

网络
Flannel
Docker 的网络模式可以解决一个节点上的容器之间的网络通信问题,但是对于跨主机的容器之间的通信就无能为力了,就需要借助第三方的工具来实现容器的跨主机通信。为解决容器跨主机通信问题,社区出现了很多种网络解决方案,不同的方案工作原理各有不同,对于网络环境的要求也各有不同,我们这里以使用最多的 Flannel 这个网络插件为例,来给大家讲解该经典网络插件的工作原理。
Flannel 是 CoreOS(Etcd 的公司)推出的一个 Overlay 类型的容器网络插件,目前支持三种后端实现:UDP、VXLAN、host-gw 三种方式。UDP 是最开始支持的最简单的但是却是性能最差的一种方式,因此基本上在正式使用的时候不会使用这种方式,不过该方式由于非常简单所有可以有助于我们来理解容器跨主机网络通信的实现原理,所以我们先来和大家了解下 UDP 方式的实现方式。
UDP 方式
UDP 模式需要在 Flannel 的配置文件中指定 Backend type 为 UDP,可以直接修改 Flannel 的方式实现:
$ kubectl edit cm kube-flannel-cfg -n kube-system
apiVersion: v1
data:
cni-conf.json: |
{
"cniVersion": "0.2.0",
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "udp" # 修改后端类型为 UDP
}
}
kind: ConfigMap
......
需要将 Backend 的类型更改为 udp,采用 UDP 模式时后端默认为端口为 8285,即 Flanneld 的监听端口。当采用 UDP 模式时,Flanneld 进程在启动时会通过打开 /dev/net/tun 的方式生成一个 TUN 设备,TUN 设备可以简单理解为 Linux 当中提供的一种内核网络与用户空间通信的一种机制,即应用可以通过直接读写 TUN 设备的方式收发 RAW IP 包。所以我们还需要将宿主机的 /dev/net/tun 文件挂载到容器中去:
$ kubectl edit ds kube-flannel-ds-amd64 -n kube-system
......
volumeMounts:
- mountPath: /run/flannel
name: run
- mountPath: /etc/kube-flannel/
name: flannel-cfg
- mountPath: /dev/net
name: tun
......
volumes:
- hostPath:
path: /run/flannel
type: ""
name: run
- hostPath:
path: /etc/cni/net.d
type: ""
name: cni
- hostPath:
path: /dev/net # 挂载宿主机的 /dev/net/tun 文件
type: ""
name: tun
......
然后 Flanneld 的 Pod 会自动重建,重建完成后,可以随便查看一个 Pod 的日志:
$ kubectl logs -f kube-flannel-ds-amd64-5bk4dmd64 -n kube-system
I1128 08:26:49.663566 1 main.go:527] Using interface with name eth0 and address 10.151.30.11
I1128 08:26:49.663838 1 main.go:544] Defaulting external address to interface address (10.151.30.11)
I1128 08:26:49.857634 1 kube.go:126] Waiting 10m0s for node controller to sync
I1128 08:26:49.857805 1 kube.go:309] Starting kube subnet manager
I1128 08:26:50.858137 1 kube.go:133] Node controller sync successful
I1128 08:26:50.858324 1 main.go:244] Created subnet manager: Kubernetes Subnet Manager - ydzs-master
I1128 08:26:50.858357 1 main.go:247] Installing signal handlers
I1128 08:26:50.858933 1 main.go:386] Found network config - Backend type: udp
I1128 08:26:51.089114 1 main.go:317] Wrote subnet file to /run/flannel/subnet.env
I1128 08:26:51.089177 1 main.go:321] Running backend.
I1128 08:26:51.089227 1 main.go:339] Waiting for all goroutines to exit
I1128 08:26:51.089280 1 udp_network_amd64.go:100] Watching for new subnet leases
I1128 08:26:51.089350 1 udp_network_amd64.go:195] Subnet added: 10.244.4.0/24
I1128 08:26:51.089443 1 udp_network_amd64.go:195] Subnet added: 10.244.1.0/24
I1128 08:26:51.089487 1 udp_network_amd64.go:195] Subnet added: 10.244.2.0/24
I1128 08:26:51.089518 1 udp_network_amd64.go:195] Subnet added: 10.244.3.0/24
I1128 08:27:01.936553 1 udp_network_amd64.go:195] Subnet added: 10.244.3.0/24
I1128 08:27:03.341176 1 udp_network_amd64.go:195] Subnet added: 10.244.4.0/24
I1128 08:27:04.136280 1 udp_network_amd64.go:195] Subnet added: 10.244.2.0/24
I1128 08:27:07.863379 1 udp_network_amd64.go:195] Subnet added: 10.244.1.0/24
看到Found network config - Backend type: udp这个信息证明我们现在已经变成了 UDP 模式了。
Flanneld 进程启动后通过 ip a 命令可以发现节点当中已经多了一个叫 flannel0 的网络设备:
$ ip -d link show flannel0
210: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN mode DEFAULT group default qlen 500
link/none promiscuity 0
tun addrgenmode random numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
由于是 UDP 的服务,所以我们需要通过 netstat -ulnp 命令查看进程:
$ netstat -ulnp | grep flanneld
udp 0 0 10.151.30.11:8285 0.0.0.0:* 24844/flanneld
现在我们有两个 Pod,分别在节点 ydzs-node1 和节点 ydzs-node2 上面,现在让 pod-a(10.244.1.236)向 pod-b(10.244.2.123)发送一个请求报文(ping),我们来分析以下报文是如何从 pod-a 到达 pod-b 的:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-a 1/1 Running 0 73s 10.244.1.236 ydzs-node1 <none> <none>
pod-b 1/1 Running 0 38s 10.244.2.123 ydzs-node2 <none> <none>
1、在 pod-a 当中发出 ICMP 请求报文,其源地址就是 10.244.1.236,目标地址是 10.244.2.123,此时通过 pod-a 内的路由表匹配到应该将该 IP 包发送到 ydzs-node1 节点上网关 10.244.1.1(cni0网桥)。
$ kubectl exec pod-a -- route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.1.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.1.1 255.255.0.0 UG 0 0 0 eth0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
在 ydzs-node1 节点上可以查看到 pod-a 中的网关 10.244.1.1 就是节点上的 cni0 网桥:
[root@ydzs-node1 ~]# ifconfig -a
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::64c2:65ff:fe15:3669 prefixlen 64 scopeid 0x20<link>
ether f6:f9:99:71:81:a2 txqueuelen 1000 (Ethernet)
RX packets 33385207 bytes 24883992070 (23.1 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 31653673 bytes 19703556786 (18.3 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
......
2、这个时候,IP 包的下一个目的地,就取决于宿主机上面的路由规则了,Flanneld 进程已经在宿主机上面创建了一系列的路由规则,比如当前的 ydzs-node1 节点:
[root@ydzs-node1 ~]# ip route
default via 10.151.30.11 dev eth0 proto static metric 100
10.151.30.0/24 dev eth0 proto kernel scope link src 10.151.30.22 metric 100
10.244.0.0/16 dev flannel0
10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
此时到达 cni0 的 IP 包目标地址 10.244.2.123 匹配不到本机的 cni0 网桥对应的 10.244.1.0/24 网段,只能匹配到第三条 10.244.0.0/16 对应的这条路由规则,这个时候内核将 RAW IP 包发送给 flannel0 设备。
flannel0 设备它是一个 TUN 设备(Tunnel 设备)。在 Linux 中,TUN 设备是一种工作在三层(Network Layer)的虚拟网络设备,TUN 设备的功能非常简单,即:在操作系统内核和用户应用程序之间传递 IP 包。
3、由于 flannel0 是一个 TUN 设备,发送给 flannel0 接口的 RAW IP 包将被 Flanneld 进程接收到,然后在原有的基础上进行 UDP 封包,然后发送到 ydzs-node2 节点上的 Flanneld 进行解包。
UDP 封包的形式为:10.151.30.22:src port -> 10.151.30.23:8285。
这里最关键的就是 UDP 封包发送到我们的目标 IP 10.244.2.123 这个容器所在的节点,但是是如何知道这个节点的呢?
这个就需要了解一个非常重要的概念子网(Subnet),Flannel 管理的容器网络,一台宿主机上的所有容器,都属于该宿主机被分配的一个子网,比如我们这里的 ydzs-node1 节点的子网是 10.244.1.0/24(10.244.1.1-10.244.1.254),pod-a 的 IP 地址是 10.244.1.236;ydzs-node2 节点的子网是 10.244.2.0/24(10.244.2.1-10.244.2.254),pod-b 的 IP 地址是 10.244.2.123,这些子网信息是当 Flanneld 进程在启动时通过 api-server 保存到 etcd 当中,所以在发送报文时可以通过目的地址 10.244.2.123 匹配到对应的子网是 10.244.2.0/24,这个时候查询 etcd 得到这个子网对应的宿主机的 IP 地址 10.151.30.23,也就是 ydzs-node2 节点。
4、ydzs-node2 节点收到 UDP 报文过后经过 Linux 内核通过 UDP 端口 8285 将包交给节点上的 Flanneld 进程。
5、然后 ydzs-node2 节点上的 Flanneld 进程将接收到的 UDP 包解包后得到 RAW IP 包:10.244.1.236 -> 10.244.2.123。
6、解包后的 RAW IP 包匹配到 ydzs-node2 节点上的路由规则(10.244.2.0/24),内核将 RAW IP 包发送给 cni0 设备
[root@ydzs-node2 ~]# ip route
default via 10.151.30.11 dev eth0 proto static metric 100
10.151.30.0/24 dev eth0 proto kernel scope link src 10.151.30.23 metric 100
10.244.0.0/16 dev flannel0
10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
7、cni0 将 IP 包转发给连接在 cni0 网桥上的 pod-b,这样就完成了这个通信过程:
$ kubectl exec pod-a ping 10.244.2.123
PING 10.244.2.123 (10.244.2.123): 56 data bytes
64 bytes from 10.244.2.123: seq=0 ttl=62 time=1.452 ms
64 bytes from 10.244.2.123: seq=1 ttl=62 time=1.160 ms
64 bytes from 10.244.2.123: seq=2 ttl=62 time=0.853 ms
上面就是基于 Flannel UDP 模式的跨主通信的基本流程了,从上面的整个流程来看,Flanneld 主要有两方面的功能:
- UDP 封包解包
- 节点上的路由表的动态更新
我们可以明显看出来数据包是通过 tun 设备从内核态复制到用户态的应用中的,然后再通过用户态复制到内核态,仅一次网络传输就进行了两次用户态和内核态的切换,显然这种效率是不会很高的,由于低效率所以这种方式基本上不是呀,要提高效率最简单的方式就是把封包解包这些事情都交给内核去干好了,事实上 Linux 内核本身也提供了比较成熟的网络封包解包(隧道传输)实现方案 VXLAN,Flanneld 也实现了基于 VXLAN 的方案,该方案在我们日常使用的时候也是最普遍的。
VXLAN 方式
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。所以说,VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
同样的当我们使用 VXLAN 模式的时候需要将 Flanneld 的 Backend 类型修改为 vxlan:
$ kubectl edit cm kube-flannel-cfg -n kube-system
apiVersion: v1
data:
cni-conf.json: |
{
"cniVersion": "0.2.0",
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan" # 修改后端类型为 vxlan
}
}
kind: ConfigMap
......
将类型修改为 vxlan 过后,需要重建下 Flanneld 的所有 Pod 才能生效:
$ kubectl delete pod -n kube-system -l app=flannel
重建完成后同样可以随便查看一个 Pod 的日志,出现如下Found network config - Backend type: vxlan的日志信息就证明已经配置成功了:
$ kubectl logs -f kube-flannel-ds-amd64-pfb8h -n kube-system
I1129 03:33:56.588549 1 main.go:527] Using interface with name eth0 and address 10.151.30.23
I1129 03:33:56.588893 1 main.go:544] Defaulting external address to interface address (10.151.30.23)
I1129 03:33:56.698562 1 kube.go:126] Waiting 10m0s for node controller to sync
I1129 03:33:56.698726 1 kube.go:309] Starting kube subnet manager
I1129 03:33:57.698910 1 kube.go:133] Node controller sync successful
I1129 03:33:57.698980 1 main.go:244] Created subnet manager: Kubernetes Subnet Manager - ydzs-node2
I1129 03:33:57.699000 1 main.go:247] Installing signal handlers
I1129 03:33:57.699375 1 main.go:386] Found network config - Backend type: vxlan
I1129 03:33:57.699553 1 vxlan.go:120] VXLAN config: VNI=1 Port=0 GBP=false DirectRouting=false
I1129 03:33:57.703715 1 main.go:317] Wrote subnet file to /run/flannel/subnet.env
I1129 03:33:57.703785 1 main.go:321] Running backend.
I1129 03:33:57.703825 1 main.go:339] Waiting for all goroutines to exit
I1129 03:33:57.703940 1 vxlan_network.go:60] watching for new subnet leases
Flanneld 在启动时会通过 Netlink 机制与 Linux 内核通信,建立一个 VTEP(Virtual Tunnel Access End Point) 设备 flannel.1(命名规则为flannel.[VNI],VNI 默认为1),类似于交换机当中的一个网口。我们可以通过 ip -d link 命令查看 VTEP 设备 flannel.1 的配置信息:
$ ip -d link show flannel.1
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT
link/ether 72:f7:e9:40:97:1e brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 10.151.30.22 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 addrgenmode eui64
从上面输出可以看到,VTEP 的 local IP 为 10.151.30.22,destination port 为 8472。同样我们也可以在节点上查看进程监听情况:
$ netstat -ulnp | grep 8472
udp 0 0 0.0.0.0:8472 0.0.0.0:* -
我们仔细看和 UDP 模式下查看 Flanneld 监听的端口是有区别的,最后一栏显示的不是进程的 ID 和名称,而是一个破折号“-”,这说明 UDP 的8472端口不是由用户态的进程在监听的,也证实了VXLAN模块工作在内核态模式下。
在 UDP 模式下由 Flanneld 进程进行网络包的封包和解包的工作,而在 VXLAN 模式下解封包的事情交由内核处理,下面我们来看下 Flanneld 后端的具体工具流程。当 Flanneld 启动时将创建 VTEP 设备 flannel.1,并将 VTEP 设备的相关信息上报到 etcd 当中,而当在 Flannel 网络中有新的节点发现时,各个节点上的 Flanneld 进程将依次执行以下流程:
1、在节点当中创建一条该节点所属网段的路由表,主要是能让 Pod 当中的流量路由到 flannel.1 接口。通过route -n可以查看到节点当中已经有四条 flannel.1 接口的路由:
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.151.30.11 0.0.0.0 UG 100 0 0 eth0
10.151.30.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.3.0 10.244.3.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.4.0 10.244.4.0 255.255.255.0 UG 0 0 0 flannel.1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
比如 10.244.2.0 这条路由规则,他的意思就是发往 10.244.2.0/24 网段的 IP 包,都需要经过 flannel.1 设备发出,而且最后被发送到的网关地址是 10.244.2.0。而其实这个网关地址就是 ydzs-node2 节点上的 VTEP 设备(也就是 flannel.1)的 IP 地址:
[root@ydzs-node2 ~]# ifconfig
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::2467:52ff:fe6b:1bf9 prefixlen 64 scopeid 0x20<link>
ether 26:67:52:6b:1b:f9 txqueuelen 0 (Ethernet)
RX packets 42050890 bytes 27691009839 (25.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 36287976 bytes 46894346975 (43.6 GiB)
TX errors 0 dropped 163 overruns 0 carrier 0 collisions 0
......
2、上面知道了目的 VTEP 设备的 IP 地址了,这个时候就需要知道目的 MAC 地址,才能把数据包发送过去,这个时候其实 Flanneld 进程就会在节点当中维护所有节点的 IP 以及 VTEP 设备的静态 ARP 缓存。可通过 arp -n 命令查看到当前节点当中已经缓存了另外四个节点以及 VTEP 的 ARP 信息。
$ arp -n
Address HWtype HWaddress Flags Mask Iface
10.244.3.0 ether 32:f1:e0:a9:97:ab CM flannel.1
10.244.2.0 ether 26:67:52:6b:1b:f9 CM flannel.1
10.244.0.0 ether 0a:24:5e:40:ff:da CM flannel.1
10.244.4.0 ether 4a:09:1f:42:ed:c1 CM flannel.1
......
这里我们可以看到 IP 地址 10.244.2.0 对应的 MAC 地址是 26:67:52:6b:1b:f9,这样我们就知道了目的 VTEP 设备的 MAC 地址。但是现在我们只是知道了目标设备的 MAC 地址,却不知道对应的宿主机的地址是什么?
3、这个时候 Flanneld 进程还会在节点当中添加一条该节点的转发表,通过 bridge 命令查看节点上的 VXLAN 转发表(FDB entry),MAC 为 VTEP 设备即 flannel.1 的 MAC 地址,IP 为 VTEP 对应的对外 IP(可通过 Flanneld 的启动参数 --iface=eth0 指定,若不指定则按默认网关查找网络接口对应的 IP),可以看到已经有四条转发表。
$ bridge fdb show dev flannel.1
32:f1:e0:a9:97:ab dst 10.151.30.57 self permanent
26:67:52:6b:1b:f9 dst 10.151.30.23 self permanent
4a:09:1f:42:ed:c1 dst 10.151.30.59 self permanent
0a:24:5e:40:ff:da dst 10.151.30.11 self permanent
这样我们就找到了上面目的 VTEP 设备的 MAC 地址对应的 IP 地址为 10.151.30.23 的主机,这就是我们的 ydzs-node2 节点,所以我们就找到了要发往的目的地址。
这个时候容器跨节点网络通信实现的完整流程为:
- 和 UDP 模式一样,pod-a(10.244.1.236)当中的 IP 包通过 pod-a 内的路由表被发送到 cni0
- 到达 cni0 当中的 IP 包通过匹配节点 ydzs-node1 当中的路由表发现通往 10.244.2.13 的 IP 包应该交给 flannel.1 接口
- flannel.1 作为一个 VTEP 设备,收到报文后将按照 VTEP 的配置进行封包,通过 ydzs-node1 节点上的 arp 和转发表得知 10.244.2.123 属于节点 ydzs-node2,并且会将 ydzs-node2 节点对应的 VTEP 设备的 MAC 地址,根据 flannel.1 设备创建时的设置的参数(VNI、local IP、Port)进行 VXLAN 封包
- 通过节点 ydzs-node2 跟 ydzs-node1 之间的网络连接,VXLAN 包到达 ydzs-node2 的 eth0 接口
- 通过端口 8472,VXLAN 包被转发给 VTEP 设备 flannel.1 进行解包
- 解封装后的 IP 包匹配节点 ydzs-node2 当中的路由表(10.244.2.0),内核将 IP 包转发给cni0
- cni0将 IP 包转发给连接在 cni0 上的 pod-b
host-gw
host-gw 即 Host Gateway,从名字中就可以想到这种方式是通过把主机当作网关来实现跨节点网络通信的。那么具体如何实现跨节点通信呢?
