双十一福利!爬取电商平台商品详情!买东西我们只买优质产品!
嗨 ,兄弟们晚上好啊!
下午爬完京东,我们晚上再试试淘宝,剁手之路永不停歇!
其实我不太想爬的,没办法被媳妇知道了,说要在淘宝买东西,自己懒得看,让我用代码去分析分析。
害,有这时间打两把无限火力他不香吗!

反正都爬完了,整理出来发给大家参考一下吧。
环境介绍:
- python 3.6
- pycharm
- selenium
- csv
- time
- random
python解释器安装包、安装教程
pycharm代码编辑器安装包、安装教程、激活码
Chrome浏览器Webdriver插件安装教程
xpath-helper插件安装教程
这些如果没有的话,可以在文末获取。
第三方模块
selenium python模块 操作浏览器驱动 pip install selenium
这里简单的说下chromedriver (谷歌驱动)
浏览器驱动用来自动翻页的,下载跟你安装的谷歌浏览器版本最相近的版本,放到你的Python安装目录,或者跟你的代码放在同一个文件夹中就好了。
这个是我的浏览器版本
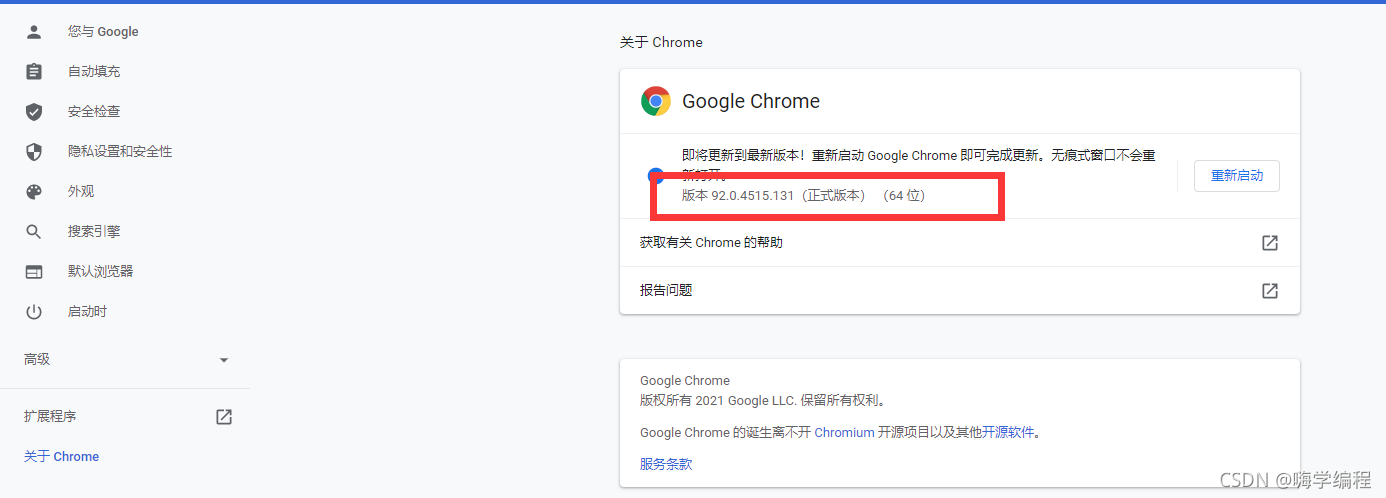 这是跟我对应版本的驱动插件
这是跟我对应版本的驱动插件
 下载好解压出来长这样子,我这里把它跟代码放一起了。
下载好解压出来长这样子,我这里把它跟代码放一起了。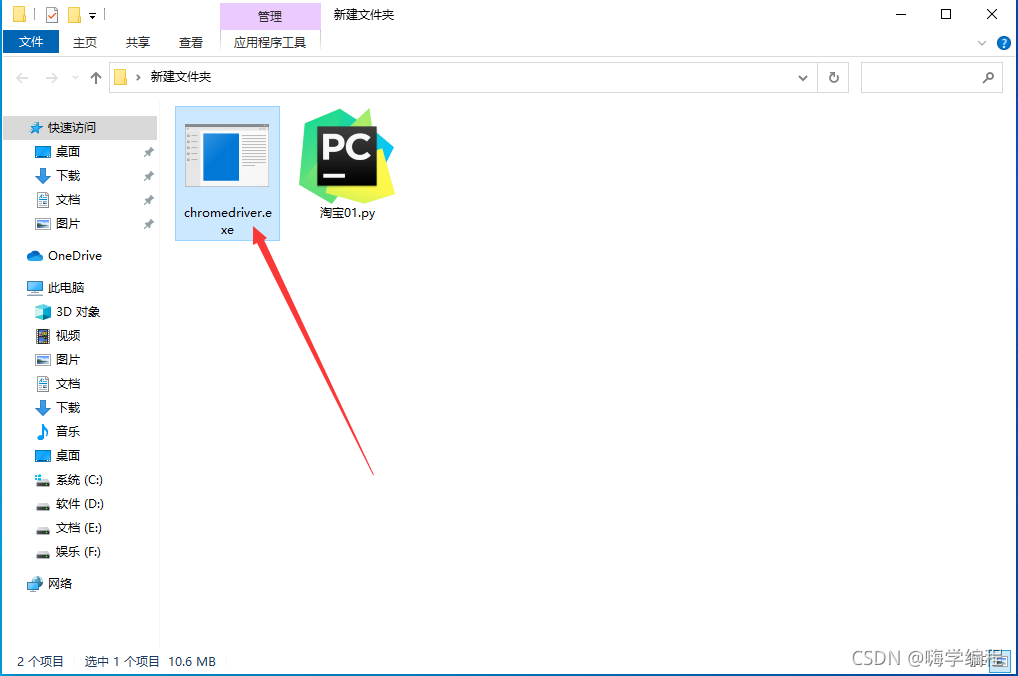 其他几个的话就不多说了
其他几个的话就不多说了
导入模块
先导入一下要用的模块,注释够详细了吧。
from selenium import webdriver # 导入selenium模块的浏览器功能 import random # 随机数据模块 设置随机等待 import time # 时间模块, 这是等待的时间<随机> 内置模块, 安装解释器的时候自带的 from constants import TAO_USERNAME, TAO_PASSWORD # 导入用户信息 import csv # 数据保存 # 内置模块
解决登录
我们要根据关键字搜索商品, 解决登录,避免淘宝检测selenium, 尽量的模拟用户操作去解决登录,淘宝登录它是有js 加密的, js会检测selenium自动登录, 最好是学学JS解密。
def search_product(keyword): driver.find_element_by_xpath('//*[@id="q"]').send_keys(keyword) time.sleep(random.randint(1, 3)) driver.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click() time.sleep(random.randint(1, 3)) driver.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(TAO_USERNAME) time.sleep(random.randint(1, 3)) driver.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(TAO_PASSWORD) time.sleep(random.randint(1, 3)) driver.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click() time.sleep(random.randint(1, 3))
解析数据
这里我们要对多个商品数据解析,所有的div标签,然后进行二次提取商品价格、付款人数、店铺名称、店铺地址、详情页地址
