王心凌再次爆火,为了防止收费,我连夜用Python把她所有的MV离线
《乘风破浪的姐姐3》王心凌一骑绝尘,破收视率,多年后再次全网爆火,某音截止现在差不多3500W粉丝,五月份热门女星排名,吊打其它所有人,不愧是我女神!
但是这个热度,感觉她的歌曲和MV,已经离收费越来越近了,于是我连夜用Python把所有MV 和歌曲离线,今天先给大家分享MV的方法。
女神镇楼!

话不多说,我们开冲!
一、数据来源分析
1、首先我们确定自己的需求,什么网站,获取什么数据。
以酷我为例,直接打开酷我搜索王心凌,点击MV。
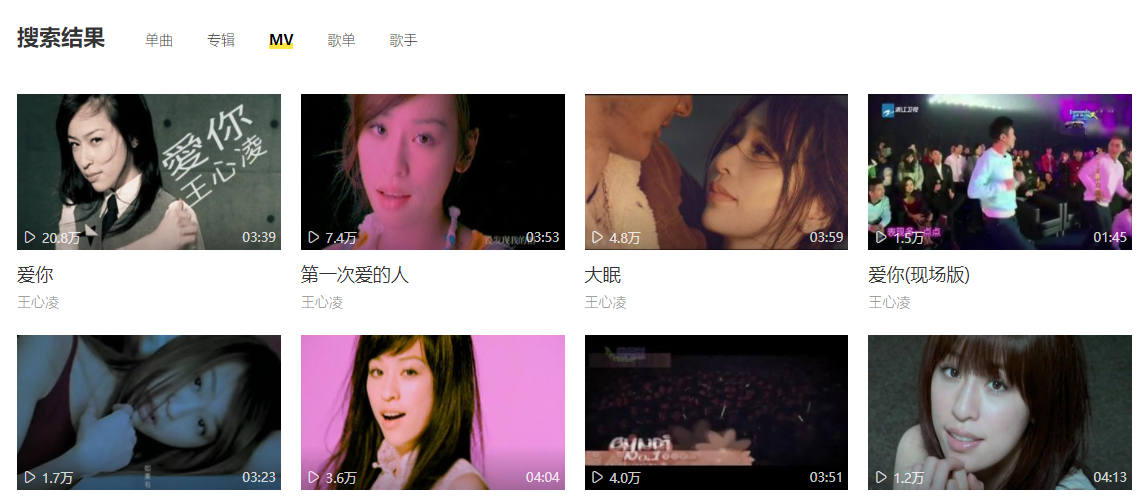
然后我们通过开发者工具进行抓包分析,分析我们想要的数据来自于哪里。
直接点击第一个,然后右键点击检查,或者直接按F12 打开开发者工具,然后点击network ,点击AII ,然后我们看到的是这样的页面。
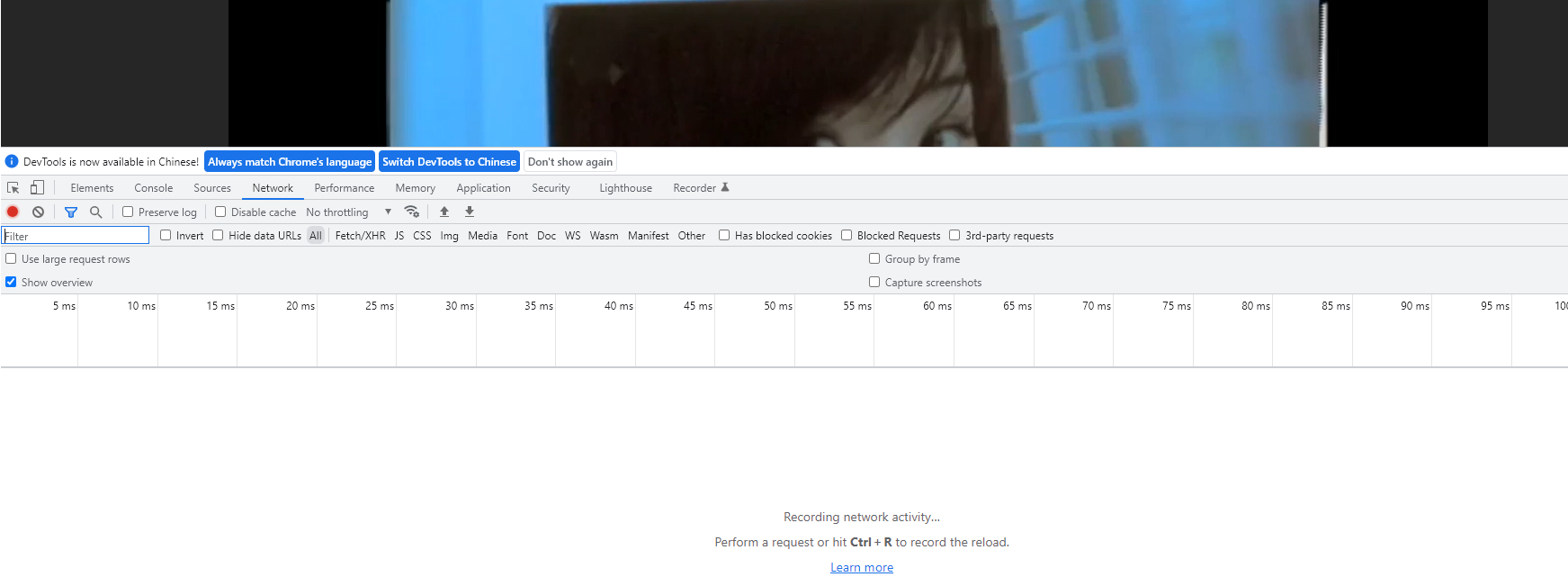
这个时候是没有数据的,所以我们需要刷新一下。
现在数据就出来了

