

Ceph 存储集群第一部分:配置和部署
内容来源于官方,经过个人实践操作整理,官方地址:http://docs.ceph.org.cn/rados/
所有 Ceph 部署都始于 Ceph 存储集群。
基于 RADOS 的 Ceph 对象存储集群包括两类守护进程:term:对象存储守护进程( OSD )把存储节点上的数据存储为对象; term:Ceph 监视器( MON )维护集群运行图的主拷贝。
一个 Ceph 集群可以包含数千个存储节点,最简系统至少需要一个监视器和两个 OSD 才能做到数据复制。
Ceph 文件系统、 Ceph 对象存储、和 Ceph 块设备从 Ceph 存储集群读出和写入数据。

Ceph 存储集群的某些配置选项是必要的,但大多数都有默认值。典型部署是通过部署工具定义集群、并启动监视器的,关于 ceph-deploy 的详情见部署(http://docs.ceph.org.cn/rados/deployment/)。
配置
Ceph 作为集群时可以包含数千个对象存储设备(OSD)。最简系统至少需要二个 OSD 做数据复制。要配置 OSD 集群,你得把配置写入配置文件。 Ceph 对很多选项提供了默认值,你可以在配置文件里覆盖它们;另外,你可以使用命令行工具修改运行时配置。
Ceph 启动时要激活三类守护进程:
- ceph-mon (必备)
- ceph-osd (必备)
- ceph-mds (cephfs必备)
各进程、守护进程或工具都会读取配置文件。一个进程可能需要不止一个守护进程例程的信息(即多个上下文);一个守护进程或工具只有关于单个守护进程例程的信息(单上下文)。
硬盘和文件系统
1.准备硬盘
Ceph 注重数据安全,就是说, Ceph 客户端收到数据已写入存储器的通知时,数据确实已写入硬盘。使用较老的内核(版本小于 2.6.33 )时,如果日志在原始硬盘上,就要禁用写缓存;较新的内核没问题。
用 hdparm 禁用硬盘的写缓冲功能。
sudo hdparm -W 0 /dev/hda 0
在生产环境,我们建议操作系统和 Ceph OSD 守护进程数据分别放到不同的硬盘。如果必须把数据和系统放在同一硬盘里,最好给数据分配一个单独的分区。
2.文件系统
Ceph 的 OSD 依赖于底层文件系统的稳定性和性能。
当前,我们推荐部署生产系统时使用 xfs 文件系统;推荐用 btrfs 做测试、开发和其他不太要紧的部署。我们相信,长远来看 btrfs 适合 Ceph 的功能需求和发展方向,但是 xfs 和 ext4 能提供当前部署所必需的稳定性。
OSD 守护进程有赖于底层文件系统的扩展属性( XATTR )存储各种内部对象状态和元数据。底层文件系统必须能为 XATTR 提供足够容量, btrfs 没有限制随文件的 xattr 元数据总量; xfs 的限制相对大( 64KB ),多数部署都不会有瓶颈; ext4 的则太小而不可用。
使用 ext4 文件系统时,一定要把下面的配置放于 ceph.conf 配置文件的 [osd] 段下;用 btrfs 和 xfs 时可以选填。
filestore xattr use omap = true
配置 Ceph
启动 Ceph 服务时,初始化进程会把一系列守护进程放到后台运行。 Ceph 存储集群运行两种守护进程:
- Ceph 监视器 ( ceph-mon )
- Ceph OSD 守护进程 ( ceph-osd )
要支持 Ceph 文件系统功能,它还需要运行至少一个 Ceph 元数据服务器( ceph-mds );支持 Ceph 对象存储功能的集群还要运行网关守护进程( radosgw )。为方便起见,各类守护进程都有一系列默认值(很多由 ceph/src/common/config_opts.h 配置),你可以用 Ceph 配置文件覆盖这些默认值。
1.配置文件
启动 Ceph 存储集群时,各守护进程都从同一个配置文件(即默认的 ceph.conf )里查找它自己的配置。手动部署时,你需要创建此配置文件;用部署工具(如 ceph-deploy 、 chef 等)创建配置文件时可以参考下面的信息。配置文件定义了:
- 集群身份
- 认证配置
- 集群成员
- 主机名
- 主机 IP 地址
- 密钥环路径
- 日志路径
- 数据路径
- 其它运行时选项
默认的 Ceph 配置文件位置相继排列如下:
$CEPH_CONF(就是 $CEPH_CONF 环境变量所指示的路径);-c path/path(就是 -c 命令行参数);/etc/ceph/ceph.conf~/.ceph/config./ceph.conf (就是当前所在的工作路径)。
Ceph 配置文件使用 ini 风格的语法,以分号 (😉 和井号 (#) 开始的行是注释,如下:
