

Kubernetes 调度 - 污点和容忍度详解
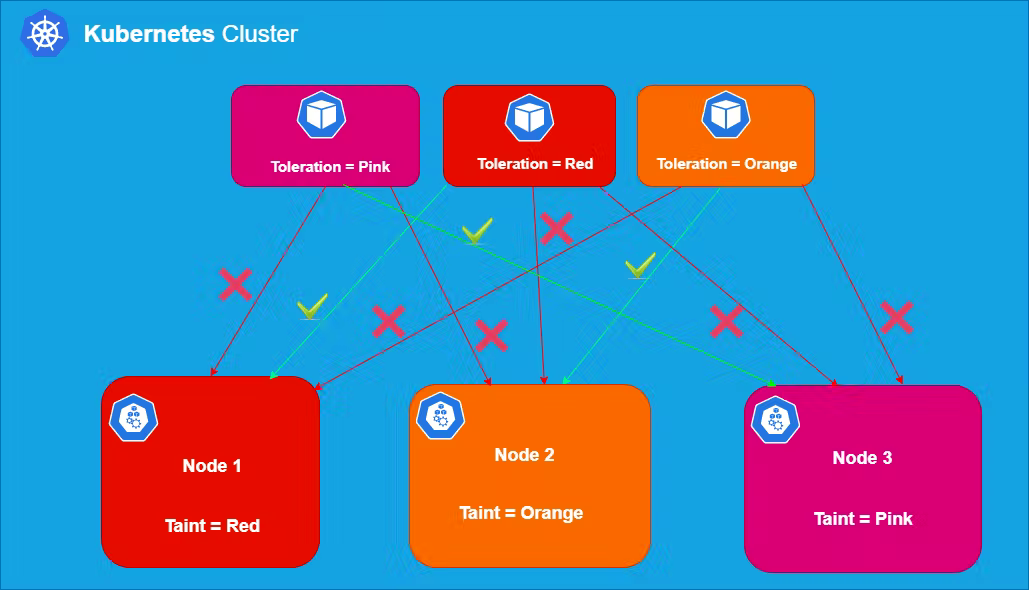
当我们使用节点亲和力(Pod 的一个属性)时,它会将Pod吸引到一组节点(作为偏好或硬性要求)。污点的行为完全相反,它们允许一个节点排斥一组 Pod。
在 Kubernetes 中,您可以标记(污染)一个节点,以便在该节点上不能调度任何 Pod,除非它们应用了明确的容忍度。Tolerations 应用于 Pod,并允许(但不要求)Pod 调度到具有匹配污点的节点上。
污点和容忍度协同工作可确保 Pod 不会被调度到不合适的节点上。
污点语法
常见的污点语法是:
key=value:Effect
可以分配三个不同的值effect:
- NoSchedule:如果至少有一个未被忽略的污点NoSchedule生效,那么 Kubernetes 不会将 pod 调度到该节点上。已经存在的不容忍这种污点的 Pod 不会被从该节点驱逐或删除。但是除非有匹配的容忍度,否则不会在这个节点上安排更多的 Pod。这是一个硬约束。
- PreferNoSchedule:如果至少有一个不可容忍的污点有影响,Kubernetes 将尝试不在节点上调度 Pod 。但是如果有一个 pod 可以容忍一个 taint,它可以被调度。这是一个软约束。
- NoExecute:如果至少有一个未被忽略的NoExecute taint 生效,那么 Pod 将从节点中被逐出(如果它已经在节点上运行),并且不会被调度到节点上(如果它还没有在节点上运行)节点)。这是一个强约束。
可以对单个节点应用多个污点,对单个 Pod 应用多个容忍度。
向节点添加污点
语法:
kubectl taint nodes <node_name> key=value:effect
看看不同节点上已经运行的 pod
root@kube-master:~# kubectl get pods -o wide

在节点上kube-worker2应用污点
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: <none>
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoSchedule
node/kube-worker2 tainted
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: new-taint=taint_demo:NoSchedule
在上面的示例中,在 kube-worker2 node 上应用了一个 taint new-taint=taint_demo:NoSchedule
现在让我们看看正在运行的 pod:
root@kube-master:~# kubectl get pods -o wide

根据NoSchedule约定,已经运行的 pod 不受影响。
现在让我们用同一个节点添加 NoExecute 污点。
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoExecute
node/kube-worker2 tainted
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: new-taint=taint_demo:NoExecute
new-taint=taint_demo:NoSchedule
现在让我们看看正在运行的 pod:
root@kube-master:~# kubectl get pods -o wide
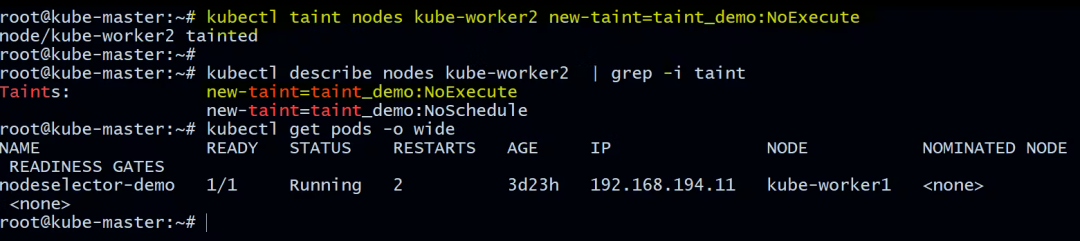
所有不能容忍污点的Pod都被驱逐了。
从节点中移除污点
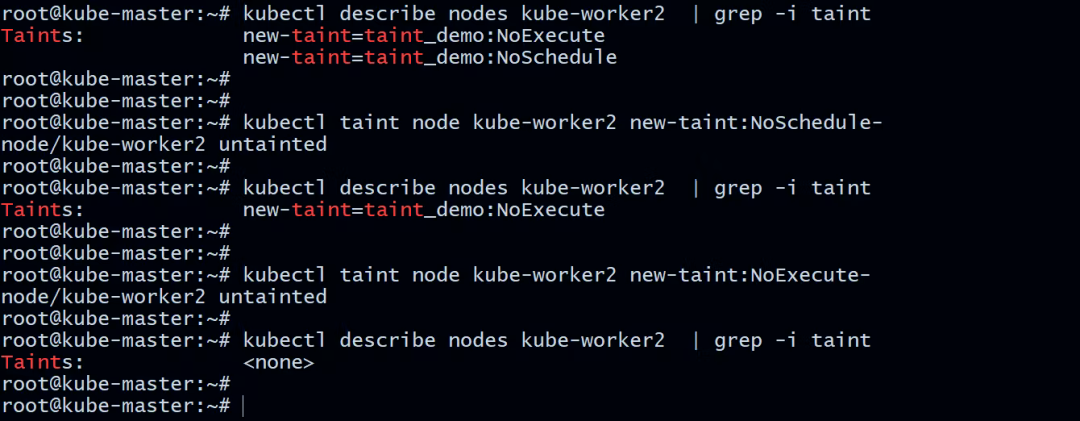
如果您不再需要污点,请运行以下命令将其删除:
root@kube-master:~# kubectl taint node kube-worker2 new-taint:NoSchedule-
node/kube-worker2 untainted
