

使用Prometheus和Grafana监控nacos集群
官方文档:https://nacos.io/zh-cn/docs/monitor-guide.html
按照部署文档搭建好Nacos集群
配置application.properties文件,暴露metrics数据
management.endpoints.web.exposure.include=*
访问{ip}:8848/nacos/actuator/prometheus,看是否能访问到metrics数据
搭建prometheus采集Nacos metrics数据
修改配置文件prometheus.yml采集Nacos metrics数据
- job_name: 'nacos'
metrics_path: '/nacos/actuator/prometheus'
static_configs:
- targets: ['172.16.0.75:8848','172.16.0.76:8848','172.16.0.235:8848']
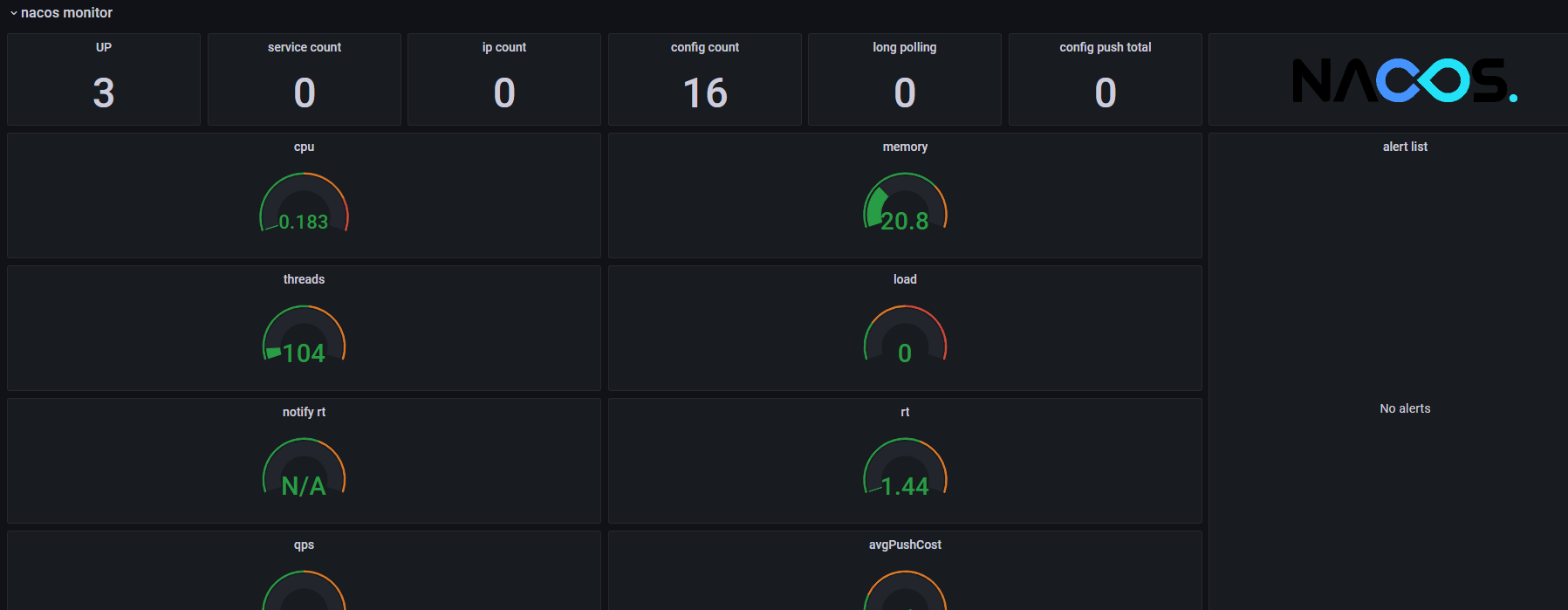
Grafana
https://grafana.com/grafana/dashboards/13221
面板ID:13221


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2019-12-13 查看索引在哪些ES集群节点上的命令
2019-12-13 结构化查询
2019-12-13 使用DbVisualizer 10.0.20 查询ES中的索引时需要注意的事项
2019-12-13 映射和分析
2016-12-13 TCMalloc优化MySQL、Nginx内存管理