

使用 Logstash 和 JDBC 确保 Elasticsearch 与关系型数据库保持同步
为了充分利用 Elasticsearch 提供的强大搜索功能,很多公司都会在既有关系型数据库的基础上再部署Elasticsearch。在这种情况下,很可能需要确保 Elasticsearch 与所关联关系型数据库中的数据保持同步。因此,在本篇博文中,我会演示如何使用 Logstash 来高效地复制数据并将关系型数据库中的更新同步到 Elasticsearch 中。本文中所列出的代码和方法已使用 MySQL 进行过测试,但理论上应该适用于任何关系数据库管理系统 (RDBMS)。
系统配置
在本篇文章中,我使用下列产品进行测试:
- MySQL:8.0.16
- Elasticsearch:7.1.1
- Logstash:7.1.1
- Java:1.8.0_162-b12
- JDBC 输入插件:v4.3.13
- JDBC 连接器:Connector/J 8.0.16
同步步骤整体概览
在本篇博文中,我们使用 Logstash 和 JDBC 输入插件来让 Elasticsearch 与 MySQL 保持同步。从概念上讲,Logstash 的 JDBC 输入插件会运行一个循环来定期对 MySQL 进行轮询,从而找出在此次循环的上次迭代后插入或更改的记录。如要让其正确运行,必须满足下列条件:
- 在将 MySQL 中的文档写入 Elasticsearch 时,Elasticsearch 中的 "_id" 字段必须设置为 MySQL 中的 "id" 字段。这可在 MySQL 记录与 Elasticsearch 文档之间建立一个直接映射关系。如果在 MySQL 中更新了某条记录,那么将会在 Elasticsearch 中覆盖整条相关记录。请注意,在 Elasticsearch 中覆盖文档的效率与更新操作的效率一样高,因为从内部原理上来讲,更新便包括删除旧文档以及随后对全新文档进行索引。
- 当在 MySQL 中插入或更新数据时,该条记录必须有一个包含更新或插入时间的字段。通过此字段,便可允许 Logstash 仅请求获得在轮询循环的上次迭代后编辑或插入的文档。Logstash 每次对 MySQL 进行轮询时,都会保存其从 MySQL 所读取最后一条记录的更新或插入时间。在下一次迭代时,Logstash 便知道其仅需请求获得符合下列条件的记录:更新或插入时间晚于在轮询循环中的上一次迭代中所收到的最后一条记录。
如果满足上述条件,我们便可配置 Logstash,以定期请求从 MySQL 获得新增或已编辑的全部记录,然后将它们写入 Elasticsearch 中。完成这些操作的 Logstash 代码在本篇博文的后面会列出。
MySQL 设置
可以使用下列代码配置 MySQL 数据库和数据表:
CREATE DATABASE es_db;
USE es_db;
DROP TABLE IF EXISTS es_table;
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
在上面的 MySQL 配置中,有几个参数需要特别注意:
