

使用Elasticsearch的processors来对csv格式数据进行解析
来源数据是一个csv文件,具体内容如下图所示:
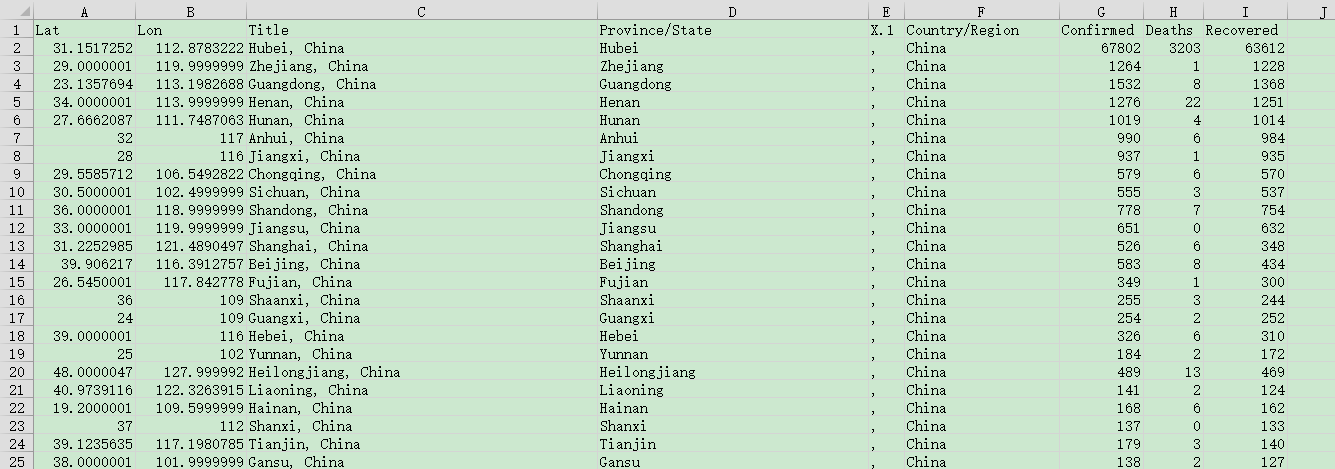
导入数据到es中
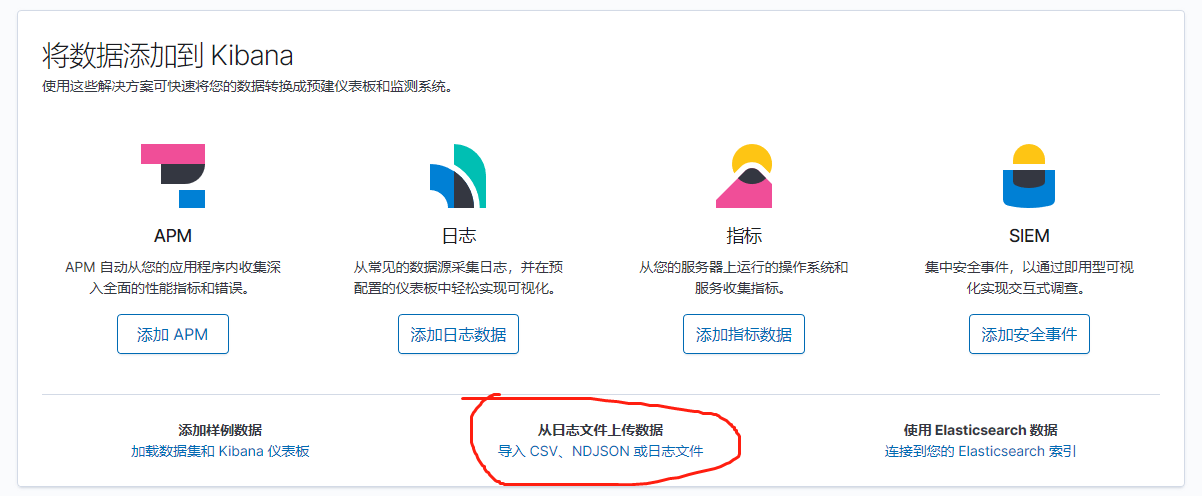
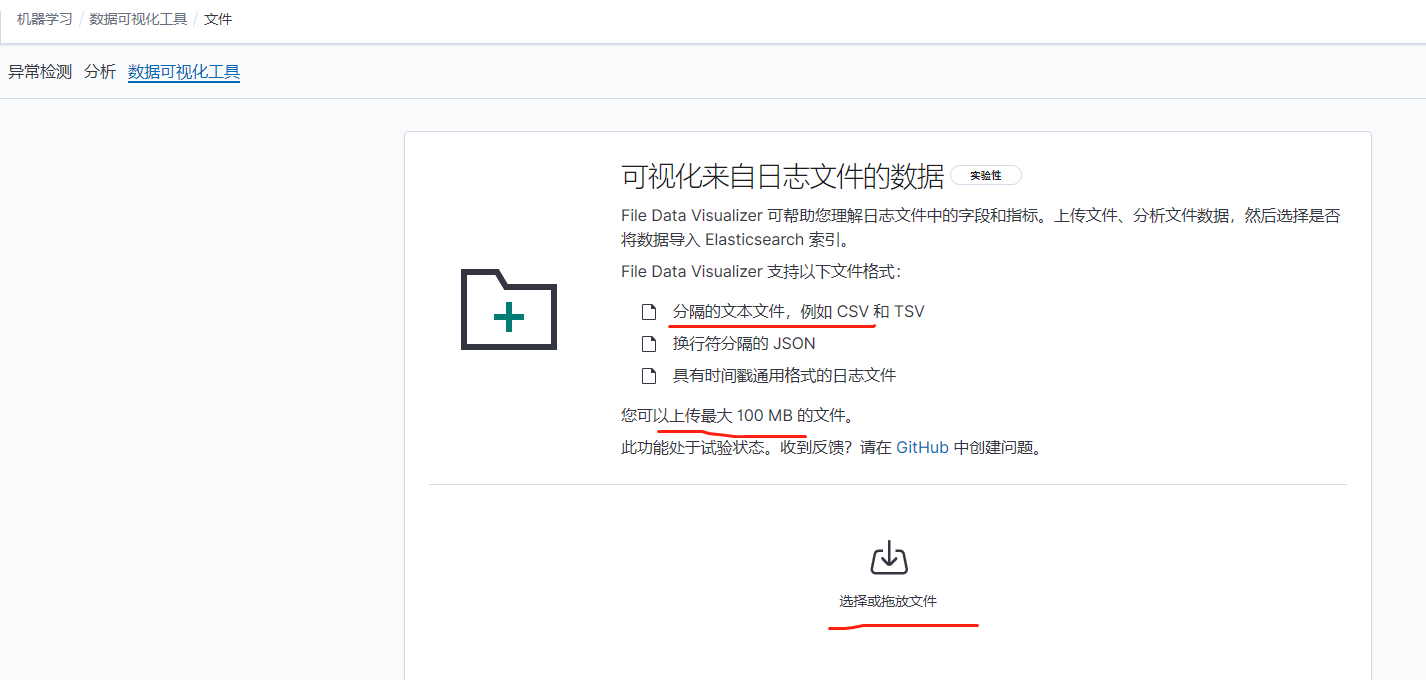
有两种办法,第一种是在kibana界面直接上传文件导入
第二种方法是使用filebeat读取文件导入
这里采用第二种办法
配置文件名:filebeat_covid19.yml
filebeat.inputs:
- type: log
paths:
- /covid19/covid19.csv # 文件路径根据实际情况修改
exclude_lines: ['^Lat'] # 去掉csv文件的第一行数据header
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: covid19 # 设置索引名
setup.ilm.enabled: false # 不使用索引生命周期管理
setup.template.name: covid19
setup.template.pattern: covid19
注意:csv文件的第一行是数据的header,需要去掉这一行。为此,采用了exclude_lines: ['^Lat']来去掉第一行。
执行如下命令导入数据:./filebeat -e -c filebeat_covid19.yml
Filebeat的registry文件存储Filebeat用于跟踪上次读取位置的状态和位置信息。如果由于某种原因,我们想重复对这个csv文件的处理,我们可以删除如下的目录:
- data/registry 针对 .tar.gz and .tgz 归档文件安装
- /var/lib/filebeat/registry 针对 DEB 及 RPM 安装包
- c:\ProgramData\filebeat\registry 针对 Windows zip 文件
对数据进行查询:GET covid19/_search
其中一条数据格式:
{
"_index" : "covid19",
"_type" : "_doc",
"_id" : "udJG93EB9vfbZvWY2eEV",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2020-05-09T02:32:26.345Z",
"log" : {
