

爬取某网站景区列表并保存为csv文件
网址:http://www.halehuo.com/jingqu.html
经过查看可以发现,该景区页面没有分页,不停的往下拉,页面会进行刷新显示后面的景区信息
通过使用浏览器调试器,发现该网站使用的是post请求,使用ajax传输数据

请求参数:

响应数据:
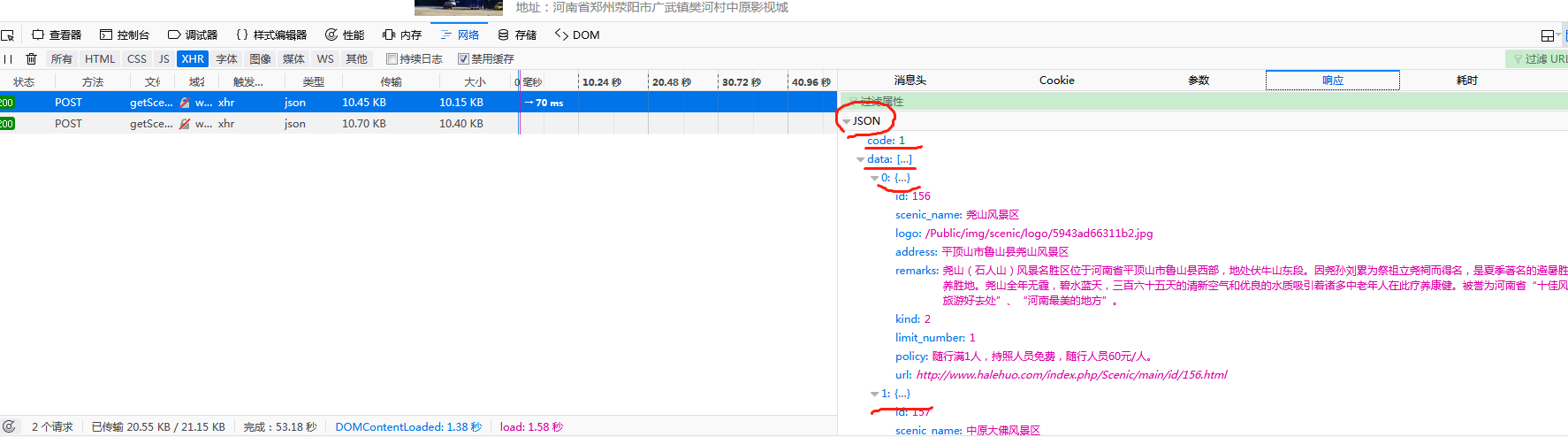


经过以上分析,大致思路如下:
(1)向请求网站使用post方式传递参数,先传递首页参数,获得json数据,然后进行数据提取,获取所需要的数据
(2)使用for循环遍历获取数据
需要注意的地方:
(1)景区logo图片获取的是相对地址,通过构造一个函数获得景区logo的绝对地址
(2)获取到的景区详情链接打不开,通过景区列表页面打开景区详情页面,发现获取的景区详情链接跟景区详情页面链接不匹配再构造一个函数处理获取到的景区详情链接

#!/usr/bin/env python
# -*- coding: utf-8 -*-
import csv
import json
from urllib.parse import urlencode
import requests
# 构造参数,发起请求,获得数据
def get_page_index(pageindex):
data = {
'citycode': 0,
'countycode': 0,
'keywords': 0,
'pageindex': pageindex,
'sceniclev': 0,
'themetype': 0,
}
params = urlencode(data)
base = 'http://www.halehuo.com/index.php/Scenic/getScenicList'
url = base + '?' + params
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
print('Error occurred')
return None
# 处理景区logo地址
def get_log_url(url):
base_url = 'http://www.halehuo.com'
return base_url + url
# 处理景区详情链接
def get_detail_url(url):
return url.replace('index.php/Scenic/main/id', 'jingqu')
# 解析获得的景区数据
def parse_page_index(pageindex):
item = get_page_index(pageindex)
items = json.loads(item)['data']
for item in items:
yield {
'id': item['id'],
'scenic_name': item['scenic_name'],
'logo': get_log_url(item['logo']),
'address': item['address'],
'policy': item['policy'],
'url': get_detail_url(item['url']),
'remarks': item['remarks']
}
# 数据存储到csv
def write_to_file3(item):
with open('jingqu_detail.csv', 'a', encoding='utf_8_sig', newline='') as f:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['id', 'scenic_name', 'logo', 'address', 'policy', 'url', 'remarks']
w = csv.DictWriter(f, fieldnames=fieldnames)
# w.writeheader()
# print(item)
w.writerow(item)
def main():
for i in range(1, 13):
items = parse_page_index(i)
for item in items:
write_to_file3(item)
if __name__ == '__main__':
main()
保存到csv文件的截图如下:

分类:
Python爬虫


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!