

多字段特性及配置自定义Analyzer


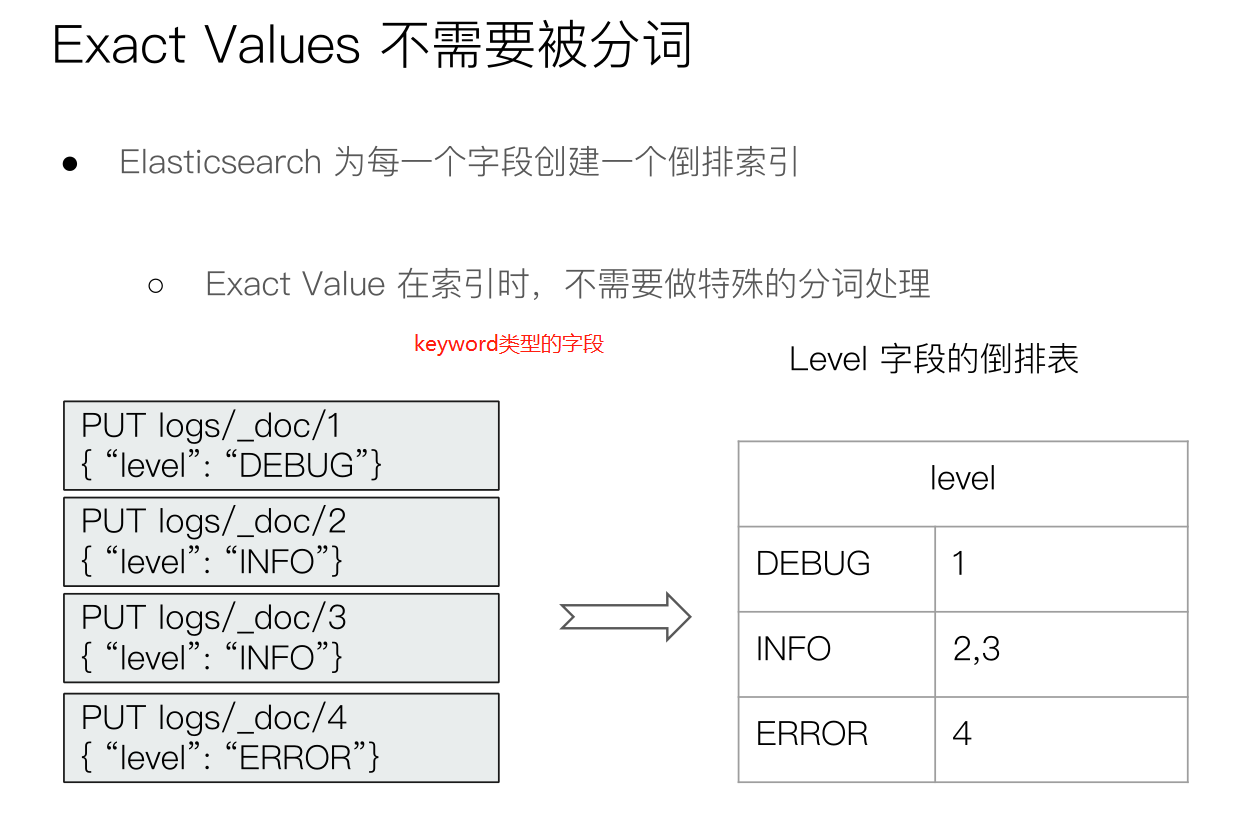





PUT logs/_doc/1
{"level":"DEBUG"}
GET /logs/_mapping
POST _analyze
{
"tokenizer":"keyword",
"char_filter":["html_strip"],
"text": "<b>hello world</b>"
}
POST _analyze
{
"tokenizer":"path_hierarchy",
"text":"/user/ymruan/a/b/c/d/e"
}
#使用char filter进行替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ "- => _"]
}
],
"text": "123-456, I-test! test-990 650-555-1234"
}
//char filter 替换表情符号
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ ":) => happy", ":( => sad"]
}
],
"text": ["I am felling :)", "Feeling :( today"]
}
// white space and snowball
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
// whitespace与stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The rain in Spain falls mainly on the plain."]
}
//remove 加入lowercase后,The被当成 stopword删除
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["lowercase","stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
//正则表达式
GET _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "pattern_replace",
"pattern" : "http://(.*)",
"replacement" : "$1"
}
],
"text" : "http://www.elastic.co"
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!