# <--A number (#) sign precedes a comment.
; A comment may be anything.
# Comments always follow a semi-colon (;) or a pound (#) on each line.
# The end of the line terminates a comment.
# We recommend that you provide comments in your configuration file(s).
2.配置段落
Ceph 配置文件可用于配置存储集群内的所有守护进程、或者某一类型的所有守护进程。要配置一系列守护进程,这些配置必须位于能收到配置的段落之下,比如:
[global]
描述: [global] 下的配置影响 Ceph 集群里的所有守护进程。
实例: auth supported = cephx
[osd]
描述: [osd] 下的配置影响存储集群里的所有 ceph-osd 进程,并且会覆盖 [global] 下的同一选项。
实例: osd journal size = 1000
[mon]
描述: [mon] 下的配置影响集群里的所有 ceph-mon 进程,并且会覆盖 [global] 下的同一选项。
实例: mon addr = 10.0.0.101:6789
[mds]
描述: [mds] 下的配置影响集群里的所有 ceph-mds 进程,并且会覆盖 [global] 下的同一选项。
实例: host = myserver01
[client]
描述: [client] 下的配置影响所有客户端(如挂载的 Ceph 文件系统、挂载的块设备等等)。
实例: log file = /var/log/ceph/radosgw.log
全局设置影响集群内所有守护进程的例程,所以 [global] 可用于设置适用所有守护进程的选项。但可以用这些覆盖 [global] 设置:
- 在 [osd] 、 [mon] 、 [mds] 下更改某一类进程的配置。
- 更改特定进程的设置,如 [osd.1] 。
覆盖全局设置会影响所有子进程,明确剔除的例外。
典型的全局设置包括激活认证,例如:
[global]
#Enable authentication between hosts within the cluster.
#v 0.54 and earlier
auth supported = cephx
#v 0.55 and after
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
可以统一配置一类守护进程。配置写到 [osd] 、 [mon] 、 [mds] 下时,无须再指定某个特定例程,即可分别影响所有 OSD 、监视器、元数据进程。
典型的类范畴配置包括日志尺寸、 filestore 选项等,如:
[osd]
osd journal size = 1000
也可以配置某个特定例程。一个例程由类型和及其例程 ID 确定, OSD 的例程 ID 只能是数字,但监视器和元数据服务器的 ID 可包含字母和数字。
[osd.1]
# settings affect osd.1 only.
[mon.a]
# settings affect mon.a only.
[mds.b]
# settings affect mds.b only.
如果你想配置某个 Ceph 网关客户端,可以用点( . )分隔的守护进程和例程来指定,例如:
[client.radosgw.instance-name]