同理 UDP 模式和 VXLAN 模式,首先将 Backend 中的 type 改为host-gw,这里就不再赘述,更新完成后,随便查看一个 flannel 的 Pod 日志,如果出现如下所示的 Found network config - Backend type: host-gw 日志就证明已经是 host-gw 模式了:
$ kubectl logs -f kube-flannel-ds-amd64-642l6 -n kube-system
I1129 04:53:34.309992 1 main.go:527] Using interface with name eth0 and address 10.151.30.59
I1129 04:53:34.310292 1 main.go:544] Defaulting external address to interface address (10.151.30.59)
I1129 04:53:34.510618 1 kube.go:126] Waiting 10m0s for node controller to sync
I1129 04:53:34.607860 1 kube.go:309] Starting kube subnet manager
I1129 04:53:35.511530 1 kube.go:133] Node controller sync successful
I1129 04:53:35.511624 1 main.go:244] Created subnet manager: Kubernetes Subnet Manager - ydzs-node4
I1129 04:53:35.511646 1 main.go:247] Installing signal handlers
I1129 04:53:35.511899 1 main.go:386] Found network config - Backend type: host-gw
I1129 04:53:35.611040 1 main.go:317] Wrote subnet file to /run/flannel/subnet.env
I1129 04:53:35.611120 1 main.go:321] Running backend.
I1129 04:53:35.611165 1 main.go:339] Waiting for all goroutines to exit
I1129 04:53:35.611280 1 route_network.go:53] Watching for new subnet leases
I1129 04:53:35.611768 1 route_network.go:85] Subnet added: 10.244.0.0/24 via 10.151.30.11
W1129 04:53:35.612268 1 route_network.go:102] Replacing existing route to 10.244.0.0/24 via 10.244.0.0 dev index 6 with 10.244.0.0/24 via 10.151.30.11 dev index 2.
I1129 04:53:35.612705 1 route_network.go:85] Subnet added: 10.244.1.0/24 via 10.151.30.22
W1129 04:53:35.612777 1 route_network.go:88] Ignoring non-host-gw subnet: type=vxlan
I1129 04:53:35.612829 1 route_network.go:85] Subnet added: 10.244.2.0/24 via 10.151.30.23
W1129 04:53:35.612868 1 route_network.go:88] Ignoring non-host-gw subnet: type=vxlan
I1129 04:53:35.612935 1 route_network.go:85] Subnet added: 10.244.3.0/24 via 10.151.30.57
W1129 04:53:35.612995 1 route_network.go:88] Ignoring non-host-gw subnet: type=vxlan
I1129 04:53:35.808989 1 route_network.go:85] Subnet added: 10.244.3.0/24 via 10.151.30.57
W1129 04:53:35.809279 1 route_network.go:102] Replacing existing route to 10.244.3.0/24 via 10.244.3.0 dev index 6 with 10.244.3.0/24 via 10.151.30.57 dev index 2.
I1129 04:53:37.012832 1 route_network.go:85] Subnet added: 10.244.1.0/24 via 10.151.30.22
W1129 04:53:37.013132 1 route_network.go:102] Replacing existing route to 10.244.1.0/24 via 10.244.1.0 dev index 6 with 10.244.1.0/24 via 10.151.30.22 dev index 2.
I1129 04:53:37.713684 1 route_network.go:85] Subnet added: 10.244.2.0/24 via 10.151.30.23
W1129 04:53:37.714022 1 route_network.go:102] Replacing existing route to 10.244.2.0/24 via 10.244.2.0 dev index 6 with 10.244.2.0/24 via 10.151.30.23 dev index 2.
采用 host-gw 模式后 Flanneld 的唯一作用就是负责主机上路由表的动态更新,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址,当然,Flannel 子网和主机的信息,都是保存在 etcd 当中的。Fanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。主要流程如下所示:
1、同 UDP、VXLAN 模式一致,通过容器A 的路由表 IP 包到达cni0
2、到达 cni0 的 IP 包匹配到 ydzs-node1 当中的路由规则(10.244.2.0),并且网关为 10.151.30.23,即节点 ydzs-node2,所以内核将 IP 包发送给节点 ydzs-node2(10.151.30.23):
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.151.30.11 0.0.0.0 UG 100 0 0 eth0
10.151.30.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
10.244.0.0 10.151.30.11 255.255.255.0 UG 0 0 0 eth0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.2.0 10.151.30.23 255.255.255.0 UG 0 0 0 eth0
10.244.3.0 10.151.30.57 255.255.255.0 UG 0 0 0 eth0
10.244.4.0 10.151.30.59 255.255.255.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
3、IP 包通过物理网络到达节点的 ydzs-node2 的 eth0 设备 4、到达 ydzs-node2 节点 eth0 的 IP 包匹配到节点当中的路由表(10.244.2.0/24),IP 包被转发给 cni0 设备 5、cni0 将 IP 包转发给连接在 cni0 上的 pod-b
这样就完成了整个跨主机通信流程,这个流程可能是最简单最容器理解的模式了,而且容器通信的过程还免除了额外的封包和解包带来的性能损耗,所以理论上性能肯定要更好,但是该模式是通过节点上的路由表来实现各个节点之间的跨节点网络通信,那么就得保证两个节点是可以直接路由过去的。按照内核当中的路由规则,网关必须在跟主机当中至少一个 IP 处于同一网段,故造成的结果就是采用host-gw 这种模式的时候,集群中所有的节点必须处于同一个网络当中,这对于集群规模比较大时需要对节点进行网段划分的话会存在一定的局限性,另外一个则是随着集群当中节点规模的增大,Flanneld 需要维护主机上成千上万条路由表的动态更新也是一个不小的压力。
除了 Flannel 之外,Calico 这种网络插件和 Flannel 的 host-gw 模式基本上是一样的,都是在每台书主机上面添加子网和对应的书主机的 IP 地址为网关这样的路由信息,不过,不同于 Flannel 通过 Etcd 和宿主机上的 flanneld 来维护路由信息的做法,Calico 使用 bgp 来自动地在整个集群中分发路由信息。
网络策略 - NetworkPolicy
在 Kubernetes 中要实现容器之间网络的隔离,是通过一个专门的 API 对象 NetworkPolicy(网络策略)来实现的,要让网络策略生效,就需要特定的网络插件支持,目前已经实现了 NetworkPolicy 的网络插件包括 Calico、Weave 和 kube-router 等项目,但是并不包括 Flannel 项目。所以说,如果想要在使用 Flannel 的同时还使用 NetworkPolicy 的话,你就需要再额外安装一个网络插件,比如 Calico 项目,来负责执行 NetworkPolicy。由于我们这里使用的是 Flannel 网络插件,所以首先需要安装 Calico 来负责网络策略。
安装 Calico
首先确定 kube-controller-manager 配置了如下的两个参数:
......
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --cluster-cidr=10.244.0.0/16
......
然后下载需要使用的资源清单文件:
$ curl https://docs.projectcalico.org/v3.10/manifests/canal.yaml -O
如果之前配置的 pod CIDR 就是 10.244.0.0/16 网段,则可以跳过下面的配置,如果不同则可以使用如下方式进行替换:
$ POD_CIDR="<your-pod-cidr>" \
$ sed -i -e "s?10.244.0.0/16?$POD_CIDR?g" canal.yaml
然后直接安装即可:
$ kubectl apply -f canal.yaml
网络策略
默认情况下 Pod 是可以接收来自任何发送方的请求,也可以向任何接收方发送请求。而如果我们要对这个情况作出限制,就必须通过 NetworkPolicy 对象来指定。
如下资源清单文件所示,我们这里定义了一个网络策略资源清单文件:(test-networkpolicy.yaml)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
- ports:
- protocol: TCP
port: 80
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
与所有其他的 Kubernetes 资源对象一样,NetworkPolicy 需要 apiVersion、kind 和 metadata 字段,我们通过 spec.podSelector 字段定义这个 NetworkPolicy 的限制范围,因为 NetworkPolicy 目前只支持定义 ingress 规则,所以这里的 podSelector 本质上是为该策略定义 “目标pod”, 比如我们这里 matchLabels:role=db 表示的就是当前 Namespace 里携带了 role=db 标签的 Pod。而如果你把 podSelector 字段留空:
spec:
podSelector: {}
那么这个 NetworkPolicy 就会作用于当前 Namespace 下的所有 Pod。
然后每个 NetworkPolicy 包含一个 policyTypes 列表,可以是一个 Ingress、Egress 或者都包含,该字段表示给当前策略是否应用于所匹配的 Pod 的入口流量、出口流量或者二者都包含,如果没有指定 policyTypes,则默认情况下表示 Ingress 入口流量,如果配置了任何出口流量规则,则将指定为 Egress。
规则: 一旦 Pod 被 NetworkPolicy 选中,那么这个 Pod 就会进入“拒绝所有”(Deny All)的状态,即这个 Pod 既不允许被外界访问,也不允许对外界发起访问,所以 NetworkPolicy 定义的规则,其实就是“白名单”了。
比如上面示例表示的是该隔离规则只对 default 命名空间下的,携带了 role=db 标签的 Pod 有效。限制的请求类型包括 ingress(流入)和 egress(流出)。
ingress: 每个 NetworkPolicy 包含一个 ingress 规则的白名单列表。其中的规则允许同时匹配 from 和 ports 部分的流量。比如上面示例中我们配置的入口流量规则如下所示:
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
- ports:
- protocol: TCP
port: 80
这里的 ingress 规则中我们定义了 from 和 ports,表示允许流入的白名单和端口,上面我们也说了 Kubernetes 会拒绝任何访问被隔离 Pod 的请求,除非这个请求来自于以下“白名单”里的对象,并且访问的是被隔离 Pod 的 8- 端口。而这个允许流入的白名单中指定了三种并列的情况,分别是:ipBlock、namespaceSelector 和 podSelector:
- default 命名空间下面带有 role=frontend 标签的 Pod
- 带有 project=myproject 标签的 Namespace 下的任何 Pod
- 任何源地址属于 172.17.0.0/16 网段,且不属于 172.17.1.0/24 网段的请求。
egress: 每个 NetworkPolicy 包含一个 egress 规则的白名单列表。每个规则都允许匹配 to 和 port 部分的流量。比如我们这里示例规则的配置:
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
表示 Kubernetes 会拒绝被隔离 Pod 对外发起任何请求,除非请求的目的地址属于 10.0.0.0/24 网段,并且访问的是该网段地址的 5978 端口。
测试
比如现在我们创建一个 Pod,带有 role=db 的 Label 标签:(test-networkpolicy-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: test-networkpolicy
labels:
role: db
spec:
containers:
- name: testnp
image: nginx
直接创建这个 Pod:
$ kubectl apply -f test-networkpolicy-pod.yaml
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-a 1/1 Running 4 4h3m 10.244.1.236 ydzs-node1 <none> <none>
pod-b 1/1 Running 4 4h3m 10.244.2.123 ydzs-node2 <none> <none>
test-networkpolicy 1/1 Running 0 4m49s 10.244.3.2 ydzs-node3 <none> <none>
这个时候我们用一个已经存在的 Pod 来对这个 Pod 发起一个网络请求:
$ kubectl exec pod-a wget 10.244.3.2
Connecting to 10.244.3.2 (10.244.3.2:80)
saving to 'index.html'
index.html 100% |********************************| 612 0:00:00 ETA
'index.html' saved
我们可以看到可以成功请求,这个时候我们来创建上面的 NetworkPolicy 对象:
$ kubectl apply -f test-networkpolicy.yaml
networkpolicy.networking.k8s.io/test-network-policy created
这个时候我们创建了一个网络策略,由于匹配了网络策略的就会拒绝所有的网络请求,需要通过白名单来进行开启请求,由于我们这里的测试 Pod 明显没有在白名单之中,所以就会拒绝网络请求了:
$ kubectl exec pod-a wget 10.244.3.2
Connecting to 10.244.3.2 (10.244.3.2:80)
# 请求会一直 hang 住
这个时候我们可以用 NetworkPolicy 白名单里面匹配的 Pod 来对上面的 Pod 发起网络请求,比如在带有标签 project=myproject 的 Namespace 下面的 Pod 来发起网络请求,或者给 pod-a 加上一个 role=frontend 的标签:
$ kubectl label pod pod-a role=frontend
pod/pod-a labeled
这个时候重新发起一个网络请求可以看到已经可以成功了,因为我们访问的 Pod 进程默认的端口就是 80 端口,是匹配白名单的:
$ kubectl exec pod-a -- wget 10.244.3.2 -O-
Connecting to 10.244.3.2 (10.244.3.2:80)
writing to stdout
- 100% |********************************| 612 0:00:00 ETA
written to stdout
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
我们可以看到已经成功了,Kubernetes 的 NetworkPolicy 实现了访问控制,依赖的底层是依靠网络插件添加 iptables 规则来进行控制的,但是在每个节点上都需要配置大量 iptables 规则,加上不同维度控制的增加,导致运维、排障难度较大,所以如果不是特别需要的场景,最好不要使用了。
表示 Kubernetes 会拒绝被隔离 Pod 对外发起任何请求,除非请求的目的地址属于 10.0.0.0/24 网段,并且访问的是该网段地址的 5978 端口。
Service
用 ReplicaSet 和Deployment 来动态的创建和销毁 Pod,每个 Pod 都有自己的 IP 地址,但是如果 Pod 重建了的话那么他的 IP 很有可能也就变化了。这就会带来一个问题:比如我们有一些后端的 Pod 集合为集群中的其他应用提供 API 服务,如果我们在前端应用中把所有的这些后端的 Pod 的地址都写死,然后以某种方式去访问其中一个 Pod 的服务,这样看上去是可以工作的,对吧?但是如果这个 Pod 挂掉了,然后重新启动起来了,是不是 IP 地址非常有可能就变了,这个时候前端就极大可能访问不到后端的服务了。
遇到这样的问题该怎么解决呢?在没有使用 Kubernetes 之前,我相信可能很多同学都遇到过这样的问题,不一定是 IP 变化的问题,比如我们在部署一个WEB 服务的时候,前端一般部署一个 Nginx 作为服务的入口,然后 Nginx 后面肯定就是挂载的这个服务的大量后端服务,很早以前我们可能是去手动更改Nginx 配置中的 upstream 选项,来动态改变提供服务的数量,到后面出现了一些服务发现的工具,比如 Consul、ZooKeeper 还有我们熟悉的 etcd 等工具,有了这些工具过后我们就可以只需要把我们的服务注册到这些服务发现中心去就可以,然后让这些工具动态的去更新 Nginx 的配置就可以了,我们完全不用去手工的操作了,是不是非常方便。
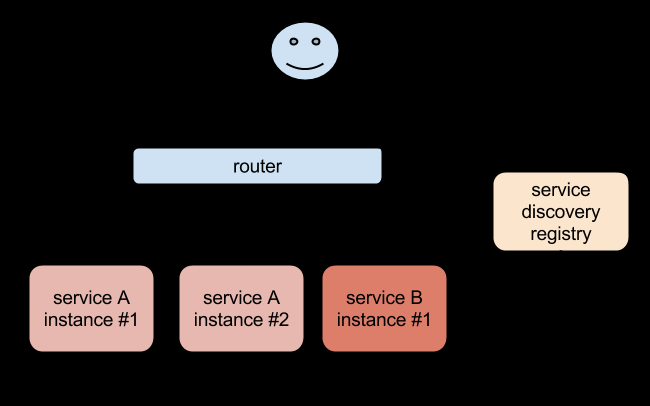
同样的,要解决我们上面遇到的问题是不是实现一个服务发现的工具也可以解决?没错的,当我们 Pod 被销毁或者新建过后,我们可以把这个 Pod 的地址注册到这个服务发现中心去就可以,但是这样的话我们的前端应用就不能直接去连接后台的 Pod 集合了,应该连接到一个能够做服务发现的中间件上面,对吧?
