

修复 Elasticsearch 集群的常见错误和问题
文章转载自:https://mp.weixin.qq.com/s/8nWV5b8bJyTLqSv62JdcAw
第一篇:Elasticsearch 磁盘使用率超过警戒水位线
从磁盘常见错误说下去
当客户端向 Elasticsearch 写入文档时候报错:
cluster_block_exception [FORBIDDEN/12/index read-only / allow delete (api)];
在 elasticsearch 的日志文件中报错如下:
flood stage disk watermark [95%] exceeded ... all indices on this node will marked read-only
出现如上问题多半是:磁盘使用量超过警戒水位线,索引存在 read-only-allow-delete 索引块数据。
报错释义
基础认知:磁盘三个警戒水位线:

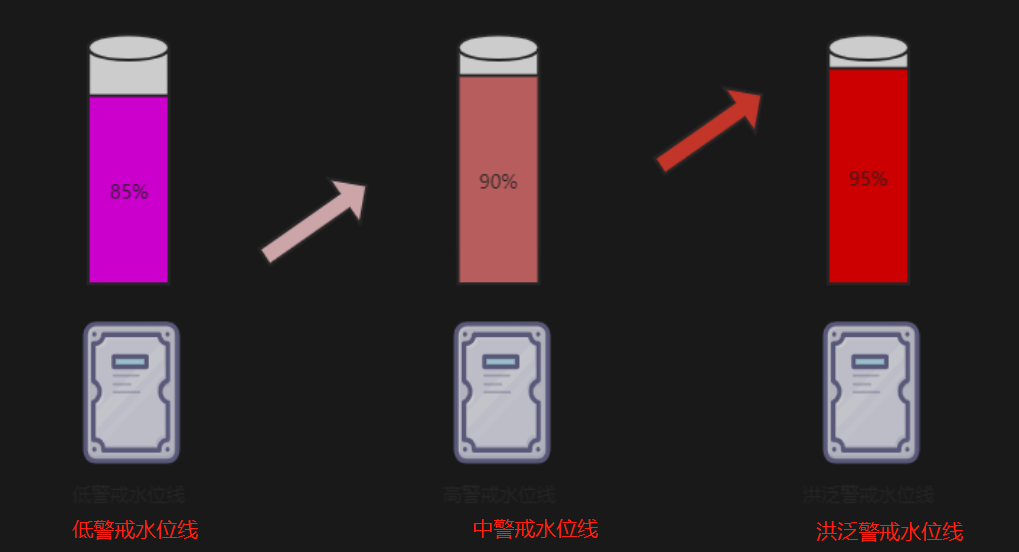
报错表明数据节点的磁盘空间严重不足,并且已达到磁盘洪泛警戒水位线(磁盘使用率95%+,洪水泛滥的意思)。
为防止磁盘变满,当节点达到洪泛警戒水位线时,Elasticsearch 会阻止向该节点的任何索引分片写入数据,如果该数据块影响到相关的系统索引,可能会导致 Kibana 或者其他 Elastic Stack 功能不可用。
修复指南
cat shards 验证分片分配
要验证分片是否正在移出受影响的节点,请使用 cat shards API。
GET _cat/shards?v=true
explain 验证分配细节
如果分片仍然保留在节点上,请使用集群 allocation/explain API 获取其分配状态的说明。
GET _cluster/allocation/explain
{
"index": "my-index",
"shard": 0,
"primary": false,
"current_node": "my-node"
}
如上 API几个参数解释如下:
- index: 对应索引。
- shard:分片号。
- primary:是否主分片。
- current_node: 节点名称。
四个参数需要结合业务实际进行修改。
恢复写入,可以上调磁盘警戒水位线。
要立即恢复写入操作,你可以暂时上调磁盘警戒水位并移除写入块。
如下命令行是集群层面更新设置的操作。
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.routing.allocation.disk.watermark.flood_stage": "97%"
}
}
索引块的五种不同状态如下:
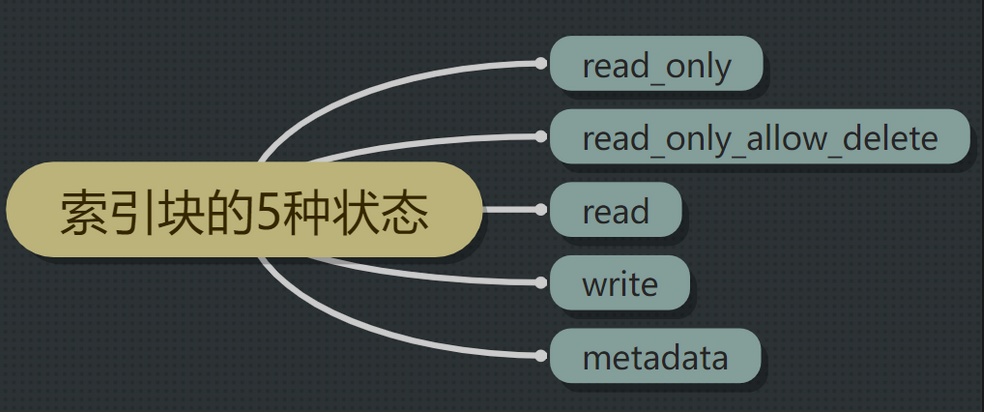
- 状态一:index.blocks.read_only
设置为 "true"可以使索引和索引元数据只读,"false "可以允许写入和元数据改变。
- 状态二:index.blocks.read_only_allow_delete
类似于index.blocks.read_only,但也允许删除索引释放磁盘资源。
基于磁盘的分片分配器(The disk-based shard allocator)可以自动添加和删除index.blocks.read_only属性的数据块。
这里依然会引申出删除索引文档和删除索引本身的区别等知识点:
(1)删除索引文档会出现删除后磁盘使用率反而增加的现象,因为删除的本质是 version 的 update;只有删除索引才相当于物理删除,会立即释放磁盘空间。
(2)当 index.blocks.read_only_allow_delete 被设置为true时,删除文档是不允许的,仅允许删除索引。
(3)当磁盘使用率达到洪泛警戒水位线 95% 时,Elasitcsearch 会强制所有包含分片数据的索引的数据库设置为:index.blocks.read_only_allow_delete 属性。
(4)当磁盘使用率低于高警戒水位线 90% 时,index.blocks.read_only_allow_delete 属性会自动释放。
- 状态三:index.blocks.read
设置为 "true",代表禁止对索引进行读操作。
- 状态四:index.blocks.write
设置为 "true "代表禁止对索引的数据写入操作。
与read_only不同,这个设置并不影响元数据。例如,你可以用一个 write 块关闭一个索引,但是你不能用一个 read_only 块关闭一个索引。