# settings affect client.radosgw.instance-name only.
3.元变量
元变量大大简化了集群配置。 Ceph 会把配置的元变量展开为具体值;元变量功能很强大,可以用在配置文件的 [global] 、 [osd] 、 [mon] 、 [mds] 段里,类似于 Bash 的 shell 扩展。
Ceph 支持下列元变量:
$cluster
描述: 展开为存储集群名字,在同一套硬件上运行多个集群时有用。
实例: /etc/ceph/$cluster.keyring
默认值: ceph
$type
描述: 可展开为 mds 、 osd 、 mon 中的一个,有赖于当前守护进程的类型。
实例: /var/lib/ceph/$type
$id
描述: 展开为守护进程标识符; osd.0 应为 0 , mds.a 是 a 。
实例: /var/lib/ceph/$type/$cluster-$id
$host
描述: 展开为当前守护进程的主机名。
$name
描述: 展开为 $type.$id 。
实例: /var/run/ceph/$cluster-$name.asok
4.共有选项
硬件推荐段提供了一些配置 Ceph 存储集群的硬件指导。
一个 Ceph 节点可以运行多个进程,例如一个节点有多个硬盘,可以为每个硬盘配置一个 ceph-osd 守护进程。
理想情况下一台主机应该只运行一类进程,例如:一台主机运行着 ceph-osd 进程,另一台主机运行着 ceph-mds 进程, ceph-mon 进程又在另外一台主机上。
各节点都用 host 选项指定主机名字,监视器还需要用 addr 选项指定网络地址和端口(即域名或 IP 地址)。基本配置文件可以只指定最小配置。例如:
[global]
mon_initial_members = ceph1
mon_host = 10.0.0.1
host 选项是此节点的短名字,不是全资域名( FQDN ),也不是 IP 地址;执行
hostname -s即可得到短名字。不要给初始监视器之外的例程设置 host ,除非你想手动部署;一定不能用于 chef 或 ceph-deploy ,这些工具会自动获取正确结果。
网络配置参考
网络配置对构建高性能 Ceph 存储集群来说相当重要。 Ceph 存储集群不会代表 Ceph 客户端执行请求路由或调度,相反, Ceph 客户端(如块设备、 CephFS 、 REST 网关)直接向 OSD 请求,然后OSD为客户端执行数据复制,也就是说复制和其它因素会额外增加集群网的负载。
我们的快速入门配置提供了一个简陋的 Ceph 配置文件,其中只设置了监视器 IP 地址和守护进程所在的主机名。如果没有配置集群网,那么 Ceph 假设你只有一个“公共网”。只用一个网可以运行 Ceph ,但是在大型集群里用单独的“集群”网可显著地提升性能。
我们建议用两个网络运营 Ceph 存储集群:一个公共网(前端)和一个集群网(后端)。为此,各节点得配备多个网卡.
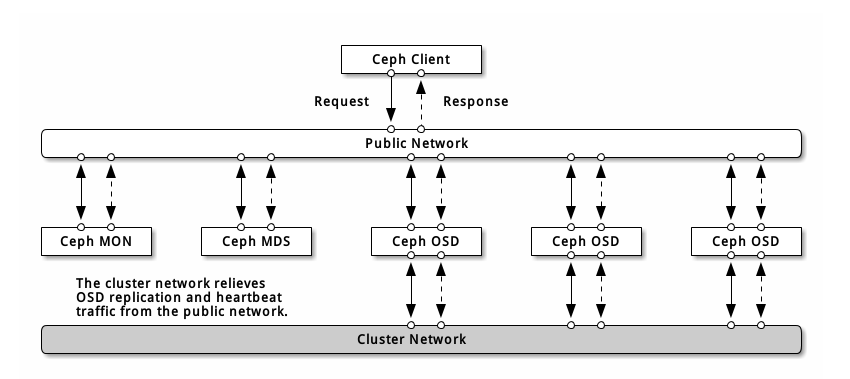
运营两个独立网络的考量主要有:
- 性能: OSD 为客户端处理数据复制,复制多份时 OSD 间的网络负载势必会影响到客户端和 Ceph 集群的通讯,包括延时增加、产生性能问题;恢复和重均衡也会显著增加公共网延时。
- 安全: 大多数人都是良民,很少的一撮人喜欢折腾拒绝服务攻击( DoS )。当 OSD 间的流量失控时,归置组再也不能达到 active + clean 状态,这样用户就不能读写数据了。挫败此类攻击的一种好方法是维护一个完全独立的集群网,使之不能直连互联网
1.防火墙
守护进程默认会绑定到 6800:7300 间的端口,你可以更改此范围。
1.1 监视器防火墙
