

第二周
第一题
linux版本信息


gcc版本
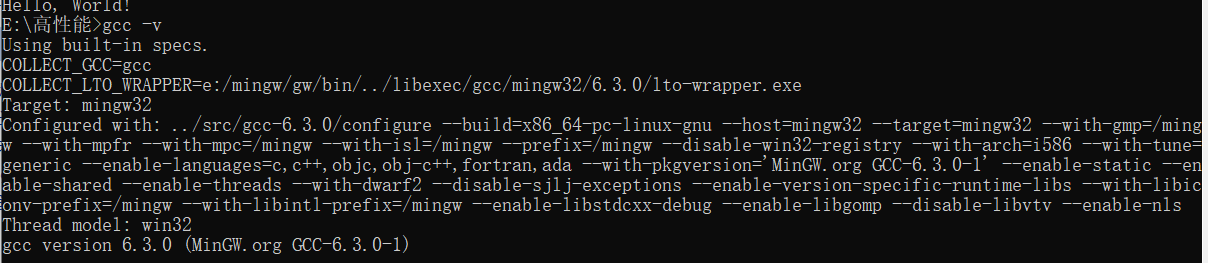
gcc版本是6.3.0
gcc编译c语言文件,并运行成功输出hello,world
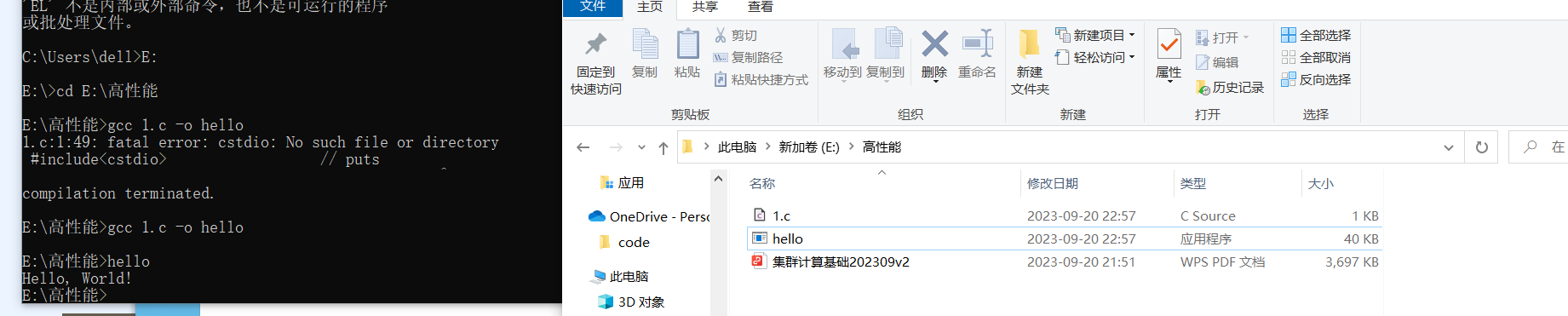
第二题
| THREAD_NUM | g_Count |
| 5 | 5 |
| 25 | 25 |
| 50 | 49 |
| 800 | 659 |
| 1000 | 672 |
//互斥量代码(使用(mutex))
代码:
#include<Windows.h>
#include<stdio.h>
#include <thread>
#include <mutex>
using namespace std;
HANDLE hMutex = NULL; //互斥量
DWORD WINAPI ThreadFunc(LPVOID);
const unsigned int THREAD_NUM = 1500;
unsigned int g_Count = 0;
HANDLE hThread[64];
DWORD WINAPI ThreadFunc(LPVOID);
int main()
{
int sum = 0;
hMutex = CreateMutex(NULL, FALSE, "Test");
int loop = 0;
for (int i = 0; i < THREAD_NUM; i++)
{hThread[i] = CreateThread(NULL, 0, ThreadFunc, &i, 0, NULL);}
int tempNumThreads = THREAD_NUM;
int tempMax = 0;
while (tempNumThreads >= MAXIMUM_WAIT_OBJECTS)
{
tempNumThreads -= MAXIMUM_WAIT_OBJECTS;
WaitForMultipleObjects(MAXIMUM_WAIT_OBJECTS, &hThread[tempMax], TRUE, INFINITE);
tempMax += MAXIMUM_WAIT_OBJECTS;
}
WaitForMultipleObjects(tempNumThreads, &hThread[tempMax], TRUE, INFINITE);
printf("%d", g_Count);
return 0;
}
DWORD WINAPI ThreadFunc(LPVOID p)
{
int n = *(int*)p;
//Sleep(1000 * n);
WaitForSingleObject(hMutex, INFINITE);
g_Count++;
printf("我是, pid = %d 的子线程,go=%d\n", GetCurrentThreadId(), g_Count);
ReleaseMutex(hMutex);
//Sleep(100);
return 0;
}
说明文档:
利用互斥量对代码进行上锁,g_Count++每次只能由一个线程执行,因为WaitForMultipleObjects一次只能接收64个线程因此当线程数大于64时要循环调用WaitForMultipleObjects函数。
测试文档
测试结果
| THREAD_NUM | g_Count |
| 5 | 5 |
| 25 | 25 |
| 50 | 50 |
| 800 | 800 |
| 1000 | 1000 |
信号量
代码:
#ifndef _SEMAPHORE_H
#define _SEMAPHORE_H
#include <mutex>
#include <condition_variable>
using namespace std;
class Semaphore
{
public:
Semaphore(long count = 0) : count(count) {}
//V操作,唤醒
void signal()
{