es_table:这是 MySQL 数据表的名称,数据会从这里读取出来并同步到 Elasticsearch。id:这是该条记录的唯一标识符。请注意 “id” 已被定义为 PRIMARY KEY(主键)和 UNIQUE KEY(唯一键)。这能确保每个 “id” 仅在当前表格中出现一次。其将会转换为 “_id”,以用于更新 Elasticsearch 中的文档及向 Elasticsearch 中插入文档。client_name:此字段表示在每条记录中所存储的用户定义数据。在本篇博文中,为简单起见,我们只有一个包含用户定义数据的字段,但您可以轻松添加更多字段。我们要更改的就是这个字段,从而向大家演示不仅新插入的 MySQL 记录被复制到了 Elasticsearch 中,而且更新的记录也被正确传播到了 Elasticsearch 中。modification_time:在MySQL插入或更改任何记录时,都会将这个所定义字段的值设置为编辑时间。有了这个编辑时间,我们便能提取自从上次 Logstash 请求从 MySQL 获取记录后被编辑的任何记录。insertion_time:此字段主要用于演示目的,并非正确进行同步需满足的严格必要条件。我们用其来跟踪记录最初插入到 MySQL 中的时间。
MySQL 操作
完成上述配置后,可以通过下列语句向 MySQL 中写入记录:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
可以通过下列命令更新 MySQL 中的记录:
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
可以通过下列语句完成 MySQL 更新/插入操作 (upsert):
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;
同步代码
下列 Logstash 管道会实施在前一部分中所描述的同步代码:
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
Read Less
在上述管道中,应该重点强调几个区域:
tracking_column:此字段会指定 “unix_ts_in_secs” 字段(用于跟踪 Logstash 从 MySQL 读取的最后一个文档,下面会进行描述),其存储在 .logstash_jdbc_last_run 中的磁盘上。该值将会用来确定 Logstash 在其轮询循环的下一次迭代中所请求文档的起始值。在 .logstash_jdbc_last_run 中所存储的值可以作为 “:sql_last_value” 通过 SELECT 语句进行访问。unix_ts_in_secs:这是一个由上述 SELECT 语句生成的字段,包含可作为标准 Unix 时间戳(自 Epoch 起秒数)的 “modification_time”。我们刚讨论的 “tracking column” 会引用该字段。Unix 时间戳用于跟踪进度,而非作为简单的时间戳;如将其作为简单时间戳,可能会导致错误,因为在 UMT 和本地时区之间正确地来回转换是一个十分复杂的过程。sql_last_value:这是一个内置参数,包括 Logstash 轮询循环中当前迭代的起始点,上面 JDBC 输入配置中的 SELECT 语句便会引用这一参数。该字段会设置为 “unix_ts_in_secs”(读取自 .logstash_jdbc_last_run)的最新值。在 Logstash 轮询循环内所执行的 MySQL 查询中,其会用作所返回文档的起点。通过在查询中加入这一变量,能够确保不会将之前传播到 Elasticsearch 的插入或更新内容重新发送到 Elasticsearch。schedule:其会使用 cron 语法来指定 Logstash 应当以什么频率对 MySQL 进行轮询以查找变更。