监视器默认监听 6789 端口,而且监视器总是运行在公共网。按下例增加规则时,要把 {iface} 替换为公共网接口(如 eth0 、 eth1 等等)、 {ip-address} 替换为公共网 IP 、{netmask} 替换为公共网掩码。
sudo iptables -A INPUT -i {iface} -p tcp -s {ip-address}/{netmask} --dport 6789 -j ACCEPT
1.2 MDS 防火墙
元数据服务器会监听公共网 6800 以上的第一个可用端口。需要注意的是,这种行为是不确定的,所以如果你在同一主机上运行多个 OSD 或 MDS 、或者在很短的时间内重启了多个守护进程,它们会绑定更高的端口号;所以说你应该预先打开整个 6800-7300 端口区间。按下例增加规则时,要把 {iface} 替换为公共网接口(如 eth0 、 eth1 等等)、 {ip-address} 替换为公共网 IP 、 {netmask} 替换为公共网掩码。
sudo iptables -A INPUT -i {iface} -m multiport -p tcp -s {ip-address}/{netmask} --dports 6800:7300 -j ACCEPT
1.3 OSD 防火墙
OSD 守护进程默认绑定 从 6800 起的第一个可用端口,需要注意的是,这种行为是不确定的,所以如果你在同一主机上运行多个 OSD 或 MDS 、或者在很短的时间内重启了多个守护进程,它们会绑定更高的端口号。一主机上的各个 OSD 最多会用到 4 个端口:
1 一个用于和客户端、监视器通讯;
2 一个用于发送数据到其他 OSD ;
3 两个用于各个网卡上的心跳;
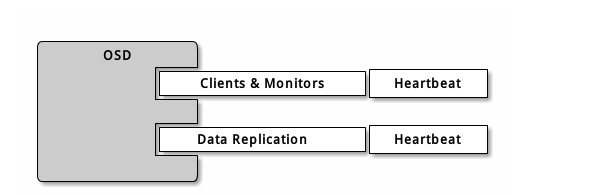
当某个守护进程失败并重启时没释放端口,重启后的进程就会监听新端口。你应该打开整个 6800-7300 端口区间,以应对这种可能性。
如果你分开了公共网和集群网,必须分别为之设置防火墙,因为客户端会通过公共网连接、而其他 OSD 会通过集群网连接。按下例增加规则时,要把 {iface} 替换为网口(如 eth0 、 eth1 等等)、 {ip-address}替换为公共网或集群网 IP 、 {netmask} 替换为公共网或集群网掩码。例如:
sudo iptables -A INPUT -i {iface} -m multiport -p tcp -s {ip-address}/{netmask} --dports 6800:7300 -j ACCEPT
如果你的元数据服务器和 OSD 在同一节点上,可以合并公共网配置。
2.Ceph 网络
Ceph 的网络配置要放到 [global] 段下。前述的 5 分钟快速入门提供了一个简陋的 Ceph 配置文件,它假设服务器和客户端都位于同一网段, Ceph 可以很好地适应这种情形。然而 Ceph 允许配置更精细的公共网,包括多 IP 和多掩码;也能用单独的集群网处理 OSD 心跳、对象复制、和恢复流量。不要混淆你配置的 IP 地址和客户端用来访问存储服务的公共网地址。典型的内网常常是 192.168.0.0 或 10.0.0.0 。
如果你给公共网或集群网配置了多个 IP 地址及子网掩码,这些子网必须能互通。另外要确保在防火墙上为各 IP 和子网开放了必要的端口。
Ceph 用 CIDR 法表示子网,如 10.0.0.0/24 。
配置完几个网络后,可以重启集群或挨个重启守护进程。 Ceph 守护进程动态地绑定端口,所以更改网络配置后无需重启整个集群。
公共网
要配置一个公共网,把下列选项加到配置文件的 [global] 段下。
[global]
...
public network = {public-network/netmask}
集群网
如果你声明了集群网, OSD 将把心跳、对象复制和恢复流量路由到集群网,与单个网络相比这会提升性能。要配置集群网,把下列选项加进配置文件的 [global] 段。
[global]
...
