efficienthrnet
有俩个配置文件分别是frozen-60和unfrozen-29他俩的区别只在于批度。为了区别配置文件的区别可以用word审阅->比较去查看区别。删除和添加表示不同的字符.删除区别不同的字符添加成后一篇文章的字符。
get_anno_file_name()是读取标签路径的
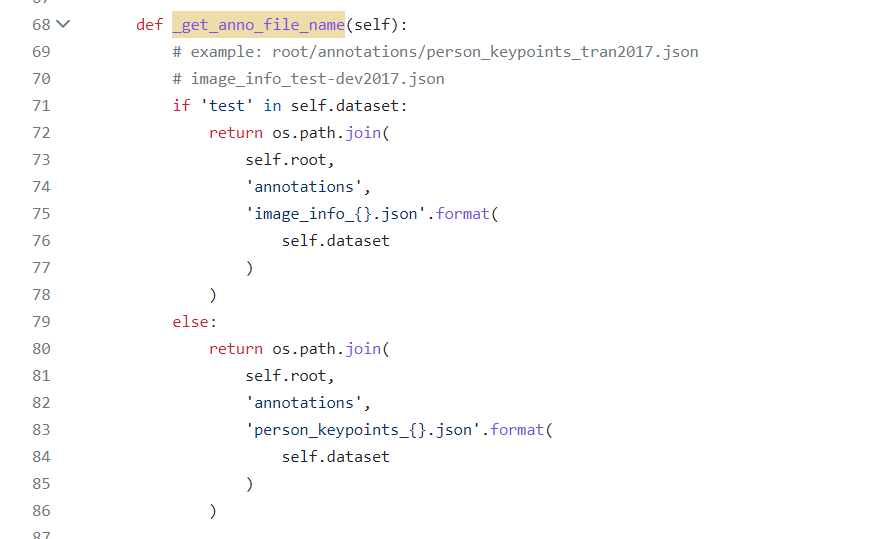
get_image_path是读取图片的文件夹
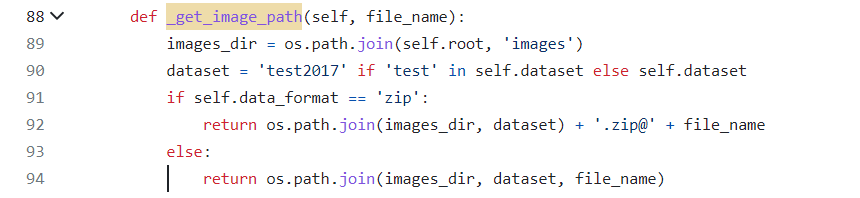
模型怎么读取。get_pose_net函数中PoseHigherResolutionNet创建模型,model.init_weights初始化权重。

预训练导入是把模型各层的名称插入set集合中,然后读取预训练模型的名称如果预训练模型的名称在模型中就赋值。
虽然yaml中每个结构都导入b0预训练模型但我感觉那是不对的,因为模型结构不一样,也给出了各模型的预训练模型。
H-2模型输入尺寸。448×448
如果想跑这个代码的话,起码呢,要先能跑代码,然后了解模型结构如何修改结构以及修改模型结构。
这里有hrnet各种的预训练模型:https://github.com/TeCSAR-UNCC/EfficientHRNet/tree/main/Example%20Configs。
得了解不同模型的结构。
为什么研究不同结构因为我的服务器资源不太行,所以不能直接训练他们提供了要了解他们的结构以及都需要那种预训练模型。但我观察不同的模型预训练模型相同,然后是训练参数的获取怎么解决。
训练文件的178行是建立模型。
模型H0时导入B0预训练模型
模型H-2导入B0预训练模型报错导入H-2模型是对的导入B-2也没报错。
预训练模型层数:1213
创建模型层数:643
预训练的层数包含创建模型的层数。
H-2的预训练模型肯定包含代码根据H-2.yaml创建的,代码全程未输出不同。self.named_parameters(),self.named_buffers()这俩个集合生成参数名和参数尺寸。与其H-2.pth.tar完全吻合。即efficient hrnet根据H-2.yaml创建的网络层跟H-2.pth.tar提供的完全一样,跟efficientnet-bc2.pth没有一点相似。跟efficientnet-b0-4cfa50.pth,1213层模型跟efficientnet-b0-4cfa50.pth模型有101层相似。lightweight openpose12层骨架预训练模型,26层训练的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号