为解决这个问题 Kubernetes 就为我们提供了这样的一个对象 - Service,Service 是一种抽象的对象,它定义了一组 Pod 的逻辑集合和一个用于访问它们的策略,其实这个概念和微服务非常类似。一个 Serivce 下面包含的 Pod 集合是由 Label Selector 来决定的。
比如我们上面的例子,假如我们后端运行了3个副本,这些副本都是可以替代的,因为前端并不关心它们使用的是哪一个后端服务。尽管由于各种原因后端的 Pod 集合会发送变化,但是前端却不需要知道这些变化,也不需要自己用一个列表来记录这些后端的服务,Service 的这种抽象就可以帮我们达到这种解耦的目的。
三种IP
先弄明白 Kubernetes 系统中的三种IP:
- Node IP:Node 节点的 IP 地址
- Pod IP: Pod 的 IP 地址
- Cluster IP: Service 的 IP 地址
首先,Node IP 是 Kubernetes 集群中节点的物理网卡 IP 地址(一般为内网),所有属于这个网络的服务器之间都可以直接通信,所以 Kubernetes 集群外要想访问 Kubernetes 集群内部的某个节点或者服务,肯定得通过 Node IP 进行通信(这个时候一般是通过外网 IP 了)
然后 Pod IP 是每个 Pod 的 IP 地址,它是网络插件进行分配的,前面我们已经讲解过
最后 Cluster IP 是一个虚拟的 IP,仅仅作用于 Kubernetes Service 这个对象,由 Kubernetes 自己来进行管理和分配地址。
定义 Service
定义 Service 的方式和我们前面定义的各种资源对象的方式类型,例如,假定我们有一组 Pod 服务,它们对外暴露了 8080 端口,同时都被打上了 app=myapp 这样的标签,那么我们就可以像下面这样来定义一个 Service 对象:
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 8080
name: myapp-http
然后通过的使用 kubectl create -f myservice.yaml 就可以创建一个名为 myservice 的 Service 对象,它会将请求代理到使用 TCP 端口为 8080,具有标签 app=myapp 的 Pod 上,这个 Service 会被系统分配一个我们上面说的 Cluster IP,该 Service 还会持续的监听 selector 下面的 Pod,会把这些 Pod 信息更新到一个名为 myservice 的Endpoints 对象上去,这个对象就类似于我们上面说的 Pod 集合了。
需要注意的是,Service 能够将一个接收端口映射到任意的 targetPort。默认情况下,targetPort 将被设置为与 port 字段相同的值。可能更有趣的是,targetPort 可以是一个字符串,引用了 backend Pod 的一个端口的名称。因实际指派给该端口名称的端口号,在每个 backend Pod 中可能并不相同,所以对于部署和设计 Service,这种方式会提供更大的灵活性。
另外 Service 能够支持 TCP 和 UDP 协议,默认是 TCP 协议。
kube-proxy
在 Kubernetes 集群中,每个 Node 会运行一个 kube-proxy 进程, 负责为 Service 实现一种 VIP(虚拟 IP,就是我们上面说的 clusterIP)的代理形式,现在的 Kubernetes 中默认是使用的 iptables 这种模式来代理。
iptables
这种模式,kube-proxy 会监视 apiserver 对 Service 对象和 Endpoints 对象的添加和移除。对每个 Service,它会添加上 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某一个 Pod 上面。我们还可以使用 Pod readiness 探针验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端,这样做意味着可以避免将流量通过 kube-proxy 发送到已知失败的 Pod 中,所以对于线上的应用来说一定要做 readiness 探针。
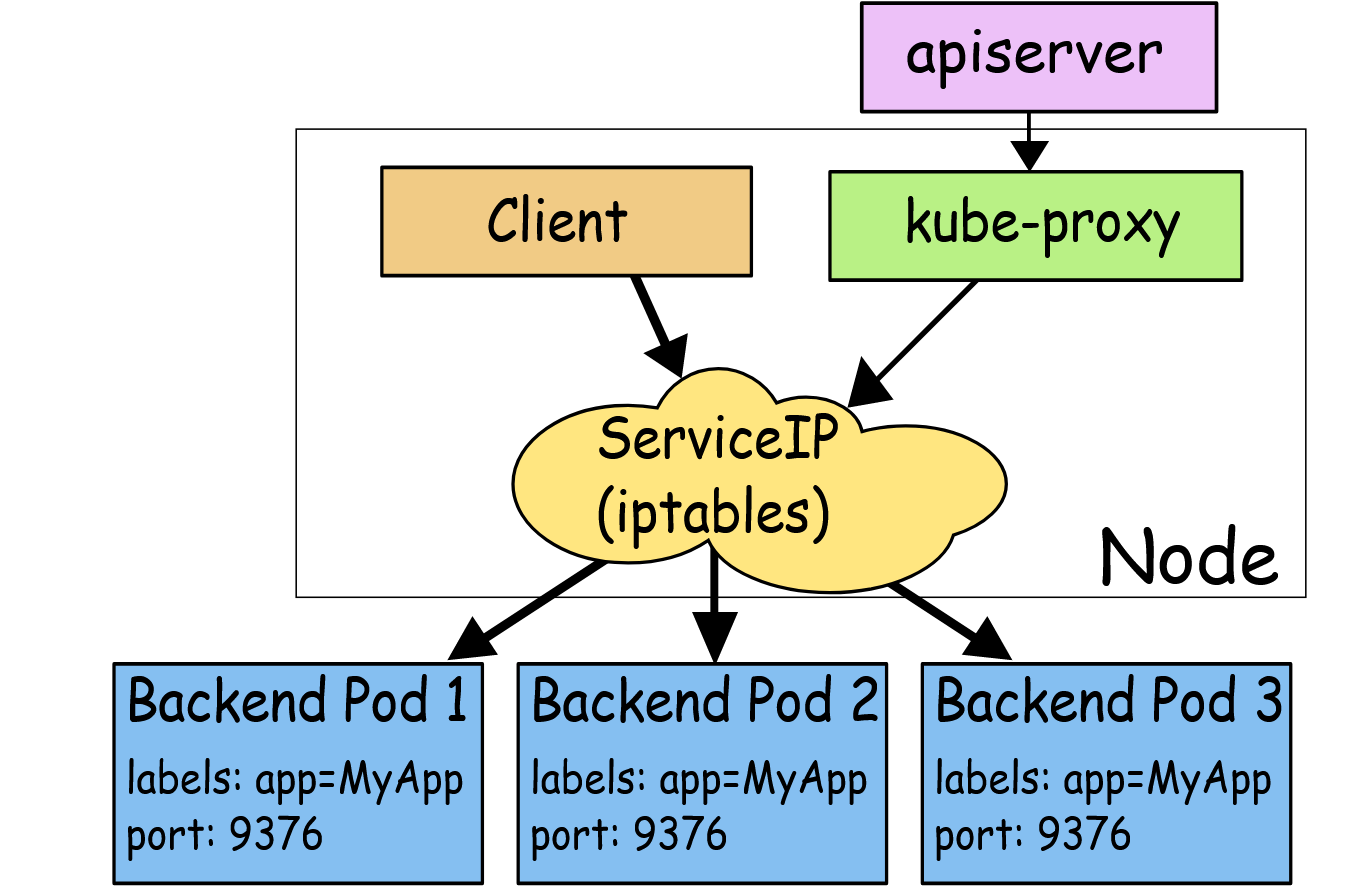
iptables 模式的 kube-proxy 默认的策略是,随机选择一个后端 Pod。
比如当创建 backend Service 时,Kubernetes 会给它指派一个虚拟 IP 地址,比如 10.0.0.1。假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。当 kube-proxy 看到一个新的 Service,它会安装一系列的 iptables 规则,从 VIP 重定向到 per-Service 规则。 该 per-Service 规则连接到 per-Endpoint 规则,该 per-Endpoint 规则会重定向(目标 NAT)到后端的 Pod。
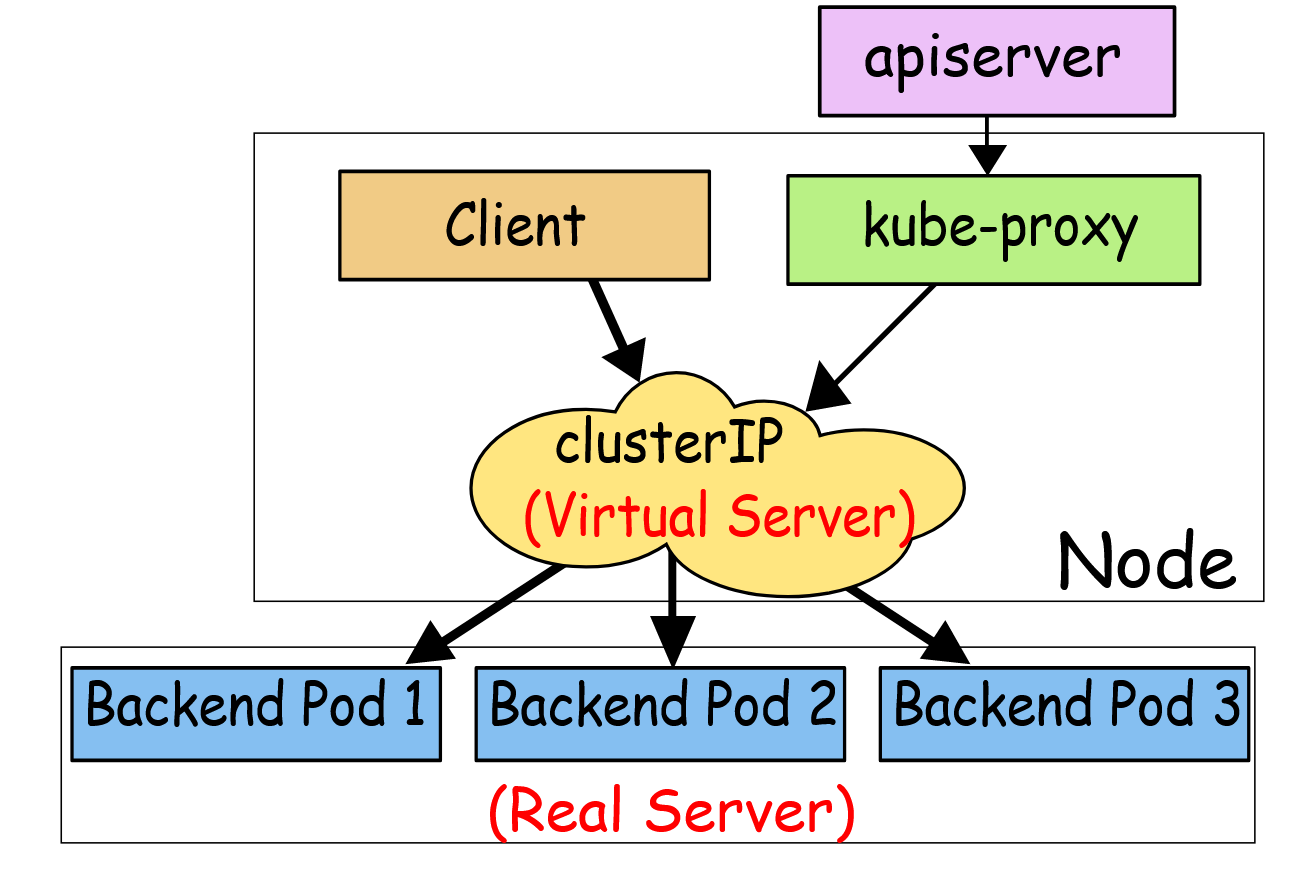
ipvs
除了 iptables 模式之外,kubernetes 也支持 ipvs 模式,在 ipvs 模式下,kube-proxy 监视 Kubernetes 服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。该控制循环可确保 IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端 Pod 之一。
IPVS 代理模式基于类似于 iptables 模式的 netfilter 钩子函数,但是使用哈希表作为基础数据结构,并且在内核空间中工作。 所以与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。所以对于较大规模的集群会使用 ipvs 模式的 kube-proxy,只需要满足节点上运行 ipvs 的条件,然后我们就可以直接将 kube-proxy 的模式修改为 ipvs,如果不满足运行条件会自动降级为 iptables 模式,现在都推荐使用 ipvs 模式,可以大幅度提高 Service 性能。
IPVS 提供了更多选项来平衡后端 Pod 的流量,默认是 rr,有如下一些策略:
- rr: round-robin
- lc: least connection (smallest number of open connections)
- dh: destination hashing
- sh: source hashing
- sed: shortest expected delay
- nq: never queue
不过现在只能整体修改策略,可以通过 kube-proxy 中配置 –ipvs-scheduler 参数来实现,暂时不支持特定的 Service 进行配置。
也可以实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")即可,此外还可以通过适当设置 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 来设置最大会话停留时间(默认值为 10800 秒,即 3 小时):
apiVersion: v1
kind: Service
spec:
sessionAffinity: ClientIP
...
亲和性: Service 只支持两种形式的会话亲和性服务:None 和 ClientIP,不支持基于 cookie 的会话亲和性,这是因为 Service 不是在 HTTP 层面上工作的,处理的是 TCP 和 UDP 包,并不关心其中的载荷内容,因为 cookie 是 HTTP 协议的一部分,Service 并不知道它们,所有会话亲和性不能基于 Cookie。
Service
在定义 Service 的时候可以指定一个自己需要的类型的 Service,如果不指定的话默认是 ClusterIP类型。可以使用的服务类型如下:
- ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的服务类型。
- NodePort:通过每个 Node 节点上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求 NodeIp:NodePort,可以从集群的外部访问一个 NodePort 服务。
- LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务,这个需要结合具体的云厂商进行操作。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。
NodePort 类型
如果设置 type 的值为 "NodePort",Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定,如果不指定的话会自动生成一个端口。
需要注意的是,Service 将能够通过 spec.ports[].nodePort 和 spec.clusterIp:spec.ports[].port 而对外可见。
接下来我们来给大家创建一个 NodePort 的服务来访问我们前面的 Nginx 服务:(service-nodeport-demo.yaml)
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
name: myapp-http
创建该 Service:
$ kubectl apply -f service-demo.yaml
然后我们可以查看 Service 对象信息:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 27d
myservice NodePort 10.104.57.198 <none> 80:32560/TCP 14h
我们可以看到 myservice 的 TYPE 类型已经变成了 NodePort,后面的 PORT(S) 部分也多了一个 32560 的映射端口。
ExternalName
ExternalName 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
当访问地址 my-service.prod.svc.cluster.local 时,集群的 DNS 服务将返回一个值为 my.database.example.com 的 CNAME 记录。访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。如果后续决定要将数据库迁移到 Kubernetes 集群中,可以启动对应的 Pod,增加合适的 Selector 或 Endpoint,修改 Service 的 type,完全不需要修改调用的代码,这样就完全解耦了。
除了可以直接通过 externalName 指定外部服务的域名之外,我们还可以通过自定义 Endpoints 来创建 Service,前提是 clusterIP=None,名称要和 Service 保持一致,如下所示:
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 2379
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s # 名称必须和 Service 一致
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 10.151.30.57 # Service 将连接重定向到 endpoint
ports:
- name: port
port: 2379 # endpoint 的目标端口
上面这个服务就是将外部的 etcd 服务引入到 Kubernetes 集群中来。
获取客户端 IP
通常,当集群内的客户端连接到服务的时候,是支持服务的 Pod 可以获取到客户端的 IP 地址的,但是,当通过节点端口接收到连接时,由于对数据包执行了源网络地址转换(SNAT),因此数据包的源 IP 地址会发生变化,后端的 Pod 无法看到实际的客户端 IP,对于某些应用来说是个问题,比如,nginx 的请求日志就无法获取准确的客户端访问 IP 了,比如下面我们的应用:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
直接创建后可以查看 nginx 服务被自动分配了一个 32761 的 NodePort 端口:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28d
nginx NodePort 10.106.190.194 <none> 80:32761/TCP 48m
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-54f57cf6bf-nwtjp 1/1 Running 0 3m 10.244.3.15 ydzs-node3 <none> <none>
nginx-54f57cf6bf-ptvgs 1/1 Running 0 2m59s 10.244.2.13 ydzs-node2 <none> <none>
nginx-54f57cf6bf-xhs8g 1/1 Running 0 2m59s 10.244.1.16 ydzs-node1 <none> <none>
我们可以看到这个3个 Pod 被分配到了 3 个不同的节点,这个时候我们通过 master 节点的 NodePort 端口来访问下我们的服务,因为我这里只有 master 节点可以访问外网,这个时候我们查看 nginx 的 Pod 日志可以看到其中获取到的 clientIP 是 10.151.30.11,其实是 master 节点的内网 IP,并不是我们期望的真正的浏览器端访问的 IP 地址:
$ kubectl logs -f nginx-54f57cf6bf-xhs8g
10.151.30.11 - - [07/Dec/2019:16:44:38 +0800] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" "-"
这个是因为我们 master 节点上并没有对应的 Pod,所以通过 master 节点去访问应用的时候必然需要额外的网络跳转才能到达其他节点上 Pod,在跳转过程中由于对数据包进行了 SNAT,所以看到的是 master 节点的 IP。这个时候我们可以在 Service 设置 externalTrafficPolicy 来减少网络跳数:
spec:
externalTrafficPolicy: Local
如果 Service 中配置了 externalTrafficPolicy=Local,并且通过服务的节点端口来打开外部连接,则 Service 会代理到本地运行的 Pod,如果本地没有本地 Pod 存在,则连接将挂起,比如我们这里设置上该字段更新,这个时候我们去通过 master 节点的 NodePort 访问应用是访问不到的,因为 master 节点上并没有对应的 Pod 运行,所以需要确保负载均衡器将连接转发给至少具有一个 Pod 的节点。
但是需要注意的是使用这个参数有一个缺点,通常情况下,请求都是均匀分布在所有 Pod 上的,但是使用了这个配置的话,情况就有可能不一样了。比如我们有两个节点上运行了 3 个 Pod,假如节点 A 运行一个 Pod,节点 B 运行两个 Pod,如果负载均衡器在两个节点间均衡分布连接,则节点 A 上的 Pod 将接收到所有请求的 50%,但节点 B 上的两个 Pod 每个就只接收 25% 。
由于增加了externalTrafficPolicy: Local这个配置后,接收请求的节点和目标 Pod 都在一个节点上,所以没有额外的网络跳转(不执行 SNAT),所以就可以拿到正确的客户端 IP,如下所示我们把 Pod 都固定到 master 节点上:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
tolerations:
- operator: "Exists"
nodeSelector:
kubernetes.io/hostname: ydzs-master
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
externalTrafficPolicy: Local
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
更新服务后,然后再通过 NodePort 访问服务可以看到拿到的就是正确的客户端 IP 地址了:
$ kubectl logs -f nginx-ddc8f997b-ptb7b
182.149.166.11 - - [07/Dec/2019:17:03:43 +0800] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh;
服务发现
可以通过 Service 生成的 ClusterIP(VIP) 来访问 Pod 提供的服务,但是在使用的时候还有一个问题:我们怎么知道某个应用的 VIP 呢?比如我们有两个应用,一个是 api 应用,一个是 db 应用,两个应用都是通过 Deployment 进行管理的,并且都通过 Service 暴露出了端口提供服务。api 需要连接到 db 这个应用,我们只知道 db 应用的名称和 db 对应的 Service 的名称,但是并不知道它的 VIP 地址,我们前面的 Service 课程中是不是学习到我们通过 ClusterIP 就可以访问到后面的 Pod 服务,如果我们知道了 VIP 的地址是不是就行了?
环境变量
为了解决上面的问题,在之前的版本中,Kubernetes 采用了环境变量的方法,每个 Pod 启动的时候,会通过环境变量设置所有服务的 IP 和 port 信息,这样 Pod 中的应用可以通过读取环境变量来获取依赖服务的地址信息,这种方法使用起来相对简单,但是有一个很大的问题就是依赖的服务必须在 Pod 启动之前就存在,不然是不会被注入到环境变量中的。比如我们首先创建一个 Nginx 服务:(test-nginx.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
labels:
name: nginx-service
spec:
ports:
- port: 5000
targetPort: 80
selector:
app: nginx
创建上面的服务:
$ kubectl apply -f test-nginx.yaml
deployment.apps "nginx-deploy" created
service "nginx-service" created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
...
nginx-deploy-75675f5897-47h4t 1/1 Running 0 53s
nginx-deploy-75675f5897-mmm8w 1/1 Running 0 53s
...
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
nginx-service ClusterIP 10.107.225.42 <none> 5000/TCP 1m
...