unique_lock<mutex> unique(mt);
++count;
if (count <= 0)
cond.notify_one();
}
//P操作,阻塞
void wait()
{
unique_lock<mutex> unique(mt);
--count;
if (count < 0)
cond.wait(unique);
}
private:
mutex mt;
condition_variable cond;
long count;
};
#endif
#include<Windows.h>
#include<stdio.h>
#include <thread>
#include <mutex>
#include<iostream>
#include<chrono>
#include<thread>
using namespace std;
HANDLE hMutex = NULL; //互斥量
DWORD WINAPI ThreadFunc(LPVOID);
const unsigned int THREAD_NUM = 900;
unsigned int g_Count = 0;
HANDLE hThread[THREAD_NUM];
DWORD WINAPI ThreadFunc(LPVOID);
Semaphore sem(0);
int main()
{
int sum = 0;
//hMutex = CreateMutex(NULL, FALSE, "Test");
int loop = 0;
for (int i = 0; i < THREAD_NUM; i++)
{hThread[i] = CreateThread(NULL, 0, ThreadFunc, &i, 0, NULL);}
int tempNumThreads = THREAD_NUM;
int tempMax = 0;
sem.signal();
while (tempNumThreads >= MAXIMUM_WAIT_OBJECTS)
{
tempNumThreads -= MAXIMUM_WAIT_OBJECTS;
WaitForMultipleObjects(MAXIMUM_WAIT_OBJECTS, &hThread[tempMax], TRUE, INFINITE);
tempMax += MAXIMUM_WAIT_OBJECTS;
}
WaitForMultipleObjects(tempNumThreads, &hThread[tempMax], TRUE, INFINITE);
//Sleep(2000);
printf("%d", g_Count);
return 0;
}
DWORD WINAPI ThreadFunc(LPVOID p)
{
int n = *(int*)p;
//Sleep(1000 * n);
//WaitForSingleObject(hMutex, INFINITE);
sem.wait();
g_Count++;
printf("我是, pid = %d 的子线程,go=%d\n", GetCurrentThreadId(), g_Count);
sem.signal();
//ReleaseMutex(hMutex);
//Sleep(100);
return 0;
}
运行结果观测值
| THREAD_NUM | g_Count |
| 5 | 5 |
| 25 | 25 |
| 50 | 50 |
| 800 | 800 |
| 1000 | 1000 |
测试文档:
测试了不同线程下,多线程对g_count的加法结果。数值由5,25,50,800,1000。
说明文档
因为C++11没有信号量的头文件需要自己编写P,V操作。
条件变量代码:
#ifndef _SEMAPHORE_H
#define _SEMAPHORE_H
#include <mutex>
#include <condition_variable>
using namespace std;
class Semaphore
{
public:
Semaphore(long count = 0) : count(count) {}
//V操作,唤醒
void signal()
{
unique_lock<mutex> unique(mt);
++count;
if (count <= 0)
cond.notify_one();
}
//P操作,阻塞
void wait()
{
unique_lock<mutex> unique(mt);
--count;
if (count < 0)
cond.wait(unique);
}
private:
mutex mt;
condition_variable cond;
long count;
};
#endif
#include<Windows.h>
#include<stdio.h>
#include <thread>
#include <mutex>
#include<iostream>
#include<chrono>
#include<thread>
using namespace std;
HANDLE hMutex = NULL; //互斥量
DWORD WINAPI ThreadFunc(LPVOID);
const unsigned int THREAD_NUM = 900;
unsigned int g_Count = 0;
HANDLE hThread[THREAD_NUM];
std::mutex mtx;
std::condition_variable cv;
DWORD WINAPI ThreadFunc(LPVOID);
Semaphore sem(0);
int main()
{
int sum = 0;
//hMutex = CreateMutex(NULL, FALSE, "Test");
int loop = 0;
for (int i = 0; i < THREAD_NUM; i++)
{hThread[i] = CreateThread(NULL, 0, ThreadFunc, &i, 0, NULL);}
int tempNumThreads = THREAD_NUM;
int tempMax = 0;
cv.notify_one();
//sem.signal();
while (tempNumThreads >= MAXIMUM_WAIT_OBJECTS)
{
tempNumThreads -= MAXIMUM_WAIT_OBJECTS;
WaitForMultipleObjects(MAXIMUM_WAIT_OBJECTS, &hThread[tempMax], TRUE, INFINITE);
tempMax += MAXIMUM_WAIT_OBJECTS;
}
WaitForMultipleObjects(tempNumThreads, &hThread[tempMax], TRUE, INFINITE);
//Sleep(2000);
printf("%d", g_Count);
return 0;
}
DWORD WINAPI ThreadFunc(LPVOID p)
{
int n = *(int*)p;
//Sleep(1000 * n);
//WaitForSingleObject(hMutex, INFINITE);
//sem.wait();
std::unique_lock <std::mutex> locker(mtx);
cv.wait(locker);
g_Count++;
printf("我是, pid = %d 的子线程,go=%d\n", GetCurrentThreadId(), g_Count);
cv.notify_one();
//sem.signal();
//ReleaseMutex(hMutex);
//Sleep(100);
return 0;
}
测试结果
| THREAD_NUM | g_Count |
| 5 | 5 |
| 25 | 25 |
| 50 | 50 |
| 800 | 800 |
| 1000 | 1000 |
测试文档