这里所指定的"*/5 * * * * *"会告诉 Logstash 每 5 秒钟联系一次 MySQL。modification_time < NOW():SELECT 中的这一部分是一个较难解释的概念,我们会在下一部分详加解释。filter:在这一部分,我们只需简单地将 MySQL 记录中的 “id” 值复制到名为 “_id” 的元数据字段,因为我们之后输出时会引用这一字段,以确保写入 Elasticsearch 的每个文档都有正确的 “_id” 值。通过使用元数据字段,可以确保这一临时值不会导致创建新的字段。我们还从文档中删除了 “id”、“@version” 和 “unix_ts_in_secs” 字段,因为我们不希望将这些字段写入到 Elasticsearch 中。output:在这一部分,我们指定每个文档都应当写入 Elasticsearch,还需为其分配一个_id。(需从我们在筛选部分所创建的元数据字段提取出来)还会有一个包含被注释掉代码的 rubydebug 输出,启用此输出后能够帮助您进行故障排查。
SELECT 语句正确性分析
在这一部分,我们会详加解释为什么在 SELECT 语句中添加 modification_time < NOW() 至关重要。为帮助解释这一概念,我们首先给出几个反面例子,向您演示为什么两种最直观的方法行不通。然后会解释为什么添加 modification_time < NOW() 能够克服那两种直观方法所导致的问题。
直观方法应用情况:一
在这一部分,我们会演示如果 WHERE 子句中不包括 modification_time < NOW(),而仅仅指定 UNIX_TIMESTAMP(modification_time) > :sql_last_value 的话,会发生什么情况。在这种情况下,SELECT 语句如下:
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
乍看起来,上面的方法好像应可以正常运行,但是对于一些边缘情况,其可能会错过一些文档。举例说明,我们假设 MySQL 现在每秒插入两个文档,Logstash 每 5 秒执行一次 SELECT 语句。具体如下图所示,T0 到 T10 分别代表每一秒,MySQL 中的数据则以 R1 到 R22 表示。我们假定 Logstash 轮询循环的第一个迭代发生在 T5,其会读取文档 R1 到 R11,如蓝绿色的方框所示。在 sql_last_value 中存储的值现在是 T5,因为这是所读取最后一条记录 (R11) 的时间戳。我们还假设在 Logstash 从 MySQL 读取完文件后,另一个时间戳为 T5 的文档 R12 立即插入到了 MySQL 中。
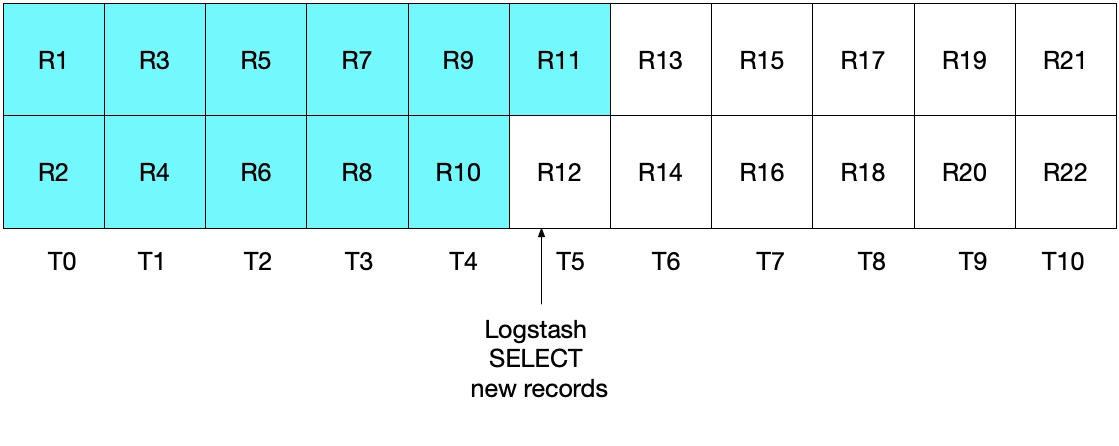
在上述 SELECT 语句的下一个迭代中,我们仅会提取时间晚于 T5 的文档(因为 WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) 就是如此规定的),这也就意味着将会跳过记录 R12。您可以参看下面的图表,其中蓝绿色方框表示 Logstash 在当前迭代中读取的记录,灰色方框表示 Logstash 之前读取的记录。
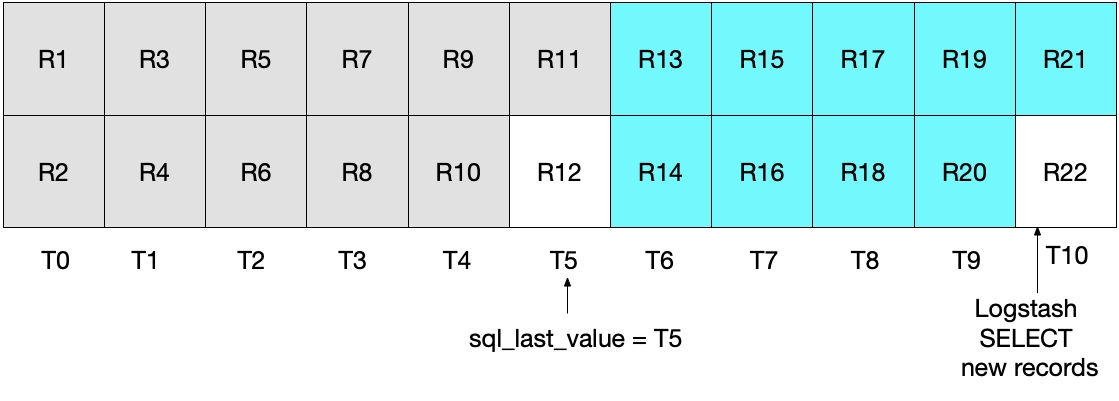
请注意,如果使用这种情况中的 SELECT 语句,记录 R12 永远不会写到 Elasticsearch 中。
