

Binlog Load
官方文档地址:https://doris.apache.org/zh-CN/docs/1.2/data-operate/import/import-way/binlog-load-manual/
Binlog Load提供了一种使Doris增量同步用户在Mysql数据库的对数据更新操作的CDC(Change Data Capture)功能。
适用场景
- INSERT/UPDATE/DELETE支持
- 过滤Query
- 暂不兼容DDL语句
基本原理
当前版本设计中,Binlog Load需要依赖canal作为中间媒介,让canal伪造成一个从节点去获取Mysql主节点上的Binlog并解析,再由Doris去获取Canal上解析好的数据,主要涉及Mysql端、Canal端以及Doris端,总体数据流向如下:
+---------------------------------------------+
| Mysql |
+----------------------+----------------------+
| Binlog
+----------------------v----------------------+
| Canal Server |
+-------------------+-----^-------------------+
Get | | Ack
+-------------------|-----|-------------------+
| FE | | |
| +-----------------|-----|----------------+ |
| | Sync Job | | | |
| | +------------v-----+-----------+ | |
| | | Canal Client | | |
| | | +-----------------------+ | | |
| | | | Receiver | | | |
| | | +-----------------------+ | | |
| | | +-----------------------+ | | |
| | | | Consumer | | | |
| | | +-----------------------+ | | |
| | +------------------------------+ | |
| +----+---------------+--------------+----+ |
| | | | |
| +----v-----+ +-----v----+ +-----v----+ |
| | Channel1 | | Channel2 | | Channel3 | |
| | [Table1] | | [Table2] | | [Table3] | |
| +----+-----+ +-----+----+ +-----+----+ |
| | | | |
| +--|-------+ +---|------+ +---|------+|
| +---v------+| +----v-----+| +----v-----+||
| +----------+|+ +----------+|+ +----------+|+|
| | Task |+ | Task |+ | Task |+ |
| +----------+ +----------+ +----------+ |
+----------------------+----------------------+
| | |
+----v-----------------v------------------v---+
| Coordinator |
| BE |
+----+-----------------+------------------+---+
| | |
+----v---+ +---v----+ +----v---+
| BE | | BE | | BE |
+--------+ +--------+ +--------+
如上图,用户向FE提交一个数据同步作业。
FE会为每个数据同步作业启动一个canal client,来向canal server端订阅并获取数据。
client中的receiver将负责通过Get命令接收数据,每获取到一个数据batch,都会由consumer根据对应表分发到不同的channel,每个channel都会为此数据batch产生一个发送数据的子任务Task。
在FE上,一个Task是channel向BE发送数据的子任务,里面包含分发到当前channel的同一个batch的数据。
channel控制着单个表事务的开始、提交、终止。一个事务周期内,一般会从consumer获取到多个batch的数据,因此会产生多个向BE发送数据的子任务Task,在提交事务成功前,这些Task不会实际生效。
满足一定条件时(比如超过一定时间、达到提交最大数据大小),consumer将会阻塞并通知各个channel提交事务。
当且仅当所有channel都提交成功,才会通过Ack命令通知canal并继续获取并消费数据。
如果有任意channel提交失败,将会重新从上一次消费成功的位置获取数据并再次提交(已提交成功的channel不会再次提交以保证幂等性)。
整个数据同步作业中,FE通过以上流程不断的从canal获取数据并提交到BE,来完成数据同步。
配置Mysql端
在Mysql Cluster模式的主从同步中,二进制日志文件(Binlog)记录了主节点上的所有数据变化,数据在Cluster的多个节点间同步、备份都要通过Binlog日志进行,从而提高集群的可用性。架构通常由一个主节点(负责写)和一个或多个从节点(负责读)构成,所有在主节点上发生的数据变更将会复制给从节点。
注意:目前必须要使用Mysql 5.7及以上的版本才能支持Binlog Load功能。
要打开mysql的二进制binlog日志功能,则需要编辑my.cnf配置文件设置一下。
[mysqld]
log-bin = mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
Mysql端说明
在Mysql上,Binlog命名格式为mysql-bin.000001、mysql-bin.000002... ,满足一定条件时mysql会去自动切分Binlog日志:
- mysql重启了
- 客户端输入命令flush logs
- binlog文件大小超过1G
要定位Binlog的最新的消费位置,可以通过binlog文件名和position(偏移量)。
例如,各个从节点上会保存当前消费到的binlog位置,方便随时断开连接、重新连接和继续消费。
--------------------- ------------------
| Slave | read | Master |