输入不同的线程数,观察多线程在条件变量的控制是否发生加错误。
说明文档,利用条件变量的阻塞和激活函数使线程执行对变量实行串行加法操作。
读写锁程序:
#ifndef _SEMAPHORE_H
#define _SEMAPHORE_H
#include <mutex>
#include <condition_variable>
using namespace std;
class readWriteLock {
private:
std::mutex readMtx;
std::mutex writeMtx;
int readCnt; // 已加读锁个数
public:
readWriteLock() : readCnt(0) {}
void readLock()
{
readMtx.lock();
if (++readCnt == 1) {
writeMtx.lock(); // 存在线程读操作时,写加锁(只加一次)
}
readMtx.unlock();
}
void readUnlock()
{
readMtx.lock();
if (--readCnt == 0) { // 没有线程读操作时,释放写锁
writeMtx.unlock();
}
readMtx.unlock();
}
void writeLock()
{
writeMtx.lock();
}
void writeUnlock()
{
writeMtx.unlock();
}
};
readWriteLock rwLock;
class Semaphore
{
public:
Semaphore(long count = 0) : count(count) {}
//V操作,唤醒
void signal()
{
unique_lock<mutex> unique(mt);
++count;
if (count <= 0)
cond.notify_one();
}
//P操作,阻塞
void wait()
{
unique_lock<mutex> unique(mt);
--count;
if (count < 0)
cond.wait(unique);
}
private:
mutex mt;
condition_variable cond;
long count;
};
#endif
#include<Windows.h>
#include<stdio.h>
#include <thread>
#include <mutex>
#include<iostream>
#include<chrono>
#include<thread>
using namespace std;
HANDLE hMutex = NULL; //互斥量
DWORD WINAPI ThreadFunc(LPVOID);
const unsigned int THREAD_NUM = 900;
unsigned int g_Count = 0;
HANDLE hThread[THREAD_NUM];
std::mutex mtx;
std::condition_variable cv;
DWORD WINAPI ThreadFunc(LPVOID);
Semaphore sem(0);
int main()
{
int sum = 0;
//hMutex = CreateMutex(NULL, FALSE, "Test");
int loop = 0;
for (int i = 0; i < THREAD_NUM; i++)
{hThread[i] = CreateThread(NULL, 0, ThreadFunc, &i, 0, NULL);}
int tempNumThreads = THREAD_NUM;
int tempMax = 0;
cv.notify_one();
//sem.signal();
while (tempNumThreads >= MAXIMUM_WAIT_OBJECTS)
{
tempNumThreads -= MAXIMUM_WAIT_OBJECTS;
