Elasticsearch SQL
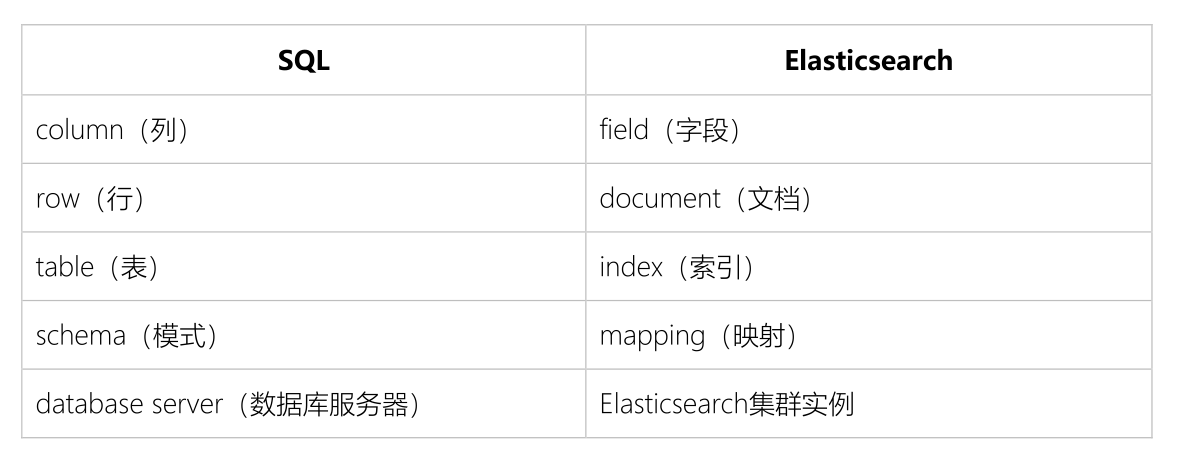
SQL与Elasticsearch对应关系
Elasticsearch SQL语法
SELECT select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
目前FROM只支持单表
职位查询案例
查询职位索引库中的一条数据
# format:表示指定返回的数据类型
// 1. 查询职位信息
GET /_sql?format=txt
{
"query": "SELECT * FROM job_idx limit 1"
}

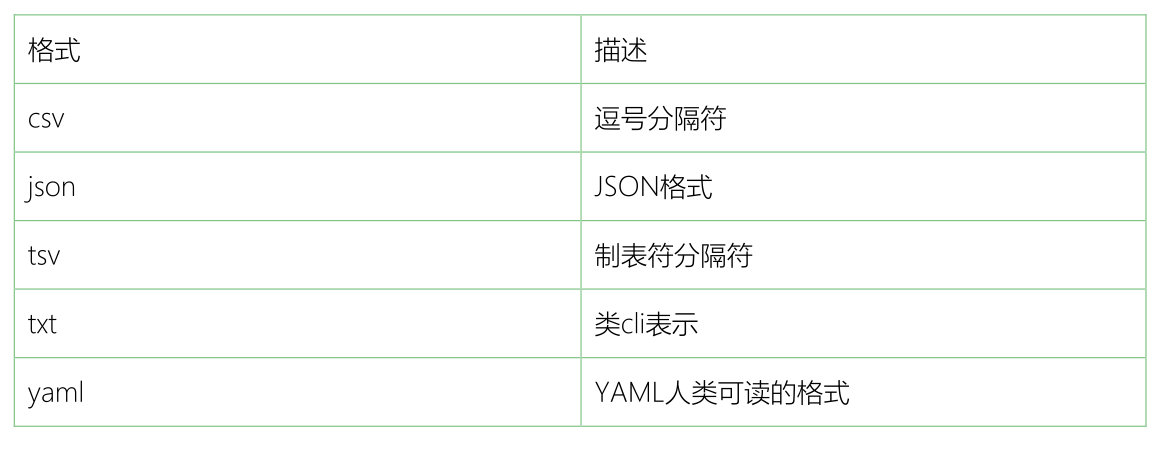
除了txt类型,Elasticsearch SQL还支持以下类型,
将SQL转换为DSL
GET /_sql/translate
{
"query": "SELECT * FROM job_idx limit 1"
}
结果如下:
{
"size": 1,
"_source": {
"includes": [
"area",
"cmp",
"exp",
"jd",
"title"
],
"excludes": []
},
"docvalue_fields": [
{
"field": "edu"
},
{
"field": "job_type"
},
{
"field": "pv"
},
{
"field": "salary"
}
],
"sort": [
{
"_doc": {
"order": "asc"
}
}
]
}
职位scroll分页查询
第一次查询
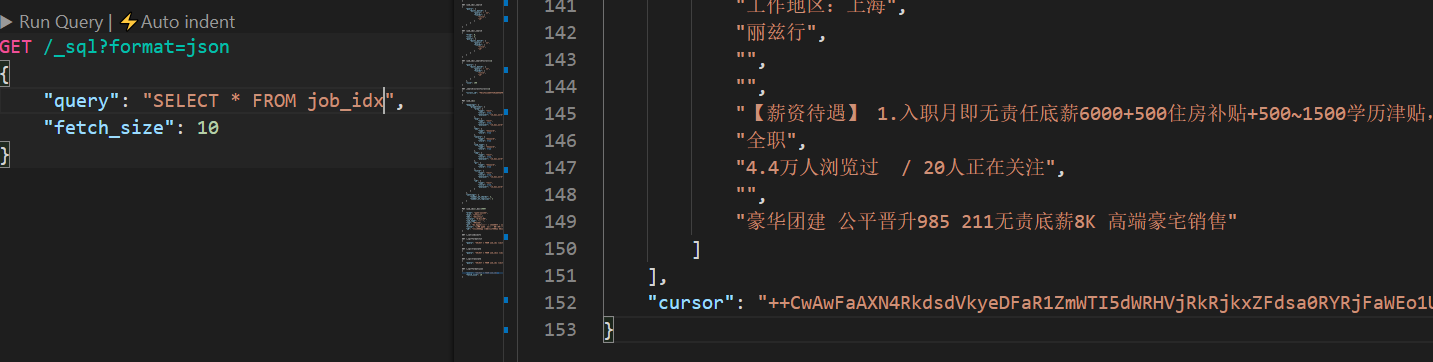
// 2. scroll分页查询
GET /_sql?format=json
{
"query": "SELECT * FROM job_idx",
"fetch_size": 10
}
fetch_size表示每页显示多少数据,而且当我们指定format为Json格式时,会返回一个cursor ID。
默认快照的失效时间为45s,如果要延迟快照失效时间,可以配置为以下:
GET /_sql?format=json
{
"query": "select * from job_idx",
"fetch_size": 1000,
"page_timeout": "10m"
}
第二次查询
GET /_sql?format=json
{
