毕业论文找文献是个问题,我直接用python把全网文献爬了一遍...
一、写在前面
马上要毕业了兄弟们,毕业论文是个麻烦事,论文要的资料得一条一条去网上查看,那多浪费时间,咱直接写个爬虫,批量下载慢慢看,不舒服?

使用软件
Python和pycharm就可以了,版本的话都行,只要你别用python2。
模块
requests #模拟请求 Selenium # 浏览器自动化操作
win+r打开搜索框,输入cmd按确定打开命令提示符窗口,输入pip install 加上你要安装的模块名, 回车即可安装,下载速度慢就换国内镜像源。
然后要下载一个谷歌浏览器驱动,版本跟你的浏览器最相近的那个就行。
不会的看我置顶文章。
页面分析
首先分析一下知网页面元素,我们一般是在首页输入框中输入你想搜的内容,然后跳转到搜索页面。

我们通过浏览器的检查页面,得到输入框和搜索图标的XPATH分别为:
input_xpath = '/html[1]/body[1]/div[1]/div[2]/div[1]/div[1]/input[1]' button_xpath = '/html[1]/body[1]/div[1]/div[2]/div[1]/div[1]/input[2]'
在输入框输入要搜索的内容,操作搜索按钮转到结果页。
以搜索Python为例,共找到15,925条,300页,每页中包含20个条目,每个条目包含题目、作者、来源等等内容。
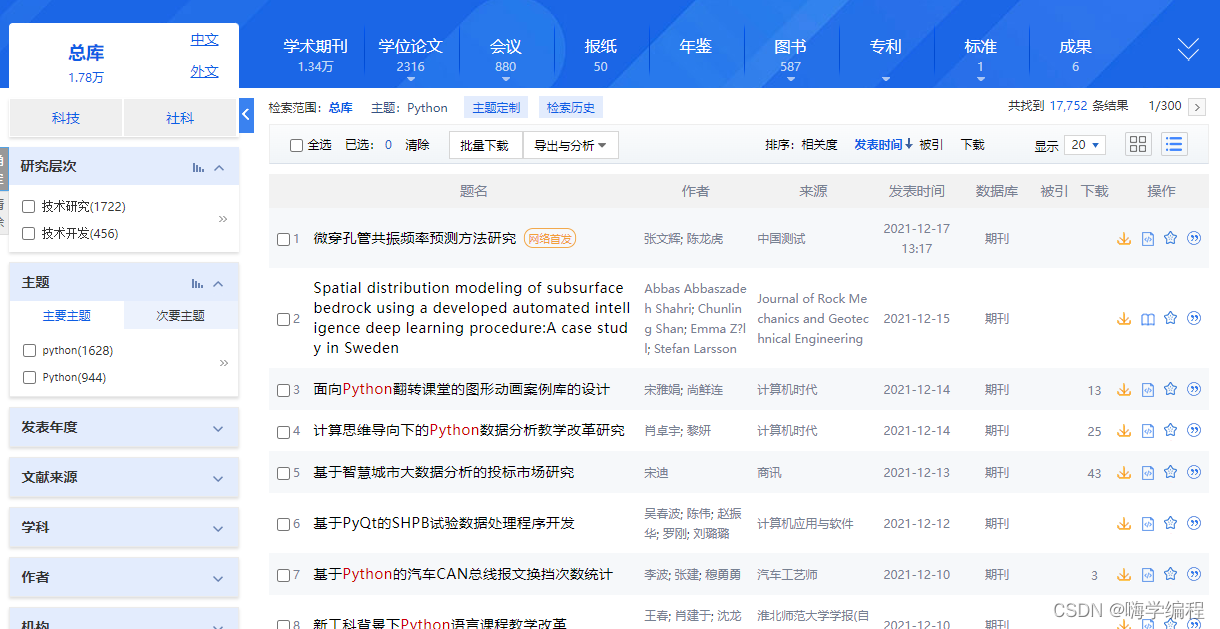
通过对当前页面分析发现每个条目对应的的xpath的规律
/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[1]/td[2]
就是倒数第二个标签数字代表本页的第几个条目,最后一个标签 2 - 6 分别代表题目、作者、来源、发表时间和数据库。在当前页面无法或者文献的摘要信息,下载链接,需要进一步点击进入相关文献条目。
进入详情页面后,根据class name:abstract-text 能够很容易定位到摘要的文本,class name: btn-dlcaj 定位到下载链接,其他元素也是一样的。