每个视频都有自己的编号,我们可以在地址栏看到,这个视频的编号是89622
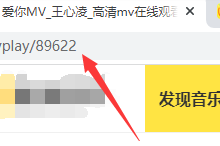
我们在开发者工具找到对应的目录,在network → AII 里第一个就是。
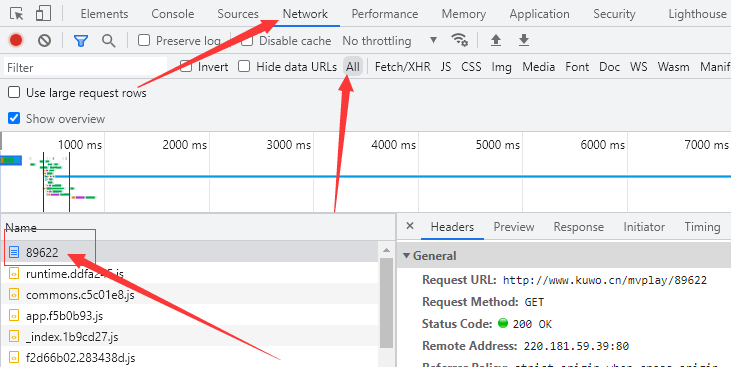
或者直接点左上角的搜索工具,或者直接 Ctrl+f 打开搜索框,输入序号进行搜索。

第一个就是,或者搜索对应的标题也可以找到相关数据。
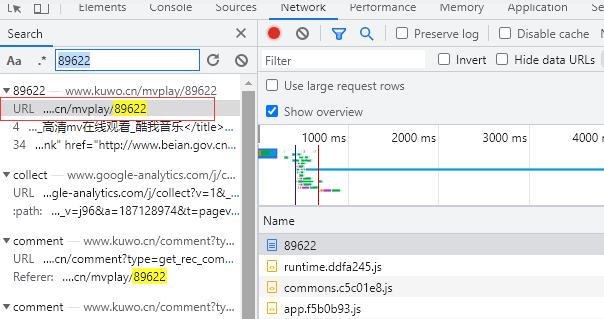
然后再这里找到我们需要的 Cookie 、Referer 、url 等等数据。
本文代码实现的基本四大步骤
1. 发送请求, 模拟浏览器对于url网址发送请求 <专门定义函数来发送请求>
2. 获取数据, 获取网页源代码
3. 解析数据, 提取我们想要数据内容 <视频信息以及视频标题>
4. 保存数据, 把视频内容保存本地
1、首先导入需要用的模块
import requests import re
requests 是第三方模块,需要手动安装一下。
键盘按住 win+r 输入 cmd 确定,弹出命令提示符窗口,输入 pip install requests 回车安装即可。
不会的可以看我置顶文章,有专门介绍,或者加文章底部直接联系我。
2、发送请求
模拟浏览器对于url网址发送请求 <专门定义函数来发送请求>
headers = { 'Cookie': '_ga=GA1.2.1259590012.1628168238; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1655356984; _gid=GA1.2.1126000694.1655356984; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1655357023; _gat=1; kw_token=XBR2CWDG9IP', 'Host': 'www.kuwo.cn', 'Referer': 'http://www.kuwo.cn/search/list?key=%E9%99%88%E5%A5%95%E8%BF%85', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36', } url = 'http://www.kuwo.cn/mvplay/89622' response = requests.get(url=url, headers=headers) # Python学习交流群 279199867
这些数据的话,都在开发者工具里面获取,还记得前面讲的步骤吗?
Cookie、Host 、Referer 、 User-Agent 这些数据找到后,直接复制下来,Referer是防盗链,没看到的话不用写。

