

Logstash & 索引生命周期管理(ILM)
Grok语法
Grok是通过模式匹配的方式来识别日志中的数据,可以把Grok插件简单理解为升级版本的正则表达式。它拥有更多的模式,默认,Logstash拥有120个模式。如果这些模式不满足我们解析日志的需求,我们可以直接使用正则表达式来进行匹配。
官网:
https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
grok模式的语法是:%{SYNTAX:SEMANTIC}
SYNTAX指的是Grok模式名称,SEMANTIC是给模式匹配到的文本字段名。例如:
%{NUMBER:duration} %{IP:client}
duration表示:匹配一个数字,client表示匹配一个IP地址。
默认在Grok中,所有匹配到的的数据类型都是字符串,如果要转换成int类型(目前只支持int和float),可以这样:%{NUMBER:duration:int} %{IP:client}
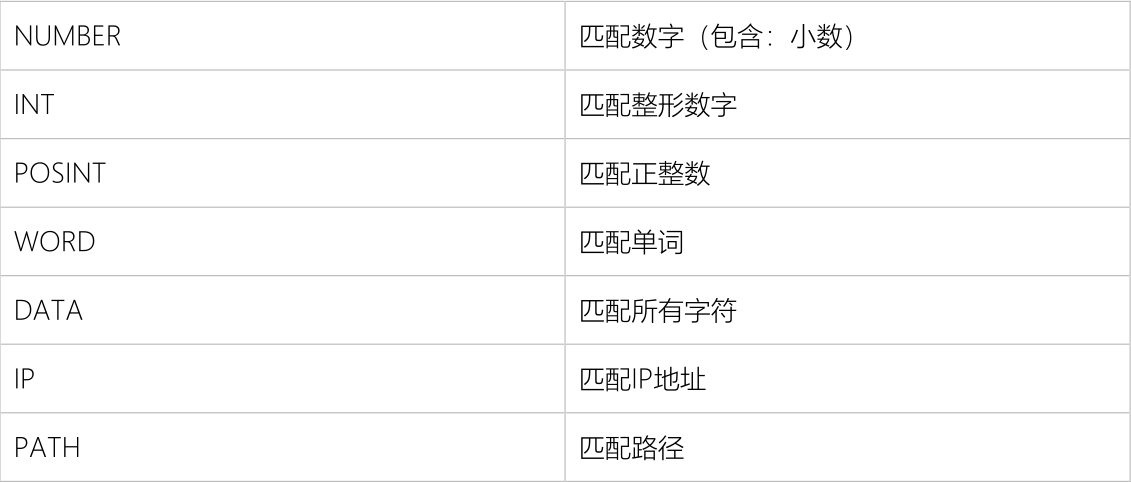
以下是常用的Grok模式:
索引生命周期管理(ILM)
Elasticsearch索引生命周期管理指的是:Elasticsearch从创建索引、打开索引、关闭索引、删除索引的全生命过程的管理。
在大型Elasticsearch应用中,一般采用多索引结合基于时间、索引大小的横向扩展方式存储数据,随着数据量的增加,而不需要修改索引的底层架构。
- 索引生命周期管理 (ILM) 是在Elasticsearch 6.6首次引入,并在 6.7 版正式推出的一项功能
- ILM 是Elasticsearch的一部分,主要用来帮助管理索引
- 基于Elasticsearch的ILM可以实现热温冷架构
热温冷架构
- 热温冷架构常用于日志或指标类的时序数据
- 例如,假设正在使用 Elasticsearch 聚合来自多个系统的日志文件
- 今天的日志正在频繁地被索引,且本周的日志搜索量最大(热)
- 上周的日志可能会被频繁搜索,但频率没有本周日志那么高(温)
- 上月日志的搜索频率可能较高,也可能较低,但最好保留一段时间以防万一(冷)
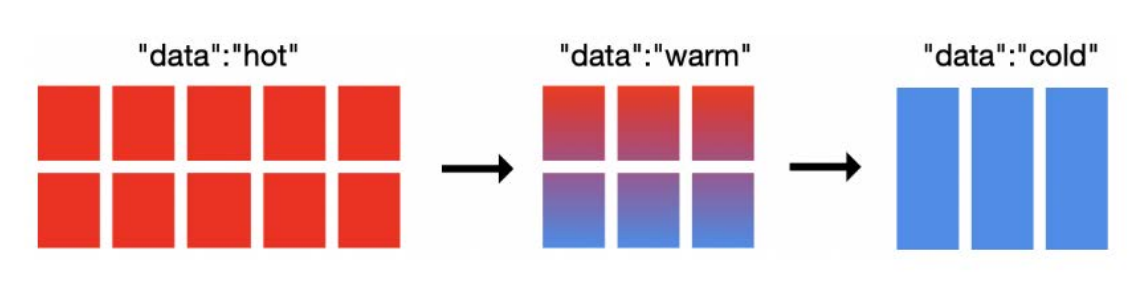
上图, 集群中有19个节点: 10个了热节点、 6个温节点、 3个冷节点。 冷节点是可选的。 Elasticsearch中,可以定义哪些节点是热节点、温节点或冷节点。
- ILM 允许定义何时在两个阶段之间移动,以及在进入那个阶段时如何处理索引
- 对于热温冷架构,没有一成不变的设置。但是,通常而言,热节点需要较多的 CPU 资源和较快的 IO。对于温节点和冷节点来说,通常每个节点会需要更多的磁盘空间,但即便使用较少的 CPU 资源和较慢的 IO 设备,也能勉强应付
