

ELK Stack生产实践第六篇:—自定义日志采集(Filebeat方式) => Filebeat采集——>kafka消息缓冲队列——>logstash解析处理数据——>es存储——>kibana数据可视化 (推荐使用)
转载自:https://www.cuiliangblog.cn/detail/article/63
在某些存在业务高峰期的场景下,期间可能会产生大量日志,如果继续使用fleet采集日志,使用ingest处理数据,可能会出现写入堆积的情况。此时可采用传统的Filebeat方式采集日志,引入Kafka作为消息缓冲队列,保证日志传输数据的可靠性和稳定性。接下来以日志demo程序为例,实现Filebeat采集——>kafka消息缓冲队列——>logstash解析处理数据——>es存储——>kibana数据可视化分析完整流程的演示。
日志demo程序部署
项目地址
代码仓库地址:https://gitee.com/cuiliang0302/log_demo
日志格式
模拟常见的后端服务日志,格式如下
2023-07-23 09:35:18.987 | INFO | __main__:debug_log:49 - {'access_status': 200, 'request_method': 'GET', 'request_uri': '/account/', 'request_length': 67, 'remote_address': '186.196.110.240', 'server_name': 'cu-36.cn', 'time_start': '2023-07-23T09:35:18.879+08:00', 'time_finish': '2023-07-23T09:35:19.638+08:00', 'http_user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36'}
2023-07-23 09:35:19.728 | WARNING | __main__:debug_log:47 - {'access_status': 403, 'request_method': 'PUT', 'request_uri': '/public/', 'request_length': 72, 'remote_address': '158.113.125.213', 'server_name': 'cu-35.cn', 'time_start': '2023-07-23T09:35:18.948+08:00', 'time_finish': '2023-07-23T09:35:20.343+08:00', 'http_user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36'}
2023-07-23 09:35:19.793 | INFO | __main__:debug_log:49 - {'access_status': 200, 'request_method': 'GET', 'request_uri': '/public/', 'request_length': 46, 'remote_address': '153.83.121.71', 'server_name': 'cm-17.cn', 'time_start': '2023-07-23T09:35:19.318+08:00', 'time_finish': '2023-07-23T09:35:20.563+08:00', 'http_user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0'}
2023-07-23 09:35:20.614 | ERROR | __main__:debug_log:45 - {'access_status': 502, 'request_method': 'GET', 'request_uri': '/public/', 'request_length': 62, 'remote_address': '130.190.246.56', 'server_name': 'cu-34.cn', 'time_start': '2023-07-23T09:35:20.061+08:00', 'time_finish': '2023-07-23T09:35:21.541+08:00', 'http_user_agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'}
部署
[root@es-master ~]# cd /opt/
[root@es-master opt]# git clone https://gitee.com/cuiliang0302/log_demo.git
[root@es-master opt]# cd log_demo/
[root@es-master log_demo]# ls
Dockerfile log.py main.py readme.md requirements.txt
[root@es-master log_demo]# docker build -t log_demo:1.0 .
[root@es-master log_demo]# docker run --name log_demo -d -v /var/log/log_demo:/opt/logDemo/log --restart always log_demo:1.0
[root@es-master log]# cd /var/log/log_demo/
[root@es-master log_demo]# ll
total 44
-rw-r--r-- 1 root root 4320 Jul 19 22:33 error.log
-rw-r--r-- 1 root root 22729 Jul 19 22:33 info.log
-rw-r--r-- 1 root root 8612 Jul 19 22:33 warning.log
Filebeat部署配置
下载地址
https://www.elastic.co/downloads/beats
安装
建议下载rpm包进行安装,版本跟es的版本号保持一致
[root@es-master ~]# cat > /etc/yum.repos.d/elastic.repo << EOF
[elastic-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
[root@es-master ~]# dnf -y install filebeat
[root@es-master ~]# systemctl enable filebeat
修改配置
读取/opt/log_demo/log下的文件,输出到kafka集群中
[root@es-master ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/log_demo/info.log
output.kafka:
enable: true
hosts: ["es-hot1:9092","es-hot2:9092","es-hot3:9092"]
topic: "log_demo"
partition.round_robin:
reachable_only: false
required_acks: -1
compression: gzip
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat
keepfiles: 7
permissions: 0644