cluster network = {cluster-network/netmask}
为安全起见,从公共网或互联网到集群网应该是不可达的。
3.Ceph 守护进程
有一个网络配置是所有守护进程都要配的:各个守护进程都必须指定 host , Ceph 也要求指定监视器 IP 地址及端口。
host 选项是主机的短名,不是全资域名 FQDN ,也不是 IP 地址。在命令行下输入 hostname -s 获取主机名。
[mon.a]
host = {hostname}
mon addr = {ip-address}:6789
[osd.0]
host = {hostname}
并非一定要给守护进程设置 IP 地址。如果你有一个静态配置,且分离了公共网和集群网, Ceph 允许你在配置文件里指定主机的 IP 地址。要给守护进程设置静态 IP ,可把下列选项加到 ceph.conf 。
[osd.0]
public addr = {host-public-ip-address}
cluster addr = {host-cluster-ip-address}
单网卡OSD、双网络集群
一般来说,我们不建议用单网卡 OSD 主机部署两个网络。然而这事可以实现,把 public addr 选项配在 [osd.n] 段下即可强制 OSD 主机运行在公共网,其中 n 是其 OSD 号。另外,公共网和集群网必须互通,考虑到安全因素我们不建议这样做。
4.网络配置选项
网络配置选项不是必需的, Ceph 假设所有主机都运行于公共网,除非你特意配置了一个集群网。
公共网
公共网配置用于明确地为公共网定义 IP 地址和子网。你可以分配静态 IP 或用 public addr 覆盖 public network 选项。
public network
描述: 公共网(前端)的 IP 地址和掩码(如 192.168.0.0/24 ),置于 [global] 下。多个子网用逗号分隔。
类型: {ip-address}/{netmask} [, {ip-address}/{netmask}]
是否必需: No
默认值: N/A
public addr
描述: 用于公共网(前端)的 IP 地址。适用于各守护进程。
类型: IP 地址
是否必需: No
默认值: N/A
集群网
集群网配置用来声明一个集群网,并明确地定义其 IP 地址和子网。你可以配置静态 IP 或为某 OSD 守护进程配置 cluster addr 以覆盖 cluster network 选项。
cluster network
描述: 集群网(后端)的 IP 地址及掩码(如 10.0.0.0/24 ),置于 [global] 下。多个子网用逗号分隔。
类型: {ip-address}/{netmask} [, {ip-address}/{netmask}]
是否必需: No
默认值: N/A
cluster addr
描述: 集群网(后端) IP 地址。置于各守护进程下。
类型: Address
是否必需: No
默认值: N/A
绑定
绑定选项用于设置 OSD 和 MDS 默认使用的端口范围,默认范围是 6800:7300 。确保防火墙开放了对应端口范围。
你也可以让 Ceph 守护进程绑定到 IPv6 地址。
ms bind port min
描述: OSD 或 MDS 可绑定的最小端口号。
类型: 32-bit Integer
默认值: 6800
是否必需: No
ms bind port max
描述: OSD 或 MDS 可绑定的最大端口号。
类型: 32-bit Integer
默认值: 7300
是否必需: No.
ms bind ipv6
描述: 允许 Ceph 守护进程绑定 IPv6 地址。
类型: Boolean
默认值: false
是否必需: No
主机
Ceph 配置文件里至少要写一个监视器、且每个监视器下都要配置 mon addr 选项;每个监视器、元数据服务器和 OSD 下都要配 host 选项。
mon addr
描述: {hostname}:{port} 条目列表,用以让客户端连接 Ceph 监视器。如果未设置, Ceph 查找 [mon.*] 段。
类型: String
是否必需: No
默认值: N/A
host
描述: 主机名。此选项用于特定守护进程,如 [osd.0] 。
类型: String
是否必需: Yes, for daemon instances.