WaitForMultipleObjects(MAXIMUM_WAIT_OBJECTS, &hThread[tempMax], TRUE, INFINITE);
tempMax += MAXIMUM_WAIT_OBJECTS;
}
WaitForMultipleObjects(tempNumThreads, &hThread[tempMax], TRUE, INFINITE);
//Sleep(2000);
printf("%d", g_Count);
return 0;
}
DWORD WINAPI ThreadFunc(LPVOID p)
{
int n = *(int*)p;
//Sleep(1000 * n);
//WaitForSingleObject(hMutex, INFINITE);
//sem.wait();
//std::unique_lock <std::mutex> locker(mtx);
//cv.wait(locker);
rwLock.writeLock();
g_Count++;
printf("我是, pid = %d 的子线程,go=%d\n", GetCurrentThreadId(), g_Count);
rwLock.writeUnlock();
//cv.notify_one();
//sem.signal();
//ReleaseMutex(hMutex);
//Sleep(100);
return 0;
}
测试值
| THREAD_NUM | g_Count |
| 5 | 5 |
| 25 | 25 |
| 50 | 50 |
| 800 | 800 |
| 1000 | 1000 |
测试文档
输入五个不同的线程数,测定执行完线程数g_Count的加法值。
说明文档
利用读写锁进行多线程加法,由于g_Count++是写操作,运用写锁使线程达到并行。
第三题
| 矩阵维度 | 单线程 | 4线程 | 8线程 | ||
| 计算效率 | 计算效率 | 加速比 | 计算效率 | 加速比 | |
| a(15*20) b(20*20) | 0.001s | 0.003s | 0.33 | 0.005s | 0.2 |
| a(150*200) b(200*200) | 0.024s | 0.013s | 1.85 | 0.016s | 1.5 |
| a(300*500) b(500*500) | 0.436s | 0.179s | 2.44 | 0.147s | 2.97 |
| a(1300*1500) b(1500*500) | 4.888s |
2.147s |
2.28 | 1.85s | 2.64 |
| a(1300*1500) b(1500*5000) | 76.706s | 26.424s | 2.9 | 22.366s | 3.4 |
第四题
原始代码运行结果
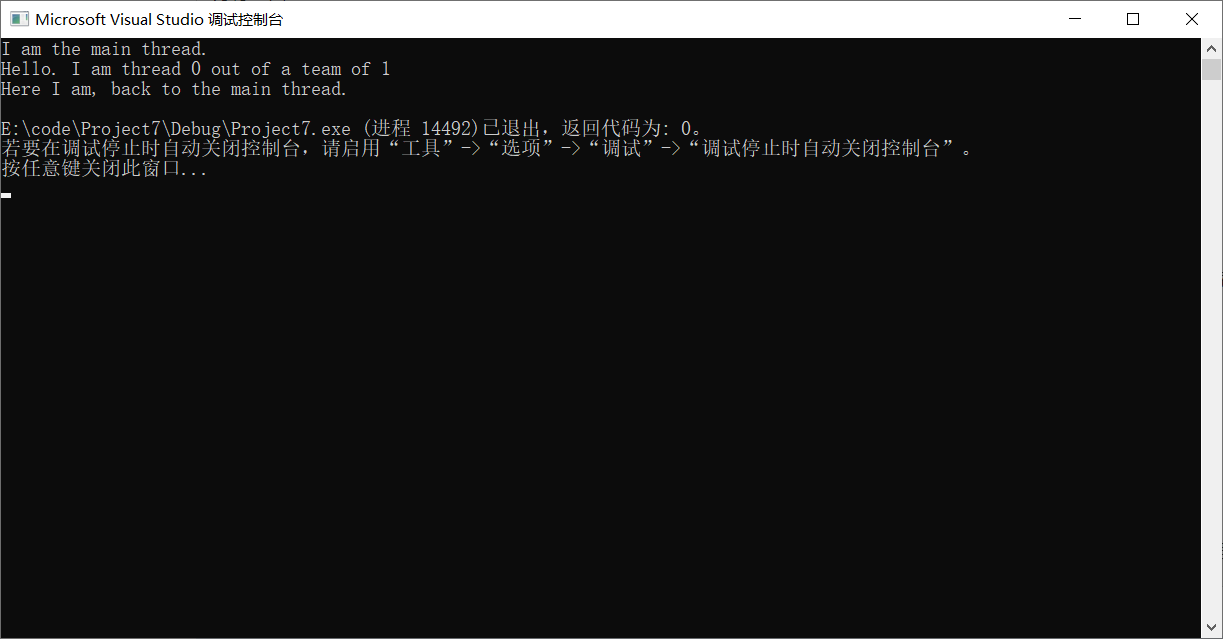
第四题
#include <stdio.h>
#include <omp.h>
int main(int argc, char **argv)
{
int nthreads, thread_id;
printf("I am the main thread.\n");
omp_set_num_threads(4);
#pragma omp parallel private(nthreads, thread_id)
{
nthreads = omp_get_num_threads();
thread_id = omp_get_thread_num();
printf("Hello. I am thread %d out of a team of %d\n", thread_id, nthreads);
}
printf("Here I am, back to the main thread.\n");
return 0;
}
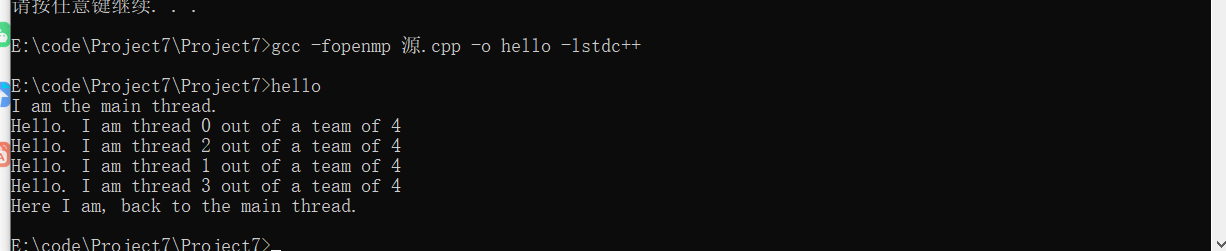
线程数为10时
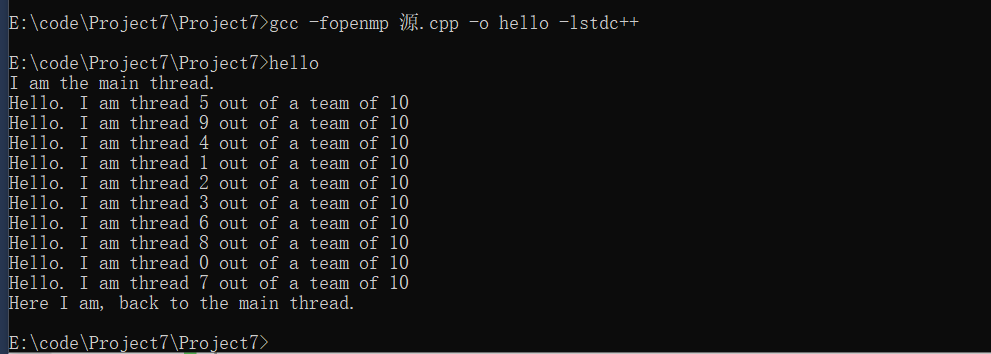
第五题
