

Kubernetes 存储系统 Storage 介绍:PV,PVC,SC
要求:先了解数据docker容器中数据卷的挂载等知识
参考网址:
- https://www.cnblogs.com/sanduzxcvbnm/p/13176938.html
- https://www.cnblogs.com/sanduzxcvbnm/p/13371254.html
容器中的存储都是临时的,因此Pod重启的时候,内部的数据会发生丢失。实际应用中,我们有些应用是无状态,有些应用则需要保持状态数据,确保Pod重启之后能够读取到之前的状态数据,有些应用则作为集群提供服务。这三种服务归纳为无状态服务、有状态服务以及有状态的集群服务,其中后面两个存在数据保存与共享的需求,Kubermetes对于有状态的容器应用或者对数据需要持久化的应用,不仅需要将容器内的目录挂载到宿主机的目录或者emptyDir临时存储卷,而且需要更加可靠的存储来保存应用产生的重要数据,以便容器应用在重建之后,仍然可以使用之前的数据。
Kubernetes Volume(数据卷)主要解决如下两方面问题:
- 数据持久性:通常情况下,容器运行起来之后,写入到其文件系统的文件暂时性的。当容器崩溃后,kubelet 将会重启该容器,此时原容器运行后写入的文件将丢失,因为容器将重新从镜像创建。
- 数据共享:同一个 Pod(容器组)中运行的容器之间,经常会存在共享文件/文件夹的需求
Docker 里同样也存在一个 volume(数据卷)的概念,但是 docker 对数据卷的管理相对 kubernetes 而言要更少一些。在 Docker 里,一个 Volume(数据卷)仅仅是宿主机(或另一个容器)文件系统上的一个文件夹。Docker 并不管理 Volume(数据卷)的生命周期。
在 Kubernetes 里,Volume(数据卷)存在明确的生命周期(与包含该数据卷的容器组相同)。因此,Volume(数据卷)的生命周期比同一容器组中任意容器的生命周期要更长,不管容器重启了多少次,数据都能被保留下来。当然,如果容器组退出了,数据卷也就自然退出了。此时,根据容器组所使用的 Volume(数据卷)类型不同,数据可能随数据卷的退出而删除,也可能被真正持久化,并在下次容器组重启时仍然可以使用。
从根本上来说,一个 Volume(数据卷)仅仅是一个可被容器组中的容器访问的文件目录(也许其中包含一些数据文件)。这个目录是怎么来的,取决于该数据卷的类型(不同类型的数据卷使用不同的存储介质)。
使用 Volume(数据卷)时,我们需要先在容器组中定义一个数据卷,并将其挂载到容器的挂载点上。容器中的一个进程所看到(可访问)的文件系统是由容器的 docker 镜像和容器所挂载的数据卷共同组成的。Docker 镜像将被首先加载到该容器的文件系统,任何数据卷都被在此之后挂载到指定的路径上。Volume(数据卷)不能被挂载到其他数据卷上,或者通过引用其他数据卷。同一个容器组中的不同容器各自独立地挂载数据卷,即同一个容器组中的两个容器可以将同一个数据卷挂载到各自不同的路径上。
我们现在通过下图来理解 容器组、容器、挂载点、数据卷、存储介质(nfs、PVC、ConfigMap)等几个概念之间的关系:
- 一个容器组可以包含多个数据卷、多个容器
- 一个容器通过挂载点决定某一个数据卷被挂载到容器中的什么路径
- 不同类型的数据卷对应不同的存储介质
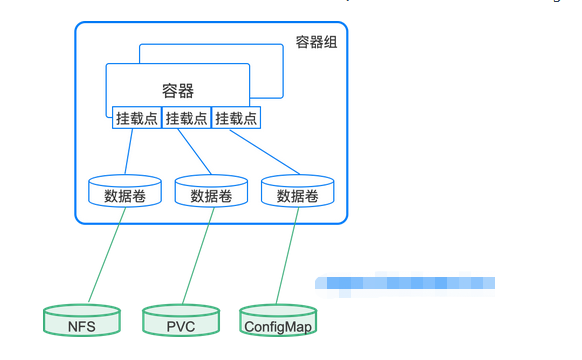
对上段话的理解
1.docker中的数据卷挂载,是指把宿主机的某个路径或者另外其他的容器路径给挂载到当前容器中使用
2.Kubernetes 中的 Volume 是存储的抽象,并且能够为Pod提供多种存储解决方案。Volume 最终会映射为Pod中容器可访问的一个文件夹或裸设备
3.k8s中提供的数据卷挂载,除了宿主机路径和数据卷容器外,还包含其他的一些挂载路径,也就是其他的存储介质,比如说NFS
额外补充知识
k8s中挂载数据卷,还可以挂载数据卷的子路径:数据卷内子路径 用于指定将数据卷所对应目录下的某一个子目录挂载到容器的挂载点,而不是将数据卷对应的目录的根路径挂载到容器的挂载点
Pod中使用数据卷
Pod的spec.volumes中声明的卷的使用场景:
- Pod中的容器异常退出被重新拉起后,保证之前产生的数据没有丢失
- Pod中的多个容器共享数据
容器中通过volumeMounts字段使用卷,volumeMounts[].name字段指定它使用的哪个卷,volumeMounts[].mountPath字段指定容器中的挂载路径。
多个容器共享卷时,可以通过volumeMounts[].subPath字段隔离不同容器在卷上数据存储的路径

k8s中支持的数据卷类型
Volumes的类型
- configMap
- hostPath
- emptyDir
- local
- nfs
- cephfs
- secret
- persistentVolumeClaim
- ConfigMap
描述:
ConfigMap 提供了一种向容器组注入配置信息的途径。ConfigMap 中的数据可以被 Pod(容器组)中的容器作为一个数据卷挂载。
在数据卷中引用 ConfigMap 时:
- 您可以直接引用整个 ConfigMap 到数据卷,此时 ConfigMap 中的每一个 key 对应一个文件名,value 对应该文件的内容
- 您也可以只引用 ConfigMap 中的某一个名值对,此时可以将 key 映射成一个新的文件名
将 ConfigMap 数据卷挂载到容器时,如果该挂载点指定了 数据卷内子路径 (subPath),则该 ConfigMap 被改变后,该容器挂载的内容仍然不变。
使用场景:
使用 ConfigMap 中的某一 key 作为文件名,对应 value 作为文件内容,替换 nginx 容器中的 /etc/nginx/conf.d/default.conf 配置文件。