| FileName/Position | <<<--------------------------- | Binlog Files |
--------------------- ------------------
对于主节点来说,它只负责写入Binlog,多个从节点可以同时连接到一台主节点上,消费Binlog日志的不同部分,互相之间不会影响。
Binlog日志支持两种主要格式(此外还有混合模式mixed-based):
statement-based格式: Binlog只保存主节点上执行的sql语句,从节点将其复制到本地重新执行
row-based格式: Binlog会记录主节点的每一行所有列的数据的变更信息,从节点会复制并执行每一行的变更到本地
第一种格式只写入了执行的sql语句,虽然日志量会很少,但是有下列缺点
- 没有保存每一行实际的数据
- 在主节点上执行的UDF、随机、时间函数会在从节点上结果不一致
- limit语句执行顺序可能不一致
因此我们需要选择第二种格式,才能从Binlog日志中解析出每一行数据。
在row-based格式下,Binlog会记录每一条binlog event的时间戳,server id,偏移量等信息,如下面一条带有两条insert语句的事务:
begin;
insert into canal_test.test_tbl values (3, 300);
insert into canal_test.test_tbl values (4, 400);
commit;
对应将会有四条binlog event,其中一条begin event,两条insert event,一条commit event:
SET TIMESTAMP=1538238301/*!*/;
BEGIN
/*!*/.
# at 211935643
# at 211935698
#180930 0:25:01 server id 1 end_log_pos 211935698 Table_map: 'canal_test'.'test_tbl' mapped to number 25
#180930 0:25:01 server id 1 end_log_pos 211935744 Write_rows: table-id 25 flags: STMT_END_F
...
'/*!*/;
### INSERT INTO canal_test.test_tbl
### SET
### @1=1
### @2=100
# at 211935744
#180930 0:25:01 server id 1 end_log_pos 211935771 Xid = 2681726641
...
'/*!*/;
### INSERT INTO canal_test.test_tbl
### SET
### @1=2
### @2=200
# at 211935771
#180930 0:25:01 server id 1 end_log_pos 211939510 Xid = 2681726641
COMMIT/*!*/;
如上图所示,每条Insert event中包含了修改的数据。在进行Delete/Update操作时,一条event还能包含多行数据,使得Binlog日志更加的紧密。
开启GTID模式 [可选]
一个全局事务Id(global transaction identifier)标识出了一个曾在主节点上提交过的事务,在全局都是唯一有效的。开启了Binlog后,GTID会被写入到Binlog文件中,与事务一一对应。
要打开mysql的GTID模式,则需要编辑my.cnf配置文件设置一下
gtid-mode=on // 开启gtid模式
enforce-gtid-consistency=1 // 强制gtid和事务的一致性
在GTID模式下,主服务器可以不需要Binlog的文件名和偏移量,就能很方便的追踪事务、恢复数据、复制副本。
在GTID模式下,由于GTID的全局有效性,从节点将不再需要通过保存文件名和偏移量来定位主节点上的Binlog位置,而通过数据本身就可以定位了。在进行数据同步中,从节点会跳过执行任意被识别为已执行的GTID事务。
GTID的表现形式为一对坐标, source_id标识出主节点,transaction_id表示此事务在主节点上执行的顺序(最大263-1)。
GTID = source_id:transaction_id
例如,在同一主节点上执行的第23个事务的gtid为
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
配置Canal端
canal是属于阿里巴巴otter项目下的一个子项目,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,用于解决跨机房同步的业务场景,建议使用canal 1.1.5及以上版本,下载地址,下载完成后,请按以下步骤完成部署。
-
解压canal deployer
-
在conf文件夹下新建目录并重命名,作为instance的根目录,目录名即后文提到的destination
-
修改instance配置文件(可拷贝conf/example/instance.properties)
vim conf/{your destination}/instance.properties
## canal instance serverId
canal.instance.mysql.slaveId = 1234
## mysql adress
canal.instance.master.address = 127.0.0.1:3306
## mysql username/password
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
启动
sh bin/startup.sh
验证启动成功
cat logs/{your destination}/{your destination}.log
2013-02-05 22:50:45.636 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
2013-02-05 22:50:45.641 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [xxx/instance.properties]
2013-02-05 22:50:45.803 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-xxx
2013-02-05 22:50:45.810 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start successful....