我们可以看到两个 Pod 和一个名为 nginx-service 的服务创建成功了,该 Service 监听的端口是 5000,同时它会把流量转发给它代理的所有 Pod(我们这里就是拥有 app: nginx 标签的两个 Pod)。
现在我们再来创建一个普通的 Pod,观察下该 Pod 中的环境变量是否包含上面的 nginx-service 的服务信息:(test-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-service-pod
image: busybox
command: ["/bin/sh", "-c", "env"]
然后创建该测试的 Pod:
$ kubectl apply -f test-pod.yaml
pod "test-pod" created
等 Pod 创建完成后,我们查看日志信息:
$ kubectl logs test-pod
...
KUBERNETES_PORT=tcp://10.96.0.1:443
KUBERNETES_SERVICE_PORT=443
HOSTNAME=test-pod
HOME=/root
NGINX_SERVICE_PORT_5000_TCP_ADDR=10.107.225.42
NGINX_SERVICE_PORT_5000_TCP_PORT=5000
NGINX_SERVICE_PORT_5000_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
NGINX_SERVICE_SERVICE_HOST=10.107.225.42
NGINX_SERVICE_PORT_5000_TCP=tcp://10.107.225.42:5000
KUBERNETES_PORT_443_TCP_PORT=443
KUBERNETES_PORT_443_TCP_PROTO=tcp
NGINX_SERVICE_SERVICE_PORT=5000
NGINX_SERVICE_PORT=tcp://10.107.225.42:5000
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
KUBERNETES_SERVICE_HOST=10.96.0.1
PWD=/
...
我们可以看到打印了很多环境变量信息,其中就包括我们刚刚创建的 nginx-service 这个服务,有 HOST、PORT、PROTO、ADDR 等,也包括其他已经存在的 Service 的环境变量,现在如果我们需要在这个 Pod 里面访问 nginx-service 的服务,我们是不是可以直接通过 NGINX_SERVICE_SERVICE_HOST 和 NGINX_SERVICE_SERVICE_PORT 就可以了,但是如果这个 Pod 启动起来的时候 nginx-service 服务还没启动起来,在环境变量中我们是无法获取到这些信息的,当然我们可以通过 initContainer 之类的方法来确保 nginx-service 启动后再启动 Pod,但是这种方法毕竟增加了 Pod 启动的复杂性,所以这不是最优的方法,局限性太多了。
DNS
由于上面环境变量这种方式的局限性,我们需要一种更加智能的方案,其实我们可以自己思考一种比较理想的方案:那就是可以直接使用 Service 的名称,因为 Service 的名称不会变化,我们不需要去关心分配的 ClusterIP 的地址,因为这个地址并不是固定不变的,所以如果我们直接使用 Service 的名字,然后对应的 ClusterIP 地址的转换能够自动完成就很好了。我们知道名字和 IP 直接的转换是不是和我们平时访问的网站非常类似啊?他们之间的转换功能通过 DNS 就可以解决了,同样的,Kubernetes 也提供了 DNS 的方案来解决上面的服务发现的问题。
DNS 服务不是一个独立的系统服务,而是作为一种 addon 插件而存在,现在比较推荐的两个插件:kube-dns 和 CoreDNS,实际上在比较新点的版本中已经默认是 CoreDNS 了,因为 kube-dns 默认一个 Pod 中需要3个容器配合使用,CoreDNS 只需要一个容器即可,我们在前面使用 kubeadm 搭建集群的时候直接安装的就是 CoreDNS 插件:
$ kubectl get pods -n kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-667f964f9b-sthqq 1/1 Running 0 32m
coredns-667f964f9b-zj4r4 1/1 Running 0 33m
CoreDns 是用 GO 写的高性能,高扩展性的 DNS 服务,基于 HTTP/2 Web 服务 Caddy 进行编写的。CoreDns 内部采用插件机制,所有功能都是插件形式编写,用户也可以扩展自己的插件,以下是 Kubernetes 部署 CoreDns 时的默认配置:
$ kubectl get cm coredns -n kube-system -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors # 启用错误记录
health # 启用检查检查端点,8080:health
ready
kubernetes cluster.local in-addr.arpa ip6.arpa { # 处理 k8s 域名解析
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153 # 启用 prometheus metrics 指标,9153:metrics
forward . /etc/resolv.conf # 通过 resolv.conf 内的 nameservers 解析
cache 30 # 启用缓存,所有内容限制为 30s 的TTL
loop # 检查简单的转发循环并停止服务
reload # 运行自动重新加载 corefile,热更新
loadbalance # 负载均衡,默认 round_robin
}
kind: ConfigMap
metadata:
creationTimestamp: "2019-11-08T11:59:49Z"
name: coredns
namespace: kube-system
resourceVersion: "188"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: 21966186-c2d9-467a-b87f-d061c5c9e4d7
- 每个 {} 代表一个 zone,格式是 “Zone:port{}”, 其中"."代表默认zone
- {} 内的每个名称代表插件的名称,只有配置的插件才会启用,当解析域名时,会先匹配 zone(都未匹配会执行默认 zone),然后 zone 内的插件从上到下依次执行(这个顺序并不是配置文件内谁在前面的顺序,而是core/dnsserver/zdirectives.go内的顺序),匹配后返回处理(执行过的插件从下到上依次处理返回逻辑),不再执行下一个插件
CoreDNS 的 Service 地址一般情况下是固定的,类似于 kubernetes 这个 Service 地址一般就是第一个 IP 地址 10.96.0.1,CoreDNS 的 Service 地址就是 10.96.0.10,该 IP 被分配后,kubelet 会将使用 --cluster-dns=<dns-service-ip> 参数配置的 DNS 传递给每个容器。DNS 名称也需要域名,本地域可以使用参数--cluster-domain = <default-local-domain> 在 kubelet 中配置:
$ cat /var/lib/kubelet/config.yaml
......
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
......
我们前面说了如果我们建立的 Service 如果支持域名形式进行解析,就可以解决我们的服务发现的功能,那么利用 kubedns 可以将 Service 生成怎样的 DNS 记录呢?
- 普通的 Service:会生成 servicename.namespace.svc.cluster.local 的域名,会解析到 Service 对应的 ClusterIP 上,在 Pod 之间的调用可以简写成 servicename.namespace,如果处于同一个命名空间下面,甚至可以只写成 servicename 即可访问
- Headless Service:无头服务,就是把 clusterIP 设置为 None 的,会被解析为指定 Pod 的 IP 列表,同样还可以通过 podname.servicename.namespace.svc.cluster.local 访问到具体的某一个 Pod。
接下来我们来使用一个简单 Pod 来测试下 Service 的域名访问:
$ kubectl run -it --image busybox:1.28.3 test-dns --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
/ #
我们进入到 Pod 中,查看 /etc/resolv.conf 中的内容,可以看到 nameserver 的地址 10.96.0.10,该 IP 地址即是在安装 CoreDNS 插件的时候集群分配的一个固定的静态 IP 地址,我们可以通过下面的命令进行查看:
$ kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 28d
也就是说我们这个 Pod 现在默认的 nameserver 就是 kube-dns 的地址,现在我们来访问下前面我们创建的 nginx-service 服务:
/ # wget -q -O- nginx-service.default.svc.cluster.local
可以看到上面我们使用 wget 命令去访问 nginx-service 服务的域名的时候被 hang 住了,没有得到期望的结果,这是因为上面我们建立 Service 的时候暴露的端口是 5000:
/ # wget -q -O- nginx-service.default.svc.cluster.local:5000
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
加上 5000 端口,就正常访问到服务,再试一试访问:nginx-service.default.svc、nginx-service.default、nginx-service,不出意外这些域名都可以正常访问到期望的结果。
Ingress - 对外暴露集群服务
在 Kubernetes 集群内部使用 kube-dns 实现服务发现的功能,那么我们部署在 Kubernetes 集群中的应用如何暴露给外部的用户使用呢?我们知道可以使用 NodePort 和 LoadBlancer 类型的 Service 可以把应用暴露给外部用户使用,除此之外,Kubernetes 还为我们提供了一个非常重要的资源对象可以用来暴露服务给外部用户,那就是 Ingress。对于小规模的应用我们使用 NodePort 或许能够满足我们的需求,但是当你的应用越来越多的时候,你就会发现对于 NodePort 的管理就非常麻烦了,这个时候使用 Ingress 就非常方便了,可以避免管理大量的端口。
Ingress 其实就是从 Kuberenets 集群外部访问集群的一个入口,将外部的请求转发到集群内不同的 Service 上,其实就相当于 nginx、haproxy 等负载均衡代理服务器,可能你会觉得我们直接使用 nginx 就实现了,但是只使用 nginx 这种方式有很大缺陷,每次有新服务加入的时候怎么改 Nginx 配置?不可能让我们去手动更改或者滚动更新前端的 Nginx Pod 吧?那我们再加上一个服务发现的工具比如 consul 如何?貌似是可以,对吧?Ingress 实际上就是这样实现的,只是服务发现的功能自己实现了,不需要使用第三方的服务了,然后再加上一个域名规则定义,路由信息的刷新依靠 Ingress Controller 来提供。
Ingress Controller 可以理解为一个监听器,通过不断地监听 kube-apiserver,实时的感知后端 Service、Pod 的变化,当得到这些信息变化后,Ingress Controller 再结合 Ingress 的配置,更新反向代理负载均衡器,达到服务发现的作用。其实这点和服务发现工具 consul、 consul-template 非常类似。
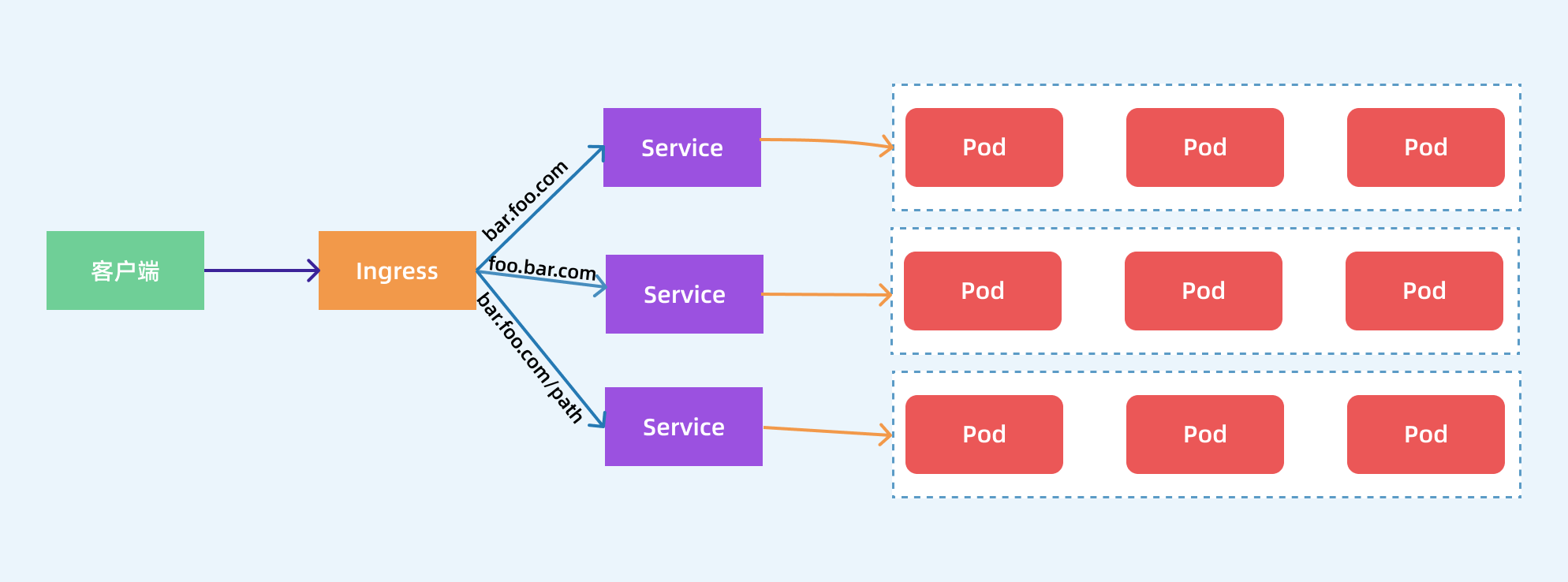
现在可以供大家使用的 Ingress Controller 有很多,比如 traefik、nginx-controller、Kubernetes Ingress Controller for Kong、HAProxy Ingress controller,当然你也可以自己实现一个 Ingress Controller,现在普遍用得较多的是 traefik 和 nginx-controller,traefik 的性能较 nginx-controller 差,但是配置使用要简单许多,我们这里会重点给大家介绍 nginx-controller 以及 traefik 的使用。
NGINX Ingress Controller
NGINX Ingress Controller 是使用 Kubernetes Ingress 资源对象构建的,用 ConfigMap 来存储 Nginx 配置的一种 Ingress Controller 实现。
要使用 Ingress 对外暴露服务,就需要提前安装一个 Ingress Controller,我们这里就先来安装 NGINX Ingress Controller,由于 nginx-ingress 所在的节点需要能够访问外网,这样域名可以解析到这些节点上直接使用,所以需要让 nginx-ingress 绑定节点的 80 和 443 端口,所以可以使用 hostPort 来进行访问,当然对于线上环境来说为了保证高可用,一般是需要运行多个 nginx-ingress 实例的,然后可以用一个 nginx/haproxy 作为入口,通过 keepalived 来访问边缘节点的 vip 地址。
边缘节点: 所谓的边缘节点即集群内部用来向集群外暴露服务能力的节点,集群外部的服务通过该节点来调用集群内部的服务,边缘节点是集群内外交流的一个Endpoint。
所以我们这里需要更改下资源清单文件:
$ wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.26.1/deploy/static/mandatory.yaml
$ cat mandatory.yaml
...
tolerations: # 由于我这里的边缘节点只有master一个节点,所有需要加上容忍
- operator: "Exists"
nodeSelector: # 固定在边缘节点
kubernetes.io/hostname: ydzs-master
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.26.1
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 33
runAsUser: 33
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
hostPort: 80 # 使用hostPort
containerPort: 80
- name: https
hostPort: 443 # 使用hostPort
containerPort: 443
...