- 状态五:index.blocks.metadata
设置为 "true "代表禁用索引元数据的读写。
所以,如下的设置本质上是破除磁盘洪泛警戒水位线 95% 的 index.blocks.read_only_allow_delete 的限制,让索引继续可以写入数据。
个人评价:应急可以用。
PUT */_settings?expand_wildcards=all
{
"index.blocks.read_only_allow_delete": null
}
长期解决方案
作为长期解决方案,我们建议您将节点添加到受影响的数据层或升级现有节点实现节点磁盘扩容以增加磁盘空间。
比如:data_hot 热节点爆满,建议:
- 添加新的热节点
- 为已有热节点磁盘扩容。
要释放额外的磁盘空间,你可以使用删除索引 API 删除不需要的索引。DELETE my-index
重置磁盘警戒水位线操作
当长期解决方案到位时,可使用如下命令行重置磁盘警戒水位线。
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": null,
"cluster.routing.allocation.disk.watermark.high": null,
"cluster.routing.allocation.disk.watermark.flood_stage": null
}
}
小结
为避免磁盘使用率吃紧的问题,建议如下:
第一:“不等下雨天之前就修好屋顶”,而不是“下了雨之后应急修补屋顶”。
第二:做好磁盘使用率监控和预警操作。
第三:提前规划设置 total_shards_per_node 参数,以使得各个节点分片分配数相对均衡。
第二篇:Elasitcsearch CPU 使用率突然飙升
Elasticsearch 高CPU 使用率的内涵
Elasticsearch 使用线程池来管理并发操作的 CPU 资源。
Elasticsearch 高 CPU 使用率通常意味着一个或多个线程池不足以支撑业务需求。如果线程池资源耗尽,Elasticsearch 将拒绝与线程池相关的请求。例如,如果搜索线程池(search thread pool)耗尽,Elasticsearch 将拒绝搜索请求,直到有更多线程可用。
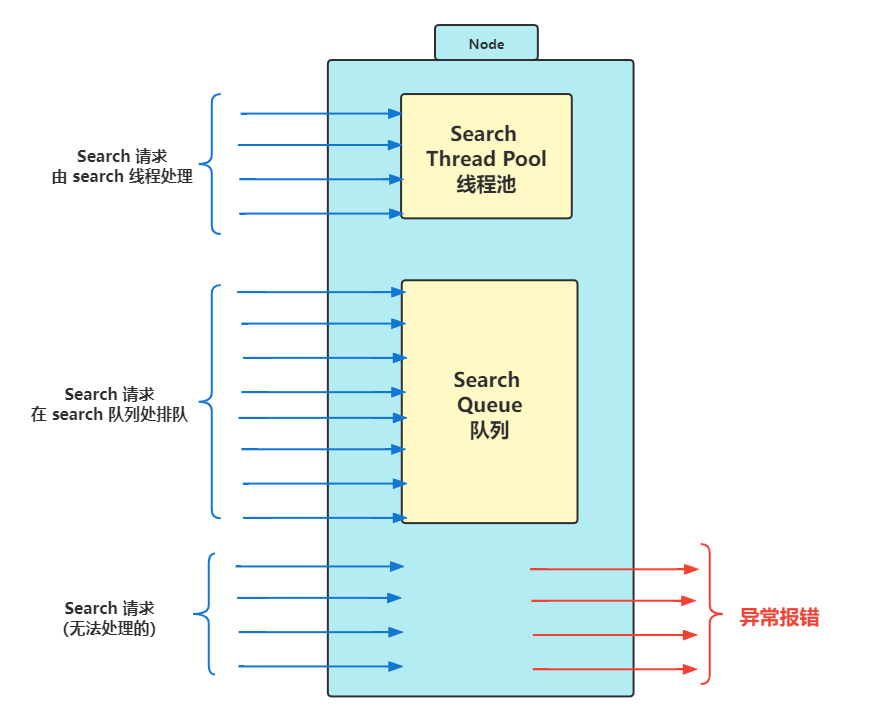
上图更直观的解释了线程池、队列、客户端请求之间的关系,拿检索线程为例:
- 当请求比较少时,线程池完全可以处理过来;
- 当前再多一些时,需要线程池队列排队;
- 如果请求再多,就超出了线程池和队列的最大负载,导致异常报错。
诊断 Elasticsearch 高 CPU 使用率
核查 CPU 使用率
使用 cat nodes API 获取每个节点的当前 CPU 使用率。
GET _cat/nodes?v=true&s=cpu:desc
返回结果:

如上所示,CPU 即为 cpu 使用率,name 为节点的名称。
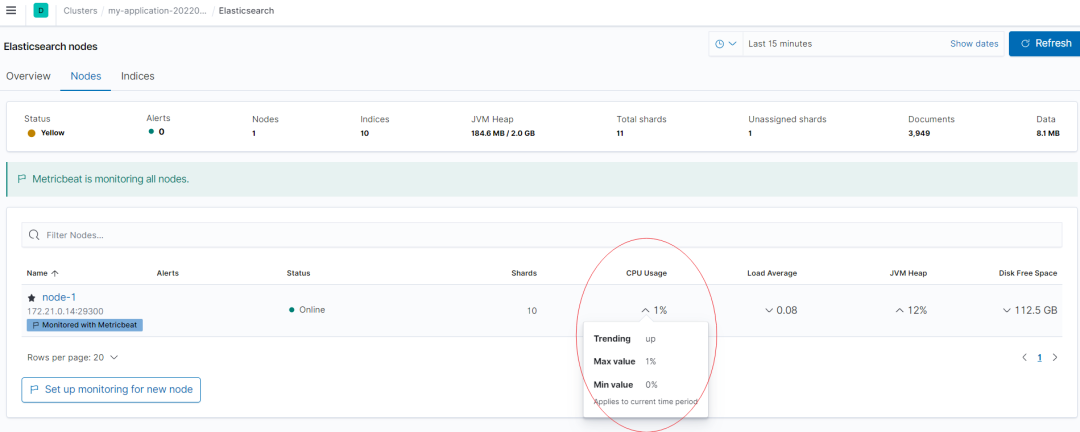
也可以借助 Kibana Stack Monitoring 进行可视化监控,CPU 监控如下红圈所示:
核查热点线程
如果某个节点的 CPU 使用率很高,请使用节点热点线程 API 检查该节点上运行的资源密集型线程。
GET _nodes/my-node,my-other-node/hot_threads
此 API 以纯文本形式返回任何热点线程的细节。
降低 CPU 使用率的实操方案
扩展集群
繁重的数据写入(indexing)和搜索负载会耗尽较小的线程池。为了更好地处理繁重的工作负载,向集群添加更多节点或升级(扩容)现有节点以增加容量。
分散批量请求
批量请求虽然比单个请求效率更高,但大型批量写入或多搜索请求需要大量 CPU 资源。
如果可能,提交较小的请求并在它们之间留出更多时间。
这里的较小有多小?需要结合业务实际、结合线程池和队列大小不断调出最优值。
取消长时间运行的搜索
长时间运行的搜索会阻塞搜索线程池中的线程。
要检查这些搜索,请使用任务管理 API。
GET _tasks?actions=*search&detailed
上述命令行响应的描述包含检索请求及其查询细节,其中:running_time_in_nanos 显示搜索运行了多长时间。
{
"nodes" : {
"oTUltX4IQMOUUVeiohTt8A" : {
"name" : "my-node",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"tasks" : {