root@kube-master:~# kubectl taint node kube-worker2 new-taint:NoExecute-
node/kube-worker2 untainted
为 Pod 添加容忍度
您可以在PodSpec添加容忍度. 让我们再查看添加NoSchedule污点的节点。
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoSchedule
node/kube-worker2 tainted
部署一个具有污点容忍度的 pod ,这是我们的清单文件:
root@kube-master:~/taint_tolerations# cat toleration.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-toleration-demo
labels:
env: staging
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoSchedule"
Pod 的 toleration 具有 key new-taint、 value true和 effect NoSchedule,这与我们之前在 node 上应用节点kube-worker2上的 taint 相匹配。这意味着这个 pod 现在有资格被调度到节点kube-worker2。但是,这并不能保证这个 Pod 一定被调度,因为我们没有指定任何node affinity或者nodeSelector。
operator的默认值为Equal。(如果键相同且值相同,则容忍匹配污点)
运算符是Exists(这种情况下不应指定任何值)
应用 Pod 清单文件
root@kube-master:~/taint_tolerations# kubectl apply -f toleration.yaml
pod/nginx-toleration-demo created
验证 Pod 在哪个节点上运行
root@kube-master:~/taint_tolerations# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-toleration-demo 1/1 Running 0 7s 192.168.161.196 kube-worker2 <none> <none>
nodeselector-demo 1/1 Running 2 3d23h 192.168.194.11 kube-worker1 <none> <none>
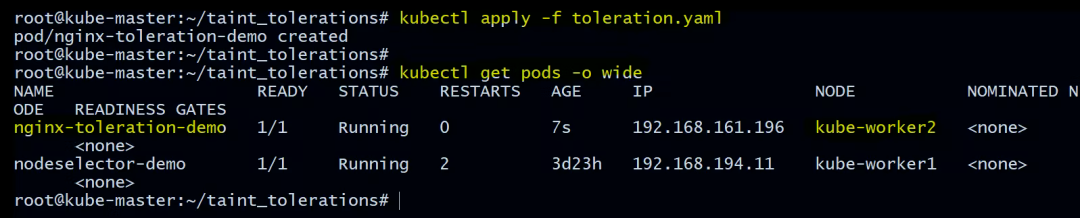
您可以在上面看到nginx-toleration-demo 被调度到 kube-worker2。
一个节点可以有多个污点,而 pod 可以有多个容忍度。Kubernetes 处理多个 taints 和 toleration 的方式就像一个过滤器:从节点的所有 taint 开始,然后忽略 pod 具有匹配 toleration 的那些;剩余的未被忽略的污点对 pod 有特定的影响。
关于容忍度的重要说明
- 如果至少有一个未被忽略的NoSchedule taint 生效,那么 Kubernetes 将不会把 pod 调度到该节点上。
- 如果没有未忽略的 NoSchedule taint 生效,但至少有一个未忽略的PreferNoSchedule taint 生效,则 Kubernetes 将尝试不把 pod 调度到节点上。
- 如果至少有一个未被忽略的NoExecute taint 生效,那么 pod 将从节点中被逐出(如果它已经在节点上运行),并且不会被调度到节点上(如果它还没有在节点上运行) )。
让我们举个例子:
我已经污染了的节点
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoExecute
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoSchedule
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint2=taint_demo2:NoSchedule
验证应用的污点