"file" : {
"path" : "/usr/local/src/covid19.csv"
},
"offset" : 3308
},
"message" : """37.1232245,-78.4927721,"Virginia, US",Virginia,",",US,2640,0,0""",
"input" : {
"type" : "log"
},
"ecs" : {
"version" : "1.1.0"
},
"host" : {
"os" : {
"codename" : "Core",
"platform" : "centos",
"version" : "7 (Core)",
"family" : "redhat",
"name" : "CentOS Linux",
"kernel" : "4.4.196-1.el7.elrepo.x86_64"
},
"id" : "8e40a96218dc4a3db226ae44244c0b26",
"containerized" : false,
"name" : "bogon",
"hostname" : "bogon",
"architecture" : "x86_64"
},
"agent" : {
"ephemeral_id" : "4d3cb998-1a1c-4545-8c60-ab0ddd135d86",
"hostname" : "bogon",
"id" : "147d9456-23f4-470e-94cb-fdddab45f5a6",
"version" : "7.5.0",
"type" : "filebeat"
}
}
}
利用Processors来加工数据
去掉无用的字段
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
}
]
}
上面的pipeline定义了一个叫做remove的processor。它检查log,input, ecs, host及agent都不为空的情况下,删除字段log, input,ecs, host及agent。
应用pipleline,执行如下命令:POST covid19/_update_by_query?pipeline=covid19_parser
替换引号
导入的message数据为:
"""37.1232245,-78.4927721,"Virginia, US",Virginia,",",US,221,0,0"""
这里的数据有很多的引号"字符,想把这些字符替换为符号'。为此,需要gsub processors来帮我们处理。重新修改我们的pipeline:
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
},
{
"gsub": {
"field": "message",
"pattern": "\"",
"replacement": "'"
}
}
]
}
注意:上述语句在kibana的Dev Tools中不能执行“自动缩进”命令,否则“gsub”中的“pattern”,会由"pattern": "\"",变成"pattern": """"""",
应用pipleline,执行如下命令:POST covid19/_update_by_query?pipeline=covid19_parser
看出来我们已经成功都去掉了引号。我们的message的信息如下:
"37.1232245,-78.4927721,'Virginia, US',Virginia,',',US,221,0,0"
解析信息
这一步的操作具体来说是把message的信息,由一行信息转换成json样式的键值对数据
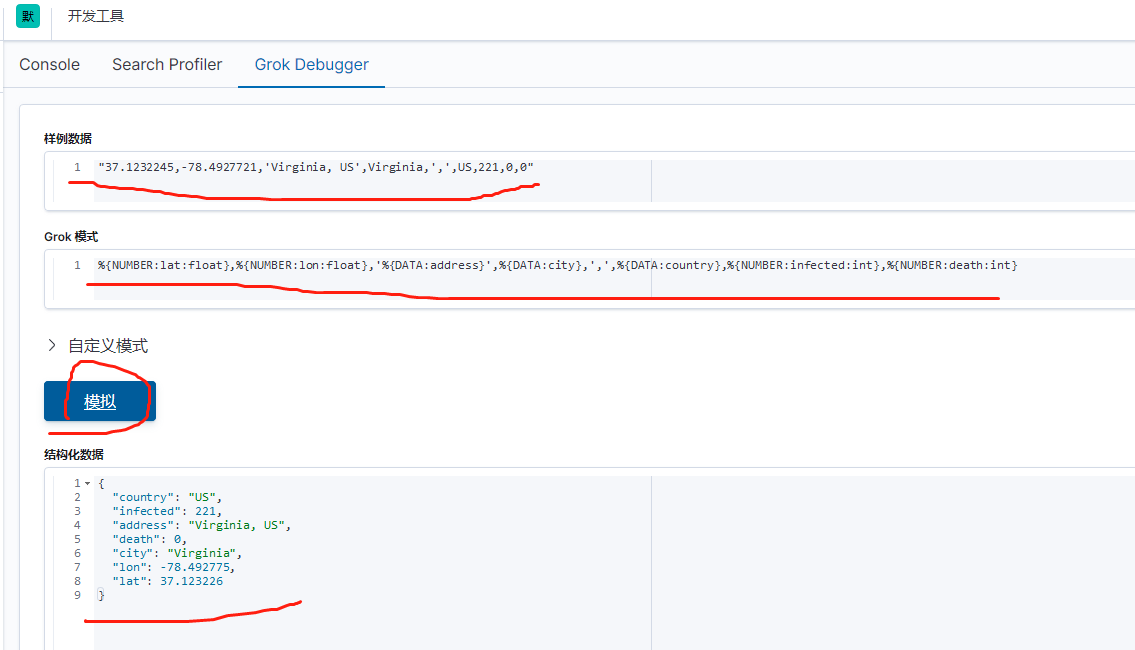
首先使用Kibana所提供的Grok Debugger来帮助我们分析数据。我们将使用如下的grok pattern来解析我们的message:
%{NUMBER:lat:float},%{NUMBER:lon:float},'%{DATA:address}',%{DATA:city},',',%{DATA:country},%{NUMBER:infected:int},%{NUMBER:death:int}
重新修改pipeline:
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
},
{
"gsub": {
"field": "message",
"pattern": "\"",
"replacement": "'"
}
},
{
"grok": {
"field": "message",
"patterns": [
"%{NUMBER:lat:float},%{NUMBER:lon:float},'%{DATA:address}',%{DATA:city},',',%{DATA:country},%{NUMBER:infected:int},%{NUMBER:death:int}"
]
}
}
]
}
使用如下的命令来重新对数据进行分析:
POST covid19/_update_by_query?pipeline=covid19_parser