"oTUltX4IQMOUUVeiohTt8A:464" : {
"node" : "oTUltX4IQMOUUVeiohTt8A",
"id" : 464,
"type" : "transport",
"action" : "indices:data/read/search",
"description" : "indices[my-index], search_type[QUERY_THEN_FETCH], source[{\"query\":...}]",
"start_time_in_millis" : 4081771730000,
"running_time_in_nanos" : 13991383,
"cancellable" : true
}
}
}
}
}
可以使用 _cancel API 取消任务以释放资源:
POST _tasks/oTUltX4IQMOUUVeiohTt8A:464/_cancel
避免耗费资源的搜索
举例:前缀匹配的 wildcard 查询、多重聚合或分桶设置过大的单重聚合都会非常耗费资源。
避免策略包含但不限于:
- 避免脚本 script 检索。
- 少使用:fuzzy、regexp、prefix、wildcard检索
- 避免将 range 检索应用到 text 和 keyword 类型。
- 避免多表关联 Join 类型。
- 使用 index.max_result_window 索引设置降低大小限制。
- 使用 search.max_buckets 集群设置降低允许的聚合桶的最大数量。
- 使用 search.allow_expensive_queries 集群设置禁用耗费资源的查询。
小结
建议提前做好集群监控和指标预警工作,“防范于未然”,结合节点的 CPU 核数最大化的提升线程池和队列的使用率。
第三篇:Elasticsearch 断路器报错
啥是断路器
断路器(circuit breakers)都指定了它可以使用内存的限制。
Elasticsearch 包含多个断路器,用于防止操作导致内存泄露错误(OutOfMemoryError)。
此外,还有一个父级断路器(parent-level breaker),规定了所有断路器可以使用的内存总量。
如果Elasticsearch估计某项操作会导致内存使用率超过断路器设置的上限,它会停止操作并返回错误。
默认情况下,父级断路器在 JVM 内存使用率达到 95% 时触发。为了防止错误,官方建议在使用率持续超过 85% 的情况下,采取措施减少内存压力。

Elasticsearch 断路器报错示例
客户端请求报 429 错误
如果一个请求触发了一个断路器,Elasticsearch会返回一个错误,其 HTTP 状态代码为429。
{
'error': {
'type': 'circuit_breaking_exception',
'reason': '[parent] Data too large, data for [<http_request>] would be [123848638/118.1mb], which is larger than the limit of [123273216/117.5mb], real usage: [120182112/114.6mb], new bytes reserved: [3666526/3.4mb]',
'bytes_wanted': 123848638,
'bytes_limit': 123273216,
'durability': 'TRANSIENT'
},
'status': 429
}
熟悉Http 协议的同学都知道:在HTTP协议中,响应状态码 429 Too Many Requests 表示在一定的时间内用户发送了太多的请求,即超出了“频次限制”。
日志报错 Data too large
elasticsearch.log 也会记录断路器错误。例如:分片的过程中会触发断路器。
可能的报错如下:
Caused by: org.elasticsearch.common.breaker.CircuitBreakingException: [parent] Data too large, data for [<transport_request>] would be [num/numGB], which is larger than the limit of [num/numGB], usages [request=0/0b, fielddata=num/numKB, in_flight_requests=num/numGB, accounting=num/numGB]