Canal端说明
canal通过伪造自己的mysql dump协议,去伪装成一个从节点,获取主节点的Binlog日志并解析。
canal server上可启动多个instance,一个instance可看作一个从节点,每个instance由下面几个部分组成:
-------------------------------------------------
| Server |
| -------------------------------------------- |
| | Instance 1 | |
| | ----------- ----------- ----------- | |
| | | Parser | | Sink | | Store | | |
| | ----------- ----------- ----------- | |
| | ----------------------------------- | |
| | | MetaManager | | |
| | ----------------------------------- | |
| -------------------------------------------- |
-------------------------------------------------
- parser:数据源接入,模拟slave协议和master进行交互,协议解析
- sink:parser和store链接器,进行数据过滤,加工,分发的工作
- store:数据存储
- meta manager:元数据管理模块
每个instance都有自己在cluster内的唯一标识,即server Id。
在canal server内,instance用字符串表示,此唯一字符串被记为destination,canal client需要通过destination连接到对应的instance。
注意:canal client和canal instance是一一对应的,Binlog Load已限制多个数据同步作业不能连接到同一个destination。
数据在instance内的流向是binlog -> parser -> sink -> store。
instance通过parser模块解析binlog日志,解析出来的数据缓存在store里面,当用户向FE提交一个数据同步作业时,会启动一个canal client订阅并获取对应instance中的store内的数据。
store实际上是一个环形的队列,用户可以自行配置它的长度和存储空间。
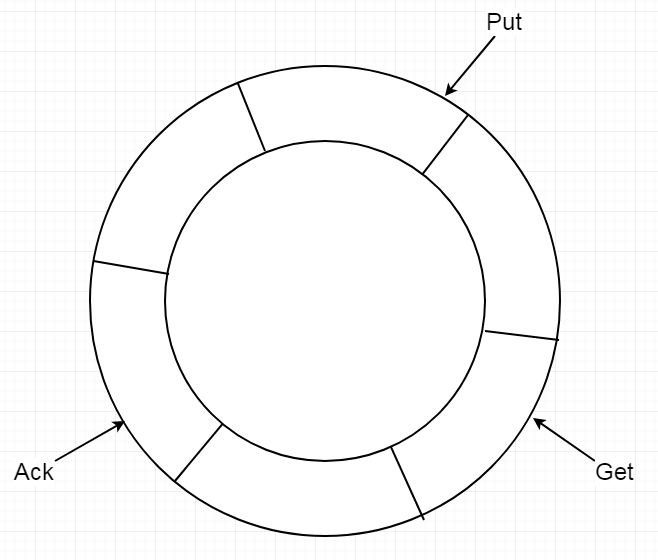
store通过三个指针去管理队列内的数据:
- get指针:get指针代表客户端最后获取到的位置。
- ack指针:ack指针记录着最后消费成功的位置。
- put指针:代表sink模块最后写入store成功的位置。
canal client异步获取store中数据
get 0 get 1 get 2 put
| | | ...... |
v v v v
--------------------------------------------------------------------- store环形队列
^ ^
| |
ack 0 ack 1
canal client调用get命令时,canal server会产生数据batch发送给client,并右移get指针,client可以获取多个batch,直到get指针赶上put指针为止。
当消费数据成功时,client会返回ack + batch Id通知已消费成功了,并右移ack指针,store会从队列中删除此batch的数据,腾出空间来从上游sink模块获取数据,并右移put指针。
当数据消费失败时,client会返回rollback通知消费失败,store会将get指针重置左移到ack指针位置,使下一次client获取的数据能再次从ack指针处开始。
和Mysql中的从节点一样,canal也需要去保存client最新消费到的位置。canal中所有元数据(如GTID、Binlog位置)都是由MetaManager去管理的,目前元数据默认以json格式持久化在instance根目录下的meta.dat文件内
基本操作
配置目标表属性
用户需要先在Doris端创建好与Mysql端对应的目标表
Binlog Load只能支持Unique类型的目标表,且必须激活目标表的Batch Delete功能。
开启Batch Delete的方法可以参考ALTER TABLE PROPERTY中的批量删除功能。
示例:
--create Mysql table
CREATE TABLE `demo.source_test` (
`id` int(11) NOT NULL COMMENT "",
`name` int(11) NOT NULL COMMENT ""
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- create Doris table
CREATE TABLE `target_test` (
`id` int(11) NOT NULL COMMENT "",
`name` int(11) NOT NULL COMMENT ""
) ENGINE=OLAP
UNIQUE KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`) BUCKETS 8;
-- enable batch delete
ALTER TABLE target_test ENABLE FEATURE "BATCH_DELETE";
!!Doris表结构和Mysql表结构字段顺序必须保持一致!!