可以看到新增加的country,infected,address等等的字段。
添加location字段
需要创建一个新的location字段,把原先表示经纬度的lon及lat字段给概括进去
更新pipeline为:
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
},
{
"gsub": {
"field": "message",
"pattern": "\"",
"replacement": "'"
}
},
{
"grok": {
"field": "message",
"patterns": [
"%{NUMBER:lat:float},%{NUMBER:lon:float},'%{DATA:address}',%{DATA:city},',',%{DATA:country},%{NUMBER:infected:int},%{NUMBER:death:int}"
]
}
},
{
"set": {
"field": "location.lat",
"value": "{{lat}}"
}
},
{
"set": {
"field": "location.lon",
"value": "{{lon}}"
}
}
]
}
设置了一个叫做location.lat及location.lon的两个字段。它们的值分别是{{lat}}及{{lon}}
由于location是一个新增加的字段,在默认的情况下,它的两个字段都会被Elasticsearch设置为text的类型。为了能够让我们的数据在地图中进行显示,它必须是一个geo_point的数据类型。为此,我们必须通过如下命令来设置它的数据类型:
PUT covid19/_mapping
{
"properties": {
"location": {
"type": "geo_point"
}
}
}
再使用如下的命令来对我们的数据重新进行处理:
POST covid19/_update_by_query?pipeline=covid19_parser
同时也可以查看covid19的mapping。
GET covid19/_mapping
我们可以发现location的数据类型为:
"location" : {
"type" : "geo_point"
},
它显示location的数据类型是对的。
到目前为止,已经够把数据处理成所需要的数据了,可以用来进一步展示使用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!