检查JVM的内存使用情况
使用命令行查看 JVM 使用率
使用 cat nodes API 来获得每个节点的当前堆内存使用率 heap.percent。
GET _cat/nodes?v=true&h=name,node*,heap*
返回结果如下:
name id node.role heap.current heap.percent heap.max
node-02 WCwv cdfhilmrstw 287mb 28 990.7mb
要获得每个断路器的 JVM 内存使用量,请使用节点统计 node stats API。
GET _nodes/stats/breaker
返回结果如下:

如何防止断路器出错
降低JVM的内存压力
高的 JVM 内存压力经常导致断路器错误。可能导致 JVM 使用率暴增的原因列举如下:
原因 1:分片大小设置不合理,存在过多小分片。
因为每个分片都会有内存的使用。官方建议分片大小 30GB-50GB之间。
原因 2:复杂的检索或查询操作。
举例:wildcard 查询、设置很大分桶数的聚合操作都是非常“吃”内存的,要避免。
原因 3:存在映射“爆炸”现象
定义太多的字段或将字段嵌套得太深,会导致使用大量内存的映射“爆炸”。
原因 4:存在大型批量请求
大型的批量索引或多重搜索请求会造成 JVM 的内存压力。
原因 5:节点硬件资源受限
物理内存本身就很小,这种是“硬伤”,为避免后患,需要整个团队知悉并想办法协调解决。
避免在 text 类型字段上使用 fielddata
本质原因:需要对 text 字段进行聚合操作,默认 text 是做分词操作的,无法实现聚合和排序,只有 fielddata:true 开启后才可以。
但,开启 fielddate:true 会使用大量的 JVM 内存。为了避免这种情况,建议 Elasticsearch 默认在文本字段上禁用 fielddata。
官方建议:如果你已经启用了 fielddata 并触发了 fielddata 断路器,请考虑禁用它并使用关键字字段 keyword 代替。
清除 fieldata 缓存
如果你已经触发了 fielddata 断路器并且不能禁用 fielddata,需要使用清除缓存 API 来清除 fielddata 缓存。
清理缓存的命令如下:
POST _cache/clear?fielddata=true
第四篇:Elasticsearch JVM 堆内存使用率飙升
症状:高 JVM 内存使用率
高 JVM 内存使用率会降低集群性能并触发断路器错误(导致内存熔断)。
为了防止这种情况发生,如果节点的 JVM 内存使用率持续超过 85%,官方建议采取措施降低内存压力。

诊断 JVM 内存压力
检查 JVM 内存使用情况
借助:node stats API 进行排查。
GET _nodes/stats?filter_path=nodes.*.jvm.mem.pools.old
结果如下:
{
"nodes": {
"J2-fr3wzSqqJk9cwoi2urw": {
"jvm": {
"mem": {
"pools": {
"old": {
"used_in_bytes": 179796016,
"max_in_bytes": 1798569984,
"peak_used_in_bytes": 179796016,
"peak_max_in_bytes": 1798569984
}
}
}
}
}
}
}
堆内存使用率为:used_in_bytes / max_in_bytes = 179796016/ 1798569984 = 9.996%,接近 10%。
能和 kibana 可视化监控结果保持一致:

垃圾回收日志检查
随着内存使用量的增加,垃圾收集变得更加频繁并且需要更长的时间。
你可以在 elasticsearch.log 中跟踪垃圾收集事件的频率和时长。
例如,以下事件表明 Elasticsearch 在过去 40 秒中花费了超过 50%(21 秒)执行垃圾收集。
[timestamp_short_interval_from_last][INFO ][o.e.m.j.JvmGcMonitorService] [node_id] [gc][number] overhead, spent [21s] collecting in the last [40s]
降低JVM 堆内存使用率方案
减少分片数
关于分片的几点认知:
第一:搜索请求是以分片为单位发起的。
至少 7.16 版本之前是,如下图示更能说明问题。
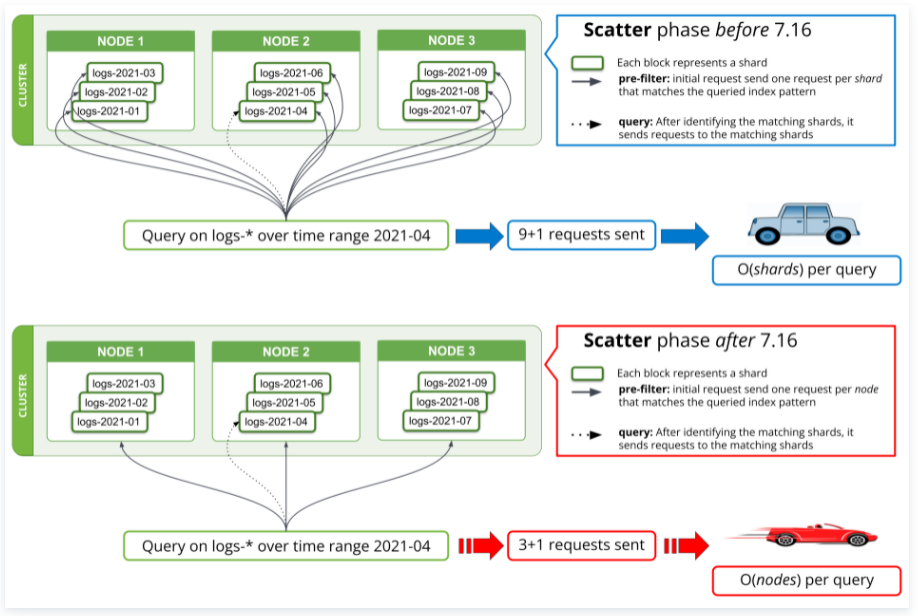
这暗示了什么?