$ kubectl apply -f mandatory.yaml
安装后会将 NGINX Ingress Controller 安装在一个统一的 ingress-nginx 的 namespace 下面:
$ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
nginx-ingress-controller-565459444-6m4cz 1/1 Running 0 38s
安装完成后,我们可以在 controller 的 Pod 所在节点使用如下方式进行验证:
$ curl 127.0.0.1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>openresty/1.15.8.2</center>
</body>
</html>
出现了上面的信息证明 Ingress Controller 已经安装成功。
Ingress
安装成功后,现在我们来为一个 nginx 应用创建一个 Ingress 资源,如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
app: my-nginx
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
app: my-nginx
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
app: my-nginx
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-nginx
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: ngdemo.qikqiak.com # 将域名映射到 my-nginx 服务
http:
paths:
- path: /
backend:
serviceName: my-nginx # 将所有请求发送到 my-nginx 服务的 80 端口
servicePort: 80 # 不过需要注意大部分Ingress controller都不是直接转发到Service
# 而是只是通过Service来获取后端的Endpoints列表,直接转发到Pod,这样可以减少网络跳转,提高性能
直接创建上面的资源对象:
$ kubectl apply -f ngdemo.yaml
deployment.apps "my-nginx" created
service "my-nginx" created
ingress.extensions "my-nginx" created
注意我们在 Ingress 资源对象中添加了一个 annotations:kubernetes.io/ingress.class: "nginx",这就是指定让这个 Ingress 通过 nginx-ingress 来处理。
上面资源创建成功后,然后我们可以将域名ngdemo.qikqiak.com解析到nginx-ingress所在的边缘节点中的任意一个,当然也可以在本地/etc/hosts中添加对应的映射也可以,然后就可以通过域名进行访问了。
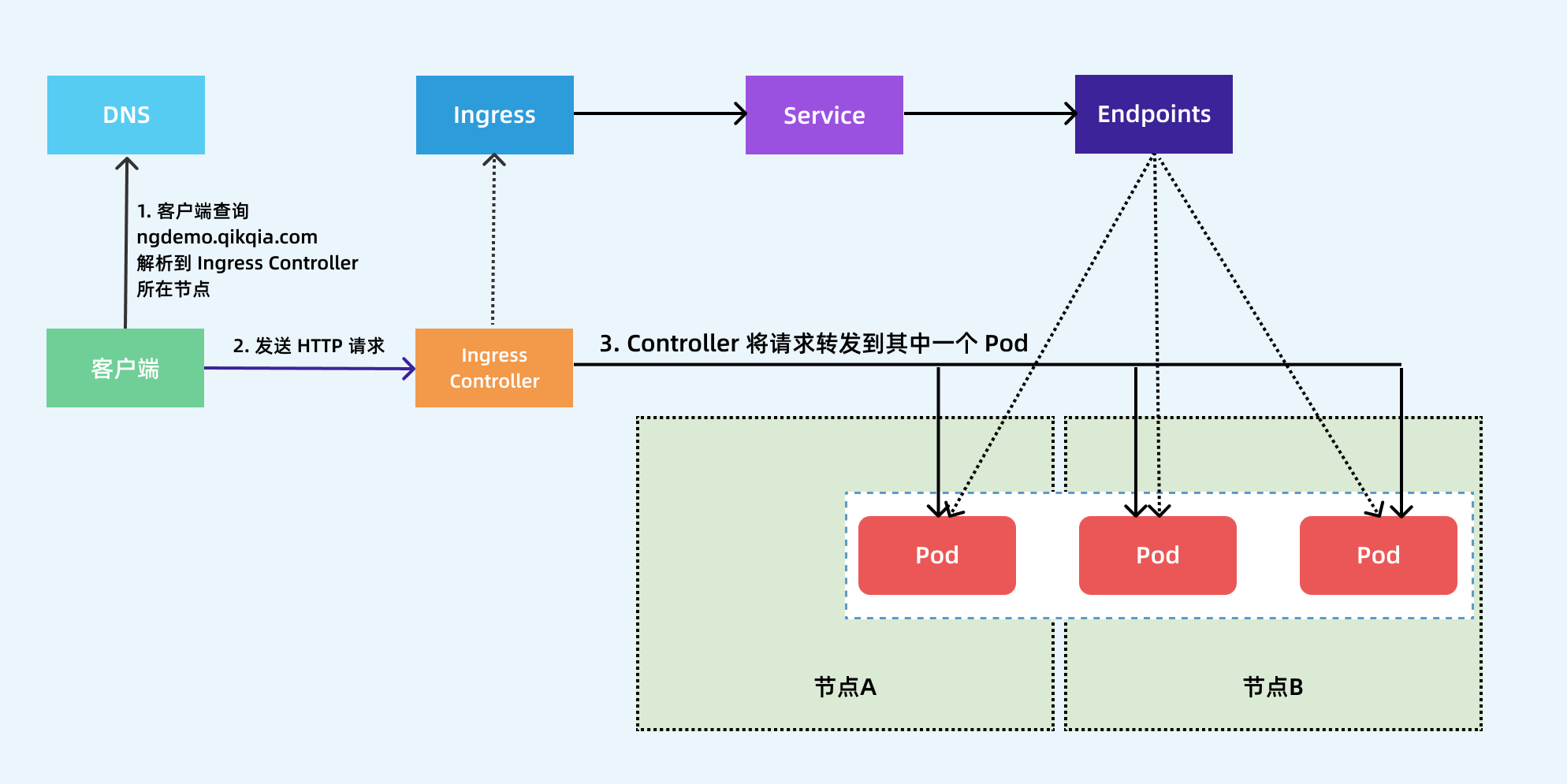
下图显示了客户端是如果通过 Ingress Controller 连接到其中一个 Pod 的流程,客户端首先对 ngdemo.qikqiak.com 执行 DNS 解析,得到 Ingress Controller 所在节点的 IP,然后客户端向 Ingress Controller 发送 HTTP 请求,然后根据 Ingress 对象里面的描述匹配域名,找到对应的 Service 对象,并获取关联的 Endpoints 列表,将客户端的请求转发给其中一个 Pod。
URL Rewrite
NGINX Ingress Controller 很多高级的用法可以通过 Ingress 对象的 annotation 进行配置,比如常用的 URL Rewrite 功能,比如我们有一个 todo 的前端应用,对应的 Ingress 资源对象如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: fe
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: todo.qikqiak.com
http:
paths:
- backend:
serviceName: fe
servicePort: 3000
path: /
就是一个很常规的 Ingress 对象,部署该对象后,将域名解析后就可以正常访问到应用:
现在我们需要对访问的 URL 路径做一个 Rewrite,比如在 PATH 中添加一个 app 的前缀,关于 Rewrite 的操作在 ingress-nginx 官方文档中也给出对应的说明:

按照要求我们需要在 path 中匹配前缀 app,然后通过 rewrite-target 指定目标,修改后的 Ingress 对象如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: fe
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
rules:
- host: todo.qikqiak.com
http:
paths:
- backend:
serviceName: fe
servicePort: 3000
path: /app(/|$)(.*)
更新后,我们可以遇见到直接访问域名肯定是不行了,因为我们没有匹配 / 的 path 路径:
但是我们带上 app 的前缀再去访问:
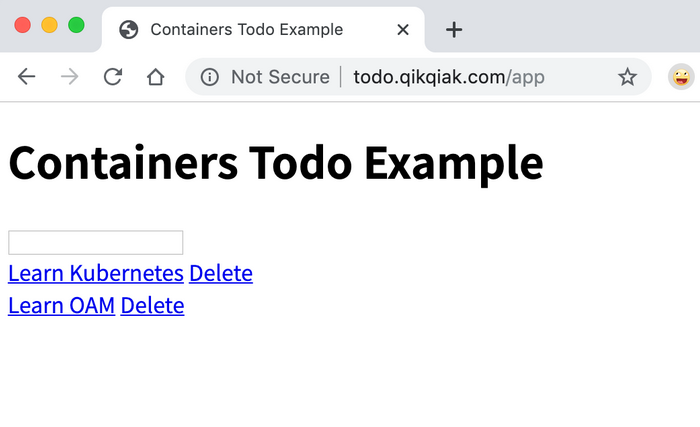
我们可以看到已经可以访问到页面内容了,这是因为我们在 path 中通过正则表达式 /app(/|$)(.*) 将匹配的路径设置成了 rewrite-target 的目标路径了,所以我们访问 todo.qikqiak.com/app 的时候实际上相当于访问的就是后端服务的 / 路径,但是我们也可以发现现在页面的样式没有了:
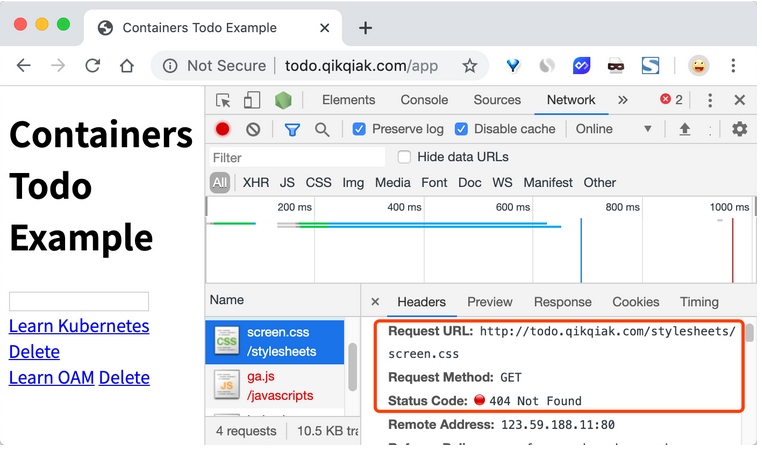
这是因为应用的静态资源路径是在 /stylesheets 路径下面的,现在我们做了 url rewrite 过后,要正常访问也需要带上前缀才可以:http://todo.qikqiak.com/stylesheets/screen.css,对于图片或者其他静态资源也是如此,当然我们去更改页面引入静态资源的方式为相对路径也是可以的,但是毕竟要修改代码,这个时候我们可以借助 ingress-nginx 中的 configuration-snippet 来对静态资源做一次跳转,如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: fe
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/configuration-snippet: |
rewrite ^/stylesheets/(.*)$ /app/stylesheets/$1 redirect; # 添加 /app 前缀
rewrite ^/images/(.*)$ /app/images/$1 redirect; # 添加 /app 前缀
spec:
rules:
- host: todo.qikqiak.com
http:
paths:
- backend:
serviceName: fe
servicePort: 3000
path: /app(/|$)(.*)
更新 Ingress 对象后,这个时候我们刷新页面可以看到已经正常了:
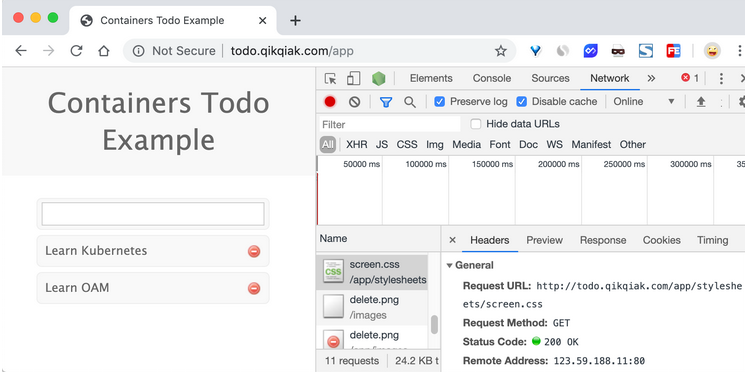
要解决我们访问主域名出现 404 的问题,我们可以给应用设置一个 app-root 的注解,这样当我们访问主域名的时候会自动跳转到我们指定的 app-root 目录下面,如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: fe
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/app-root: /app/
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/configuration-snippet: |
rewrite ^/stylesheets/(.*)$ /app/stylesheets/$1 redirect; # 添加 /app 前缀
rewrite ^/images/(.*)$ /app/images/$1 redirect; # 添加 /app 前缀
spec:
rules:
- host: todo.qikqiak.com
http:
paths:
- backend:
serviceName: fe
servicePort: 3000
path: /app(/|$)(.*)
这个时候我们更新应用后访问主域名 http://todo.qikqiak.com 就会自动跳转到 http://todo.qikqiak.com/app/ 路径下面去了。但是还有一个问题是我们的 path 路径其实也匹配了 /app 这样的路径,可能我们更加希望我们的应用在最后添加一个 / 这样的 slash,同样我们可以通过 configuration-snippet 配置来完成,如下 Ingress 对象:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: fe
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/app-root: /app/
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/configuration-snippet: |
rewrite ^(/app)$ $1/ redirect;
rewrite ^/stylesheets/(.*)$ /app/stylesheets/$1 redirect;
rewrite ^/images/(.*)$ /app/images/$1 redirect;
spec:
rules:
- host: todo.qikqiak.com
http:
paths:
- backend:
serviceName: fe
servicePort: 3000
path: /app(/|$)(.*)
更新后我们的应用就都会以 / 这样的 slash 结尾了。这样就完成了我们的需求,如果你原本对 nginx 的配置就非常熟悉的话应该可以很快就能理解这种配置方式了。
Basic Auth
同样我们还可以在 Ingress Controller 上面配置一些基本的 Auth 认证,比如 Basic Auth,可以用 htpasswd 生成一个密码文件来验证身份验证。
$ htpasswd -c auth foo
New password:
Re-type new password:
Adding password for user foo
然后根据上面的 auth 文件创建一个 secret 对象:
$ kubectl create secret generic basic-auth --from-file=auth
secret/basic-auth created
$ kubectl get secret basic-auth -o yaml
apiVersion: v1
data:
auth: Zm9vOiRhcHIxJFNjcVhZcFN6JDc4Nm5ISFNaeDdwN2VscDM2WUo0YS8K
kind: Secret
metadata:
creationTimestamp: "2019-12-08T06:40:39Z"
name: basic-auth
namespace: default
resourceVersion: "9197951"
selfLink: /api/v1/namespaces/default/secrets/basic-auth
uid: 6b2aa299-b511-412e-85ea-d0e91e578af0
type: Opaque
然后对上面的 my-nginx 应用创建一个具有 Basic Auth 的 Ingress 对象:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-with-auth
annotations:
# 认证类型
nginx.ingress.kubernetes.io/auth-type: basic
# 包含 user/password 定义的 secret 对象名
nginx.ingress.kubernetes.io/auth-secret: basic-auth
# 要显示的带有适当上下文的消息,说明需要身份验证的原因
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo'
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /
backend:
serviceName: my-nginx
servicePort: 80
直接创建上面的资源对象,然后通过下面的命令或者在浏览器中直接打开配置的域名:
$ curl -v http://k8s.youdianzhishi.com -H 'Host: foo.bar.com'
* Rebuilt URL to: http://k8s.youdianzhishi.com/
* Trying 123.59.188.11...
* TCP_NODELAY set
* Connected to k8s.youdianzhishi.com (123.59.188.11) port 80 (#0)
> GET / HTTP/1.1
> Host: foo.bar.com
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 401 Unauthorized
< Server: openresty/1.15.8.2
< Date: Sun, 08 Dec 2019 06:44:35 GMT
< Content-Type: text/html
< Content-Length: 185
< Connection: keep-alive