参考网址:https://www.cnblogs.com/sanduzxcvbnm/p/13084135.html
- hostPath
描述:
hostPath 类型的数据卷将 Pod(容器组)所在节点的文件系统上某一个文件或文件夹挂载进容器组(容器)。
除了为 hostPath 指定 path 字段以外,您还可以为其指定 type 字段,可选的 type 字段描述如下:
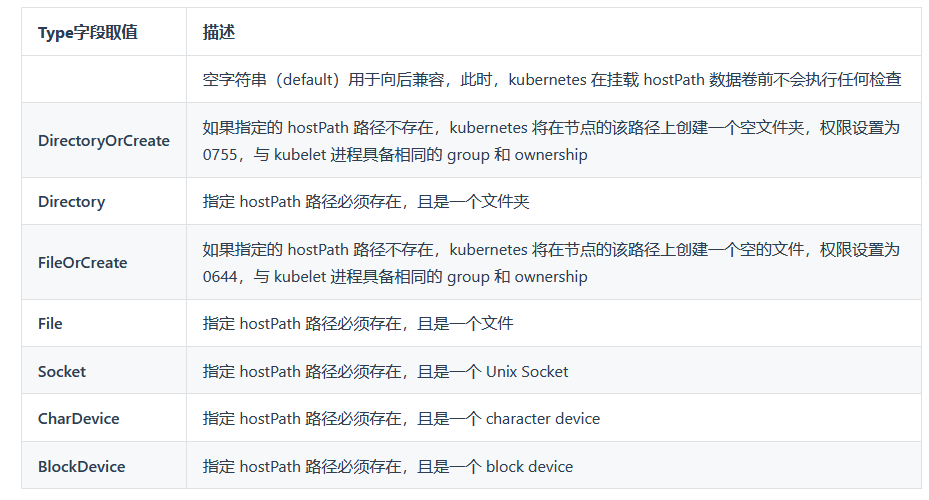
使用 hostPath 数据卷时,必须十分小心,因为:
不同节点上配置完全相同的容器组(例如同一个Deployment的容器组)可能执行结果不一样,因为不同节点上 hostPath 所对应的文件内容不同
hostPath 对应的文件/文件夹只有 root 可以写入。您要么在 privileged Container 以 root 身份运行您的进程,要么修改与 hostPath 数据卷对应的节点上的文件/文件夹的权限
容器中通过volumeMounts[].mountPropagation配置挂载传播
- None(默认):此卷挂载不会接收到任何后续挂载到该卷或是挂载到该卷的子目录下的挂载
- HostToContainer:此卷挂载将会接收到任何后续挂载到该卷或是挂载到该卷的子目录下的挂载
- Bidirectional:类似HostToContainer,但Container创建的所有卷挂载都将传播回主机和所有使用相同卷的容器
适用场景:
绝大多数容器组并不需要使用 hostPath 数据卷,但是少数情况下,hostPath 数据卷非常有用:
- 某容器需要访问 Docker,可使用 hostPath 挂载宿主节点的 /var/lib/docker
- 在容器中运行 cAdvisor,使用 hostPath 挂载宿主节点的 /sys
- emptyDir
描述:emptyDir类型的数据卷在容器组被创建时分配给该容器组,并且直到容器组被移除,该数据卷才被释放。该数据卷初始分配时,始终是一个空目录。同一容器组中的不同容器都可以对该目录执行读写操作,并且共享其中的数据,(尽管不同的容器可能将该数据卷挂载到容器中的不同路径)。当容器组被移除时,emptyDir数据卷中的数据将被永久删除
容器崩溃时,kubelet 并不会删除容器组,而仅仅是将容器重启,因此 emptyDir 中的数据在容器崩溃并重启后,仍然是存在的。
适用场景:
- 空白的初始空间,例如合并/排序算法中,临时将数据存在磁盘上
- 长时间计算中存储检查点(中间结果),以便容器崩溃时,可以从上一次存储的检查点(中间结果)继续进行,而不是从头开始
- 作为两个容器的共享存储,使得第一个内容管理的容器可以将生成的页面存入其中,同时由一个 webserver 容器对外提供这些页面
- 默认情况下,emptyDir 数据卷被存储在 node(节点)的存储介质(机械硬盘、SSD、或者网络存储)上。此外,您可以设置 emptyDir.medium 字段为 "Memory",此时 Kubernetes 将挂载一个 tmpfs(基于 RAM 的文件系统)。tmpfs 的读写速度非常快,但是与磁盘不一样,tmpfs 在节点重启后将被清空,且您向该 emptyDir 写入文件时,将消耗对应容器的内存限制。
apiVersion: v1
kind: Pod
metadata:
name: tomcat-ccb
namespace: default
labels:
app: tomcat
node: devops-103
spec:
containers:
- name: tomcat
image: docker.io/tomcat
volumeMounts:
- name: tomcat-storage
mountPath: /data/tomcat
- name: cache-storage
mountPath: /data/cache
ports:
- containerPort: 8080
protocol: TCP
env:
- name: GREETING
value: "Hello from devops-103"
volumes:
- name: tomcat-storage
hostPath:
path: /home/es
- name: cache-storage
emptyDir: {}
- local
local类型作为静态资源被PersistentVolume使用,不支持Dynamic provisioning。与hostPath相比,因为能够通过PersistentVolume的节点亲和策略来进行调度,因此比hostPath类型更加适用。local类型也存在一些问题,如果Node的状态异常,那么local存储将无法访问,从而导致Pod运行状态异常。使用这种类型存储的应用必须能够承受可用性的降低、可能的数据丢失等。
对于使用了PV的Pod,Kubernetes会调度到具有对应PV的Node上,因此PV的节点亲和性 nodeAffinity 属性是必须的。
apiVersion: v1
kind: PersistentVolume
metadata:
name: www
spec:
capacity:
storage: 100Mi
volumeMode: Filesystem
accessModes: ["ReadWriteOnce"]
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /home/es
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- devops-102
- devops-103
- NFS
描述:
nfs 类型的数据卷可以加载 NFS(Network File System)到您的容器组/容器。容器组被移除时,将仅仅 umount(卸载)NFS 数据卷,NFS 中的数据仍将被保留。
- 可以在加载 NFS 数据卷前就在其中准备好数据;
- 可以在不同容器组之间共享数据;