必然是:分片越多,检索越慢。
因为:跨大量分片的搜索可能会耗尽节点的搜索线程池,这可能导致吞吐量低和搜索速度慢。
第二:每个索引和分片都有内存和 CPU 开销。
每个索引和每个分片都需要一些内存和 CPU 资源。
在大多数情况下,一小组大分片比许多小分片使用更少的资源。
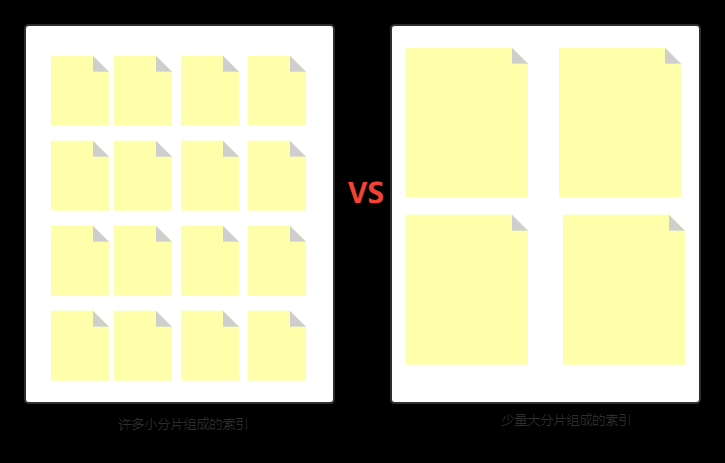
为什么呢?解释一下:
分片的底层是 Lucene 分段。
段的元数据会保留在 JVM 堆内存中,以便快速检索。
分片越多,意味着分段会越多,进而分段元数据会越多,JVM 堆内存使用率会越高。反之,则相反。
第三:Elasticsearch 会在相同角色的节点间平衡分片。
节点角色划分是 7.x 高版本新的节点定义方式,其目的是:节点用途更明确。
当添加新节点或某节点出故障时,Elasticsearch 会自动在相同角色层的剩余节点之间重新平衡索引的分片。
关于减少分片数,更确切的是如何合理规划分片,官方建议如下:
第一:尽量避免 delete_by_query 删除文档,更好的方案是直接删除索引。
第二:使用 datastrem 和 ILM 索引生命周期管理管理时序数据。
第三:分片大小控制在 10GB-50GB。
第四:控制在每 GB 堆内存 20 个分片以内。也就是说:具有 30GB 堆内存的节点最多应该有 600 个分片。
第五:避免单个节点分片过多、负载过重。如果单个节点包含太多分片,且索引量很大,则该节点可能会出现问题。
可以使用如下命令行加以控制:
PUT my_index_001/_settings
{
"index": {
"routing.allocation.total_shards_per_node": 5
}
}
避免复杂检索
复杂搜索会占用大量的内存空间。建议启用:慢日志进行排查。
导致内存使用率飙升的复杂查询,通常具备如下的特点:
- size 召回值设置的巨大;
- 包含分桶值很大的聚合操作或者聚合嵌套很深;
- 包含极其耗费资源的查询,举例:script 查询、fuzzy 查询、regexp 查询、prefix 查询、wildcard 查询、text 或 keyword 上的 range 查询。
为避免复杂查询,常规措施如下:
- 限制:index.max_result_window 的大小。
PUT _settings
{
"index.max_result_window": 5000
}
- 设置 search.max_buckets cluster 以限制分桶值大小。
PUT _cluster/settings
{
"persistent": {
"search.max_buckets": 20000,
}
}
- 设置 search.allow_expensive_queries 直接禁用耗费资源的查询。
PUT _cluster/settings
{
"persistent": {
"search.allow_expensive_queries": false
}
}
避免 Mapping “爆炸”
定义过多的字段或嵌套过深的字段会导致使用大量内存,出现“Mapping 爆炸" 现象。
为防止“Mapping 爆炸“,使用映射限制设置来限制字段映射的数量。
PUT my_index_001/_settings
{
"index.mapping.total_fields.limit": 100
}
分散批量请求
批量请求虽然比单个请求更有效,但大批量写入(以 bulk 操作为代表)或多搜索请求(以 _msearch 为代表)仍然会产生较高的 JVM 内存压力。
如果可能,提交较小(小是个相对值,需要根据集群性能测算出适合自己集群的经验值)的请求并在它们之间留出更多时间时隔。
升级节点内存
繁重的写入操作和搜索负载过重均会导致高 JVM 内存压力。
为了更好地处理繁重的工作负载,在其他方法都不灵的情况下,可以考虑通过为节点内存扩容以达到升级节点目的。
这是无法之法,这是万能之法。
第五篇:Elasticsearch 出现 “429 rejected” 报错
常见的“429拒绝请求”错误
线上报错描述:
问题 1:“我们目前节点还是有很多 reject 429,用了一些方法,比如增加Thread_pool 好像效果不大,还会load增高。还是很多堆积和reject。现在想咨询一下,是否只能增加服务器节点,如果增加,应该怎么样评估,更加合理?因为没有多余机器来做压测,只能根据现有的监控数据评估,能不能给些建议,重点来看哪些参数?”