< WWW-Authenticate: Basic realm="Authentication Required - foo"
<
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>openresty/1.15.8.2</center>
</body>
</html>
我们可以看到出现了 401 认证失败错误,然后带上我们配置的用户名和密码进行认证:
$ curl -v http://k8s.youdianzhishi.com -H 'Host: foo.bar.com' -u 'foo:foo'
* Rebuilt URL to: http://k8s.youdianzhishi.com/
* Trying 123.59.188.11...
* TCP_NODELAY set
* Connected to k8s.youdianzhishi.com (123.59.188.11) port 80 (#0)
* Server auth using Basic with user 'foo'
> GET / HTTP/1.1
> Host: foo.bar.com
> Authorization: Basic Zm9vOmZvbw==
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: openresty/1.15.8.2
< Date: Sun, 08 Dec 2019 06:46:27 GMT
< Content-Type: text/html
< Content-Length: 612
< Connection: keep-alive
< Vary: Accept-Encoding
< Last-Modified: Tue, 19 Nov 2019 12:50:08 GMT
< ETag: "5dd3e500-264"
< Accept-Ranges: bytes
<
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
可以看到已经认证成功了。当然出来 Basic Auth 这一种简单的认证方式之外,NGINX Ingress Controller 还支持一些其他高级的认证,比如 OAUTH 认证之类的。
HTTPS
如果我们需要用 HTTPS 来访问我们这个应用的话,就需要监听 443 端口了,同样用 HTTPS 访问应用必然就需要证书,这里我们用 openssl 来创建一个自签名的证书:
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=foo.bar.com"
然后通过 Secret 对象来引用证书文件:
# 要注意证书文件名称必须是 tls.crt 和 tls.key
$ kubectl create secret tls foo-tls --cert=tls.crt --key=tls.key
secret/who-tls created
这个时候我们就可以创建一个 HTTPS 访问应用的:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-with-auth
annotations:
# 认证类型
nginx.ingress.kubernetes.io/auth-type: basic
# 包含 user/password 定义的 secret 对象名
nginx.ingress.kubernetes.io/auth-secret: basic-auth
# 要显示的带有适当上下文的消息,说明需要身份验证的原因
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo'
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /
backend:
serviceName: my-nginx
servicePort: 80
tls:
- hosts:
- foo.bar.com
secretName: foo-tls
Traefik
Traefik 是一个开源的可以使服务发布变得轻松有趣的边缘路由器。它负责接收系统的请求,然后使用合适的组件来对这些请求进行处理。
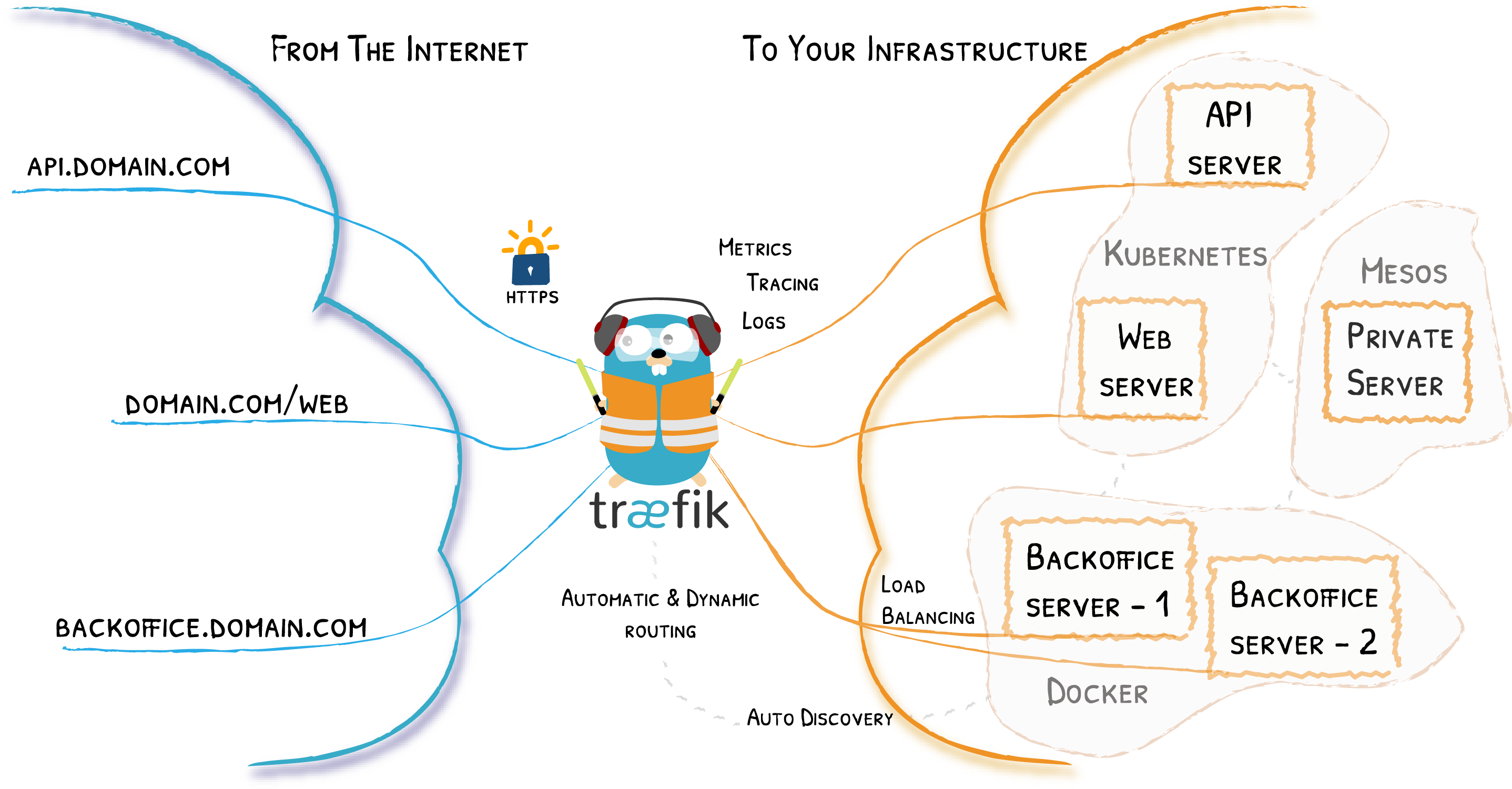
除了众多的功能之外,Traefik 的与众不同之处还在于它会自动发现适合你服务的配置。当 Traefik 在检查你的服务时,会找到服务的相关信息并找到合适的服务来满足对应的请求。
Traefik 兼容所有主流的集群技术,比如 Kubernetes,Docker,Docker Swarm,AWS,Mesos,Marathon,等等;并且可以同时处理多种方式。(甚至可以用于在裸机上运行的比较旧的软件。)
使用 Traefik,不需要维护或者同步一个独立的配置文件:因为一切都会自动配置,实时操作的(无需重新启动,不会中断连接)。使用 Traefik,你可以花更多的时间在系统的开发和新功能上面,而不是在配置和维护工作状态上面花费大量时间。
核心概念
Traefik 是一个边缘路由器,是你整个平台的大门,拦截并路由每个传入的请求:它知道所有的逻辑和规则,这些规则确定哪些服务处理哪些请求;传统的反向代理需要一个配置文件,其中包含路由到你服务的所有可能路由,而 Traefik 会实时检测服务并自动更新路由规则,可以自动服务发现。
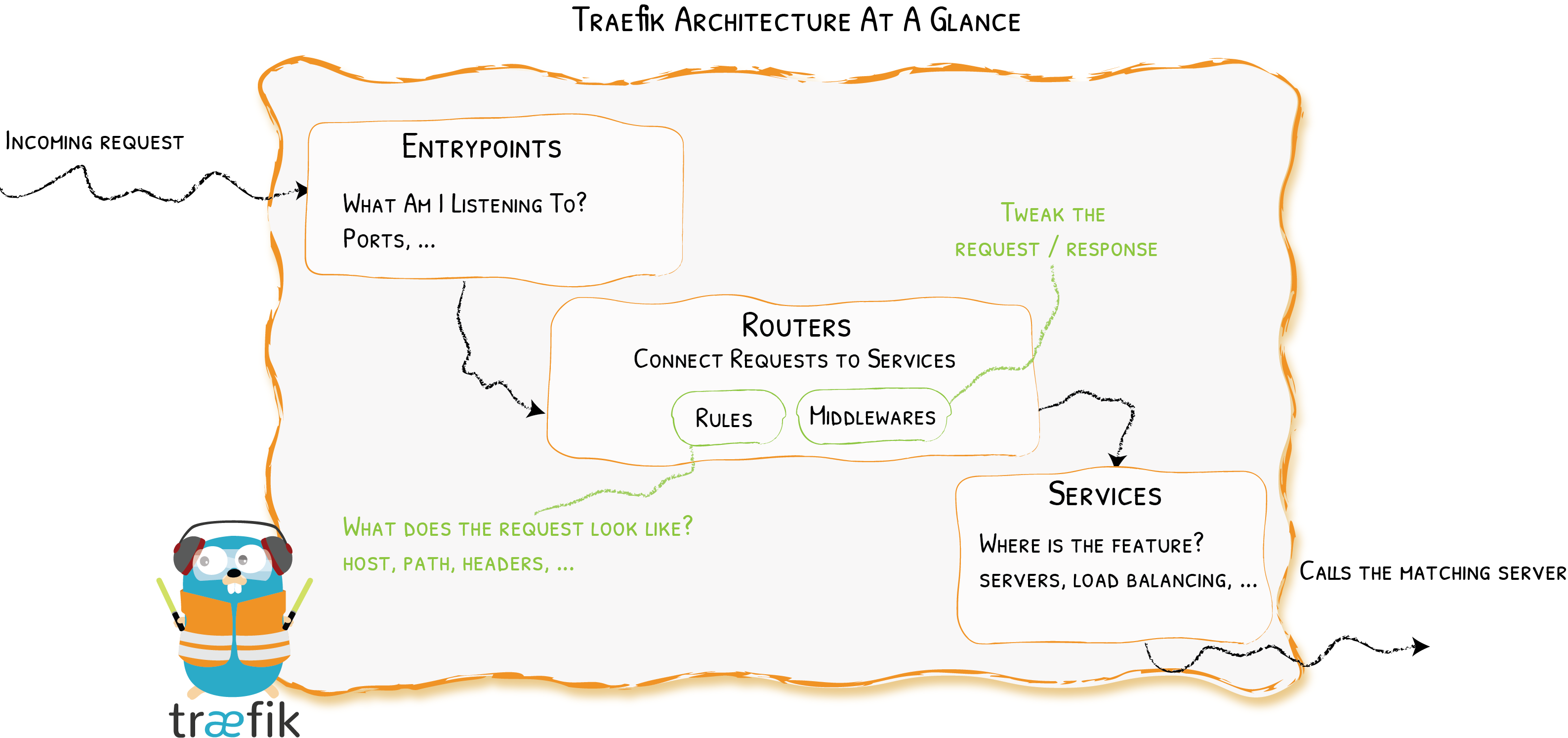
首先,当启动 Traefik 时,需要定义 entrypoints(入口点),然后,根据连接到这些 entrypoints 的路由来分析传入的请求,来查看他们是否与一组规则相匹配,如果匹配,则路由可能会将请求通过一系列中间件转换过后再转发到你的服务上去。在了解 Traefik 之前有几个核心概念我们必须要了解:
- Providers 用来自动发现平台上的服务,可以是编排工具、容器引擎或者 key-value 存储等,比如 Docker、Kubernetes、File
- Entrypoints 监听传入的流量(端口等…),是网络入口点,它们定义了接收请求的端口(HTTP 或者 TCP)。
- Routers 分析请求(host, path, headers, SSL, …),负责将传入请求连接到可以处理这些请求的服务上去。
- Services 将请求转发给你的应用(load balancing, …),负责配置如何获取最终将处理传入请求的实际服务。
- Middlewares 中间件,用来修改请求或者根据请求来做出一些判断(authentication, rate limiting, headers, ...),中间件被附件到路由上,是一种在请求发送到你的服务之前(或者在服务的响应发送到客户端之前)调整请求的一种方法。
安装
由于 Traefik 2.X 版本和之前的 1.X 版本不兼容,我们这里选择功能更加强大的 2.X 版本来和大家进行讲解,我们这里使用的镜像是 traefik:2.1.1。
在 Traefik 中的配置可以使用两种不同的方式:
- 动态配置:完全动态的路由配置
- 静态配置:启动配置
静态配置中的元素(这些元素不会经常更改)连接到 providers 并定义 Treafik 将要监听的 entrypoints。
在 Traefik 中有三种方式定义静态配置:在配置文件中、在命令行参数中、通过环境变量传递
动态配置包含定义系统如何处理请求的所有配置内容,这些配置是可以改变的,而且是无缝热更新的,没有任何请求中断或连接损耗。
安装 Traefik 到 Kubernetes 集群中的资源清单文件我这里提前准备好了,直接执行下面的安装命令即可:
$ kubectl apply -f https://www.qikqiak.com/k8strain/network/manifests/traefik/crd.yaml
$ kubectl apply -f https://www.qikqiak.com/k8strain/network/manifests/traefik/rbac.yaml
$ kubectl apply -f https://www.qikqiak.com/k8strain/network/manifests/traefik/deployment.yaml
$ kubectl apply -f https://www.qikqiak.com/k8strain/network/manifests/traefik/dashboard.yaml
其中 deployment.yaml 我这里是固定到 master 节点上的,如果你需要修改可以下载下来做相应的修改即可。我们这里是通过命令行参数来做的静态配置:
args:
- --entryPoints.web.address=:80
- --entryPoints.websecure.address=:443
- --api=true
- --api.dashboard=true
- --ping=true
- --providers.kubernetesingress
- --providers.kubernetescrd
- --log.level=INFO
- --accesslog
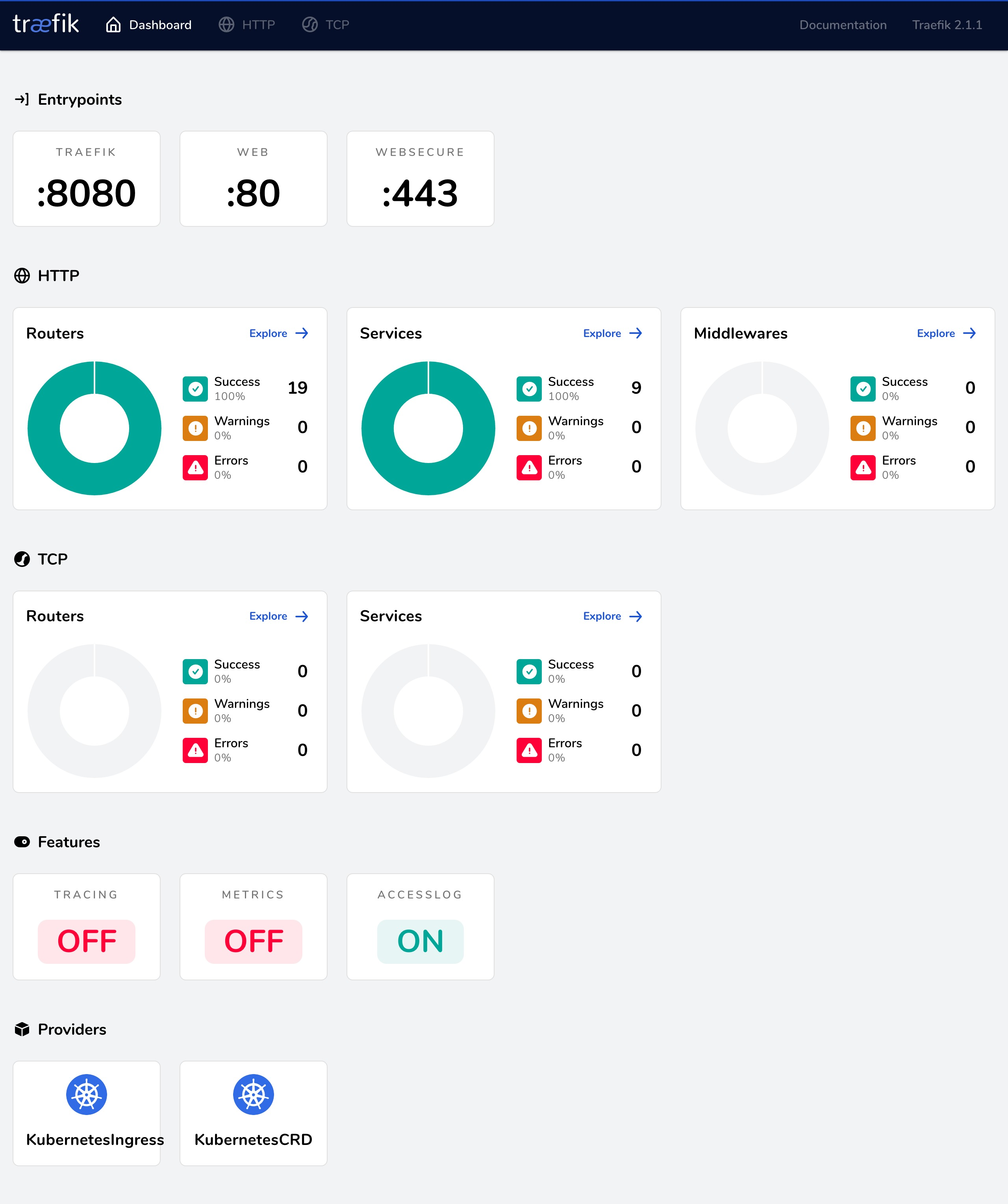
其中前两项配置是来定义 web 和 websecure 这两个入口点的,--api=true 开启,=,就会创建一个名为 api@internal 的特殊 service,在 dashboard 中可以直接使用这个 service 来访问,然后其他比较重要的就是开启 kubernetesingress 和 kubernetescrd 这两个 provider。
dashboard.yaml 中定义的是访问 dashboard 的资源清单文件,可以根据自己的需求修改。
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
traefik-867bd6b9c-lbrlx 1/1 Running 0 6m17s
......
$ kubectl get ingressroute
NAME AGE
traefik-dashboard 30m
部署完成后我们可以通过在本地 /etc/hosts 中添加上域名 traefik.domain.com 的映射即可访问 Traefik 的 Dashboard 页面了:
ACME
Traefik 通过扩展 CRD 的方式来扩展 Ingress 的功能,除了默认的用 Secret 的方式可以支持应用的 HTTPS 之外,还支持自动生成 HTTPS 证书。
比如现在我们有一个如下所示的 whoami 应用:
apiVersion: v1
kind: Service
metadata:
name: whoami
spec:
ports:
- protocol: TCP
name: web
port: 80
selector:
app: whoami
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: whoami
labels:
app: whoami
spec:
replicas: 2
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: containous/whoami
ports:
- name: web
containerPort: 80
然后定义一个 IngressRoute 对象:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: simpleingressroute
spec:
entryPoints:
- web
routes:
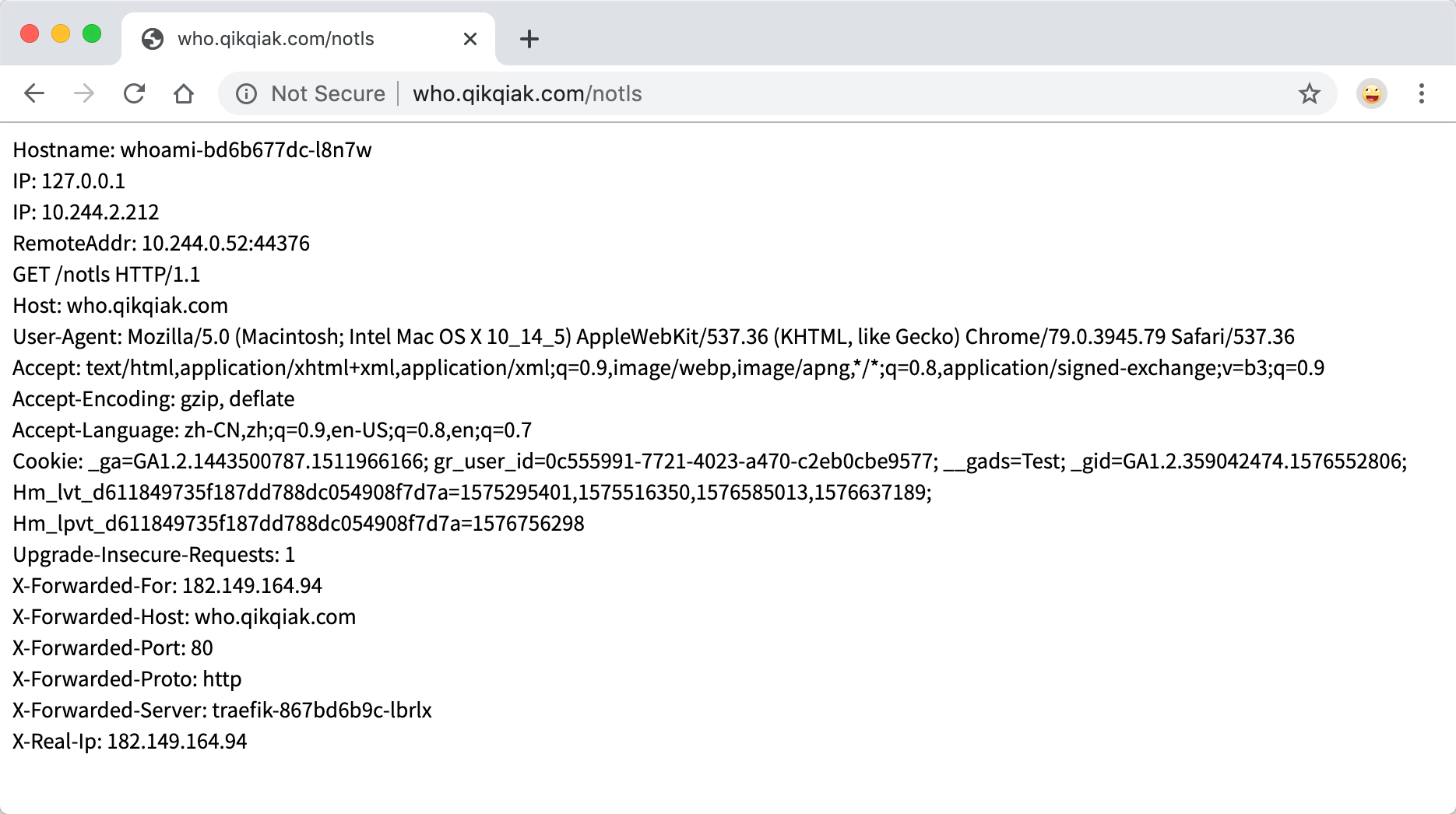
- match: Host(`who.qikqiak.com`) && PathPrefix(`/notls`)
kind: Rule
services:
- name: whoami
port: 80
通过 entryPoints 指定了我们这个应用的入口点是 web,也就是通过 80 端口访问,然后访问的规则就是要匹配 who.qikqiak.com 这个域名,并且具有 /notls 的路径前缀的请求才会被 whoami 这个 Service 所匹配。我们可以直接创建上面的几个资源对象,然后对域名做对应的解析后,就可以访问应用了:
在 IngressRoute 对象中我们定义了一些匹配规则,这些规则在 Traefik 中有如下定义方式:

如果我们需要用 HTTPS 来访问我们这个应用的话,就需要监听 websecure 这个入口点,也就是通过 443 端口来访问,同样用 HTTPS 访问应用必然就需要证书,这里我们用 openssl 来创建一个自签名的证书:
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=who.qikqiak.com"
然后通过 Secret 对象来引用证书文件:
# 要注意证书文件名称必须是 tls.crt 和 tls.key
$ kubectl create secret tls who-tls --cert=tls.crt --key=tls.key
secret/who-tls created
这个时候我们就可以创建一个 HTTPS 访问应用的 IngressRoute 对象了:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: ingressroutetls
spec:
entryPoints:
- websecure
routes:
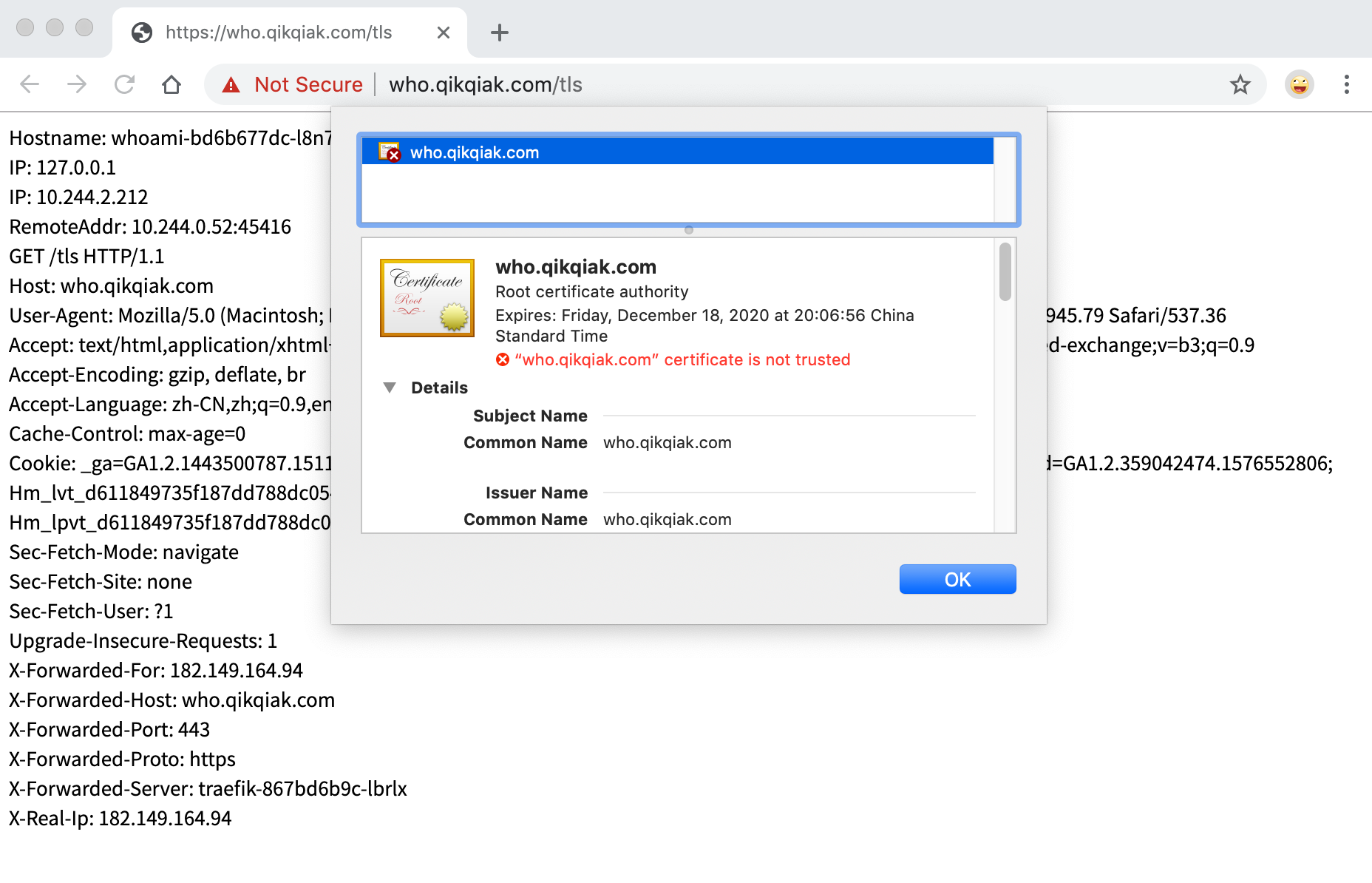
- match: Host(`who.qikqiak.com`) && PathPrefix(`/tls`)
kind: Rule
services:
- name: whoami
port: 80
tls:
secretName: who-tls
创建完成后就可以通过 HTTPS 来访问应用了,由于我们是自签名的证书,所以证书是不受信任的:
除了手动提供证书的方式之外 Traefik 还支持使用 Let’s Encrypt 自动生成证书,要使用 Let’s Encrypt 来进行自动化 HTTPS,就需要首先开启 ACME,开启 ACME 需要通过静态配置的方式,也就是说可以通过环境变量、启动参数等方式来提供,我们这里还是直接使用启动参数的形式来开启,在 Traefik 的部署文件中添加如下命令行参数:
args:
......
