

Elasticsearch:Cluster备份 Snapshot及Restore API
Elasticsearch提供了replica解决方案,它可以帮我们解决了如果有一个或多个node失败了,那么我们的数据还是可以保证完整的情况,并且搜索还可以继续进行。但是,有一种情况是我们的所有的node,或者有一部分node失败,可能会造成我们的数据的丢失。也就是说replca不能提供一种灾难性的保护机制。我们需要一种完整的备份机制。

Snapshot及Restore
在Elastic里,我们提供了一个叫做snapshot及restore API的接口。使您可以使用数据和状态快照备份您的Elasticsearch索引和集群。 快照很重要,因为快照会在出现问题时提供您数据的副本。 如果需要回滚到旧版本的数据,则可以从存储库中还原快照。

如上图所示,我们可以把当前index的状态及数据存入到一个repository里去。
Repository
为了能够做备份,我们首先必须创建一个repository,也就是一个仓库。你可以为一个cluster创建多个仓库。目前支持的仓库类型有:
# Elasticsearch支持仓库类型
Respository 配置类型
Shared file system "type": "fs"
Read-only URL "type": "url"
S3 "type": "s3"
HDFS "type": "hdfs"
Azure "type": "azure"
Google Cloud Storage "type": "gcs"
这里需要注意的是: S3, HDFS, Azure and GCS 需要相应的插件进行安装才可以。
注册仓库
在一个snapshot可以被使用之前,我们必须注册一个仓库(repository)。
- 使用_snapshot 终点
- 文件夹必须对所有的node可以访问
- path.repo必须在所有的node上进行配置,针对一个fs的repository来说
PUT _snapshot/my_repo
{
"type": "fs",
"settings": {
"location": "/mnt/my_repo_folder"
}
}
这里/mnt/my_repo_folder必须加进所有node的elasticsearch.yml文件中。
fs resposity设置:
PUT _snapshot/my_repo
{
"type": "fs",
"settings": {
"location": "/mnt/my_repo_folder",
"compress": true,
"max_restore_bytes_per_sec": "40mb",
"max_snapshot_bytes_per_sec": "40mb"
}
}
这里,我们定义compress为true,表明我们希望压缩。通过max_restore_bytes_per_sec及max_snapshot_bytes_per_sec的定义,我们可以来限制数据的snapshot及恢复的数据速度。
S3 repository设置
为了能能使用S3仓库,我们必须使用如下的命令来进行安装插件:
./bin/elasticsearch-plugin install repository-s3
注意,上面的命令必须是在Elasticsearch的安装目录下进行执行。我们可以通过如下的命令来进行配置:
PUT _snapshot/my_s3_repo
{
"type": "s3",
"settings": {
"bucket": "my_s3_bucket_name"
}
}
这里的my_s3_bucket_name是我们在AWS上定义的S3 bucket。更多关于S3的配置可以参阅链接 Repository Settings(https://www.elastic.co/guide/en/elasticsearch/plugins/current/repository-s3-repository.html)。
Snapshot所有的索引
一旦我们的repository已经被配置好了,那么我们就可以利用_snapshot终点来进行snapshot。必须注意的是snapshot只拷贝在执行该命令时的所有的数据,而在之后的所有的数据将不被备份。snapshot是按照增量来进行备份的,也就是说它只拷贝从上次执行snapshot之后变化的部分。通常来说,每隔30分钟进行一次备份是足够的。
snapshot命令:
PUT _snapshot/my_repo/my_snapshot_1
这里必须注意的几点:
- my_repo是指的我们在上面定义的repository的名字
- my_snapshot_1指的是一个唯一的snapshot名字
- 没有特定的索引名字被指出,那么它指的是所有的open索引
如果我们想指定某个或某些特定的索引,那么我们可以使用如下的命令来执行备份(snapshot)
PUT _snapshot/my_repo/my_logs_snapshot_1
{
"indices": "logs-*",
"ignore_unavailable": true,
"include_global_state": true
}
这里它表述我们相对所有以logs-为开头的索引进行备份。
我们可以通过如下的命令来进行监测正在进行的snapshot的进度:
GET _snapshot/my_repo/my_snapshot_2/_status
管理snapshots
获取所有在repo中的snapshots:
GET _snapshot/my_repo/_all
获取某个特定snapshot的信息
GET _snapshot/my_repo/my_snapshot_1
删除一个snapshot
DELETE _snapshot/my_repo/my_snapshot_1
恢复一个snapshot
我们可以使用_restore终点来从一个snapshot恢复所有的索引:
POST _snapshot/my_repo/my_snapshot_2/_restore
我们也可以通过如下的方法来恢复某个或某些特定的索引:
POST _snapshot/my_repo/my_snapshot_2/_restore
{
"indices": "logs-*",
"ignore_unavailable": true,
"include_global_state": false
}
在很多的时候,我们想把snapshot中的索引恢复到一个不同名字的索引之中,从而不用覆盖现有的。我们可以通过rename_pattern及rename_replacement来进行配置:
POST _snapshot/my_repo/my_snapshot_2/_restore
{
"indices": "logs-*",
"ignore_unavailable": true,
"include_global_state": false,
"rename_pattern": "logs-(.+)",
"rename_replacement": "restored-logs-$1"
}
在上面,我们把所有的以logs-为开头的索引恢复到以restored-logs-的开头的索引之中来。
Restore到一个新的cluster
针对这个情况,我们可以恢复从另外一个cluster中备份的snapshot到当前的cluster中来。我们必须在新的cluster中注册这个repository才可以进行下面的操作。