 完成面分析后就可以开始写代码了!
完成面分析后就可以开始写代码了!
导入要用的库
import time from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from urllib.parse import urljoin
创建浏览器对象,设置相关参数
get直接返回,不再等待界面加载完成
desired_capabilities = DesiredCapabilities.CHROME desired_capabilities["pageLoadStrategy"] = "none"
设置谷歌驱动器的环境
options = webdriver.ChromeOptions()
设置chrome不加载图片,提高速度。
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
设置不显示窗口
options.add_argument('--headless')
创建一个谷歌驱动器
driver = webdriver.Chrome(options=options)
设置搜索主题
theme = "Python"
设置所需篇数
papers_need = 100
打开页面搜索关键词
打开页面
driver.get("https://www.****.net")
网址我屏蔽了,各位自己换一下换成最大的那个查文献论文的网站。
传入关键字
WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,'''//*[@id="txt_SearchText"]''') ) ).send_keys(theme)
点击搜索
WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,"/html/body/div[1]/div[2]/div/div[1]/input[2]") ) ).click() time.sleep(3)
点击切换中文文献
WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,"/html/body/div[5]/div[1]/div/div/div/a[1]") ) ).click() time.sleep(1)
获取总文献数和页数
res_unm = WebDriverWait( driver, 100 ).until( EC.presence_of_element_located( (By.XPATH ,"/html/body/div[5]/div[2]/div[2]/div[2]/form/div/div[1]/div[1]/span[1]/em") ) ).text
去除千分位里的逗号
res_unm = int(res_unm.replace(",",'')) page_unm = int(res_unm/20) + 1 print(f"共找到 {res_unm} 条结果, {page_unm} 页。")
解析结果页
赋值序号,控制爬取的文章数量。
count = 1
当爬取数量小于需求时,循环网页页码。
while count <= papers_need:
等待加载完全,休眠3S。
在适当的地方加上 time.sleep(3) 延时几秒,既可以等待页面加载,也可以防止爬取太快被封IP。
time.sleep(3) title_list = WebDriverWait( driver, 10 ).until( EC.presence_of_all_elements_located( (By.CLASS_NAME ,"fz14") ) )
循环网页一页中的条目
for i in range(len(title_list)): try: term = count%20 # 本页的第几个条目 title_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[2]" author_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[3]" source_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[4]" date_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[5]" database_xpath = f"/html[1]/body[1]/div[5]/div[2]/div[2]/div[2]/form[1]/div[1]/table[1]/tbody[1]/tr[{term}]/td[6]" title = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,title_xpath) ) ).text authors = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,author_xpath) ) ).text source = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,source_xpath) ) ).text date = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,date_xpath) ) ).text database = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,database_xpath) ) ).text
点击条目
title_list[i].click()
获取driver的句柄
n = driver.window_handles
driver切换至最新生产的页面
driver.switch_to_window(n[-1])
开始获取页面信息
# title = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h1") ) ).text # authors = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h3[1]") ) ).text institute = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.XPATH ,"/html[1]/body[1]/div[2]/div[1]/div[3]/div[1]/div[1]/div[3]/div[1]/h3[2]") ) ).text abstract = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.CLASS_NAME ,"abstract-text") ) ).text try: keywords = WebDriverWait( driver, 10 ).until( EC.presence_of_element_located((By.CLASS_NAME ,"keywords") ) ).text[:-1] except: keywords = '无' url = driver.current_url
获取下载链接
link = WebDriverWait( driver, 10 ).until( EC.presence_of_all_elements_located((By.CLASS_NAME ,"btn-dlcaj") ) )[0].get_attribute('href') link = urljoin(driver.current_url, link)
写入文件
res = f"{count}\t{title}\t{authors}\t{institute}\t{date}\t{source}\t{database}\t{keywords}\t{abstract}\t{url}".replace("\n","")+"\n" print(res) with open('CNKI_res.tsv', 'a', encoding='gbk') as f: f.write(res)
跳过本条,接着下一个。如果有多个窗口,关闭第二个窗口, 切换回主页。
except: print(f" 第{count} 条爬取失败\n") continue finally: n2 = driver.window_handles if len(n2) > 1: driver.close() driver.switch_to_window(n2[0])
计数,判断需求是否足够。
count += 1 if count == papers_need:break
切换到下一页
WebDriverWait( driver, 10 ).until( EC.presence_of_element_located( (By.XPATH ,"//a[@id='PageNext']") ) ).click()
关闭浏览器
driver.close()
# 到这里所有的功能都实现了,我还给大家准备了这些资料,直接在群里就可以免费领取了。 # 一群:872937351 (群满了的话加二群) # 二群:924040232 # python学习路线汇总 # 精品Python学习书籍100本 # Python入门视频合集 # Python实战案例 # Python面试题 # Python相关软件工具/pycharm永久激活
兄弟们,记得随手三连,你的助力是我更新的动力~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号