- 可以被多个容器组加载并同时读写;
适用场景:
- 存储日志文件
- MySQL的data目录(建议只在测试环境中
- 用户上传的临时文件
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: nfs-client-root
volumes:
- name: nfs-client-root
nfs:
server: 10.6.229.62
path: /nfs/data/class
-
cephfs
cephfs 数据卷使得您可以挂载一个外部 CephFS 卷到您的容器组中。对于 kubernetes 而言,cephfs 与 nfs 的管理方式和行为完全相似,适用场景也相同。不同的仅仅是背后的存储介质。 -
secret
描述:
secret 数据卷可以用来注入敏感信息(例如密码)到容器组。您可以将敏感信息存入 kubernetes secret 对象,并通过 Volume(数据卷)以文件的形式挂载到容器组(或容器)。secret 数据卷使用 tmpfs(基于 RAM 的文件系统)挂载。
将 Secret 数据卷挂载到容器时,如果该挂载点指定了 数据卷内子路径 (subPath),则该 Secret 被改变后,该容器挂载的内容仍然不变。
使用场景:
将 HTTPS 证书存入 kubernets secret,并挂载到 /etc/nginx/conf.d/myhost.crt、/etc/nginx/conf.d/myhost.pem 路径,用来配置 nginx 的 HTTPS 证书
- Volumes是最基础的存储抽象,其支持多种类型,包括本地存储、NFS、FC以及众多的云存储,我们也可以编写自己的存储插件来支持特定的存储系统。Volume可以被Pod直接使用,也可以被PV使用。普通的Volume和Pod之间是一种静态的绑定关系,在定义Pod的同时,通过volume属性来定义存储的类型,通过volumeMount来定义容器内的挂载点。
- PersistentVolume。与普通的Volume不同,PV是Kubernetes中的一个资源对象,创建一个PV相当于创建了一个存储资源对象,这个资源的使用要通过PVC来请求。
- PersistentVolumeClaim。PVC是用户对存储资源PV的请求,根据PVC中指定的条件Kubernetes动态的寻找系统中的PV资源并进行绑定。目前PVC与PV匹配可以通过StorageClassName、matchLabels或者matchExpressions三种方式。
- persistentVolumeClaim
persistentVolumeClaim 数据卷用来挂载 PersistentVolume 存储卷。
数据卷挂载(比较重要)
参考文章:https://www.cnblogs.com/sanduzxcvbnm/p/13072429.html
问题
Pod中声明的Volume生命周期与Pod相同,有几种常见的缺点:
- Deployment升级时,新Pod难以复用旧Pod的数据;
- Pod跨主机迁移时,做不到带Volume迁移;
- 只能做到同一个Pod中的多个容器共享数据,做不到多个Pod之间共享数据;
- 很难实现功能扩展
PV & PVC
PersistentVolume(PV)是集群中由管理员配置的一段网络存储。 它是集群中的资源,就像节点是集群资源一样。 PV是容量插件,如Volumes,但其生命周期独立于使用PV的任何单个pod。 能够支持多种数据存储服务器,通过PV,我们能在K8S集群中,把我们的数据持久化到外部的服务器中。
pv
PV作为存储资源,主要包括存储能力、访问模式、存储类型、回收策略、后端存储类型等关键信息的设置。下面的例子声明的PV具有如下属性: 5Gi 存储空间,访问模式为“ReadWriteOnce”,存储类型为“slow" (要求系统中已存在名为slow的StorageClass),回收策略为“Recycle",并且后端存储类型为“nfs”(设置了NFS Server的IP地址和路径):
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
nfs:
path: /tmp
server: 172.17.0.2
PV能够支持的数据存储服务类型
- gcePersistentDisk: GCE公有云提供的PersistentDisk。
- AWSElasticBlockStore: AWS公有云提供的ElasticBlockStore.
- AzureFile: Azure公有云提供的File。
- AzureDisk: Azure 公有云提供的Disk。
- FC ( Fibre Channel)。
- Flocker。
- NFS:网络文件系统。
- iSCSI。
- RBD (Rados Block Device); Ceph块存储。
- CephFS。
- Cinder: OpenStack Cinder块存储。
- GlusterFS。
- VsphereVolume.
- Quobyte Volumes。
- VMware Photon。
- Portworx Volumes。
- ScaleIO Volumes。
- HostPath:宿主机目录,仅用于单机测试。
每种存储类型都有各自的特点,在使用时需要根据它们各自的参数进行设置。
1、Capacity(容量)
描述存储设备具备的能力,目前仅支持对存储空间的设置(storage=xx),未来可能加入
2、访问模式(Access Modes)
ReadWriteOnce (简写为 RWO): 读写权限,并且只能被单个Node挂载。
ReadOnlyMany (简写为 ROX): 只读权限,允许被多个Node挂载。
ReadWriteMany (简写为 RWX): 读写权限,允许被多个Node挂载。