问题2:“es集群,写入经常reject 429,同时经常会出现 request retries exceeded max retry timeout [60000] 超时的情况。想问下,一般都有什么办法缓解这种问题。现在数据堆积kafka的很多,消费不过来,会丢失一部分数据。目前节点的thread_pool 是200,调高了部分节点到300,效果不是特别明显。”
如上两个问题都和 “reject 429” 错误紧密结合在一起。
“429 拒绝请求”原因解读
当 Elasticsearch 拒绝请求时,它会停止操作并返回带有 429 响应码的错误。被拒绝的请求通常由以下原因引起:
原因1:线程池资源耗尽。
检索线程池或者写入线程池资源耗尽,会出现:TOO_MANY_REQUESTS 错误消息。
原因2:断路器报错,也就是内存出现熔断现象。
原因3:超过限制的写入压力。
主要原因在于:将文档写入到 Elasticsearch 会以内存和 CPU 负载的形式导致系统负载升高。如果在存在过多频繁的写入操作,集群可能会变得饱和。这可能会对其他操作产生不利影响,例如搜索、集群协调和后台处理。
为了防止这些问题,Elasticsearch 在内部监控索引负载。当负载超过一定限度时,新的请求将会被拒绝。
写入请求最高内存上限 indexing_pressure.memory.limit 设置为堆内存的 10%。
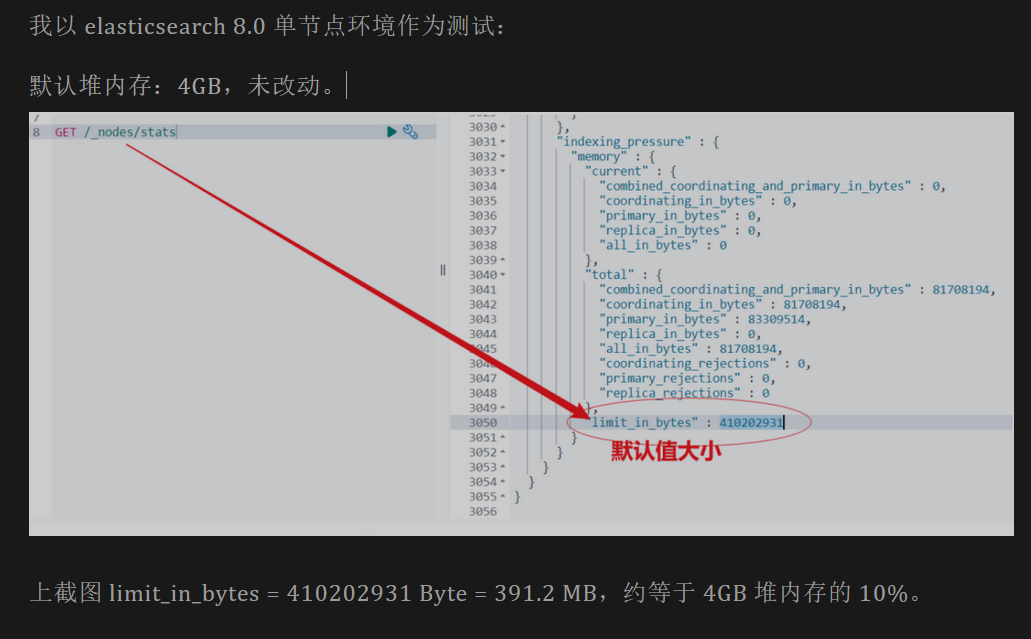
此外, “429 拒绝错误“可以作为衡量是否达到性能瓶颈的依据——做压力测试时可以不断增加并发,观察CPU使用率、磁盘IO使用率,当 Elasticsearch 返回 429 错误码时,可以认为 Elastic 集群达到负载极限。
如何检查 “429 拒绝请求”错误
要检查每个线程池的拒绝任务数,可以使用如下的 cat 线程池 API。被拒绝任务与已完成任务的比例很高,尤其是在搜索和写入线程池中,这意味着 Elasticsearch 会定期拒绝请求。
执行如下命令,可以查看 rejected 拒绝情况。
GET /_cat/thread_pool?v=true&h=id,name,active,rejected,completed
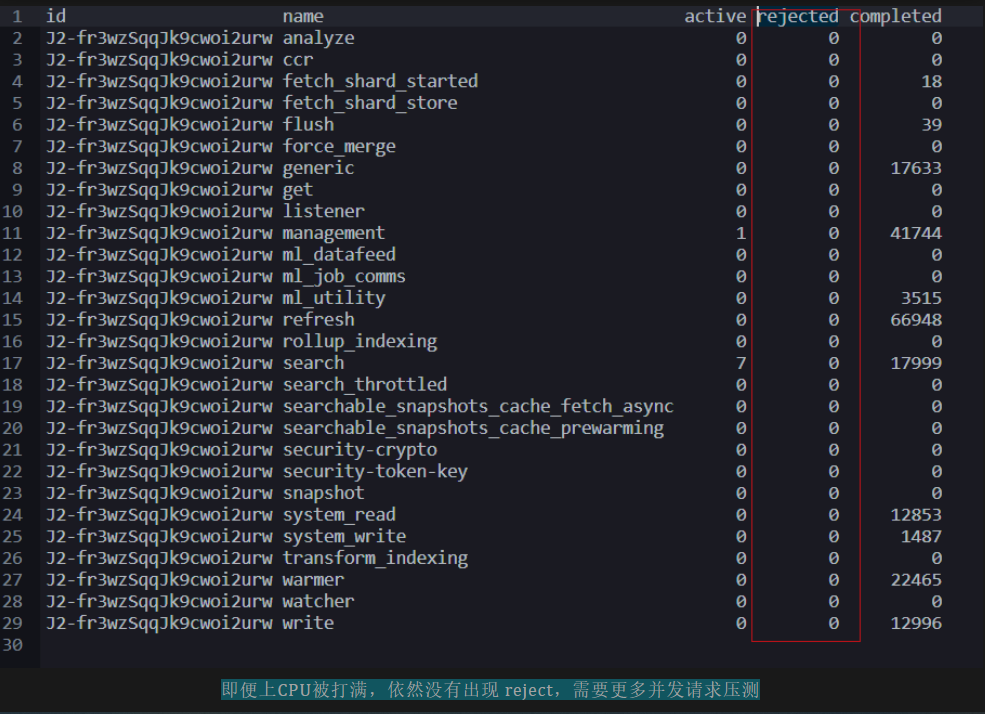
如何阻止或提前预防“429 拒绝请求”错误
方案一:修复高CPU和高内存使用率问题。
如果 Elasticsearch 经常出现拒绝请求,则你所管理集群可能具有高 CPU 使用率或高 JVM 内存压力。
方案二:避免出现内存熔断。
如果你的业务环境经常触发断路器错误或者内存熔断,请参阅断路器错误以获取有关诊断和预防错误的提示。
第六篇:Elasticsearch 集群状态变成黄色或者红色
集群健康状态之红色或黄色含义
红色或黄色集群状态表示一个或多个分片丢失或未分配。这些未分配的分片会增加数据丢失的风险,并会降低集群性能。
集群健康状态诊断
检测集群健康状态
命令行方式
GET _cluster/health?filter_path=status,*_shards

可视化方式 - head 插件可视化

kibana 可视化监控


查看未分配的分片
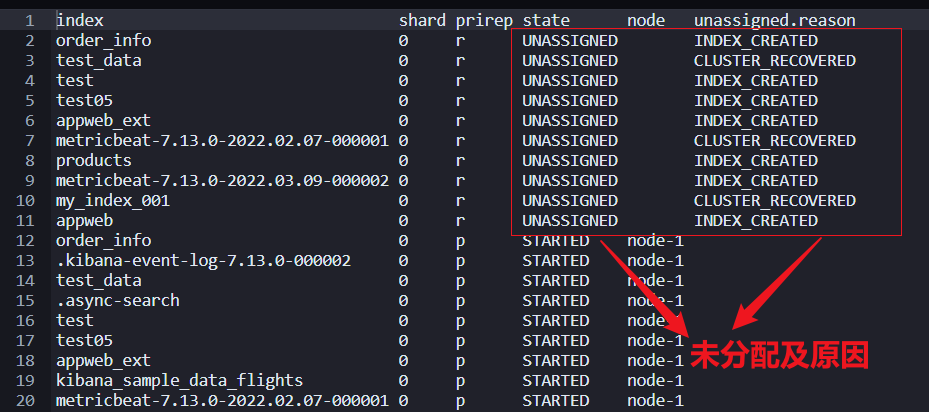
GET _cat/shards?v=true&h=index,shard,prirep,state,node,unassigned.reason&s=state
几个参数解释如下:
- v=true, 代表显示字段含义;否则首行内容不显示。
- h=*,代表列名;
- s=state,代表基于state方式排序。等价于:s=state:asc,默认升序方式排序。
- prirep,代表分片类型。p:代表主分片;r:代表副本分片。
如上截图代表:order_info、test_data等索引包含未分配的副本分片,这点和集群健康状态“黄色”一致。
查看未分配的分片的原因
上面的返回结果:unassigned.reason 已经基本包含了未分配的原因。但想得到更为详细的解释,需要使用如下的命令。