[root@es-master ~]# mkdir /var/log/filebeat
测试配置文件
使用控制台直接指定yml文件方式启动测试,查看日志是否有报错。
[root@es-master ~]# filebeat -e -c /etc/filebeat/filebeat.yml
{"log.level":"info","@timestamp":"2023-07-18T17:56:18.409+0800","log.origin":{"file.name":"instance/beat.go","file.line":779},"message":"Home path: [/usr/share/filebeat] Config path: [/etc/filebeat] Data path: [/var/lib/filebeat] Logs path: [/var/log/filebeat]","service.name":"filebeat","ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2023-07-18T17:56:18.410+0800","log.origin":{"file.name":"instance/beat.go","file.line":787},"message":"Beat ID: 5d6d4273-b4f8-4cf4-ba39-abab53f6aea2","service.name":"filebeat","ecs.version":"1.6.0"}
启动filebeat
[root@es-master ~]# systemctl start filebeat
kafka部署
本示例中采用最新的kafka kraft模式,优点在于不再依赖 zookeeper 集群,部署维护更加方便。用三台 controller 节点代替zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
下载地址
http://archive.apache.org/dist/kafka/
[root@es-hot1 ~]# wget http://archive.apache.org/dist/kafka/3.5.0/kafka_2.13-3.5.0.tgz
安装jdk
yum安装
[root@es-hot1 ~]# dnf -y install java-11-openjdk
或者使用二进制安装
[root@es-hot1 ~]# wget https://builds.openlogic.com/downloadJDK/openlogic-openjdk/17.0.7+7/openlogic-openjdk-17.0.7+7-linux-x64.tar.gz
[root@es-hot1 ~]# tar -zxf openlogic-openjdk-17.0.7+7-linux-x64.tar.gz -C /usr/local
[root@es-hot1 ~]# cd /usr/local/openlogic-openjdk-17.0.7+7-linux-x64/
[root@es-hot1 ~ openlogic-openjdk-17.0.7+7-linux-x64]# ls
bin conf demo include jmods legal lib man release
# 添加环境变量
[root@jenkins ~]# vim /etc/profile
export JAVA_HOME=/usr/local/openlogic-openjdk-17.0.7+7-linux-x64
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
[root@es-hot1 ~ ~]# source /etc/profile
[root@jenkins openlogic-openjdk-17.0.7+7-linux-x64]# java -version
openjdk version "17.0.7" 2023-04-18
OpenJDK Runtime Environment OpenLogic-OpenJDK (build 17.0.7+7-adhoc.root.jdk17u)
OpenJDK 64-Bit Server VM OpenLogic-OpenJDK (build 17.0.7+7-adhoc.root.jdk17u, mixed mode, sharing)
# 创建软连接
[root@es-hot1 ~ ~]# ln -s /usr/local/openlogic-openjdk-17.0.7+7-linux-x64/bin/java /usr/bin/java
解压安装kafka
[root@es-hot1 ~]# tar -zxf kafka_2.13-3.5.0.tgz -C /usr/local
[root@es-hot1 ~]# cd /usr/local/kafka_2.13-3.5.0/
[root@es-hot1 kafka_2.13-3.5.0]# ls
LICENSE NOTICE bin config libs licenses site-docs
# 创建kafka数据目录
[root@es-hot1 kafka]# mkdir /data/kafka-data
修改配置
[root@es-hot1 kafka]# vim /usr/local/kafka_2.13-3.5.0/config/kraft/server.properties
process.roles=broker,controller
node.id=1 # 节点ID,每个节点的值要不同
controller.quorum.voters=1@es-hot1:9093,2@es-hot2:9093,3@es-hot3:9093 # Controller节点配置,用于管理状态的节点(替换Zookeeper作用)
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.10.133:9092 # 使用IP端口,每个节点填写自己节点的IP
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka-data # 数据存储位置
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
三台hot服务器都要修改,修改内容为
# 节点ID,每个节点的值要不同,与controller.quorum.voters列表保持一致
node.id=1
# 使用IP端口,每个节点填写自己节点的IP
advertised.listeners=PLAINTEXT://192.168.10.133:9092
初始化集群
在其中一台服务器上执行下面命令生成一个uuid
[root@es-hot1 ~]# sh /usr/local/kafka_2.13-3.5.0/bin/kafka-storage.sh random-uuid
mO5FD8M9S0aRmVZxHZkZIA
用该uuid格式化kafka存储目录,三台服务器都要执行以下命令
[root@es-hot1 ~]# sh /usr/local/kafka_2.13-3.5.0/bin/kafka-storage.sh format -t mO5FD8M9S0aRmVZxHZkZIA -c /usr/local/kafka_2.13-3.5.0/config/kraft/server.properties
Formatting /data/kafka-data with metadata.version 3.5-IV2.