注意:即使volume支持很多种访问模式,但它同时只能使用一种访问模式。比如,GCEPersistentDisk可以被单个节点映射为ReadWriteOnce,或者多个节点映射为ReadOnlyMany,但不能同时使用这两种方式来映射。
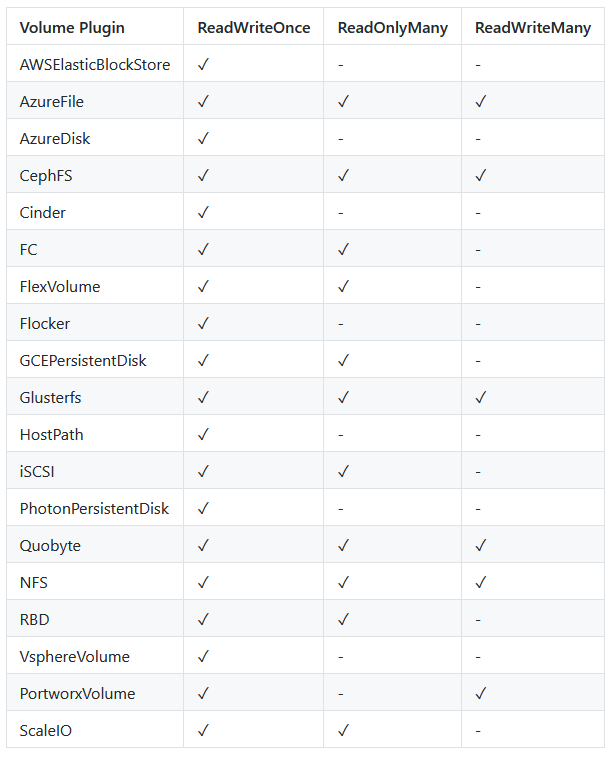
3、存储类别(Class)
PV可以设定其存储的类别(Class),通过storageClassName参数指定一个StorageClass资源对象的名称。具有特定“类别”的PV只能与请求该“类别”的PVC进行绑定。未设定“类别”的PV则只能与不请求任何“类别”的PVC进行绑定。
4、回收策略(Reclaim Policy)
目前支持如下三种回收策略。
保留(Retain): 保留数据,需要手工处理。
回收空间( Recycle): 简单清除文件的操作(例如执行rm -rf /thevolume/*命令)。
删除(Delete): 与PV相连的后端存储完成volume的删除操作(如AWS EBS、GCE PD、Azure Disk、OpenStack Cinder等设备的内部volume清理)。
目前,只有NFS和HostPath两种类型的存储支持“Recycle”策略; AWS EBS、GCE PD、Azure Disk和Cinder volumes支持“Delete”策略。
- PV生命周期的各个阶段( Phase )
某个PV在生命周期中,可能处于以下4个阶段之一。
Available: 可用状态,还未与某个PVC绑定。
Bound: 已与某个PVC绑定。
Released: 绑定的PVC已经删除,资源已释放,但没有被集群回收。
Failed: 自动资源回收失败。
- PV的挂载参数( Mount Options )
在将PV挂载到一个Node上时,根据后端存储的特点,可能需要设置额外的挂载参数,目前可以通过在PV的定义中,设置一个名为“volume.beta.kubernetes.io/mount-options"的annotation来实现。下面的例子对一个类型为gcePersistentDisk的PV设置了挂载参数“discard":
apiVersion: "v1"
kind: "PersistentVolume"
metadata :
name: gce-disk-1
annotations:
volume.beta.kubernetes.io/mount-options: "discard"
spec:
capacity:
storage : "10Gi”
accessModes :
- ”ReadWriteOnce”
gcePersistentDisk:
fsType: "ext4"
pdName : "gce-disk-1
并非所有类型的存储都支持设置挂载参数。从Kubernetes v1.6版本开始,以下存储类型支持设置挂载参数。
- gcePersistentDisk。
- AWSElasticBlockStore.
- AzureFile。
- AzureDisk。
- NFS。
- iSCSI。
- RBD
- (Rados Block Device): Ceph 块存储。
- CephFS。
- Cinder: OpenStack 块存储。
- GlusterFS。
- VsphereVolume.
- Quobyte Volumes.
- VMware Photon。
PVC
PVC(PersistentVolumeClaim)是用户对PV的一次申请。PVC对于PV就像Pod对于Node一样,Pod可以申请CPU和Memory资源,而PVC也可以申请PV的大小与权限。
PVC 作为用户对存储资源的需求申请,主要包括存储空间请求、访问模式、PV选择条件和存储类别等信息的设置。下面的例子中声明的PVC具有如下属性:申请8Gi存储空间,访问模式为"ReadWriteOnce",PV选择条件为包含标签"release=stable"并且包含条件为"environment In [dev]"的标签,存储类别为"slow"(要求系统中已存在名为slow的StorageClass)。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
PVC的关键配置参数说明如下:
资源请求(Resources):描述对存储资源的请求,目前仅支持request.storage的设置,即存储空间大小。
访问模式(Access Modes):PVC也可以设置访问模式,用于描述用户应用对存储资源的访问权限。可以设置的三种访问模式与PV相同。
PV选择条件(Selector):通过Label Selector的设置,可使PVC对于系统中已存在的各种PV进行筛选。系统将根据标签选择出合适的PV与该PVC进行绑定。选择条件可以使用matchLabels和matchExpressions进行设置。如果两个条件都设置了,则Selector的逻辑是两组条件同时满足才能完成匹配。
存储类别(Class):PVC在定义时可以设定需要的后端存储的"类别"(通过storageClassName字段指定),以降低对后端存储特性的详细信息的依赖。只有设置了该Class的PV才能被系统选出,并与该PVC进行绑定。
PVC也可以不设置Class需求。如果storageClassName字段的值被设置为空(storageClassName=""),则表示该PVC不要求特定的Class,系统将只选择未设定Class的PV与之匹配和绑定。PVC也可以完全不设置storageClassName字段,此时将根据系统是否启用了名为"DefaultStorageClass"的admission controller进行相应的操作。
未启用DefaultStorageClass:等效于PVC设置storageClassName的值为空,即只能选择未设定Class的PV与之匹配和绑定。