"cursor": "++CwAwFaAXN4RkdsdVkyeDFaR1ZmWTI5dWRHVjRkRjkxZFdsa0RYRjFaWEo1UVc1a1JtVjBZMmdCRkRkWFRqTXdTRlZDYTA1bFZWVnhSMU54VG1abEFBQUFBQUFBQzRZV1NsaGxNV296UVV0VWF6WkVlbmRQUzBsQ2MxZDNadz09/////w8JAWYEYXJlYQEEYXJlYQEEdGV4dAAAAAFmA2NtcAEDY21wAQR0ZXh0AAAAAWYDZWR1AQNlZHUBB2tleXdvcmQBAAABZgNleHABA2V4cAEEdGV4dAAAAAFmAmpkAQJqZAEEdGV4dAAAAAFmCGpvYl90eXBlAQhqb2JfdHlwZQEHa2V5d29yZAEAAAFmAnB2AQJwdgEHa2V5d29yZAEAAAFmBnNhbGFyeQEGc2FsYXJ5AQdrZXl3b3JkAQAAAWYFdGl0bGUBBXRpdGxlAQR0ZXh0AAAAAv8B"
}
清除游标
POST /_sql/close
{
"cursor": "++CwAwFaAXN4RkdsdVkyeDFaR1ZmWTI5dWRHVjRkRjkxZFdsa0RYRjFaWEo1UVc1a1JtVjBZMmdCRkRkWFRqTXdTRlZDYTA1bFZWVnhSMU54VG1abEFBQUFBQUFBQzRZV1NsaGxNV296UVV0VWF6WkVlbmRQUzBsQ2MxZDNadz09/////w8JAWYEYXJlYQEEYXJlYQEEdGV4dAAAAAFmA2NtcAEDY21wAQR0ZXh0AAAAAWYDZWR1AQNlZHUBB2tleXdvcmQBAAABZgNleHABA2V4cAEEdGV4dAAAAAFmAmpkAQJqZAEEdGV4dAAAAAFmCGpvYl90eXBlAQhqb2JfdHlwZQEHa2V5d29yZAEAAAFmAnB2AQJwdgEHa2V5d29yZAEAAAFmBnNhbGFyeQEGc2FsYXJ5AQdrZXl3b3JkAQAAAWYFdGl0bGUBBXRpdGxlAQR0ZXh0AAAAAv8B"
}
职位全文检索
需求
检索title和jd中包含hadoop的职位
MATCH函数
在执行全文检索时,需要使用到MATCH函数。
MATCH(
field_exp,
constant_exp
[, options])
- field_exp:匹配字段
- constant_exp:匹配常量表达式
实现
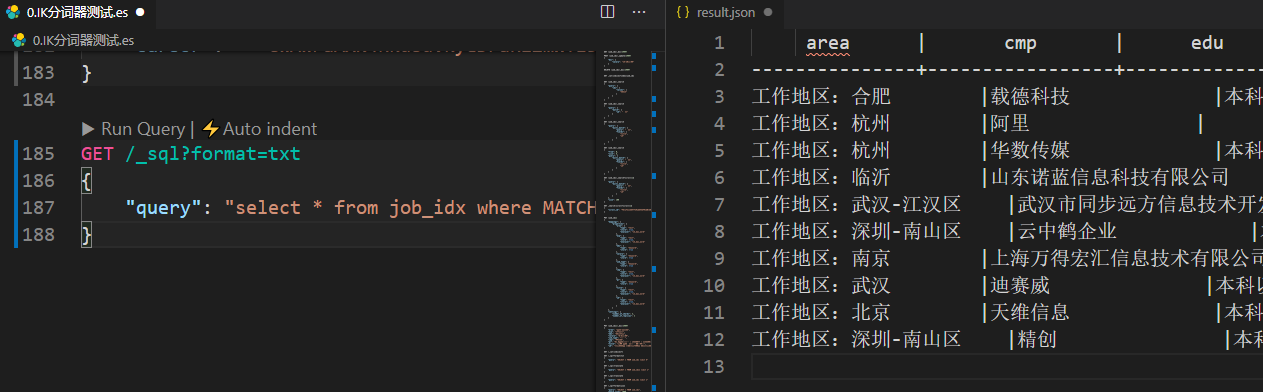
GET /_sql?format=txt
{
"query": "select * from job_idx where MATCH(title, 'hadoop') or MATCH(jd, 'hadoop') limit 10"
}