启动集群
三台都需要启动
[root@es-hot1 ~]# sh /usr/local/kafka_2.13-3.5.0/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.13-3.5.0/config/kraft/server.properties
验证
查看日志
[root@es-hot1 ~]# tail -n 30 /usr/local/kafka_2.13-3.5.0/logs/kafkaServer.out
[2023-07-18 21:46:44,857] INFO [BrokerServer id=1] Finished waiting for all of the authorizer futures to be completed (kafka.server.BrokerServer)
[2023-07-18 21:46:44,857] INFO [BrokerServer id=1] Waiting for all of the SocketServer Acceptors to be started (kafka.server.BrokerServer)
[2023-07-18 21:46:44,857] INFO [BrokerServer id=1] Finished waiting for all of the SocketServer Acceptors to be started (kafka.server.BrokerServer)
[2023-07-18 21:46:44,857] INFO [BrokerServer id=1] Transition from STARTING to STARTED (kafka.server.BrokerServer)
[2023-07-18 21:46:44,858] INFO Kafka version: 3.5.0 (org.apache.kafka.common.utils.AppInfoParser)
[2023-07-18 21:46:44,858] INFO Kafka commitId: c97b88d5db4de28d (org.apache.kafka.common.utils.AppInfoParser)
[2023-07-18 21:46:44,858] INFO Kafka startTimeMs: 1689688004857 (org.apache.kafka.common.utils.AppInfoParser)
[2023-07-18 21:46:44,862] INFO [KafkaRaftServer nodeId=1] Kafka Server started (kafka.server.KafkaRaftServer)
查看进程
[root@es-hot1 ~]# ps -aux | grep kafka
创建topic测试
[root@es-hot1 ~]# sh /usr/local/kafka_2.13-3.5.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test --partitions 3 --replication-factor 3
Created topic test.
查看topic详情
[root@es-hot1 ~]# sh /usr/local/kafka_2.13-3.5.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe test
Topic: test TopicId: QvDV8pJwSTC7NQwrNfjfAw PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: test Partition: 1 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: test Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
配置服务管理脚本
三台都需要配置
[root@es-hot1 ~]# cat > /usr/lib/systemd/system/kafka.service << EOF
[Unit]
Description=Apache Kafka server (broker)
After=network.target
[Service]
Type=forking
User=root
Group=root
ExecStart=/usr/local/kafka_2.13-3.5.0/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.13-3.5.0/config/kraft/server.properties
ExecStop=/usr/local/kafka_2.13-3.5.0/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
[root@es-hot1 ~]# systemctl daemon-reload
[root@es-hot1 ~]# systemctl restart kafka
[root@es-hot1 ~]# systemctl enable kafka
Created symlink /etc/systemd/system/multi-user.target.wants/kafka.service → /usr/lib/systemd/system/kafka.service.
[root@es-hot1 ~]# systemctl status kafka
● kafka.service - Apache Kafka server (broker)
Loaded: loaded (/usr/lib/systemd/system/kafka.service; enabled; preset: disabled)
Active: active (running) since Tue 2023-07-18 22:42:07 CST; 7s ago
Process: 3067 ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/kraft/server.properties (code=exited, status=0/SUCCESS)
Main PID: 3412 (java)
Tasks: 87 (limit: 23012)
Memory: 315.7M
CPU: 12.183s
CGroup: /system.slice/kafka.service
└─3412 java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:Max>
Jul 18 22:42:06 es-hot2 systemd[1]: Starting Apache Kafka server (broker)...
Jul 18 22:42:07 es-hot2 systemd[1]: Started Apache Kafka server (broker).
kafka ui安装部署
项目地址:https://github.com/provectus/kafka-ui
启动容器
[root@es-master ~]# docker run --name kafka-ui -d -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true -e KAFKA_CLUSTERS_0_NAME="local" -e KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS="192.168.10.133:9092" --restart always provectuslabs/kafka-ui:master
访问验证,查看集群状态

logstash部署
下载地址
官方下载地址:https://www.elastic.co/cn/downloads/logstash
安装
[root@es-warm1 ~]# wget https://artifacts.elastic.co/downloads/logstash/logstash-8.8.2-x86_64.rpm
[root@es-warm1 ~]# rpm -ivh logstash-8.8.2-x86_64.rpm
[root@es-warm1 ~]# systemctl enable logstash
Created symlink /etc/systemd/system/multi-user.target.wants/logstash.service → /usr/lib/systemd/system/logstash.service.