启用了DefaultStorageClass:要求集群管理员已定义默认的StorageClass。如果系统中不存在默认的StorageClass,则等效于不启用DefaultStorageClass的情况。如果存在默认的StorageClass,则系统将自动为PVC创建一个PV(使用默认StorageClass的后端存储),并将它们进行绑定。集群管理员设置默认StorageClass的方法为,在StorageClass的定义中加上一个annotation "storageclass.kubernetes.io/is-default-class=true"。如果管理员将多个StorageClass都定义为default,则由于不唯一,系统将无法为PVC创建相应的PV。
注意,PVC和PV都受限于namespace,PVC在选择PV时受到namespace的限制,只有相同namespace中的PV才可能与PVC绑定。Pod在引用PVC时同样受namespace的限制,只有相同namespace中的PVC才能挂载到Pod内。
当Selector和Class都进行了设置时,系统将选择两个条件同时满足的PV与之匹配。
另外,如果资源供应使用的是动态模式,即管理员没有预先定义PV,仅通过StorageClass交给系统自动完成PV的动态创建,那么PVC再设定Selector时,系统将无法为其供应任何存储资源了。
在启动动态供应模式的情况下,一旦用户删除了PVC,与之绑定的PV将根据其默认的回收策略"Delete"也会被删除。如果需要保留PV(用户数据),则在动态绑定成功后,用户需要将系统自动生成PV的回收策略从"Delete"改成"Retain"。
PV是和外部的服务器相连,Pod是不能使用的,要用PersistentVolumeClaim 简称 PVC 的资源来连接PV,Pod连接PVC 就可以使用了。类似于消息中间件的生产者和消费者的关系。PV是生产者,PVC是消费者。
PVC和PV是一一对应的,一个PV被PVC绑定后,不能被别的PVC绑定。
PV和PVC的生命周期
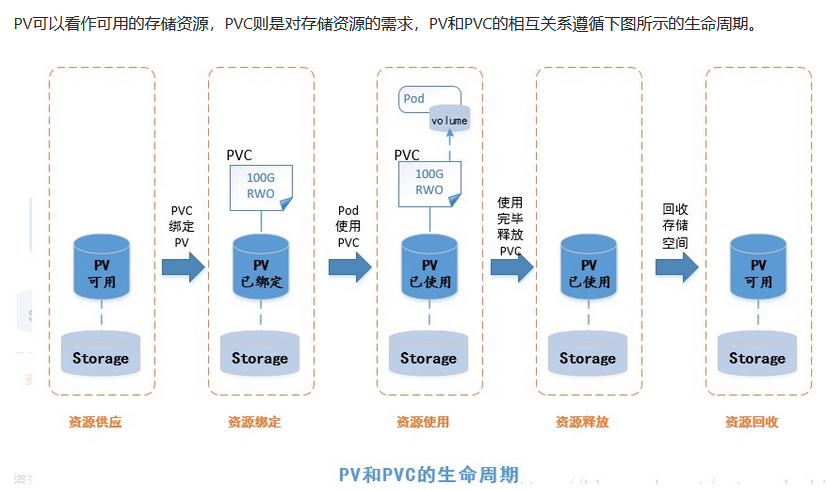
1 资源供应(Provisioning)
k8s支持两种资源的供应模式:静态模式(Static)和动态模式(Dynamic)。资源供应的结果就是创建好的PV。
静态模式:集群管理员手工创建许多PV,在定义PV时需要将后端存储的特性进行设置。
动态模式:集群管理员无须手工创建PV,而是通过StorageClass的设置对后端存储进行描述,标记为某种“类型(Class)”。此时要求PVC对存储类型进行声明,系统将自动完成PV的创建及与PVC的绑定。PVC可以声明Class为"",说明该PVC禁止使用动态模式。
2 资源绑定(Binding)
在用户定义好PVC之后,系统将根据PVC对存储资源的请求(存储空间和访问模式)在已存在的PV中选择一个满足PVC要求的PV,一旦找到,就将该PV与用户定义的PVC进行绑定,然后用户的应用就可以使用这个PVC了。如果系统中没有满足PVC要求的PV,PVC就会无限期处于Pending状态,直到等到系统管理员创建了一个符合其要求的PV。PV一旦绑定到某个PVC上,就被这个PVC独占,不能再与其他PVC进行绑定了。在这种情况下,当PVC申请的存储空间与PV的少时,整个PV的空间都会被PVC所用,可能会造成资源的浪费。如果资源供应使用的是动态模式,则系统在为PVC找到合适的StorageClass后,将自动创建一个PV并完成与PVC的绑定。
3 资源使用(Using)
Pod使用volume的定义,将PVC挂载到容器内的某个路径进行使用。volume的类型为"persistentVolumeClaim",在后面的示例中再进行详细说明。在容器应用挂载了一个PVC后,就能被持续独占使用。不过,多个Pod可以挂载同一个PVC,应用程序需要考虑多个实例共同访问同一块存储空间的问题。
4 资源释放(Releasing)
当用户对存储资源使用完毕后,用户可以删除PVC,与该PVC绑定的PV将会被标记为“已释放”,但还不能立刻与其他PVC进行绑定。通过之前PVC写入的数据可能还留在存储设备上,只有在清除之后该PV才能再次使用。
5 资源回收(Reclaimig)
对于PV,管理员可以设定回收策略(Reclaim Policy),用于设置与之绑定的PVC释放资源之后,对于遗留数据如何处理。只有PV的存储空间完成回收,才能供新的PVC绑定和使用。
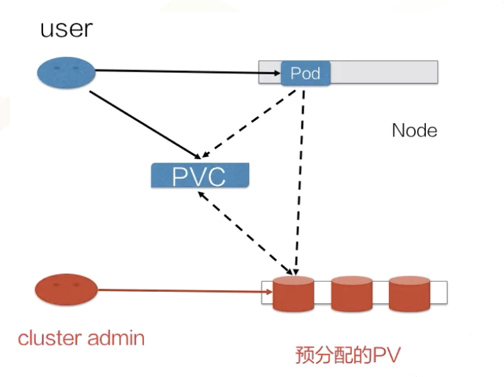
下面通过两张图分别对在静态资源供应模式和动态资源供应模式下,PV、PVC、StorageClass及Pod使用PVC的原理进行说明。
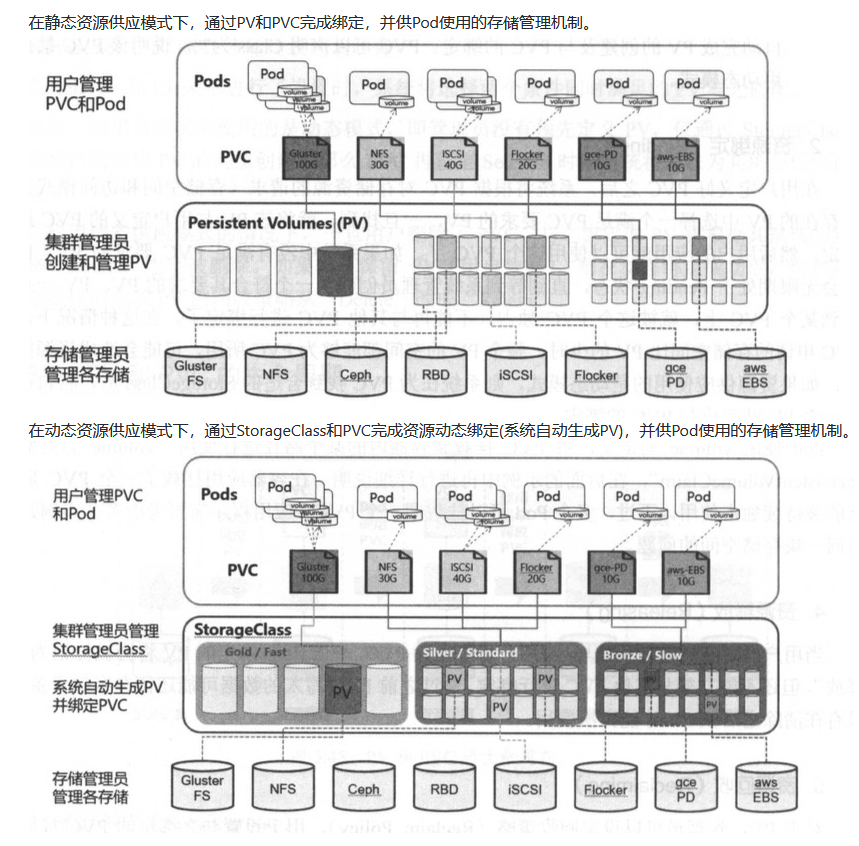
使用案例
1.使用nfs作为存储客户端
# 安装nfs
yum install -y nfs-utils
# 创建nfs目录
mkdir -p /nfs/data/nginx
# 授予权限
chmod -R 777 /nfs/data
# 编辑export文件
vim /etc/exports
/nfs/data/nginx *(rw,no_root_squash,sync)
# 使得配置生效
exportfs -r
# 查看生效
exportfs
# 启动rpcbind、nfs服务
systemctl restart rpcbind && systemctl enable rpcbind
systemctl restart nfs && systemctl enable nfs
# 查看rpc服务的注册情况
rpcinfo -p localhost
# showmount测试
showmount -e ip(ip地址)
2.在K8S集群所有节点上安装NFS客户端
yum -y install nfs-utils
systemctl start nfs && systemctl enable nfs
- 定义PV,跟NFS做关联
# cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nginx-pv
spec:
accessModes:
- ReadWriteMany
capacity:
storage: 2Gi
nfs:
path: /nfs/data/nginx
server: 10.6.229.62
4.定义pvc,使用pv
# cat pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi
- 定义pod,使用pvc
使用 persistentVolumeClaim:claimName: nginx-pvc 定义了要使用名字为nginx-pvc的 PVC
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
volumeMounts:
- name: nginx-persistent-storage
mountPath: /usr/share/nginx/html
volumes:
- name: nginx-persistent-storage
persistentVolumeClaim:
claimName: nginx-pvc
- 查看效果
当提交完yaml之后,pod可以通过该PVC找到绑定的PV。挂载完成后,在Pod内可以看到挂载,在主机上也可以看到挂载。
总结1
可以把上述pv&pvc绑定理解成静态方式,集群管理员事先规划用户怎样使用存储,并预分配一些存储(即预创建一些 PV)
pv配置yaml文件中的有关参数解释:
spec.capacity.storage字段表明创建的存储的大小
spec.accessModes字段是PV访问策略控制列表,表明创建出来的存储的访问方式
ReadWriteOnce只允许单node上的Pod访问
ReadOnlyMany允许多个node的Pod只读访问
ReadWriteMany允许多个node上的Pod读写访问
spec.persistentVolumeReclaimPolicy表明该Volume使用后被release之后(即与之绑定的PVC被删除后)的回收策略
spec.nodeAffinity字段限制了可以访问该volumes的node,对使用该Volume的Pod调度有影响
spec.csi表明此处使用的是CSI存储:
driver:指定由什么volume plugin来挂载该volume(需要提前在node上部署)
volumeHandle:指示PV的唯一标签
volumeAttribute:用于附加参数,比如PV定义的是OSS,就可以在这里定义bucket、访问的地址等信息
spec.flexVolume表明此处使用的是flexVolume存储:
driver:实现的驱动类型
fsType:文件系统类型
options:包含的具体的参数
PV 状态
- Available:未被任何PVC使用
- Bound:绑定到了PVC上
- Released:PVC被删掉,资源未被使用
- Failed:自动回收失败
pvc配置yaml文件中的有关参数解释:
spec.resources.requests.storage字段声明存储的大小需求
spec.accessModes字段声明访问方式
一些属性
- Access Modes
- Volume Modes
- Resources
- Selector:PVC可以通过标签选择器选择PV资源。可以包含两个字段matchLabels和matchExpressions。
- storageClassName 类似标签选择器,通过storagClassName 来确定PV资源。
PV的状态流转:
创建PV对象后,它会暂时处于pending状态。等真正的PV创建好之后,它处在available状态(可以使用)。
创建PVC对象后,它会暂时处于pending状态,直到PV和PVC就结合到一起,此时两者都处在bound状态。
当用户在使用完PVC将其删除后,PV处于released状态,依赖于ReclaimPolicy配置被删除或保留:
- Recycle(已废弃):会进入Available状态;如果转变失败,就会进入Failed 的状态。
- Delete:Volume被released之后直接删除,需要volume plugin支持
- Retain:默认策略,由系统管理员来手动管理该Volume。此时PV已经处在released状态下,没有办法再次回到available状态(即无法被一个新的PVC绑定),需要:
新建一个PV对象,把之前的released的PV的相关字段的信息填到新的PV对象里面,这个PV就可以结合新的PVC了;
删除pod之后不删除PVC对象,这样给PV绑定的PVC还是存在的,下次pod使用的时候,就可以直接通过PVC去复用。(K8s中的StatefulSet管理的Pod带存储的迁移就是通过这种方式)。
修改PV的spec.claimRef字段,该字段记录着原来PVC的绑定信息,删除绑定信息,即可重新释放PV从而达到Available。
处于Bound状态的PVC,与其关联的PV被删除后,变成Lost状态;重新与PV绑定后变成Bound状态。
问题1:PV,PVC都定义好了,在PVC定义中并没有看到和PV绑定的相关配置,那他们两个是怎么绑定的呢?
K8s内部相关组件会根据PVC的size和accessMode,判断它跟静态创建的哪个PV匹配,然后绑定到一起。
注:一个PV可以设置多个访问策略。PVC与PV绑定时,PV Controller会优先找到AccessModes列表最短并且匹配PVC AccessModes列表的PV集合,然后从该集合中找到Capacity最小且符合PVC size需求的PV对

问题2:关联pvc到特定的pv?
参考网址:https://www.cnblogs.com/sanduzxcvbnm/p/14695032.html
问题3:
1.使用的pv数量比较多,难道需要一一创建?
2.pvc没有找到合适的pv进行绑定,需要再次手动创建合适的pv,这样是不是太麻烦了?