# 使用 dns 验证方式
- --certificatesResolvers.ali.acme.dnsChallenge.provider=alidns
# 邮箱配置
- --certificatesResolvers.ali.acme.email=ych_1024@163.com
# 保存 ACME 证书的位置
- --certificatesResolvers.ali.acme.storage=/etc/acme/acme.json
ACME 有多种校验方式 tlsChallenge、httpChallenge 和 dnsChallenge 三种验证方式,之前更常用的是 http 这种验证方式,关于这几种验证方式的使用可以查看文档:https://www.qikqiak.com/traefik-book/https/acme/ 了解他们之间的区别。要使用 tls 校验方式的话需要保证 Traefik 的 443 端口是可达的,dns 校验方式可以生成通配符的证书,只需要配置上 DNS 解析服务商的 API 访问密钥即可校验。我们这里用 DNS 校验的方式来为大家说明如何配置 ACME。
上面我们通过设置 --certificatesResolvers.ali.acme.dnsChallenge.provider=alidns 参数来指定指定阿里云的 DNS 校验,要使用阿里云的 DNS 校验我们还需要配置3个环境变量:ALICLOUD_ACCESS_KEY、ALICLOUD_SECRET_KEY、ALICLOUD_REGION_ID,分别对应我们平时开发阿里云应用的时候的密钥,可以登录阿里云后台获取,由于这是比较私密的信息,所以我们用 Secret 对象来创建:
$ kubectl create secret generic traefik-alidns-secret --from-literal=ALICLOUD_ACCESS_KEY=<aliyun ak> --from-literal=ALICLOUD_SECRET_KEY=<aliyun sk>--from-literal=ALICLOUD_REGION_ID=cn-beijing -n kube-system
创建完成后将这个 Secret 通过环境变量配置到 Traefik 的应用中。还有一个值得注意的是验证通过的证书我们这里存到 /etc/acme/acme.json 文件中,我们一定要将这个文件持久化,否则每次 Traefik 重建后就需要重新认证,而 Let’s Encrypt 本身校验次数是有限制的。最后我们这里完整的 Traefik 的配置资源清单如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: traefik
namespace: kube-system
labels:
app: traefik
spec:
selector:
matchLabels:
app: traefik
template:
metadata:
labels:
app: traefik
spec:
serviceAccountName: traefik
terminationGracePeriodSeconds: 60
tolerations:
- operator: "Exists"
nodeSelector:
kubernetes.io/hostname: ydzs-master
volumes:
- name: acme
hostPath:
path: /data/k8s/traefik/acme
containers:
- image: traefik:2.1.1
name: traefik
ports:
- name: web
containerPort: 80
hostPort: 80
- name: websecure
containerPort: 443
hostPort: 443
args:
- --entryPoints.web.address=:80
- --entryPoints.websecure.address=:443
- --api=true
- --api.dashboard=true
- --ping=true
- --providers.kubernetesingress
- --providers.kubernetescrd
- --log.level=INFO
- --accesslog
# 使用 dns 验证方式
- --certificatesResolvers.ali.acme.dnsChallenge.provider=alidns
# 邮箱配置
- --certificatesResolvers.ali.acme.email=ych_1024@163.com
# 保存 ACME 证书的位置
- --certificatesResolvers.ali.acme.storage=/etc/acme/acme.json
# 下面是用于测试的ca服务,如果https证书生成成功了,则移除下面参数
# - --certificatesresolvers.ali.acme.caserver=https://acme-staging-v02.api.letsencrypt.org/directory
envFrom:
- secretRef:
name: traefik-alidns-secret
# ALICLOUD_ACCESS_KEY
# ALICLOUD_SECRET_KEY
# ALICLOUD_REGION_ID
volumeMounts:
- name: acme
mountPath: /etc/acme
resources:
requests:
cpu: "50m"
memory: "50Mi"
limits:
cpu: "200m"
memory: "100Mi"
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
readinessProbe:
httpGet:
path: /ping
port: 8080
failureThreshold: 1
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /ping
port: 8080
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
直接更新 Traefik 应用即可。更新完成后现在我们来修改上面我们的 whoami 应用:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: ingressroutetls
spec:
entryPoints:
- websecure
routes:
- match: Host(`who.qikqiak.com`) && PathPrefix(`/tls`)
kind: Rule
services:
- name: whoami
port: 80
tls:
certResolver: ali
domains:
- main: "*.qikqiak.com"
其他的都不变,只需要将 tls 部分改成我们定义的 ali 这个证书解析器,如果我们想要生成一个通配符的域名证书的话可以定义 domains 参数来指定,然后更新 IngressRoute 对象,这个时候我们再去用 HTTPS 访问我们的应用(当然需要将域名在阿里云 DNS 上做解析):
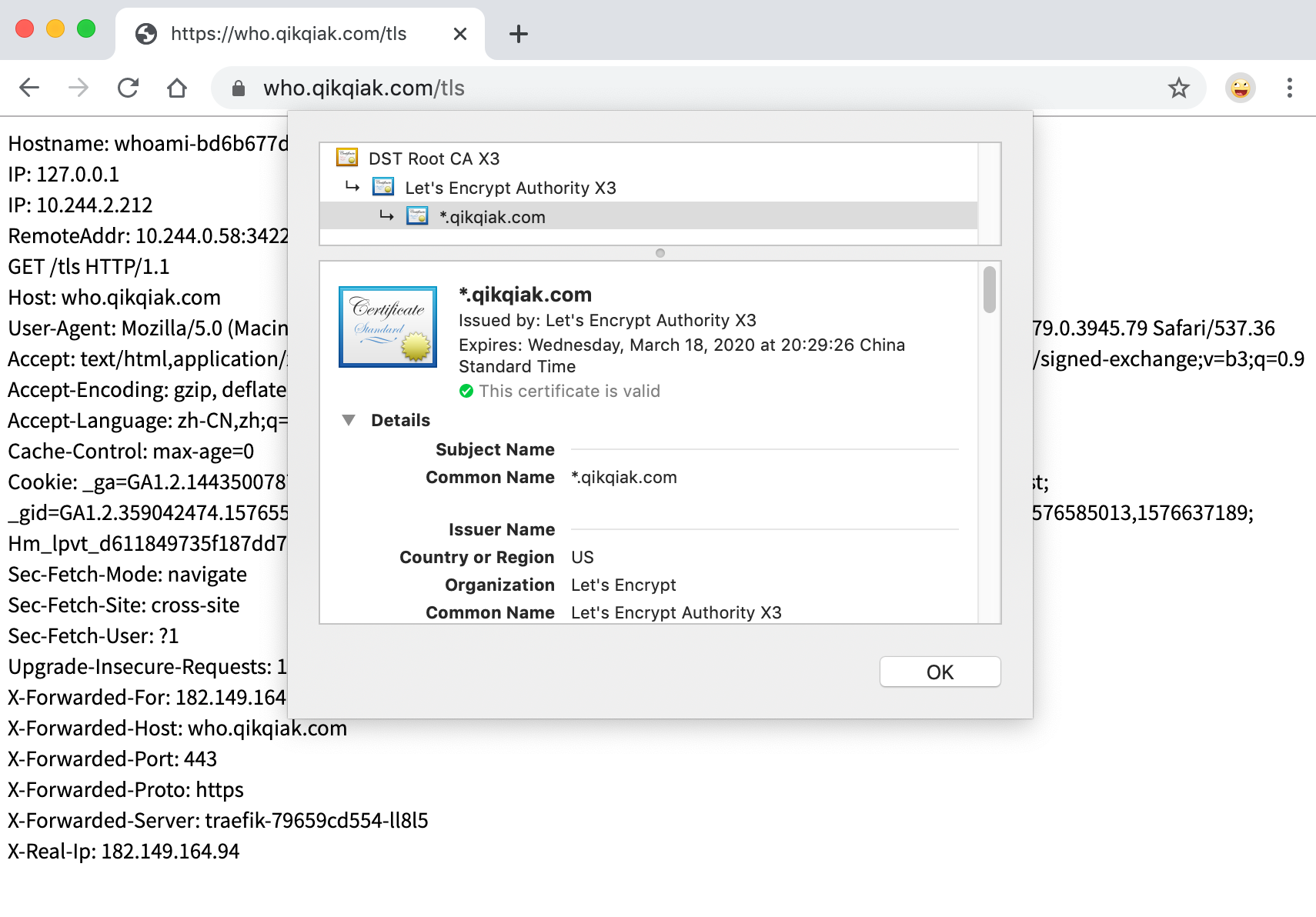
我们可以看到访问应用已经是受浏览器信任的证书了,查看证书我们还可以发现该证书是一个通配符的证书。
中间件
中间件是 Traefik2.0 中一个非常有特色的功能,我们可以根据自己的各种需求去选择不同的中间件来满足服务,Traefik 官方已经内置了许多不同功能的中间件,其中一些可以修改请求,头信息,一些负责重定向,一些添加身份验证等等,而且中间件还可以通过链式组合的方式来适用各种情况。
同样比如上面我们定义的 whoami 这个应用,我们可以通过 https://who.qikqiak.com/tls 来访问到应用,但是如果我们用 http 来访问的话呢就不行了,就会404了,因为我们根本就没有简单80端口这个入口点,所以要想通过 http 来访问应用的话自然我们需要监听下 web 这个入口点:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: ingressroutetls-http
spec:
entryPoints:
- web
routes:
- match: Host(`who.qikqiak.com`) && PathPrefix(`/tls`)
kind: Rule
services:
- name: whoami
port: 80
注意这里我们创建的 IngressRoute 的 entryPoints 是 web,然后创建这个对象,这个时候我们就可以通过 http 访问到这个应用了。
但是我们如果只希望用户通过 https 来访问应用的话呢?按照以前的知识,我们是不是可以让 http 强制跳转到 https 服务去,对的,在 Traefik 中也是可以配置强制跳转的,只是这个功能现在是通过中间件来提供的了。如下所示,我们使用 redirectScheme 中间件来创建提供强制跳转服务:
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: redirect-https
spec:
redirectScheme:
scheme: https
然后将这个中间件附加到 http 的服务上面去,因为 https 的不需要跳转:
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: ingressroutetls-http
spec:
entryPoints:
- web
routes:
- match: Host(`who.qikqiak.com`) && PathPrefix(`/tls`)
kind: Rule
services:
- name: whoami
port: 80
middlewares:
- name: redirect-https
这个时候我们再去访问 http 服务可以发现就会自动跳转到 https 去了。关于更多中间件的用法可以查看文档 Traefik Docs。
灰度发布
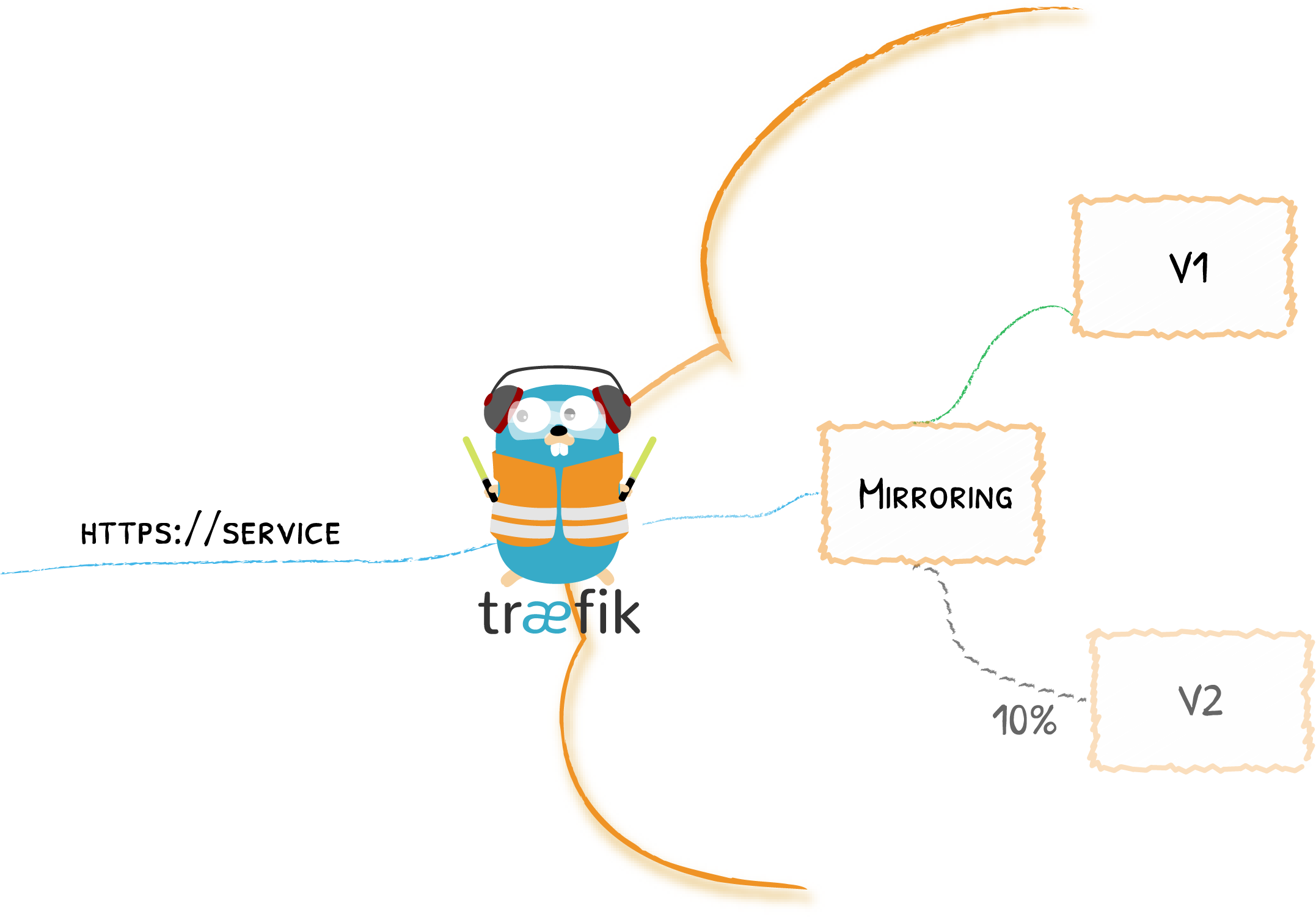
Traefik2.0 的一个更强大的功能就是灰度发布,灰度发布我们有时候也会称为金丝雀发布(Canary),主要就是让一部分测试的服务也参与到线上去,经过测试观察看是否符号上线要求。
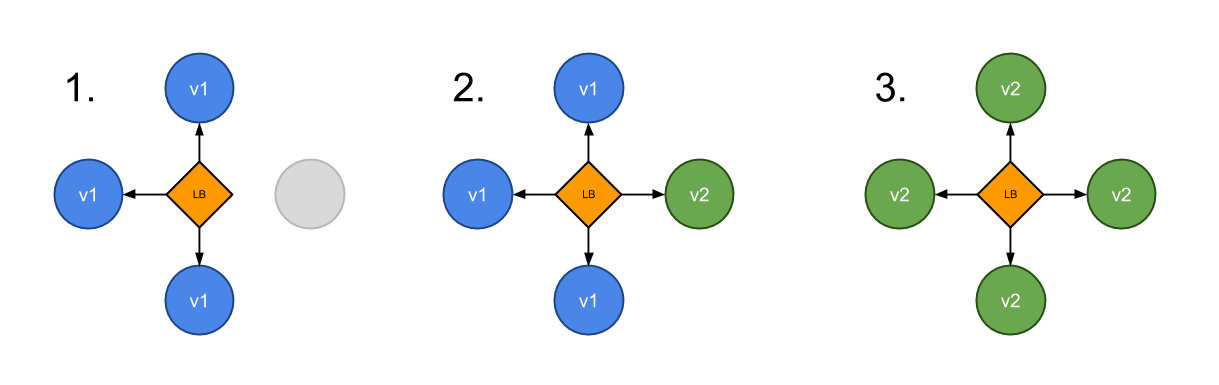
比如现在我们有两个名为 appv1 和 appv2 的服务,我们希望通过 Traefik 来控制我们的流量,将 3⁄4 的流量路由到 appv1,¼ 的流量路由到 appv2 去,这个时候就可以利用 Traefik2.0 中提供的带权重的轮询(WRR)来实现该功能,首先在 Kubernetes 集群中部署上面的两个服务。为了对比结果我们这里提供的两个服务一个是 whoami,一个是 nginx,方便测试。
appv1 服务的资源清单如下所示:(appv1.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: appv1
spec:
selector:
matchLabels:
app: appv1
template:
metadata:
labels:
use: test
app: appv1
spec:
containers:
- name: whoami
image: containous/whoami
ports:
- containerPort: 80
name: portv1
---
apiVersion: v1
kind: Service
metadata:
name: appv1
spec:
selector:
app: appv1
ports:
- name: http
port: 80
targetPort: portv1
appv2 服务的资源清单如下所示:(appv2.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: appv2
spec:
selector:
matchLabels:
app: appv2
template:
metadata:
labels:
use: test
app: appv2
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: portv2
---
apiVersion: v1
kind: Service
metadata:
name: appv2
spec:
selector:
app: appv2
ports:
- name: http
port: 80
targetPort: portv2
直接创建上面两个服务:
$ kubectl apply -f appv1.yaml
$ kubectl apply -f appv2.yaml
# 通过下面的命令可以查看服务是否运行成功
$ kubectl get pods -l use=test
NAME READY STATUS RESTARTS AGE
appv1-58f856c665-shm9j 1/1 Running 0 12s
appv2-ff5db55cf-qjtrf 1/1 Running 0 12s
在 Traefik2.1 中新增了一个 TraefikService 的 CRD 资源,我们可以直接利用这个对象来配置 WRR,之前的版本需要通过 File Provider,比较麻烦,新建一个描述 WRR 的资源清单:(wrr.yaml)
apiVersion: traefik.containo.us/v1alpha1
kind: TraefikService
metadata:
name: app-wrr
spec:
weighted:
services:
- name: appv1
weight: 3 # 定义权重
port: 80
kind: Service # 可选,默认就是 Service
- name: appv2
weight: 1
port: 80
然后为我们的灰度发布的服务创建一个 IngressRoute 资源对象:(ingressroute.yaml)
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: wrringressroute
namespace: default
spec:
entryPoints:
- web
routes:
- match: Host(`wrr.qikqiak.com`)
kind: Rule
services:
- name: app-wrr
kind: TraefikService
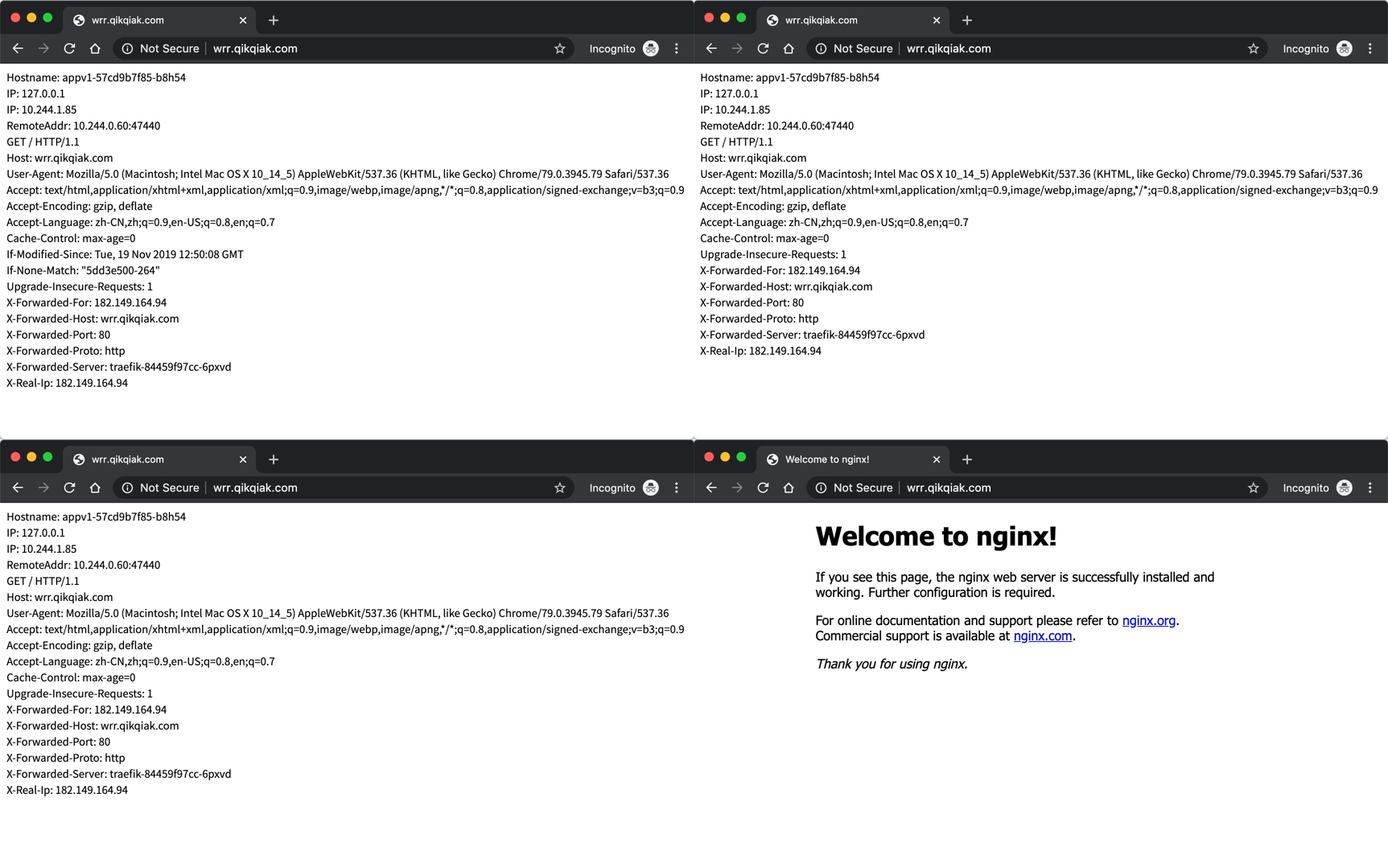
不过需要注意的是现在我们配置的 Service 不再是直接的 Kubernetes 对象了,而是上面我们定义的 TraefikService 对象,直接创建上面的两个资源对象,这个时候我们对域名 wrr.qikqiak.com 做上解析,去浏览器中连续访问 4 次,我们可以观察到 appv1 这应用会收到 3 次请求,而 appv2 这个应用只收到 1 次请求,符合上面我们的 3:1 的权重配置。
流量复制
除了灰度发布之外,Traefik 2.0 还引入了流量镜像服务,是一种可以将流入流量复制并同时将其发送给其他服务的方法,镜像服务可以获得给定百分比的请求同时也会忽略这部分请求的响应。
同样的在 2.0 中只能通过 FileProvider 进行配置,在 2.1 版本中我们已经可以通过 TraefikService 资源对象来进行配置了,现在我们部署两个 whoami 的服务,资源清单文件如下所示:
apiVersion: v1
kind: Service
metadata:
name: v1
spec:
ports:
- protocol: TCP
name: web
port: 80
selector:
app: v1
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: v1
labels:
app: v1
spec:
selector:
matchLabels:
app: v1
template:
metadata:
labels:
app: v1
spec:
containers:
- name: v1
image: nginx