配置分片分配感知
热温冷依赖于分片分配感知,因此,首先标记哪些节点是热节点、温节点和(可选)冷节点。
集群规划:

使用以下命令可以一键关键Elasticsearch集群:
jps | grep Elasticsearch | cut -f1 -d" " | xargs kill -9
配置ILM策略
- 要进行索引生命周期管理,需要配置ILM策略,ILM策略可以在选择的任意索引应用
- ILM策略主要分为四个主要阶段:热、温、冷、删除
- 不需要在一个策略中定义每个阶段, ILM 会始终按该顺序执行各个阶段 (跳过任何未定义的阶段)
- 可以通过配置ILM策略来定义什么时间进入该阶段,还可以定义按照什么样的方式来管理索引
以下代码是创建一个最基本的ILM策略:
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
这个策略规定,在索引存储时间达到 30 天后或者索引大小达到 50GB(基于主分片)时,就会滚更新该索引并开始写入一个新索引。
ILM与索引模板
当索引类型和配置信息都一样,就可以使用索引模板来处理,不然每次创建索引都需要指定很多的索引参数。例如:指定refresh的周期、主分片的数量、副本数量、以及translog的一些配置等等
创建一个名为my_template模板,并与ILM策略关联:
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
对于配置了滚动更新操作的策略,必须要在创建索引模板后使用写入别名启动索引
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
配置了滚动更新的要求得到满足后,任何以 test-* 开头的新索引将在 30 天后或达到 50GB 时自动滚动更新。通过使用滚动更新管理以 max_size 开头的索引后,可以极大减少索引的分片数量,进而减少开销。
配置用于采集的ILM策略
- Beats 和 Logstash 都支持 ILM,并在启用后将设置一个类似上例所示的默认策略
- 当为 Beats 和 Logstash 启用 ILM 时,除非每天索引量很大(大于 50GB/天),否则索引大小将可能是确定何时创建新索引的主要因素
- 从 7.0.0 开始,带有滚动更新的 ILM 将是 Beats 和 Logstash 的默认配置
- 由于针对热温冷架构没有一成不变的设置,因此,Beats 和 Logstash 将不会自动配置好热温冷策略。我们可以制定一个适用于热温冷的新策略,并在这一过程中进行一些优化。
针对温热冷优化ILM策略
下面配置创建了针对热温冷架构优化的 ILM 策略。