解决办法:
假如有一个模板,pvc想要多少资源,直接在模板里配置好,启动的时候自动创建对应的pv资源,上面的问题是不是就解决了。这就是StorageClass的功能
StorageClass
可以把上述步骤理解成静态产生方式 - Static Volume Provisioning,使用StorageClass可以理解成是动态产生方式 - Dynamic Volume Provisioning
集群管理员不预分配PV,而是预先准备StoregeClass(创建PV的模板),它包含了创建某种具体类型(块存储、文件存储等)的PV所需要的参数信息。StorageClass为管理员提供了描述存储 "类" 的方法
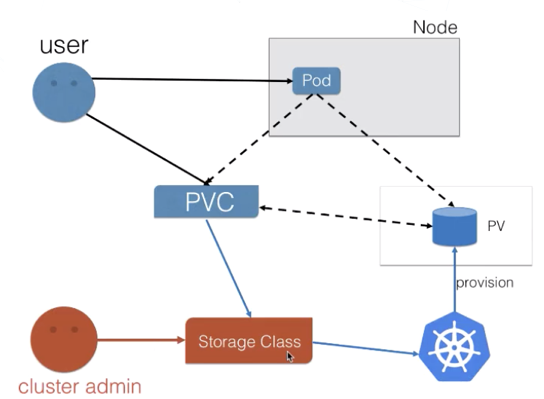
每个StorageClass都包含字段provisioner、参数和reclaimPolicy,这些字段在属于该类的PersistentVolume需要动态配置时使用。
StorageClass对象的名称很重要,它是用户请求特定类的方式。管理员在第一次创建StorageClass对象时设置类的名称和其他参数,这些对象一旦创建就无法更新。
StorageClass声明存储插件,用于自动创建PV。说白了就是创建PV的模板,其中有两个重要部分:PV属性和创建此PV所需要的插件。这样PVC就可以按“Class”来匹配PV。可以为PV指定storageClassName属性,标识PV归属于哪一个Class。
StorageClass的定义主要包括名称、后端存储的提供者(Provisioner)和后端存储的相关参数配置。StorageClass一旦被创建出来,就将无法修改,只能删除原StorageClass的定义重建。下面的例子中定义了一个名为“standard"的StorageClass,提供者为aws-ebs,其参数设置了一个type=gp2。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
1 StorageClass的关键配置参数
1)提供者(Provisioner)
描述存储资源的提供者,也可以看作后端存储驱动。
目前k8s支持的Provisioner都以"kubernetes.io/"为开头,用户也可以使用自定义的后端存储提供者。为了符合StorageClass的用法,自定义Provisioner需要符合存储卷的开发规范,详见该链接的说明:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/storage/volume-provisioning.md 。
2)参数(Parameters)
后端存储资源提供者的参数设置,不同的Provisioner包括不同的参数设置。某些参数可以不显示设定,Provisioner将使用其默认值。
设置默认的StorageClass
要在系统中设置一个默认的StorageClass,首先需要启动名为"DefaultStorageClass"的admission controller, 即在kube-apiserver的命令行参数--admission-controll中增加:
--admission-control=...,DefaultStorageClass
然后,在StorageClass的定义中设置一个annotation:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
annotations:
storageclass.beta.kubernetes.io/is-default-class="true"
provisioner: kubernetes.io/cinder
parameters:
type: fast
availability: nova
通过kubectl create命令创建成功后,查看StorageClass列表,可以看到名为gold的StorageClass被标记为"default":
# kubectl get sc
gold (default) kubernetes.io/cinder
1、storageClassName 类似标签选择器,通过storagClassName 来确定PV资源。
2、PVC与PV匹配可以通过StorageClassName、matchLabels或者matchExpressions三种方式
对于PV或者StorageClass只能对应一种后端存储
对于手动的情况,一般我们会创建很多的PV,等有PVC需要使用的时候就可以直接使用了
对于自动的情况,那么就由StorageClass来自动管理创建
如果Pod想要使用共享存储,一般会在创建PVC,PVC中描述了想要什么类型的后端存储、空间等,K8s从而会匹配对应的PV,如果没有匹配成功,Pod就会处于Pending状态。Pod中使用只需要像使用volumes一样,指定名字就可以使用了
一个Pod可以使用多个PVC,一个PVC也可以给多个Pod使用
一个PVC只能绑定一个PV,一个PV只能对应一种后端存储
sc实际操作
1.准备好NFS服务器[并且确保nfs可以正常工作],创建持久化需要的目录。
path: /nfs/data/class
server: 10.6.229.62
以下yaml配置文件的参考网址:https://github.com/kubernetes-retired/external-storage/tree/master/nfs-client/deploy
2.创建rbac.yaml
这个文件是创建授权账户。在K8S中, ApiServer 组件管理创建的 deployment, pod,service等资源,但是有些资源它是管不到的,比如说 K8S本身运行需要的组件等等,同样StorageClass这种资源它也管不到,所以,需要授权账户。
在master上创建:kubectl apply -f rbac.yaml
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
- apiGroups: [""]
resources: ["services", "endpoints"]
verbs: ["get"]
- apiGroups: ["extensions"]
resources: ["podsecuritypolicies"]
resourceNames: ["nfs-provisioner"]
verbs: ["use"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-provisioner
apiGroup: rbac.authorization.k8s.io
3.根据deployment.yaml文件创建资源
在master上创建:kubectl apply -f deployment.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: nfs-provisioner
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-provisioner
image: registry.cn-hangzhou.aliyuncs.com/open-ali/nfs-client-provisioner
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: example.com/nfs
- name: NFS_SERVER
value: 10.6.229.62
- name: NFS_PATH
value: /nfs/data/class
volumes:
- name: nfs-client-root
nfs:
server: 10.6.229.62
path: /nfs/data/class