GET _cluster/allocation/explain?filter_path=index,node_allocation_decisions.node_name,node_allocation_decisions.deciders.*
{
"index": "order_info",
"shard": 0,
"primary": false
}
上面的几个参数解释如下:
- index:索引名称,建议结合前一步指定。
- shard:分片序号。从 0 开始计数。
- primary:是否主分片;true 代表是;false 代表否。
返回结果如下:
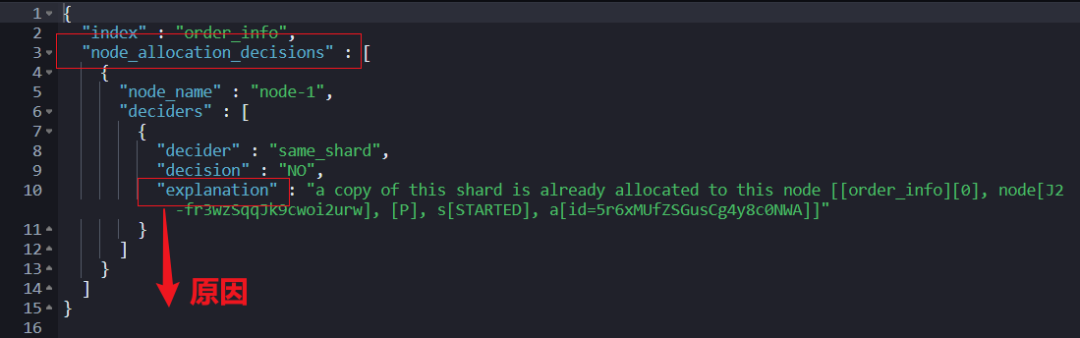
explanation 就是根本原因。如下 head 插件和 Kibana 都能看的更为明显。


本质原因就是:只有一个节点,但是设置了副本,导致了主分片可以分片正常,副本分片无法分配。进而导致:集群健康状态是黄色。
修复非健康集群状态方案汇总
重新启用分片分配
适用场景:节点重启过或者设置过禁用分片分配,但之后忘记设置重新分配策略,Elasticsearch 将无法分配分片。
需要手动更新集群设置才可以实现重新分配。
PUT _cluster/settings
{
"persistent" : {
"cluster.routing.allocation.enable" : null
}
}
调整节点下线时分片分配控制策略
当数据节点下线或特定原因宕机导致离开集群时,分片通常会变成未分配状态。造成这种情况的原因很多,比如:连接问题;比如:硬件故障问题等。
当这些故障解决后,下线节点重新加入集群,然后,Elasaticsearch 将自动分配之前因节点下线等原因导致的未分配的分片。
为了避免在上述问题上浪费资源,Elasticsearch 默认将分配延迟一分钟。根据业务实际需要,比如:因升级内存而下线数据节点的场景,可以将该延时值调大。
参考命令行如下:
PUT _all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
如果已恢复节点并且不想等待延迟期,则可以调用不带参数的集群 reroute API 来启动分配过程。该进程在后台异步运行。
POST _cluster/reroute
分片分配设置层面修复
分片分配设置错误可能会导致主分片无法分配。这些设置包括但不限于:
索引层面的分片分配设置;
集群层面的分片分配设置;
集群层面的感知(awareness)分片分配设置。
为了获取分片分配的细节设置,推荐使用如下两个 API:
GET order_info/_settings?flat_settings=true&include_defaults=true
GET _cluster/settings?flat_settings=true&include_defaults=true
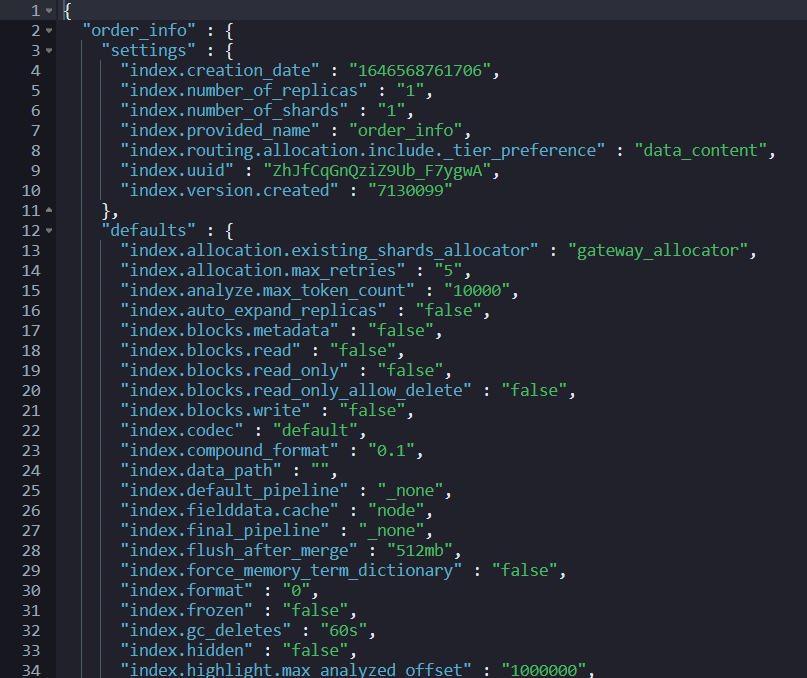
注意:
- flat_settings 标志会影响设置列表的呈现。当 flat_settings 标志为 true 时,相关设置以平面格式返回,如上图所示。
- include_defaults 默认值是 false,如果为 true,则代表返回集群所有缺省值。
更多参数设置,推荐阅读:https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html
减少副本设置
为了防止硬件故障,Elasticsearch 不会将副本分配给与其主分片相同的节点。
如果没有其他数据节点可用于分配副本分片,则该副本分片保持未分配状态。如开篇截图的黄色集群状态,本质就是这个原因。要解决此问题,你可以:
- 添加相同角色的数据节点。
- 通过更新 index.number_of_replicas 索引设置减少每个主分片的副本数。
为了保证集群线上业务的高可用性,建议每个主节点至少保留一个副本。
如下是集群层面的设置,设置后对整个集群生效。
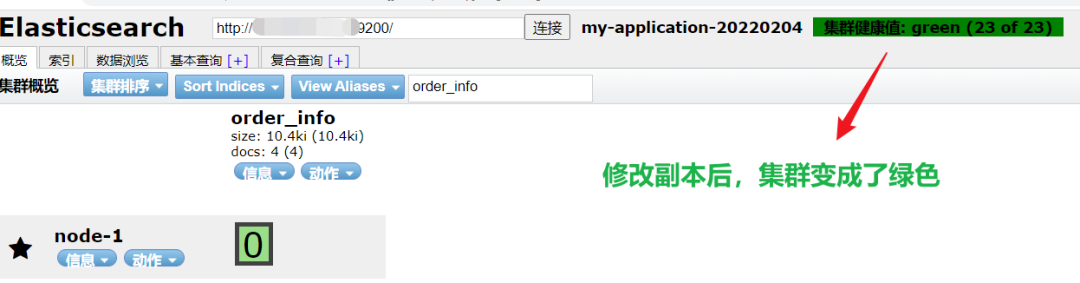
PUT _settings
{
"index.number_of_replicas": 0
}
释放或增加磁盘空间
Elasticsearch 使用 low disk watermark 低磁盘警戒水位线来确保数据节点有足够的磁盘空间来接收分片。
