

Prometheus与服务发现
这种按需的资源使用方式对于监控系统而言就意味着没有了一个固定的监控目标,所有的监控对象(基础设施、应用、服务)都在动态的变化。对于Prometheus这一类基于Pull模式的监控系统,显然也无法继续使用的static_configs的方式静态的定义监控目标。而对于Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标控即可, 这种模式被称为服务发现。
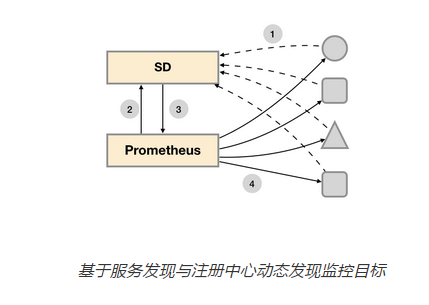
在不同的场景下,会有不同的东西扮演者代理人(服务发现与注册中心)这一角色。比如在AWS公有云平台或者OpenStack的私有云平台中,由于这些平台自身掌握着所有资源的信息,此时这些云平台自身就扮演了代理人的角色。Prometheus通过使用平台提供的API就可以找到所有需要监控的云主机。在Kubernetes这类容器管理平台中,Kubernetes掌握并管理着所有的容器以及服务信息,那此时Prometheus只需要与Kubernetes打交道就可以找到所有需要监控的容器以及服务对象。Prometheus还可以直接与一些开源的服务发现工具进行集成,例如在微服务架构的应用程序中,经常会使用到例如Consul这样的服务发现注册软件,Promethues也可以与其集成从而动态的发现需要监控的应用服务实例。除了与这些平台级的公有云、私有云、容器云以及专门的服务发现注册中心集成以外,Prometheus还支持基于DNS以及文件的方式动态发现监控目标,从而大大的减少了在云原生,微服务以及云模式下监控实施难度。

如上所示,展示了Push系统和Pull系统的核心差异。相较于Push模式,Pull模式的优点可以简单总结为以下几点:
- 只要Exporter在运行,你可以在任何地方(比如在本地),搭建你的监控系统;
- 你可以更容易的查看监控目标实例的健康状态,并且可以快速定位故障;
- 更利于构建DevOps文化的团队;
- 松耦合的架构模式更适合于云原生的部署环境。
基于文件的服务发现
在Prometheus支持的众多服务发现的实现方式中,基于文件的服务发现是最通用的方式。这种方式不需要依赖于任何的平台或者第三方服务。对于Prometheus而言也不可能支持所有的平台或者环境。通过基于文件的服务发现方式下,Prometheus会定时从文件中读取最新的Target信息,因此,你可以通过任意的方式将监控Target的信息写入即可。
用户可以通过JSON或者YAML格式的文件,定义所有的监控目标。例如,在下面的JSON文件中分别定义了3个采集任务,以及每个任务对应的Target列表:
[
{
"targets": [ "localhost:8080"],
"labels": {
"env": "localhost",
"job": "cadvisor"
}
},
{
"targets": [ "localhost:9104" ],
"labels": {
"env": "prod",
"job": "mysqld"
}
},
{
"targets": [ "localhost:9100"],
"labels": {
"env": "prod",
"job": "node"
}
}
]
同时还可以通过为这些实例添加一些额外的标签信息,例如使用env标签标示当前节点所在的环境,这样从这些实例中采集到的样本信息将包含这些标签信息,从而可以通过该标签按照环境对数据进行统计。
修改Prometheus配置文件prometheus.yml,并添加以下内容:
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
scrape_configs:
- job_name: 'file_ds'
file_sd_configs:
- files:
- targets.json
这里定义了一个基于file_sd_configs的监控采集任务,其中模式的任务名称为file_ds。在JSON文件中可以使用job标签覆盖默认的job名称,启动Prometheus服务
在Prometheus UI的Targets下就可以看到当前从targets.json文件中动态获取到的Target实例信息以及监控任务的采集状态,同时在Labels列下会包含用户添加的自定义标签.
Prometheus默认每5m重新读取一次文件内容,当需要修改时,可以通过refresh_interval进行设置,例如:
- job_name: 'file_ds'
file_sd_configs:
- refresh_interval: 1m
files:
- targets.json
通过这种方式,Prometheus会自动的周期性读取文件中的内容。当文件中定义的内容发生变化时,不需要对Prometheus进行任何的重启操作。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2019-09-02 filebeat开启自带模块收集日志如何辨别日志来源等