创建同步作业
CREATE SYNC `demo`.`job`
(
FROM `demo`.`source_test1` INTO `target_test`
(id,name)
)
FROM BINLOG
(
"type" = "canal",
"canal.server.ip" = "127.0.0.1",
"canal.server.port" = "11111",
"canal.destination" = "xxx",
"canal.username" = "canal",
"canal.password" = "canal"
);
创建数据同步作业的详细语法可以连接到 Doris 后,CREATE SYNC JOB 查看语法帮助。这里主要详细介绍,创建作业时的注意事项。
语法:
CREATE SYNC [db.]job_name
(
channel_desc,
channel_desc
...
)
binlog_desc
-
job_name
job_name是数据同步作业在当前数据库内的唯一标识,相同job_name的作业只能有一个在运行。 -
channel_desc
channel_desc用来定义任务下的数据通道,可表示mysql源表到doris目标表的映射关系。在设置此项时,如果存在多个映射关系,必须满足mysql源表应该与doris目标表是一一对应关系,其他的任何映射关系(如一对多关系),检查语法时都被视为不合法。 -
column_mapping
column_mapping主要指mysql源表和doris目标表的列之间的映射关系,如果不指定,FE会默认源表和目标表的列按顺序一一对应。但是我们依然建议显式的指定列的映射关系,这样当目标表的结构发生变化(比如增加一个 nullable 的列),数据同步作业依然可以进行。否则,当发生上述变动后,因为列映射关系不再一一对应,导入将报错。 -
binlog_desc
binlog_desc中的属性定义了对接远端Binlog地址的一些必要信息,目前可支持的对接类型只有canal方式,所有的配置项前都需要加上canal前缀。canal.server.ip: canal server的地址canal.server.port: canal server的端口canal.destination: 前文提到的instance的字符串标识canal.batchSize: 每批从canal server处获取的batch大小的最大值,默认8192canal.username: instance的用户名canal.password: instance的密码canal.debug: 设置为true时,会将batch和每一行数据的详细信息都打印出来,会影响性能。
查看作业状态
查看作业状态的具体命令和示例可以通过 SHOW SYNC JOB 命令查看。
返回结果集的参数意义如下:
-
State
作业当前所处的阶段。作业状态之间的转换如下图所示:
+-------------+ create job | PENDING | resume job +-----------+ <-------------+ | +-------------+ | +----v-------+ +-------+----+ | RUNNING | pause job | PAUSED | | +-----------------------> | +----+-------+ run error +-------+----+ | +-------------+ | | | CANCELLED | | +-----------> <-------------+ stop job +-------------+ stop job system error -
作业提交之后状态为PENDING,由FE调度执行启动canal client后状态变成RUNNING,用户可以通过 STOP/PAUSE/RESUME 三个命令来控制作业的停止,暂停和恢复,操作后作业状态分别为CANCELLED/PAUSED/RUNNING。
作业的最终阶段只有一个CANCELLED,当作业状态变为CANCELLED后,将无法再次恢复。当作业发生了错误时,若错误是不可恢复的,状态会变成CANCELLED,否则会变成PAUSED。
-
Channel
作业所有源表到目标表的映射关系。
-
Status
当前binlog的消费位置(若设置了GTID模式,会显示GTID),以及doris端执行时间相比mysql端的延迟时间。
-
JobConfig
对接的远端服务器信息,如canal server的地址与连接instance的destination
控制作业
用户可以通过 STOP/PAUSE/RESUME 三个命令来控制作业的停止,暂停和恢复。可以通过 STOP SYNC JOB ; PAUSE SYNC JOB; 以及 RESUME SYNC JOB;
相关参数
CANAL配置
