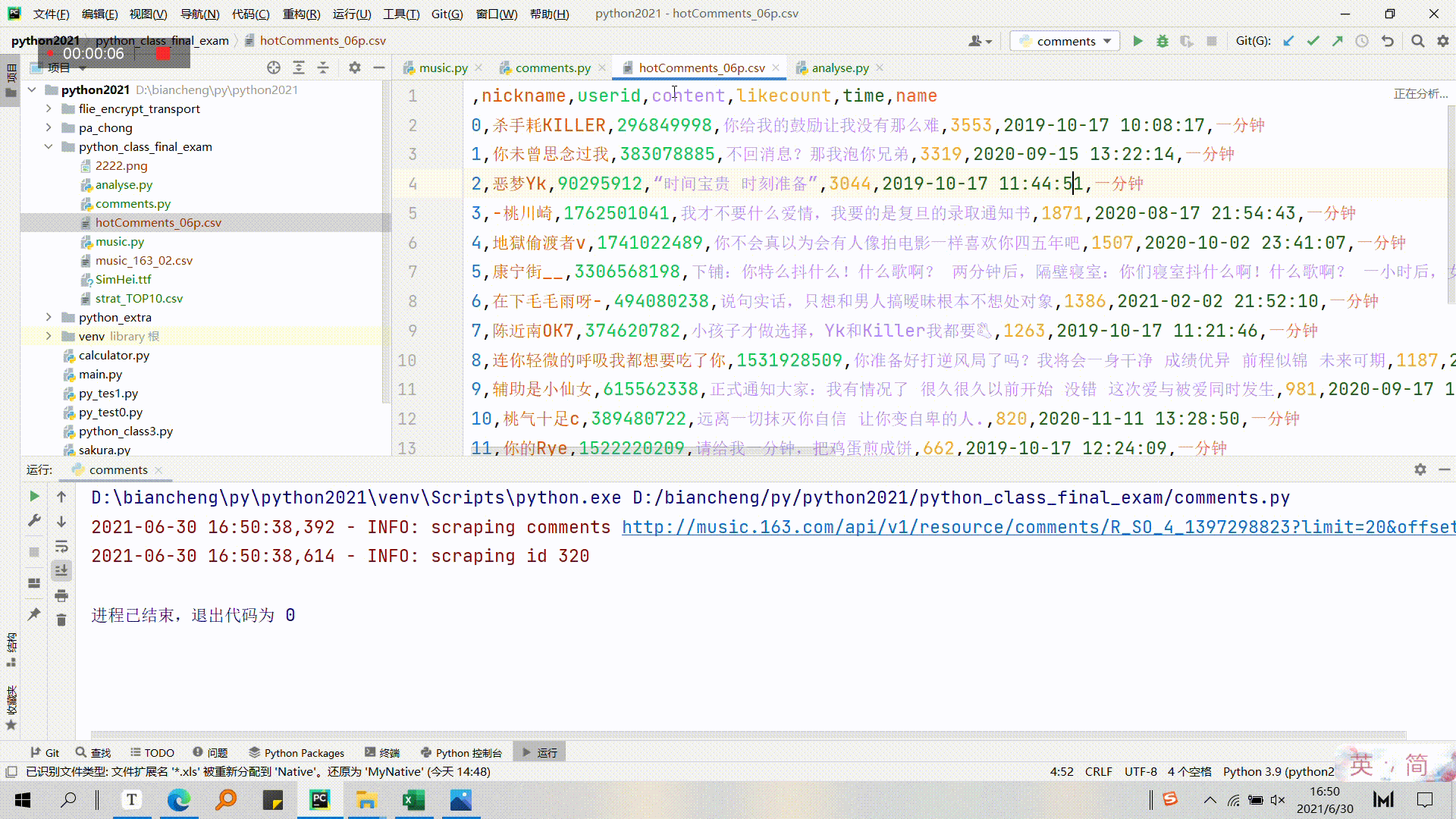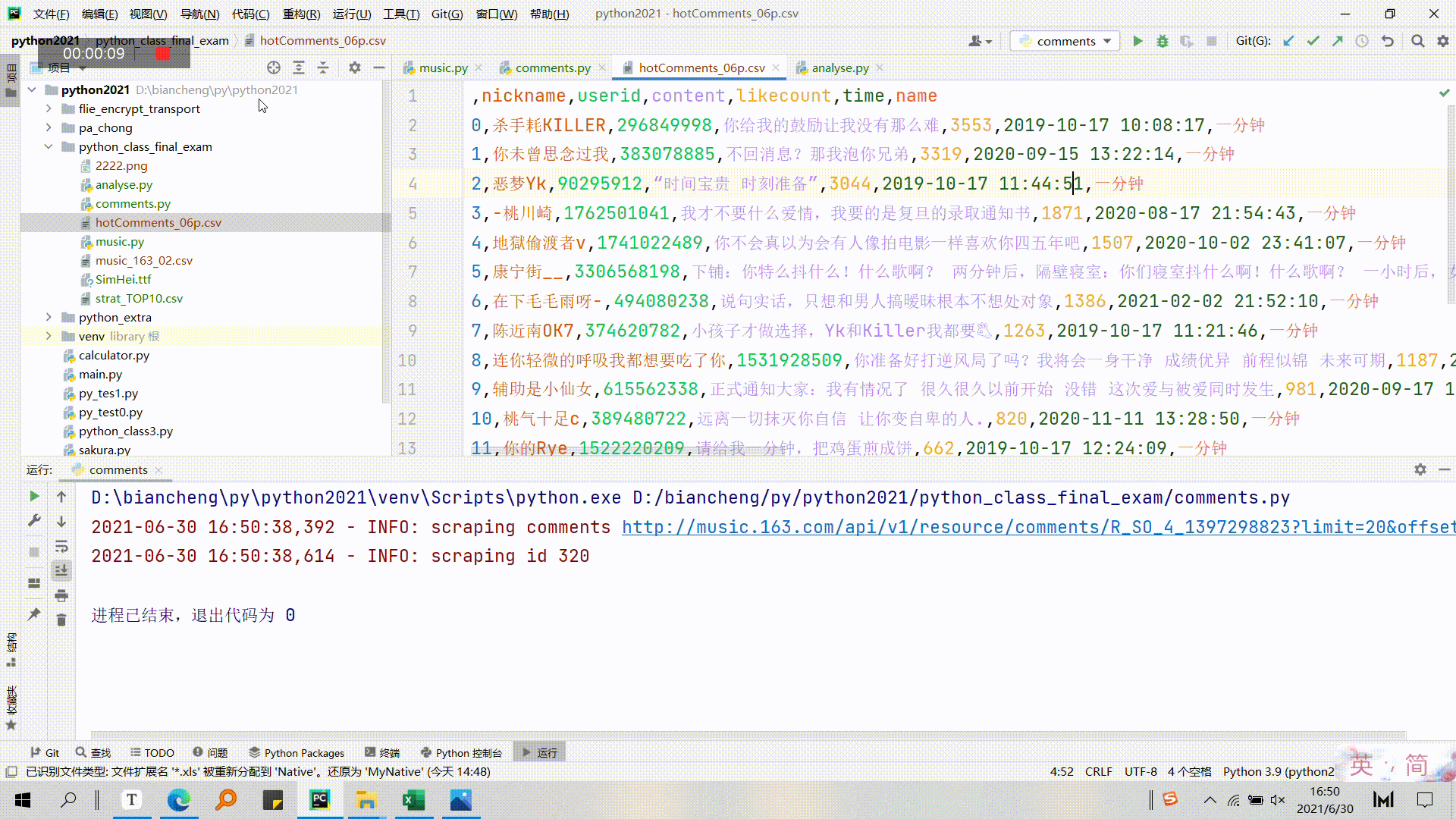
3.4.3 可视化评论gif
4.实验过程中遇到的问题和解决过程
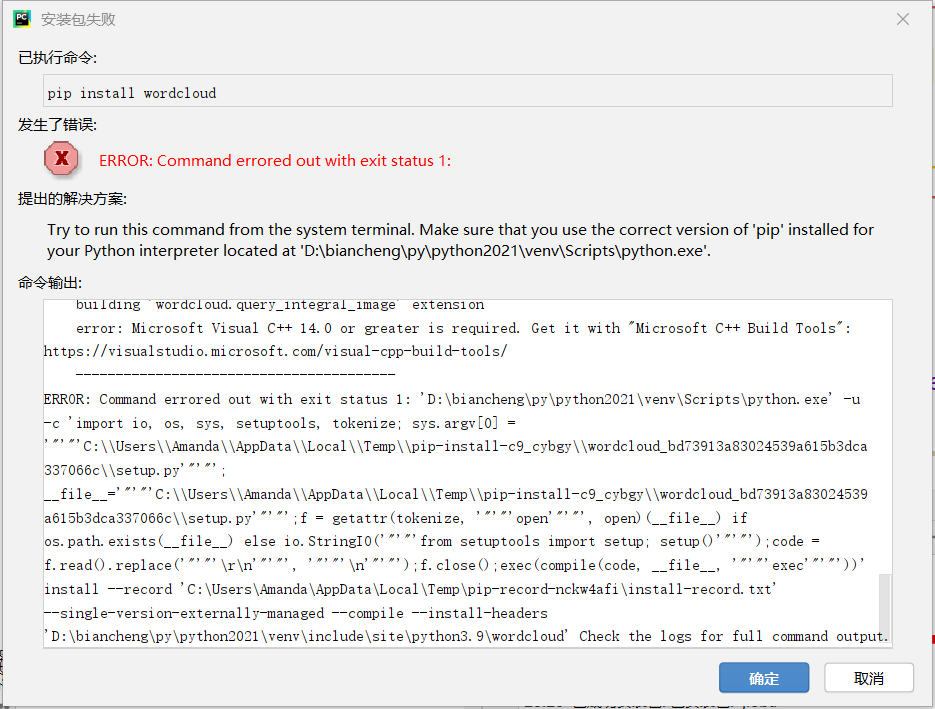
4.1 安装wordcloud库失败问题
上网搜索发现python中wordcloud库是一个很好地可以实现我想要将爬取内容根据词条进行可视化的方法,但是在安装过程中就出现了如下问题。。。于是上网查找下载方法。
4.2过程中本来应该爬取歌曲的ID,但是不小心爬成了歌手的ID。。。
4.3 返回html中相应的多个数据失败
上网查找到了.items函数,items()函数以列表返回可遍历的(键、值)元组 数组。
应用实例:
dict = {'Google': 'www.google.com', 'Runoob': 'www.runoob.com', 'taobao': 'www.taobao.com'}
print "字典值 : %s" % dict.items()
for key, values in dict.items():
print key, values
输出结果:
Google www.google.com
taobao www.taobao.com
Runoob www.runoob.com
4.4不知道如何遍历CSV文件中的行数据
查询到iterrows()函数
数据框(DataFrame)是拥有轴标签的二维链表,换言之数据框是拥有标签的行和列组成的矩阵 - 列标签位列名,行标签为索引。Pandas中的行和列是Pandas序列 - 拥有轴标签的一维链表。