添加环境变量
[root@es-warm1 ~]# vim /etc/profile
export PATH=$PATH:/usr/share/logstash/bin
[root@es-warm1 ~]# source /etc/profile
[root@es-warm1 ~]# logstash -V
Using bundled JDK: /usr/share/logstash/jdk
logstash 8.8.2
修改pipeline文件
Logstash的过滤规则编写思路是:
使用grok正则捕获到log_timestamp和level以及日志内容content字段。
由于content字段内容不是标准json字符,使用mutate插件将单引号替换为双引号,并将level字段值大写转小写。
使用json插件,将替换好的content字符串转码为json对象。
使用geoip插件,根据remote_address字段的ip解析查询地理位置信息。
最后使用mutate插件,移除content字段。
需要注意的是在filter中用到了geoip地址查询插件,需要提前下载ip地理信息数据库,具体可参考文档
https://www.cuiliangblog.cn/detail/section/30956529
[root@es-warm1 ~]# cat > /etc/logstash/conf.d/log-to-es.conf << EOF
input {
kafka {
bootstrap_servers => "es-hot1:9092,es-hot2:9092,es-hot3:9092"
auto_offset_reset => "latest"
consumer_threads => 1
decorate_events => true
topics => ["log_demo"]
codec => "json"
group_id => "logstash"
}
}
filter{
grok{
match => {"message" => "%{TIMESTAMP_ISO8601:log_timestamp} \| %{LOGLEVEL:level} %{SPACE}* \| (?<class>[__main__:[\w]*:\d*]+) \- %{GREEDYDATA:content}"}
}
mutate {
gsub =>[
"content", "'", '"'
]
lowercase => [ "level" ]
}
json {
source => "content"
}
geoip {
source => "remote_address"
database => "/etc/logstash/GeoLite2-City.mmdb"
ecs_compatibility => disabled
}
mutate {
remove_field => ["content"]
}
}
output {
elasticsearch {
hosts => ["https://es-master:9200"]
data_stream => "true"
data_stream_type => "logs"
data_stream_dataset => "myapp"
data_stream_namespace => "default"
timeout => 120
pool_max => 800
validate_after_inactivity => 7000
user => elastic
password => "_21FDs+tGRRSaxg=q=4P"
ssl => true
cacert => "/etc/logstash/http_ca.crt"
}