ef parse_data(): # 多个商品数据解析 divs = driver.find_elements_by_xpath('//div[@class="grid g-clearfix"]/div/div') # 所有的div标签 for div in divs: # 二次提取 try: info = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text price = div.find_element_by_xpath('.//strong').text + '元' # 商品价格 # 手写 deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text # 付款人数 # 手写 name = div.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text # 店铺名称 # 手写 location = div.find_element_by_xpath('.//div[@class="location"]').text # 店铺地址 # 手写 detail_url = div.find_element_by_xpath('.//div[@class="pic"]/a').get_attribute('href') # 详情页地址 # 手写 print(info, price, deal, name, location, detail_url, sep='|') with open('淘宝.csv', mode='a', encoding='utf-8', newline='') as f: csv_write = csv.writer(f) csv_write.writerow([info, price, deal, name, location, detail_url]) except: continue
实现根据关键字搜索商品
word = input('请输入你要搜索商品的关键字:')
浏览器操作
创建一个浏览器
driver = webdriver.Chrome()
修改浏览器的属性
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})
执行浏览器操作
driver.get('https://www.taobao.com/')
get 是driver一个方法, 内部传一个地址,driver.get() 不是函数, 是driver对象的一个方法, 方法的调用和自定义函数调用是有区别的。
智能化等待: 页面渲染加载过程需要时间
driver.implicitly_wait(10)
最大化浏览器
driver.maximize_window()
搜索商品和解析商品
search_product(word) for page in range(0, 100): # 0123456... print(f'\n========================正在抓取第{page + 1}页数据=========================') driver.get(f'https://s.taobao.com/search?q={word}&s={page * 44}') parse_data() time.sleep(random.randint(2, 4))
我们在执行浏览器的自动化操作的时候,用户平常怎么操作页面, 那么咱们代码逻辑和用户操作的页面的逻辑大致一样。
验证码主要是验证人机行为,一般是滑动, 点选, 普通验证码。
完整的免费源码领取处:
兄弟萌,我最大的动力就是来自你们的支持!!看完记得点赞收藏三连哈!
关于解答——
兄弟们在Python学习中遇到问题、有时间会给大家解答的!大家自行添加哈~

.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号