iterrows()是在数据框中的行进行迭代的一个生成器,它返回每行的索引及一个包含行本身的对象。所以,当我们在需要遍历行数据的时候,就可以使用iterrows()方法实现了。
4.5读取刚刚爬好的热评文件错误
df1 = pd.read_csv('hotComments_06.csv',index_col = 0)
ERROR: Buffer overflow caught -缓冲区溢出
发现也是因为csv文件中单个item内有\r,即回车符
解决方法:lineterminator=”\n”:让\n作为换行符即可
4.6
生成的词云不显示中文
上网查找后下载中文字体库解决
5.感悟
-
学期初抱着多学习学习知识的心态,报名了python选修课。一学期下来果然没有失望,课程进度飞快,感触颇深。
-
python语言特点:
- 简单:Python是一种代表简单思想的语言。
- 易学:Python有极其简单的语法。
- 免费、开源:Python是FLOSS(自由/开放源码软件)之一。
- 高层语言:使用Python编写程序时无需考虑如何管理程序使用的内存一类的底层细节。
- 可移植性:Python已被移植到很多平台
- 解释性:可以直接从源代码运行。在计算机内部,python解释器把源代码转换为字节码的中间形式,然后再把它翻译成计算机使用的机器语言。
- 面向对象:python既支持面向过程编程也支持面向对象编程。
- 可扩展性:部分程序可以使用其他语言编写,如c/c++。
- 可嵌入型:可以把Python嵌入到c/c++程序中,从而提供脚本功能。
- 丰富的库:Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作