4.根据class.yaml创建资源
在master上创建:kubectl apply -f class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: example-nfs
provisioner: example.com/nfs # must match deployment's env PROVISIONER_NAME'
5.根据my-pvc.yaml创建资源
在master上创建:kubectl apply -f my-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
# 我们定义了1M的PVC,storageClass会自动给我们创建这个资源,不用再去手动创建1M的PV
storage: 1Mi
# 这个名字要和上面创建的storageclass名称一致
storageClassName: example-nfs
6.根据nginx-pod.yaml创建资源
在master上创建:kubectl apply -f nginx-pod.yaml
kind: Pod
apiVersion: v1
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: my-pvc
mountPath: "/usr/class"
restartPolicy: "Never"
volumes:
- name: my-pvc
persistentVolumeClaim:
claimName: my-pvc
需要注意一点的是,NFS服务器下的/nfs/data/class并不是数据存储的根目录,pod起来之后,会自动在里面创建一个文件夹来存放数据。
部分参数解析:
-
reclaimPolicy
表示由SC动态创建出来的PV使用结束后(Pod及PVC被删除后)该怎么处理,可以是Delete(默认)或者 Retain -
allowVolumeExpansion
若设置为true,则部分存储(如CSI)支持卷扩展,可以编辑PVC对象来扩大(不能缩小)卷大小 -
mountOptions
由SC动态创建的PV将使用该字段指定的挂载选项。但挂载选项在SC和PV上都不会做验证,如果卷插件不支持挂载选项,则分配操作会失败。 -
volumeBindingMode
控制了卷绑定和动态分配的发生时间。
Immediate模式表示一旦创建了PVC,也就完成了卷的动态分配和绑定。对于由于拓扑限制而非集群所有节点可达的存储后端,PV会在不知道Pod调度要求的情况下分配、绑定。
WaitForFirstConsumer模式将延迟PV的分配和绑定,直到使用该PVC的Pod被创建。PV再根据Pod调度约束指定的拓扑来选择和分配。 -
allowedTopologies
指定了允许的拓扑结构
volumeBindingMode配置为WaitForFirstConsumer模式的情况下一般无需再进行配置此字段
需要动态创建的PV就有拓扑位置的限制时需要配置同时配置WaitForFirstConsumer和allowedTopologies,这样既限制了动态创建的PV要能被这个可用区访问、也限制了Pod在选择node时要落在这个可用区内 -
parameters
以key:values的形式描述属于卷的参数,最多可定义512个,总长度不超过256KB
PV分配器可以接受哪些参数,需要后端存储的提供者提供。
用户在PVC中指定需要使用的StoregeClass模板。PVC配置文件里存储的大小、访问模式的配置是不变的,只需新增spec.StorageClassName字段,指定动态创建PV的模板文件的名字。
新增后,若PVC找不到相应的PV,就会用该标签所指定的StorageClass去动态创建PV,并将PVC和PV进行绑定;存在一个满足条件的PV时,就会直接使用现有的PV。
PV的状态和回收策略
PV的状态
Available:表示当前的pv没有被绑定
Bound:表示已经被pvc挂载
Released:pvc没有在使用pv, 需要管理员手工释放pv
Failed:资源回收失败
PV回收策略
Retain:表示删除PVC的时候,PV不会一起删除,而是变成Released状态等待管理员手动清理
Recycle:在Kubernetes新版本就不用了,采用动态PV供给来替代
Delete:表示删除PVC的时候,PV也会一起删除,同时也删除PV所指向的实际存储空间
注意:目前只有NFS和HostPath支持Recycle策略。AWS EBS、GCE PD、Azure Disk和Cinder支持Delete策略
存储快照
k8s引入了存储快照功能,不过只有CSI支持
VolumeSnapshotContent/VolumeSnapshot/VolumeSnapshotClass体系与PV/PVC/SC体系类似
首先创建VolumeSnapshotClass
apiVersion: snapshot.storage.k8s.io/v1a1pha1
kind: VolumeSnapshotClass
metadata:
name: disk-snapshotclass
snapshotter: diskplug.csi.alibabacloud.com
snapshotter指定了真正创建存储快照所使用的Volume Plugin
然后通过Volumesnapshot声明创建存储快照:
apiVersion: snapshot.storage.k8s.io/v1a1pha1
kind: VolumeSnapshot
metadata:
name:disk-snapshot
namespace: xxx
spec:
snapshotClassName: disk-snapshotclass
source:
name: disk-pvc
kind: PersistentVolumeClaim
spec.snapshotClassName指定了使用的VolumeSnapshotClass
spec.source.name指定了作为数据源的PVC
提交VolumeSnapshot对象后,集群中的相关组件会找到数据源PVC对应的PV存储,对这个PV存储做一次快照。并自动创建volumesnapshotcontent对象。
volumesnapshotcontent对象中记录了云存储厂商返回的snapshot的ID、作为数据源的PVC
删除VolumeSnapshot后volumesnapshotcontent也会自动删除
数据恢复时,将PVC对象的spec.dataSource指定为VolumeSnapshot对象。这样当PVC提交之后,会由集群中的相关组件找到dataSource所指向的VolumeSnapshotContent,然后新创建对应的存储以及pv对象,将存储快照数据恢复到新的pv中。
k8s的存储架构
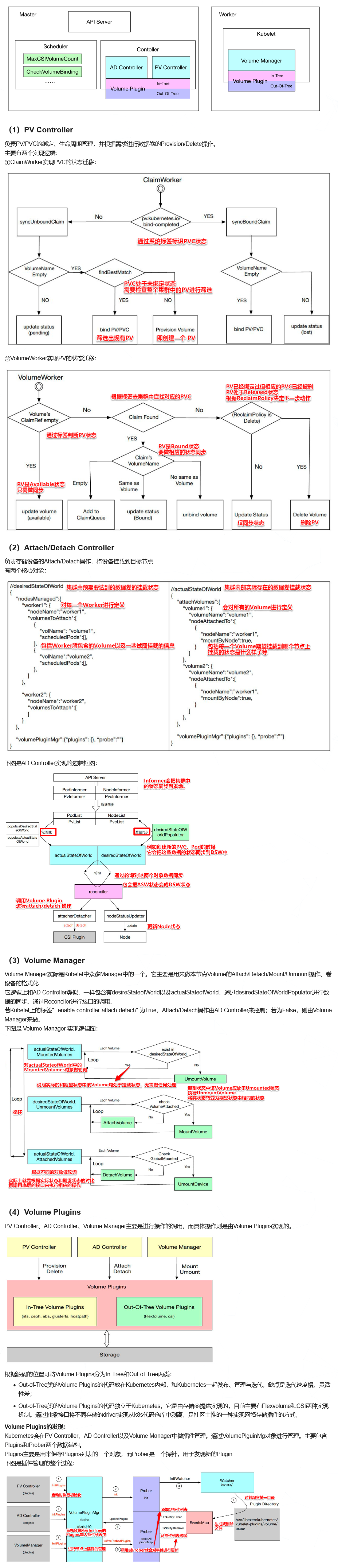
参考网址:
https://www.orchome.com/1284#item-4
https://www.cnblogs.com/yangyuliufeng/p/14301359.html
https://blog.csdn.net/cuixhao110/article/details/105858553
https://blog.csdn.net/qq_33591903/article/details/103783627
https://www.cnblogs.com/cocowool/p/kubernetes_storage.html
https://www.cnblogs.com/fat-girl-spring/p/14545547.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!