从上面我们可以看出来,my_repo必须对两个cluster都是可见的才可以。
动手实践
准备数据:
运行起来我们的Kibana:
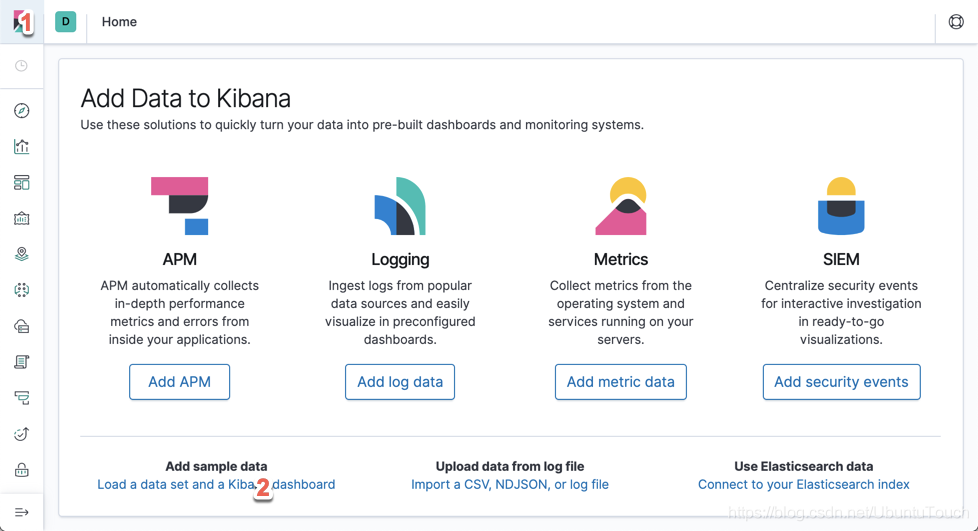
我们分别点击上面的1和2处:
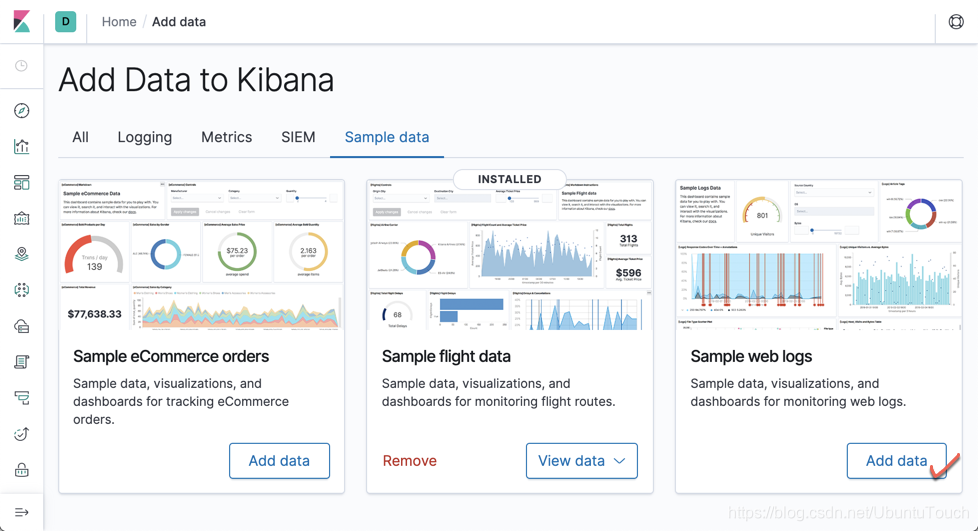
点击上面的“Add data”。这样我们就可以把我们的kibana_sample_data_logs索引加载到Elasticsearch中。
GET _cat/indices/kibana_sample_data_logs