-
本学期学习的主要知识点:
- 变量赋值及其命名规则
- 运算符及其优先级
- 基本数据类型
- 循环语句
- 列表、元组、字典、集合及其常用功能
- 字符串与正则表达式
- 函数
- 面向对象程序设计
- 文件操作及异常处理
- Python操作数据库
- Python网络编程及爬虫开发(Socket)
-
同时,python程序设计是一门实践性很强的课。有些知识听老师讲就像听天书一样,自己动手一打代码发现也就是那么回事。这要求我们在学习python的时候有动手的意愿、也要有会动手的能力。
-
学习编程要求我们系统性的去思考一个实际的问题。在现实生活中我们可以根据事态的改变而做出决断。但写代码要求我们在大脑中模拟出所有可能发生的事件,并一一进行解决。
-
还有一个很重要的能力是学会自行解决问题。遇到报错如何从众多解决方案中分析出适合自己的那一个?想借用网上的代码如何一步一步分析出代码含义并进行改造、融合到自己的代码中?这些都是属于自己的、一些比较综合的能力,遇到问题就依赖别人,这样的学习方法是走不远的。
-
我相信大部分同学报名python这门课程都是冲着学习知识来的,这也是我的初衷。但面对上课听不懂、作业不会做的现实,我们是否仍然记得学期初的初心?又是否有耐心静下心来一点一点啃书上的知识?我也在反思我自己,有时候因为一时的惰性就沉不下心来学习,玩了很久之后内心又感到空虚。其实有时候坚持自己也没有那么难,去做自己真真正正想做的事情就好。
-
课程建议:
- 多给一些上课实践的环节,但考虑到上课人数,实施起来确实有困难
- 视频实在是太多太多了。。。真的看不完,建议精简一些~

