


12. Fluentd部署:多Workers进程模式
介绍如何使用Fluentd的多worker模式处理高访问量的日志事件。此模式会运行多个worker进程以最大利用多核CPU。
- 原理
默认情况下,一个Fluentd实例会运行一个监控进程和一个工作进程。工作进程包含了Input/Filter/Output各类插件。
多worker模式就是一个实例中启动了多个工作进程,这些工作进程负责处理日志事件,接受监控进程的管理和调度。如下图所示:
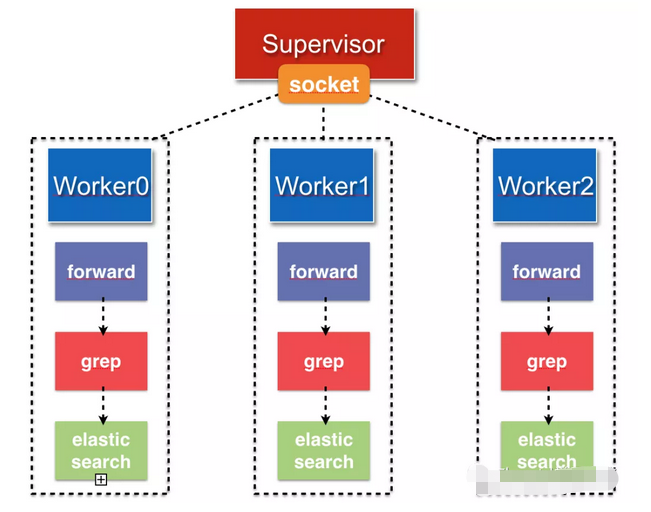
Fluentd提供了一些特性以支持多worker模式,我们通过配置就能方便地使用这些特性。
- 配置
2.1 workers参数
可在
<system>
workers 4
</system>
2.2
有些插件不支持在多worker上运行,比如tail。
对这类插件,我们可通过<worker N>指定其在哪个worker上运行。
N代表worker的索引,起始为0.
<system>
workers 4
</system>
# work on multi process workers. worker0 - worker3 run in_forward
<source>
@type forward
</source>
# work on only worker 0. worker1 - worker3 don't run in_tail
<worker 0>
<source>
@type tail
</source>
</worker>
# <worker 1>, <worker 2> or <worker 3> is also ok
这个例子中,启动了4个工作进程。tail插件被放置在<worker 0>中,表明tail只运行在索引为0的工作进程上。
这种配置可以混合使用多进程插件和单进程插件。
2.3
Fluentd v1.4.0开始支持<worker N-M>指令。这个很容易理解。
N-M代表工作进程索引范围,指定了插件可以运行在哪些工作进程中。
<system>
workers 6
</system>
<worker 0-1>
<source>
@type forward
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 0 and worker 1.
<worker 2-3>
<source>
@type tcp
<parse>
@type none
</parse>
tag test
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 2 and worker 3.
<worker 4-5>
<source>
@type udp
<parse>
@type none
</parse>
tag test
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 4 and worker 5.
2.4 root_dir/@id参数
使用文件作为buffer时,需要配置这几个参数。
在多worker模式中,不能指定固定的path作为文件buffer,因为这会不同进程中引起冲突。
<system>
workers 2
</system>
<match pattern>
@type forward
<buffer>
@type file
path /var/log/fluentd/forward # This is not allowed
</buffer>
</match>
Fluentd提供了基于root_dir和@id的动态path配置,实际的buffer路径为:${root_dir}/worker${worker index}/${plugin @id}/buffer
<system>
workers 2
root_dir /var/log/fluentd
</system>
<match pattern>
@type forward
@id out_fwd
<buffer>
@type file
</buffer>
</match>
- 操作
每个worker使用单独的内存和磁盘空间,因此需要仔细配置缓存空间,并对内存和磁盘使用情况做好监控。