默认情况下,Elasticsearch 不会将分片分配给磁盘使用率超过 85% 的节点。要检查节点的当前磁盘空间,请使用 cat allocation API。
GET _cat/allocation?v=true&h=node,shards,disk.*

如果你的节点磁盘空间不足,你通常有如下四个细化方案:
方案 1:升级节点以增加磁盘空间。
方案 2:删除不需要的索引以释放空间。
(1)如果你使用 ILM 索引生命周期管理,则可以更新生命周期策略以使用可搜索快照或添加删除阶段。
(2)如果你不再需要搜索数据,可以使用快照将其历史数据存储在集群外。
PS:这里强调的删除索引,delete 操作,不是删除数据的 delete_by_query 操作,切记!
方案 3:如果你不再写入索引,请使用强制合并 API( force merge API ) 或 ILM 的强制合并操作将其段合并为更大的段。
POST order_info/_forcemerge

方案 4:如果索引是只读的,请使用 shrink index API 或 ILM 的 shrink action 来减少其主分片数。
PUT order_index_ext
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0
}
}
POST order_index_ext/_bulk
{"index":{"_id":1}}
{"title":"just testing..."}
{"index":{"_id":2}}
{"title":"just testing..."}
{"index":{"_id":3}}
{"title":"just testing..."}
PUT order_index_ext/_settings
{
"index.blocks.write":"true"
}
POST order_index_ext/_shrink/order_shrink_index
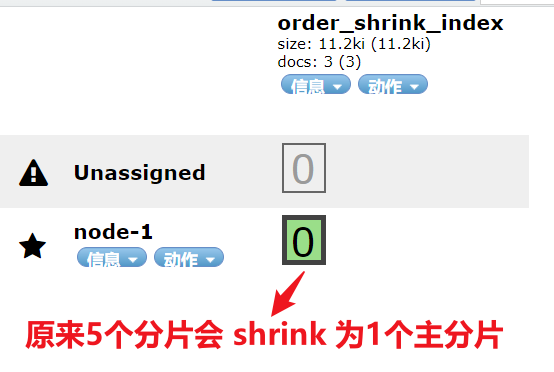
方案 5:如果你的节点具有较大的磁盘容量,你可以调大低磁盘警戒水位线的值或将其设置为显式字节值。
具体设置,参考如下:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "30gb"
}
}
减少 JVM 堆内存压力
分片分配需要 JVM 堆内存。高 JVM 内存压力可能会触发停止分片分配并使分片未分配的断路器(出现内存熔断现象)。
主分片丢失情况的恢复策略
如果包含主分片的节点因故障或其他原因下线,Elasticsearch 通常可以使用另一个节点上的副本替换它。
如果包含主分片的节点无法恢复或其副本不存在或无法恢复(这是比较极端的情况),则需要从快照或原始数据源重新添加丢失的数据。
仅当节点不再可能成功恢复时才使用此选项。因为:此过程分配一个空的主分片。如果节点稍后重新加入集群,Elasticsearch 将用这个较新的空分片中的数据覆盖其主分片,从而导致数据丢失。
使用集群重新路由 reroute API 手动将未分配的主分片分配给同一角色中的另一个数据节点。将参数 accept_data_loss 设置为 true。
POST _cluster/reroute
{
"commands": [
{
"allocate_empty_primary": {
"index": "order_info",
"shard": 0,
"node": "node-1",
"accept_data_loss": "true"
}
}
]
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2021-03-24 Docker安装部署Rancher
2021-03-24 Jenkins解决Host key verification failed
2021-03-24 Centos 7 安装 Haproxy
2021-03-24 阿里云下配置keepalive,利用HAVIP实现HA
2021-03-24 keepalived 实现双机热备
2021-03-24 HAproxy + keepalived 实现双机热备
2021-03-24 Keepalived设置master故障恢复后不重新抢回VIP