url 在第一个

对应的标签需要加上引号,把复制下来的内容变成字典格式。
然后通过 response 对网站发送请求
print 打印一下

<Response [200]>: 请求成功
3、获取数据
html_data = response.text print(html_data) # Python学习交流群 279199867
打印一下看看获取到的数据
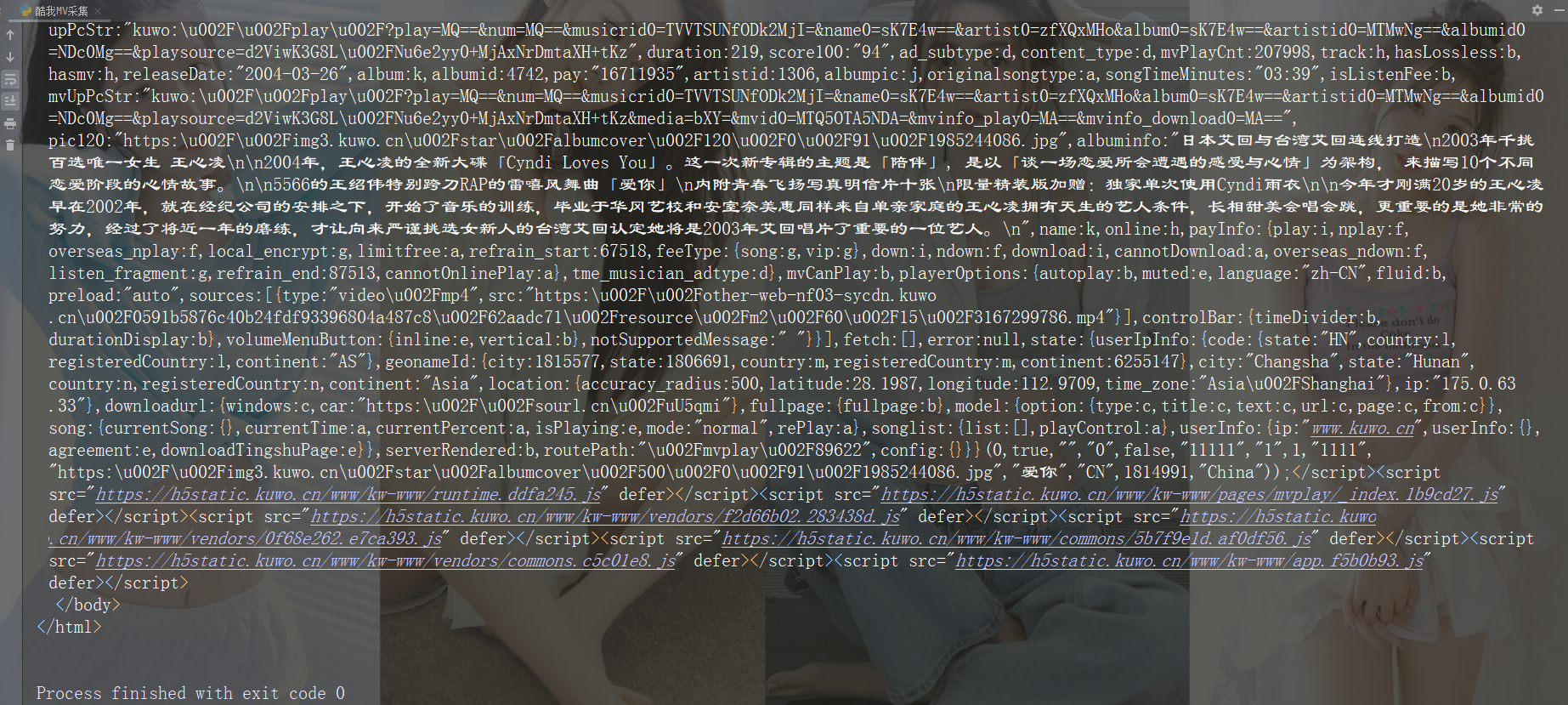
4、解析数据
.*?匹配任意字符 \n 换行除外
video_url = re.findall('src:"(.*?)"}]', html_data)[0] video_url = video_url.replace('\\u002F', '/') video_data = requests.get(url=video_url).content
5、保存数据
with open('爱你.mp4', mode='wb') as f: f.write(video_data)

就可以开始愉快的欣赏女神了!
这里我只是做了单个获取,多个爬取和多页爬取我专门录了视频,文中可以获取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号