ports:
- name: web
containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: v2
spec:
ports:
- protocol: TCP
name: web
port: 80
selector:
app: v2
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: v2
labels:
app: v2
spec:
selector:
matchLabels:
app: v2
template:
metadata:
labels:
app: v2
spec:
containers:
- name: v2
image: nginx
ports:
- name: web
containerPort: 80
直接创建上面的资源对象:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
v1-77cfb86999-wfbl2 1/1 Running 0 94s
v2-6f45d498b7-g6qjt 1/1 Running 0 91s
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
v1 ClusterIP 10.96.218.173 <none> 80/TCP 99s
v2 ClusterIP 10.99.98.48 <none> 80/TCP 96s
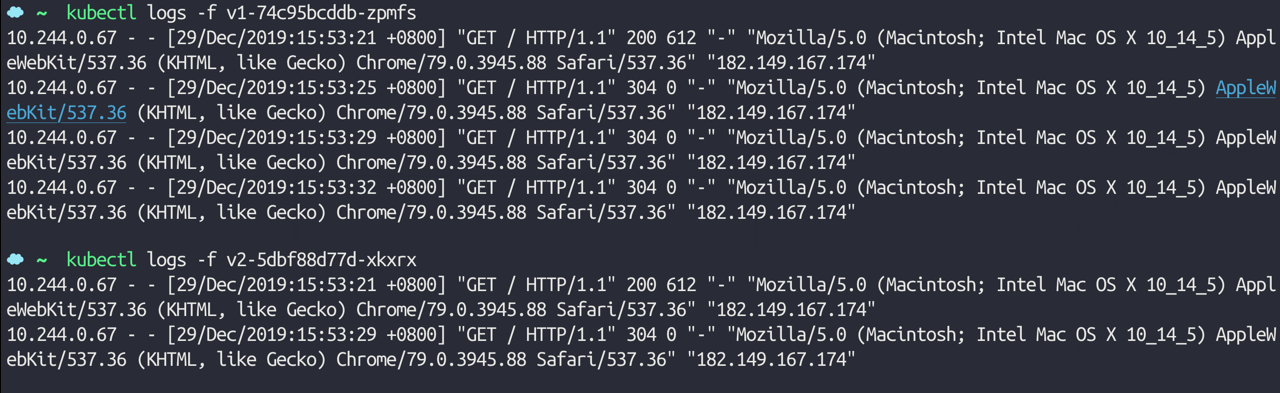
现在我们创建一个 IngressRoute 对象,将服务 v1 的流量复制 50% 到服务 v2,如下资源对象所示:(mirror-ingress-route.yaml)
apiVersion: traefik.containo.us/v1alpha1
kind: TraefikService
metadata:
name: app-mirror
spec:
mirroring:
name: v1 # 发送 100% 的请求到 K8S 的 Service "v1"
port: 80
mirrors:
- name: v2 # 然后复制 50% 的请求到 v2
percent: 50
port: 80
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: mirror-ingress-route
namespace: default
spec:
entryPoints:
- web
routes:
- match: Host(`mirror.qikqiak.com`)
kind: Rule
services:
- name: app-mirror
kind: TraefikService # 使用声明的 TraefikService 服务,而不是 K8S 的 Service
然后直接创建这个资源对象即可:
$ kubectl apply -f mirror-ingress-route.yaml
ingressroute.traefik.containo.us/mirror-ingress-route created
traefikservice.traefik.containo.us/mirroring-example created
这个时候我们在浏览器中去连续访问4次 mirror.qikqiak.com 可以发现有一半的请求也出现在了 v2 这个服务中:
TCP
另外 Traefik2.0 已经支持了 TCP 服务的,下面我们以 mongo 为例来了解下 Traefik 是如何支持 TCP 服务得。
简单 TCP 服务
首先部署一个普通的 mongo 服务,资源清单文件如下所示:(mongo.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongo-traefik
labels:
app: mongo-traefik
spec:
selector:
matchLabels:
app: mongo-traefik
template:
metadata:
labels:
app: mongo-traefik
spec:
containers:
- name: mongo
image: mongo:4.0
ports:
- containerPort: 27017
---
apiVersion: v1
kind: Service
metadata:
name: mongo-traefik
spec:
selector:
app: mongo-traefik
ports:
- port: 27017
直接创建 mongo 应用:
$ kubectl apply -f mongo.yaml
deployment.apps/mongo-traefik created
service/mongo-traefik created
创建成功后就可以来为 mongo 服务配置一个路由了。由于 Traefik 中使用 TCP 路由配置需要 SNI,而 SNI 又是依赖 TLS 的,所以我们需要配置证书才行,如果没有证书的话,我们可以使用通配符 * 进行配置,我们这里创建一个 IngressRouteTCP 类型的 CRD 对象(前面我们就已经安装了对应的 CRD 资源):(mongo-ingressroute-tcp.yaml)
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRouteTCP
metadata:
name: mongo-traefik-tcp
spec:
entryPoints:
- mongo
routes:
- match: HostSNI(`*`)
services:
- name: mongo-traefik
port: 27107
要注意的是这里的 entryPoints 部分,是根据我们启动的 Traefik 的静态配置中的 entryPoints 来决定的,我们当然可以使用前面我们定义得 80 和 443 这两个入口点,但是也可以可以自己添加一个用于 mongo 服务的专门入口点:
......
- image: traefik:2.1.1
name: traefik
ports:
- name: web
containerPort: 80
hostPort: 80
- name: websecure
containerPort: 443
hostPort: 443
- name: mongo
hostPort: 27017
containerPort: 27017
args:
- --entryPoints.web.address=:80
- --entryPoints.websecure.address=:443
- --entryPoints.mongo.address=:27017
......
这里给入口点添加 hostPort 是为了能够通过节点的端口访问到服务,关于 entryPoints 入口点的更多信息,可以查看文档 entrypoints 了解更多信息。
然后更新 Traefik 后我们就可以直接创建上面的资源对象:
$ mongo-ingressroute-tcp.yaml
ingressroutetcp.traefik.containo.us/mongo-traefik-tcp created
创建完成后,同样我们可以去 Traefik 的 Dashboard 页面上查看是否生效:
然后我们配置一个域名 mongo.local 解析到 Traefik 所在的节点,然后通过 27017 端口来连接 mongo 服务:
$ mongo --host mongo.local --port 27017
mongo(75243,0x1075295c0) malloc: *** malloc_zone_unregister() failed for 0x7fffa56f4000
MongoDB shell version: 2.6.1
connecting to: mongo.local:27017/test
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
到这里我们就完成了将 mongo(TCP)服务暴露给外部用户了。
带 TLS 证书的 TCP
上面我们部署的 mongo 是一个普通的服务,然后用 Traefik 代理的,但是有时候为了安全 mongo 服务本身还会使用 TLS 证书的形式提供服务,下面是用来生成 mongo tls 证书的脚本文件:(generate-certificates.sh)
#!/bin/bash
#
# From https://medium.com/@rajanmaharjan/secure-your-mongodb-connections-ssl-tls-92e2addb3c89
set -eu -o pipefail
DOMAINS="${1}"
CERTS_DIR="${2}"
[ -d "${CERTS_DIR}" ]
CURRENT_DIR="$(cd "$(dirname "${0}")" && pwd -P)"
GENERATION_DIRNAME="$(echo "${DOMAINS}" | cut -d, -f1)"
rm -rf "${CERTS_DIR}/${GENERATION_DIRNAME:?}" "${CERTS_DIR}/certs"
echo "== Checking Requirements..."
command -v go >/dev/null 2>&1 || echo "Golang is required"
command -v minica >/dev/null 2>&1 || go get github.com/jsha/minica >/dev/null
echo "== Generating Certificates for the following domains: ${DOMAINS}..."
cd "${CERTS_DIR}"
minica --ca-cert "${CURRENT_DIR}/minica.pem" --ca-key="${CURRENT_DIR}/minica-key.pem" --domains="${DOMAINS}"
mv "${GENERATION_DIRNAME}" "certs"
cat certs/key.pem certs/cert.pem > certs/mongo.pem
echo "== Certificates Generated in the directory ${CERTS_DIR}/certs"
将上面证书放置到 certs 目录下面,然后我们新建一个 02-tls-mongo 的目录,在该目录下面执行如下命令来生成证书:
$ bash ../certs/generate-certificates.sh mongo.local .
== Checking Requirements...
== Generating Certificates for the following domains: mongo.local...
最后的目录如下所示,在 02-tls-mongo 目录下面会生成包含证书的 certs 目录:
$ tree .
.
├── 01-mongo
│ ├── mongo-ingressroute-tcp.yaml
│ └── mongo.yaml
├── 02-tls-mongo
│ └── certs
│ ├── cert.pem
│ ├── key.pem
│ └── mongo.pem
└── certs
├── generate-certificates.sh
├── minica-key.pem
└── minica.pem
在 02-tls-mongo/certs 目录下面执行如下命令通过 Secret 来包含证书内容:
$ kubectl create secret tls traefik-mongo-certs --cert=cert.pem --key=key.pem
secret/traefik-mongo-certs created
然后重新更新 IngressRouteTCP 对象,增加 TLS 配置:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRouteTCP
metadata:
name: mongo-traefik-tcp
spec:
entryPoints:
- mongo
routes:
- match: HostSNI(`mongo.local`)
services:
- name: mongo-traefik
port: 27017
tls:
secretName: traefik-mongo-certs
同样更新后,现在我们直接去访问应用就会被 hang 住,因为我们没有提供证书:
$ mongo --host mongo.local --port 27017
MongoDB shell version: 2.6.1
connecting to: mongo1.local:27017/test
这个时候我们可以带上证书来进行连接:
$ mongo --host mongo.local --port 27017 --ssl --sslCAFile=../certs/minica.pem --sslPEMKeyFile=./certs/mongo.pem
MongoDB shell version v4.0.3
connecting to: mongodb://mongo.local:27017/
Implicit session: session { "id" : UUID("e7409ef6-8ebe-4c5a-9642-42059bdb477b") }
MongoDB server version: 4.0.14
......
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
可以看到现在就可以连接成功了,这样就完成了一个使用 TLS 证书代理 TCP 服务的功能,这个时候如果我们使用其他的域名去进行连接就会报错了,因为现在我们指定的是特定的 HostSNI:
$ mongo --host mongo.k8s.local --port 27017 --ssl --sslCAFile=../certs/minica.pem --sslPEMKeyFile=./certs/mongo.pem
MongoDB shell version v4.0.3
connecting to: mongodb://mongo.k8s.local:27017/
2019-12-29T15:03:52.424+0800 E NETWORK [js] SSL peer certificate validation failed: Certificate trust failure: CSSMERR_TP_NOT_TRUSTED; connection rejected
2019-12-29T15:03:52.429+0800 E QUERY [js] Error: couldn't connect to server mongo.qikqiak.com:27017, connection attempt failed: SSLHandshakeFailed: SSL peer certificate validation failed: Certificate trust failure: CSSMERR_TP_NOT_TRUSTED; connection rejected :
connect@src/mongo/shell/mongo.js:257:13
@(connect):1:6
exception: connect failed
当然我们也可以使用 ACME 来为我们提供一个合法的证书,这样在连接的使用就不需要指定证书了,如下所示:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRouteTCP
metadata:
name: mongo-traefik-tcp
spec:
entryPoints:
- mongo
routes:
- match: HostSNI(`mongo.qikqiak.com`)
services:
- name: mongo-traefik
port: 27017
tls:
certResolver: ali
domains:
- main: "*.qikqiak.com"
这样当我们连接的时候就只需要如下的命令即可:
$ mongo --host mongo.qikqiak.com --port 27017 --ssl