下面配置属于canal端的配置,主要通过修改 conf 目录下的 canal.properties 调整配置值。
-
canal.ipcanal server的ip地址
-
canal.portcanal server的端口
-
canal.instance.memory.buffer.sizecanal端的store环形队列的队列长度,必须设为2的幂次方,默认长度16384。此值等于canal端能缓存event数量的最大值,也直接决定了Doris端一个事务内所能容纳的最大event数量。建议将它改的足够大,防止Doris端一个事务内能容纳的数据量上限太小,导致提交事务太过频繁造成数据的版本堆积。
-
canal.instance.memory.buffer.memunitcanal端默认一个event所占的空间,默认空间为1024 bytes。此值乘上store环形队列的队列长度等于store的空间最大值,比如store队列长度为16384,则store的空间为16MB。但是,一个event的实际大小并不等于此值,而是由这个event内有多少行数据和每行数据的长度决定的,比如一张只有两列的表的insert event只有30字节,但delete event可能达到数千字节,这是因为通常delete event的行数比insert event多。
FE配置
下面配置属于数据同步作业的系统级别配置,主要通过修改 fe.conf 来调整配置值。
-
sync_commit_interval_second提交事务的最大时间间隔。若超过了这个时间channel中还有数据没有提交,consumer会通知channel提交事务。
-
min_sync_commit_size提交事务需满足的最小event数量。若Fe接收到的event数量小于它,会继续等待下一批数据直到时间超过了`sync_commit_interval_second `为止。默认值是10000个events,如果你想修改此配置,请确保此值小于canal端的`canal.instance.memory.buffer.size`配置(默认16384),否则在ack前Fe会尝试获取比store队列长度更多的event,导致store队列阻塞至超时为止。 -
min_bytes_sync_commit提交事务需满足的最小数据大小。若Fe接收到的数据大小小于它,会继续等待下一批数据直到时间超过了
sync_commit_interval_second为止。默认值是15MB,如果你想修改此配置,请确保此值小于canal端的canal.instance.memory.buffer.size和canal.instance.memory.buffer.memunit的乘积(默认16MB),否则在ack前Fe会尝试获取比store空间更大的数据,导致store队列阻塞至超时为止。 -
max_bytes_sync_commit提交事务时的数据大小的最大值。若Fe接收到的数据大小大于它,会立即提交事务并发送已积累的数据。默认值是64MB,如果你想修改此配置,请确保此值大于canal端的
canal.instance.memory.buffer.size和canal.instance.memory.buffer.memunit的乘积(默认16MB)和min_bytes_sync_commit。 -
max_sync_task_threads_num数据同步作业线程池中的最大线程数量。此线程池整个FE中只有一个,用于处理FE中所有数据同步作业向BE发送数据的任务task,线程池的实现在
SyncTaskPool类。
常见问题
-
修改表结构是否会影响数据同步作业?
会影响。数据同步作业并不能禁止
alter table的操作,当表结构发生了变化,如果列的映射无法匹配,可能导致作业发生错误暂停,建议通过在数据同步作业中显式指定列映射关系,或者通过增加 Nullable 列或带 Default 值的列来减少这类问题。 -
删除了数据库后数据同步作业还会继续运行吗?
不会。删除数据库后的几秒日志中可能会出现找不到元数据的错误,之后该数据同步作业会被FE的定时调度检查时停止。
-
多个数据同步作业可以配置相同的
ip:port + destination吗?不能。创建数据同步作业时会检查
ip:port + destination与已存在的作业是否重复,防止出现多个作业连接到同一个instance的情况。 -
为什么数据同步时浮点类型的数据精度在Mysql端和Doris端不一样?
Doris本身浮点类型的精度与Mysql不一样。可以选择用Decimal类型代替
更多帮助
关于 Binlog Load 使用的更多详细语法及最佳实践,请参阅 Binlog Load 命令手册,你也可以在 MySql 客户端命令行下输入 HELP BINLOG 获取更多帮助信息。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)