默认值: localhost
不要用 localhost 。在命令行下执行 hostname -s 获取主机名(到第一个点,不是全资域名),并用于配置文件。
用第三方部署工具时不要指定 host 选项,它会自行获取。
TCP
Ceph 默认禁用 TCP 缓冲。
ms tcp nodelay
描述: Ceph 用 ms tcp nodelay 使系统尽快(不缓冲)发送每个请求。禁用 Nagle 算法可增加吞吐量,但会引进延时。如果你遇到大量小包,可以禁用 ms tcp nodelay 试试。
类型: Boolean
是否必需: No
默认值: true
ms tcp rcvbuf
描述: 网络套接字接收缓冲尺寸,默认禁用。
类型: 32-bit Integer
是否必需: No
默认值: 0
ms tcp read timeout
描述: 如果一客户端或守护进程发送请求到另一个 Ceph 守护进程,且没有断开不再使用的连接,在 ms tcp read timeout 指定的秒数之后它将被标记为空闲。
类型: Unsigned 64-bit Integer
是否必需: No
默认值: 900 15 minutes.
监视器
典型的 Ceph 生产集群至少部署 3 个监视器来确保高可靠性,它允许一个监视器例程崩溃。奇数个监视器( 3 个)确保 PAXOS 算法能确定一批监视器里哪个版本的集群运行图是最新的。
一个 Ceph 集群可以只有一个监视器,但是如果它失败了,因没有监视器数据服务就会中断。
Ceph 监视器默认监听 6789 端口,例如:
[mon.a]
host = hostName
mon addr = 150.140.130.120:6789
默认情况下, Ceph 会在下面的路径存储监视器数据:
/var/lib/ceph/mon/$cluster-$id
你必须手动或通过部署工具(如 ceph-deploy )创建对应目录。前述元变量必须先全部展开,名为 “ceph” 的集群将展开为:
/var/lib/ceph/mon/ceph-a
认证
对于 v0.56 及后来版本,要在配置文件的 [global] 中明确启用或禁用认证。
[global]
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
另外,你应该启用消息签名,详情见 Cephx 配置参考和 Cephx 认证。
建议,升级时先明确地关闭认证,再进行升级。等升级完成后再重新启用认证。
OSDs
通常, Ceph 生产集群在一个节点上只运行一个 Ceph OSD 守护进程,此守护进程在一个存储驱动器上只运行一个 filestore ;典型部署需指定日志尺寸。例如:
[osd]
osd journal size = 10000
[osd.0]
host = {hostname} #manual deployments only.
默认情况下, Ceph 认为你把 OSD 数据存储到了以下路径:
/var/lib/ceph/osd/$cluster-$id
你必须手动或通过部署工具(如 ceph-deploy )创建对应目录,名为 “ceph” 的集群其元变量完全展开后,前述的目录将是:
/var/lib/ceph/osd/ceph-0
你可以用 osd data 选项更改默认值,但我们不建议修改。用下面的命令在新 OSD 主机上创建默认目录:
ssh {osd-host}
sudo mkdir /var/lib/ceph/osd/ceph-{osd-number}
osd data 路径应该指向一个独立硬盘的挂载点,这个硬盘应该独立于操作系统和守护进程所在硬盘。按下列步骤准备好并挂载:
ssh {new-osd-host}
sudo mkfs -t {fstype} /dev/{disk}
sudo mount -o user_xattr /dev/{hdd} /var/lib/ceph/osd/ceph-{osd-number}
我们推荐用 xfs 或 btrfs 文件系统,命令是 :command:mkfs 。
配置详细步骤见 OSD 配置参考。
心跳
在运行时, OSD 守护进程会相互检查邻居 OSD 、并把结果报告给 Ceph 监视器,一般不需要更改默认配置。但如果你的网络延时比较大,也许需要更改某些选项。
其它细节部分见监视器与 OSD 交互的配置。
日志、调试
有时候你可能遇到一些麻烦,需要修改日志或调试选项,请参考调试和日志记录。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2019-12-03 Elasticsearch7.3使用内置的JDK12
2019-12-03 关于elasticsearch使用G1垃圾回收替换CMS
2016-12-03 nginx配合modsecurity实现WAF功能
2016-12-03 ningx配置ModSecurity重启出现兼容性问题:ModSecurity: Loaded PCRE do not match with compiled!的解决方法