直观方法应用情况:二
为了解决上面的问题,您可能决定更改 WHERE 子句为 greater than or equals(晚于或等于),具体如下:
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
然而,这种实施策略也并不理想。这种情况下的问题是:在最近一个时间间隔内从 MySQL 读取的最近文档会重复发送到 Elasticsearch。尽管这不会对结果的正确性造成任何影响,但的确做了无用功。和前一部分类似,在最初的 Logstash 轮询迭代后,下图显示了已经从 MySQL 读取了哪些文档。

当执行后续的 Logstash 轮询迭代时,我们会将时间晚于或等于 T5 的文档全部提取出来。可以参见下面的图表。请注意:记录 11(紫色显示)会再次发送到 Elasticsearch。
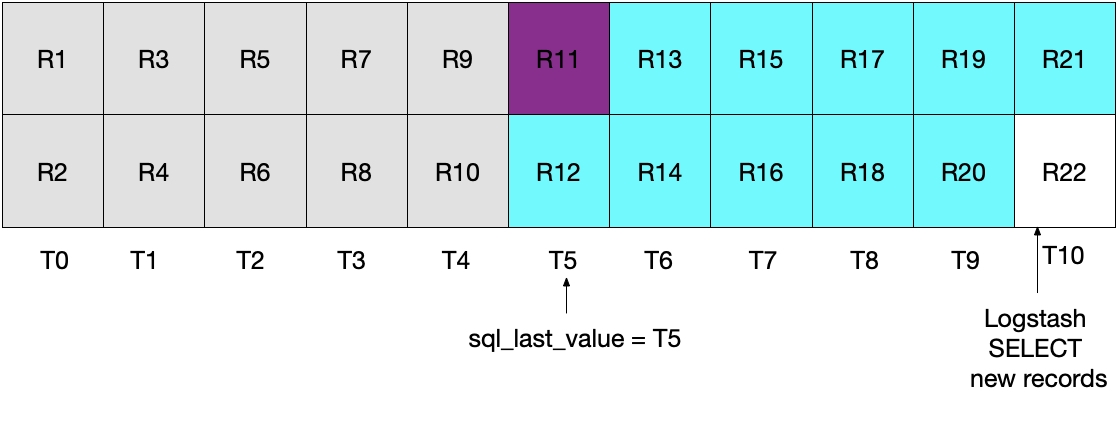
前面两种情况都不甚理想。在第一种情况中,会丢失数据,而在第二种情况中,会从 MySQL 读取冗余数据并将这些数据发送到 Elasticsearch。
如何解决直观方法所带来的的问题
鉴于前面两种情况都不太理想,应该采用另一种办法。通过指定 (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()),我们会将每个文档都发送到 Elasticsearch,而且只发送一次。
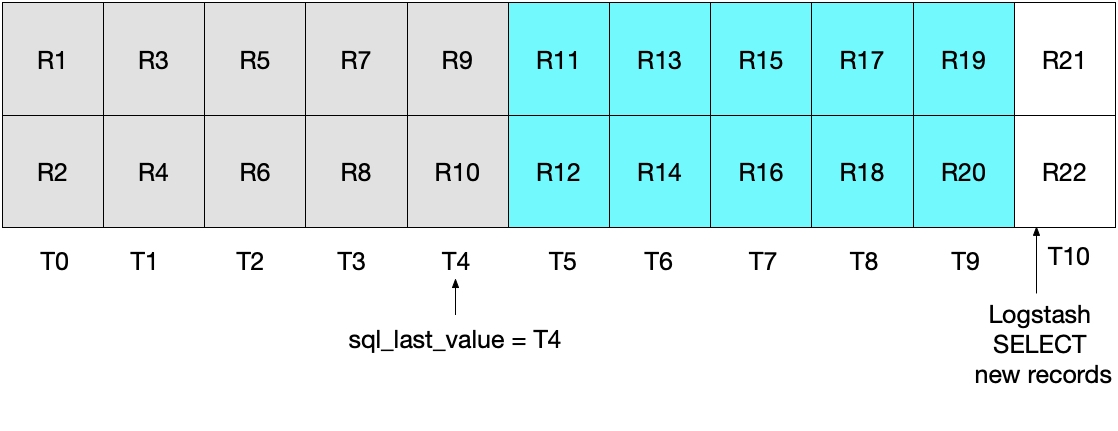
请参见下面的图表,其中当前的 Logstash 轮询会在 T5 执行。请注意,由于必须满足 modification_time < NOW(),所以只会从 MySQL 中读取截至(但不包括)时间段 T5 的文档。由于我们已经提取了 T4 的全部文档,而未读取 T5 的任何文档,所以我们知道对于下一次的Logstash 轮询迭代,sql_last_value 将会被设置为 T4。

下图演示了在 Logstash 轮询的下一次迭代中将会发生什么情况。由于 UNIX_TIMESTAMP(modification_time) > :sql_last_value,并且 sql_last_value 设置为 T4,我们知道仅会从 T5 开始提取文档。此外,由于只会提取满足 modification_time < NOW() 的文档,所以仅会提取到截至(含)T9 的文档。再说一遍,这意味着 T9 中的所有文档都已提取出来,而且对于下一次迭代 sql_last_value 将会设置为 T9。所以这一方法消除了对于任何给定时间间隔仅检索到 MySQL 文档的一个子集的风险。
测试系统
可以通过一些简单测试来展示我们的实施方案能够实现预期效果。我们可以使用下列命令向 MySQL 中写入记录:
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey');
INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers');
INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
JDBC 输入计划触发了从 MySQL 读取记录的操作并将记录写入 Elasticsearch 后,我们即可运行下列 Elasticsearch 查询来查看 Elasticsearch 中的文档:
GET rdbms_sync_idx/_search