注册repository
首先我们在我们的电脑上创建一个如下的目录:
/shared_folder/my_repo
我们在termimal中打入如下的命令:
mkdir -p shared_folder/my_repo/
$ pwd
/Users/liuxg/shared_folder
bogon:shared_folder liuxg$ ls -al
drwxr-xr-x 2 liuxg staff 64 Nov 13 13:23 my_repo
将以下path.repo属性添加到我们运行的所有node的elasticsearch.yml文件中:
path.repo: /Users/liuxg/shared_folder/my_repo
注意,针对你的情况,你需要改动这里的path路径。
然后启动我们的Elasticsearch及Kibana。紧接着,我们在Kibana console中打入如下的命令:
PUT _snapshot/my_local_repo
{
"type": "fs",
"settings": {
"location": "/Users/liuxg/shared_folder/my_repo"
}
}
注意这里的location是根据我自己的电脑的路径来设置的。你需要根据自己实际的路径进行修改。在这里my_local_repo是我们的repository名称。
接下来,我们打入如下的命令来对我们的kibana_sample_data_logs索引进行snapshot:
PUT _snapshot/my_local_repo/snapshot_1
{
"indices": "kibana_sample_data_logs",
"ignore_unavailable": true,
"include_global_state": true
}

我们可以通过如下的命令来查看snapshot:
GET _snapshot/my_local_repo/_all

我们可以在右边看到snapshot_1出现在列表之中,说明我们已经成功地创建了这个snapshot。
我们接下来可以通过如下的命令来删除kibana_sample_data_logs索引:
DELETE kibana_sample_data_logs
这样我们彻底地删除了这个索引。那么我们该如何把之前备份的数据恢复回来呢?
在Kibana中打入如下的命令:
POST _snapshot/my_local_repo/snapshot_1/_restore
{
"indices": "kibana_sample_data_logs",
"ignore_unavailable": true,
"include_global_state": false
}

在执行完上面的命令后,我们可以通过如下的命令来查看恢复后的kibana_sample_data_logs索引:
GET kibana_sample_data_logs/_count
显然我们已经成功地恢复了我们之前备份的数据。
这个时候,如果我们去到我们的snapshot文件目录,我们可以看到:
$ pwd
/Users/liuxg/shared_folder/my_repo
bogon:my_repo liuxg$ ls
index-0 meta-TzygGpJ1SOK5yJdsmc1lng.dat
index.latest snap-TzygGpJ1SOK5yJdsmc1lng.dat
indices
显然在文件目录中,已经有新生产的文件了。

