

再次爬取干货集中营的福利图片
值得学习的地方
1.utc时间转换成普通时间的函数,也就是把2015-06-05T03:54:29.403Z格式的时间转换成2015-06-05 11:54:29
2.使用requrests获取https链接开头的图片数据
之前爬取过干货集中营的照片,地址:https://www.cnblogs.com/sanduzxcvbnm/p/9209544.html
今天再重爬一次,换了一种通俗易懂的方式
首先分析网站
1.网站地址:https://gank.io/,要爬取的是网站上展示出来的图片
2.在网站首页有API地址,点进去查看发现是干货集中营 API 文档,

其中有这样一个数据显示

尝试访问:https://gank.io/api/data/福利/10/1,出来如下json数据
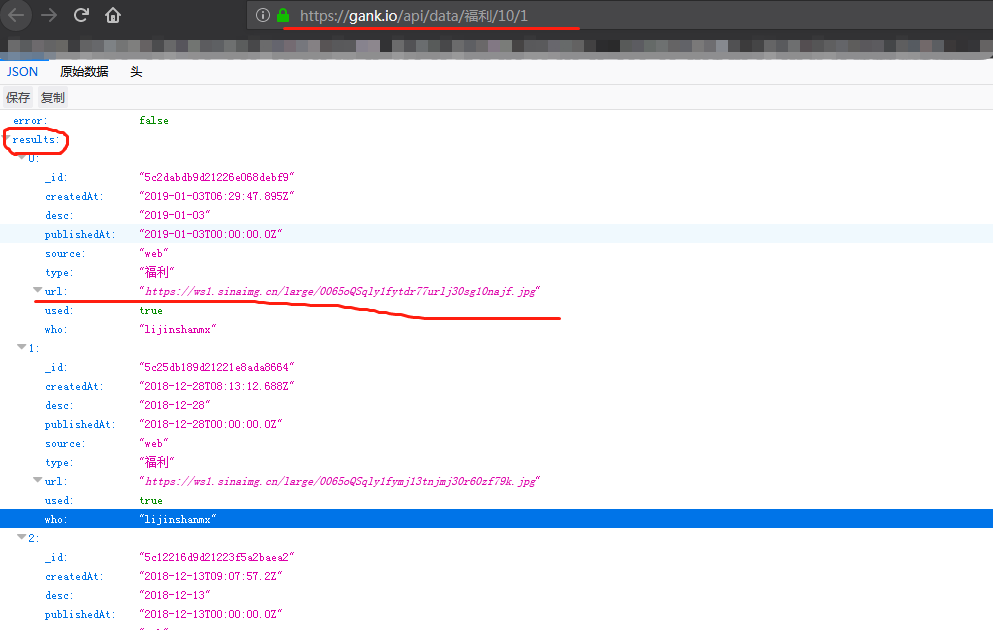
3.通过API文档描述,可以知道链接地址中的请求个数和请求页数,获取到所有的图片信息
比如:https://gank.io/api/data/福利/700/1,请求700条数据,获取第一页,发现返回的结果中总共有668条数据(截止到20190115),第二页没有数据
再次请求:https://gank.io/api/data/福利/600/1,请求600条数据,获取第一页,发现确实有600条数据,然后再请求第二页(https://gank.io/api/data/福利/600/2),有68条数据
结合以上分析,截止到今天(20190115),共有668条数据,避免使用翻页的情况,就直接使用如下网址获取全部数据:https://gank.io/api/data/福利/700/1
其次根据获取到的数据,提取出所需要的图片链接
最后下载这些图片并保存

#!/usr/bin/env python
# -*- coding: utf-8 -*-
import datetime
import os
from _md5 import md5
import requests
from requests import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except:
return None
def utc_to_local(utc_time_str, utc_format='%Y-%m-%dT%H:%M:%S.%fZ'):
"""
"2015-06-05T03:54:29.403Z"格式的时间转换成2015-06-05 11:54:29
"""
local_format = "%Y-%m-%d %H:%M:%S"
utc_dt = datetime.datetime.strptime(utc_time_str, utc_format)
local_dt = utc_dt + datetime.timedelta(hours=8)
time_str = local_dt.strftime(local_format)
return time_str
def https_to_http(url):
"""
把图片链接是https的换成http
"""
if url[0:5] == 'https':
url = url.replace(url[0:5], 'http')
return url
def parse_one_page(html):
items = html['results']
for item in items:
yield {
'id': item['_id'],
'publishedAt': utc_to_local(item['publishedAt']),
'url': https_to_http(item['url'])
}
# 请求图片url,获取图片二进制数据
def download_image(url):
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # response.contenter二进制数据 response.text文本数据
return None
except RequestException:
print('请求图片出错', url)
return None
def save_image(content):
"""
需要提前建好目录D:\\pachong\\gank\\
"""
file_path = 'D:\\pachong\\gank\\{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
def main():
url = 'http://gank.io/api/data/福利/700/1'
html = get_one_page(url)
for item in parse_one_page(html):
download_image(item['url'])
if __name__ == '__main__':
main()
最终结果显示:

总共668条数据,实际只有558条数据,通过分析获取到的图片url,发现有些图片url链接本身已失效,使用浏览器打开这些图片链接会报如下错误:

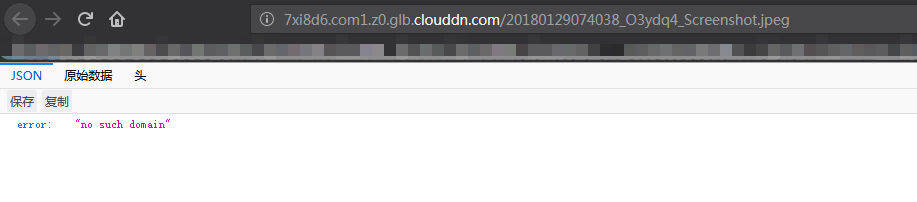
失效链接展示:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!