其会返回类似下面回复的内容:
"hits" : {
"total" : {
"value" :3,
"relation" : "eq"
},
"max_score" :1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" :"1",
"_score" :1.0,
"_source" : {
"insertion_time" :"2019-06-18T12:58:56.000Z",
"@timestamp" :"2019-06-18T13:04:27.436Z",
"modification_time" :"2019-06-18T12:58:56.000Z",
"client_name" :"Jim Carrey"
}
},
Etc …
然后我们可以使用下列命令更新在 MySQL 中对应至 _id=1 的文档:
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
其会正确更新 _id 被识别为 1 的文档。我们可以通过运行下列命令直接查看 Elasticsearch 中的文档:
GET rdbms_sync_idx/_doc/1
其会返回一个类似下面的文档:
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" :"1",
"_version" :2,
"_seq_no" :3,
"_primary_term" :1,
"found" : true,
"_source" : {
"insertion_time" :"2019-06-18T12:58:56.000Z",
"@timestamp" :"2019-06-18T13:09:30.300Z",
"modification_time" :"2019-06-18T13:09:28.000Z",
"client_name" :"Jimbo Kerry"
}
}
请注意 _version 现已设置为 2,modification_time 现在已不同于 insertion_time,并且 client_name 字段已正确更新至新值。在本例中,@timestamp 字段的用处并不大,由 Logstash 默认添加。
MySQL 中的更新/插入 (upsert) 可通过下列命令完成,您可以验证正确信息是否会反映在 Elasticsearch 中:
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
那么删除文档呢
聪明的读者可能已经发现,如果从 MySQL 中删除一个文档,那么这一删除操作并不会传播到 Elasticsearch。可以考虑通过下列方法来解决这一问题:
- MySQL 记录可以包含一个 "is_deleted" 字段,用来显示该条记录是否仍有效。这一方法被称为“软删除”。正如对 MySQL 中的记录进行其他更新一样,"is_deleted" 字段将会通过 Logstash 传播至 Elasticsearch。如果实施这一方法,则需要编写 Elasticsearch 和 MySQL 查询,从而将 "is_deleted" 为 “true”(正)的记录/文档排除在外。 最后,可以通过后台作业来从 MySQL 和 Elastic 中移除此类文档。
- 另一种方法是确保负责从 MySQL 中删除记录的任何系统随后也会执行一条命令,从而直接从 Elasticsearch 中删除相应文档。