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "30d"
},
"set_priority": {
"priority": 50
}
}
}
- 这个 ILM 策略首先会将索引优先级设置为一个较高的值,以便热索引在其他索引之前恢复
- 30天后或达到 50GB 时(符合任何一个即可),该索引将滚动更新,系统将创建一个新索引
- 该新索引将重新启动策略,而当前的索引(刚刚滚动更新的索引)将在滚动更新后等待 7 天再进入温阶段
"warm": {
"min_age": "7d", # 索引7天进入到温阶段
"actions": {
"forcemerge": {
"max_num_segments": 1 # 前置合并segment为1
},
"shrink": {
"number_of_shards": 1 # 设置分片数量为1
},
"allocate": {
"require": {
"data": "warm" # 移动到温节点
}
},
"set_priority": {
"priority": 25 # 优先级比热阶段低
}
}
}
索引进入温阶段后,ILM 会将索引收缩到 1 个分片,将索引强制合并为 1 个段,并将索引优先级设置为比热阶段低(但比冷阶段高)的值,通过分配操作将索引移动到温节点。完成该操作后,索引将等待 30 天(从滚动更新时算起)后进入冷阶段。
"cold": {
"min_age": "30d", # 索引进入温阶段后,经过30天进入冷阶段
"actions": {
"set_priority": {
"priority": 0 # 优先级更低
},
"freeze": {},
"allocate": {
"require": {
"data": "cold" # 将索引移动到冷节点
}
}
}
}
索引进入冷阶段后, ILM 将再次降低索引优先级, 以确保热索引和温索引得到先行恢复。 然后, ILM将冻结索引并将其移动到冷节点。完成该操作后,索引将等待 60 天(从滚动更新时算起)后进入删除阶段。
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
删除阶段具有用于删除索引的删除操作。在删除阶段,您将始终需要有一个 min_age 条件,以允许索引在给定时段内待在热、温或冷阶段。
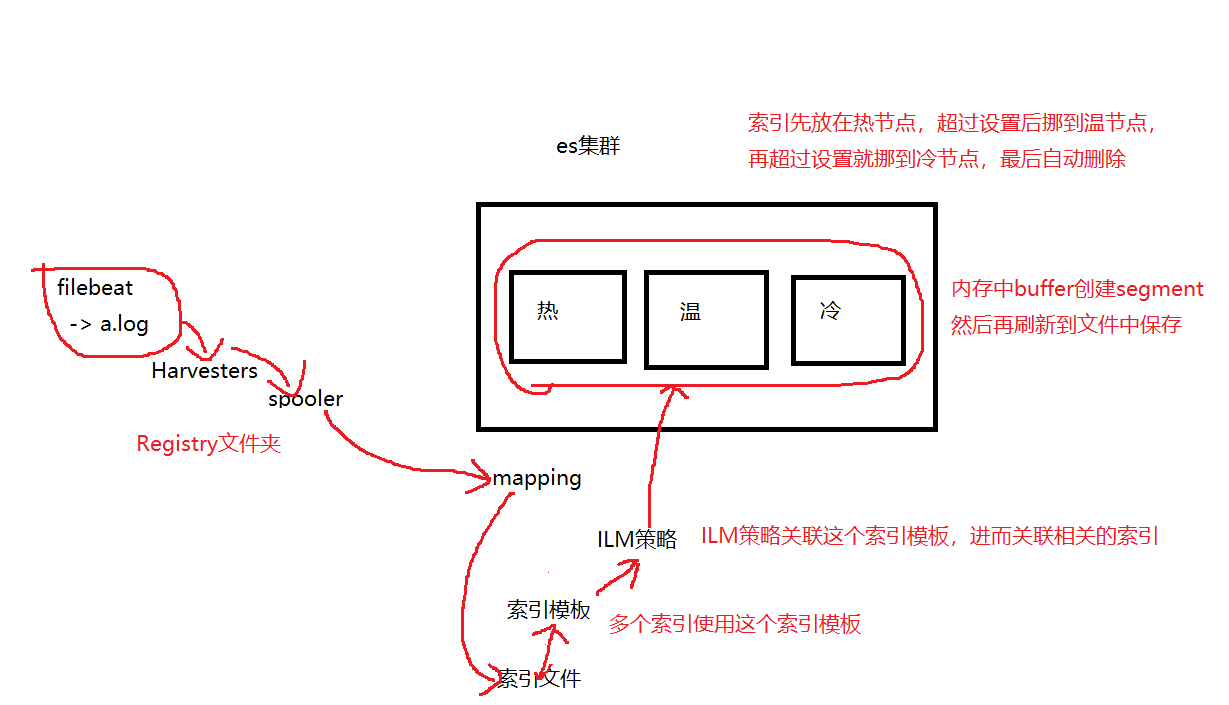
图示汇总


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2016-11-17 企业版 Linux 附加软件包(EPEL)
2016-11-17 centos7系统修改内核
2016-11-17 使用yum update更新文件系统时不更新内核的方法