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: new-taint=taint_demo:NoExecute
new-taint=taint_demo:NoSchedule
new-taint2=taint_demo2:NoSchedule
Pod 清单文件
root@kube-master:~/taint_tolerations# cat toleration-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-toleration-demo
labels:
env: staging
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoSchedule"
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoExecute"
在这种情况下,pod 将无法调度到节点上,因为没有与第三个 taint 匹配的容忍度。但是如果在添加 taint 的时候已经在 node 上运行,它就可以继续运行,因为第三个 taint 是 Pod 不能容忍的三个 taint 中唯一的一个。
实际上任何不容忍NoExecute taint 的 pod 都将被立即驱逐,而能够容忍 taint 的 pod 将永远不会被驱逐。但是可以指定一个可选tolerationSeconds字段,该字段指示在添加污点后 pod 将保持绑定到节点的时间。例如:
tolerations:
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoExecute"
tolerationSeconds: 3600
这意味着如果这个 pod 正在运行并且又一个匹配的 taint 被添加到该节点,那么该 pod 将保持绑定到该节点 3600 秒,然后被驱逐。如果在该时间之前移除了 taint,则 pod 不会被驱逐。
污点和容忍应用场景总结
- 专用节点:当您想将一组节点专用于专有工作负载或特定用户时,您可以向这些节点添加一个污点(例如kubectl taint nodes nodename dedicated=groupName:NoSchedule),然后向它们的 pod 添加相应的容忍度。
- 具有特殊硬件的节点:对于具有专用硬件(例如 GPU)的节点,我们只希望具有这些要求的 pod 在这些节点上运行。污染将帮助我们(例如kubectl taint nodes nodename special=true:NoScheduleor kubectl taint nodes nodename special=true:PreferNoSchedule)并为使用特殊硬件的 pod 添加相应的容忍度。
- 基于污点的驱逐:当节点存在问题时,每个 pod 可配置的驱逐行为。当某些条件为真时,节点控制器会自动污染节点。
如下是k8s给出内置污点:
- node.kubernetes.io/not-ready:节点没有准备好。
- node.kubernetes.io/unreachable:无法从节点控制器访问节点。准备就绪时NodeCondition为“未知”。
- node.kubernetes.io/memory-pressure:节点有内存压力。
- node.kubernetes.io/disk-pressure:节点有磁盘压力。
- node.kubernetes.io/pid-pressure:节点有 PID 压力。
- node.kubernetes.io/network-unavailable:节点的网络不可用。
- node.kubernetes.io/unschedulable:节点不可调度。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
2021-04-25 k8s安装常用软件的yaml文件
2021-04-25 yaml文件执行后常见错误解决
2021-04-25 动态存储管理实战:GlusterFS
2021-04-25 Kubernetes角色访问控制RBAC和权限规则(Role+ClusterRole)