}
EOF
拷贝CA证书
Logstash连接es时需要指定ca证书,从master节点拷贝证书至Logstash机器上。
[root@es-warm1 ~]# scp es-master:/etc/elasticsearch/certs/http_ca.crt /etc/logstash/http_ca.crt
[root@es-warm1 ~]# chown logstash:logstash /etc/logstash/http_ca.crt
测试配置文件
使用控制台直接指定pipeline文件方式启动测试,查看日志是否有报错。
[root@es-warm1 ~]# logstash -f /etc/logstash/conf.d/log-to-es.conf
启动logstash
[root@es-warm1 ~]# systemctl start logstash
kibana查看数据
数据流信息
在kibana中查看数据流信息,已自动创建名为logs-myapp-default的数据流

字段内容查看
在discover中点击展开按钮即可查看每条文档的详细字段信息。
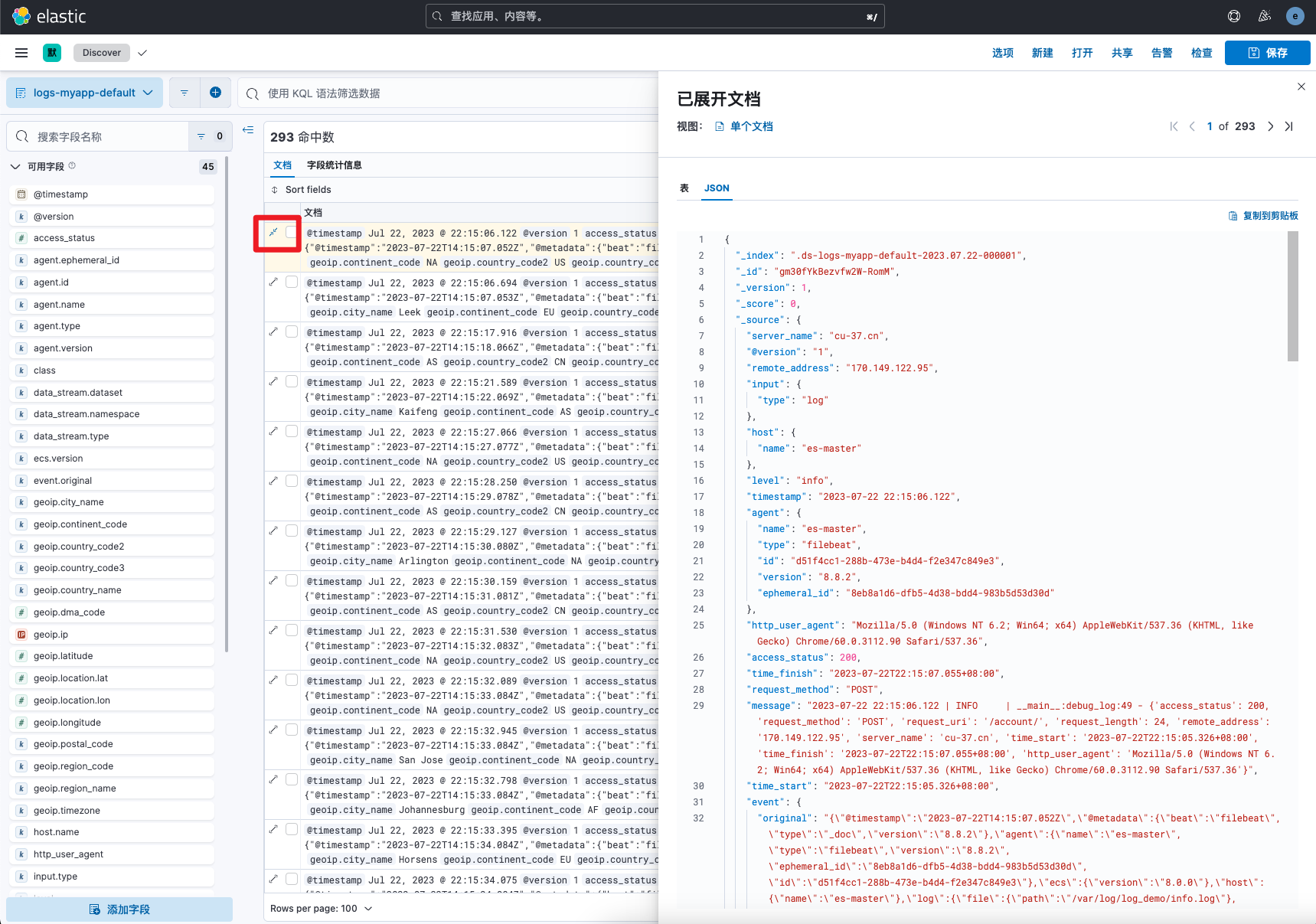
至此,我们顺利的完成了自定义日志从Filebeat采集——>kafka消息缓冲队列——>logstash解析处理数据——>es存储——>kibana数据展示的完整流程。
参考文档
filebeat读取文件配置:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-filestream.html
filebeat输出kafka配置:https://www.elastic.co/guide/en/beats/filebeat/current/kafka-output.html
kafka部署文档:https://kafka.apache.org/documentation/#quickstart
Logstash输入kafka配置:https://www.elastic.co/guide/en/logstash/master/plugins-inputs-kafka.html
Logstash正则匹配插件:https://www.elastic.co/guide/en/logstash/master/plugins-filters-grok.html
Logstash字符处理插件:https://www.elastic.co/guide/en/logstash/master/plugins-filters-mutate.html
Logstash日期处理插件:https://www.elastic.co/guide/en/logstash/current/plugins-filters-date.html
Logstash json转换插件:https://www.elastic.co/guide/en/logstash/master/plugins-filters-json.html
Logstash地理位置插件:https://www.elastic.co/guide/en/logstash/master/plugins-filters-geoip.html
Logstash输出elasticsearch配置:https://www.elastic.co/guide/en/logstash/master/plugins-outputs-elasticsearch.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2019-08-07 nginx配置一般优化参数
2019-08-07 linux系统内核优化参数