Python爬虫代码:双十一到了,爬一下某东看看有没有好东西,这不得买一波大的!
现在电商平台有很多商品数据,采集到的数据对电商价格战很有优势,这不,双十一预售都已经开启了,不得对自己好一点,把购物车塞到满满当当。

所以今天咱们以京东为例,试一试效果叭~
知识点:
- selenium工具的使用
- 结构化的数据解析
- csv数据保存
环境:
- python 3.8
- pycharm
- selenium
- csv
- time
selenium用来实现浏览器自动化操作,我们想实现浏览器自动操作还需要下载一个chromedriver工具,没有软件或者不会安装、没有激活码等等,都在文末统一给出来。

好了,开始我们的正文吧。
需要用的模块先导入进去,这一步写给新手。
import csv # 数据保存模块, 内置模块 import time from selenium import webdriver
既然我们要爬商品,当然就要实现搜索商品吧。
def get_product(key): """搜索商品""" driver.find_element_by_css_selector('#key').send_keys(key) driver.find_element_by_css_selector('#search > div > div.form > button').click()
然后把搜索功能写出来
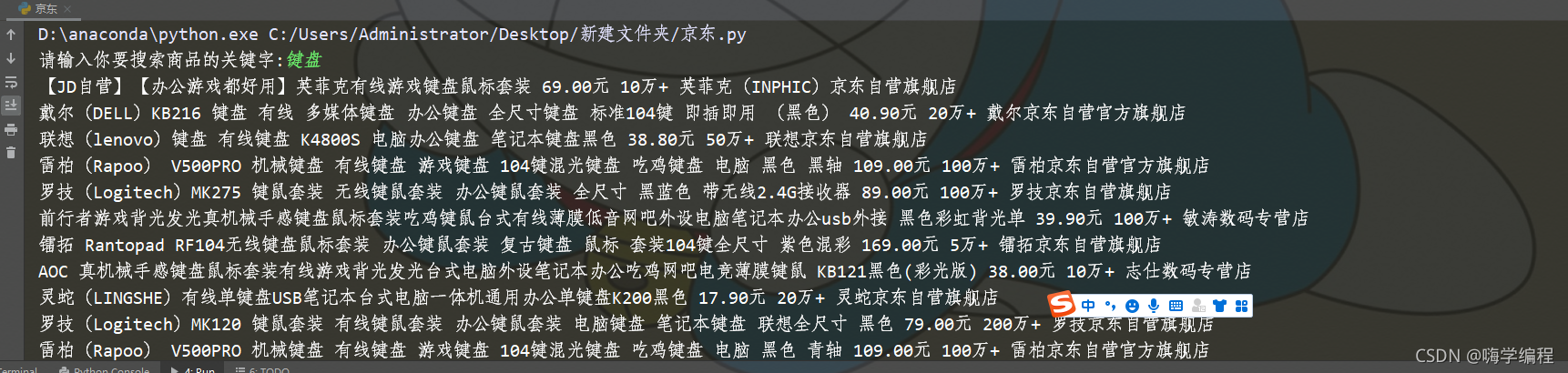
keyword = input('请输入你要搜索商品的关键字:')
运行之后的搜索效果
 数据懒加载? 你如果没有下拉页面, 那么页面下半部分数据是不会给你显示的。
数据懒加载? 你如果没有下拉页面, 那么页面下半部分数据是不会给你显示的。
所以我们要执行页面的下拉操作
创建一个浏览器 对象
driver = webdriver.Chrome()
执行浏览器自动化
driver.get('https://www.jd.com/') driver.implicitly_wait(10) # 设置浏览器的隐式等待, 智能化等待<不会死等> driver.maximize_window() # 最大化浏览器
调用搜索商品的函数
get_product(keyword) def drop_down(): """执行页面的下拉操作""" for x in range(1, 11, 2): # 控制下拉次数 代码是活的, j = x / 10 # 1/10 3/10 ... 10/10 # js JavaScript 是可以直接运行在浏览器的一门计算机语言 通过js下拉页面 js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j driver.execute_script(js) time.sleep(0.5) # 休息的时间是让浏览器加载数据的
然后我们要做的是解析商品数据并保存到Excel表格去,商品的标签、名字、价格、评论、店铺名字等等,当然只要你能看到的数据都可以爬下来。
def parse_data(): """解析商品数据, 并且保存数据""" lis = driver.find_elements_by_css_selector('.gl-item') # 解析到了所有的li标签 for li in lis: try: name = li.find_element_by_css_selector('div.p-name a em').text # 商品的名字 price = li.find_element_by_css_selector('div.p-price strong i').text + '元' # 商品的价格 deal = li.find_element_by_css_selector('div.p-commit strong a').text # 商品的评价数量 title = li.find_element_by_css_selector('span.J_im_icon a').get_attribute('title') # 商品的店铺名字 name = name.replace('京东超市', '').replace('\n', '') print(name, price, deal, title) # 数据的保存 with open('京东.csv', mode='a', encoding='utf-8', newline='') as f: csv_write = csv.writer(f) csv_write.writerow([name, price, deal, title]) except: continue
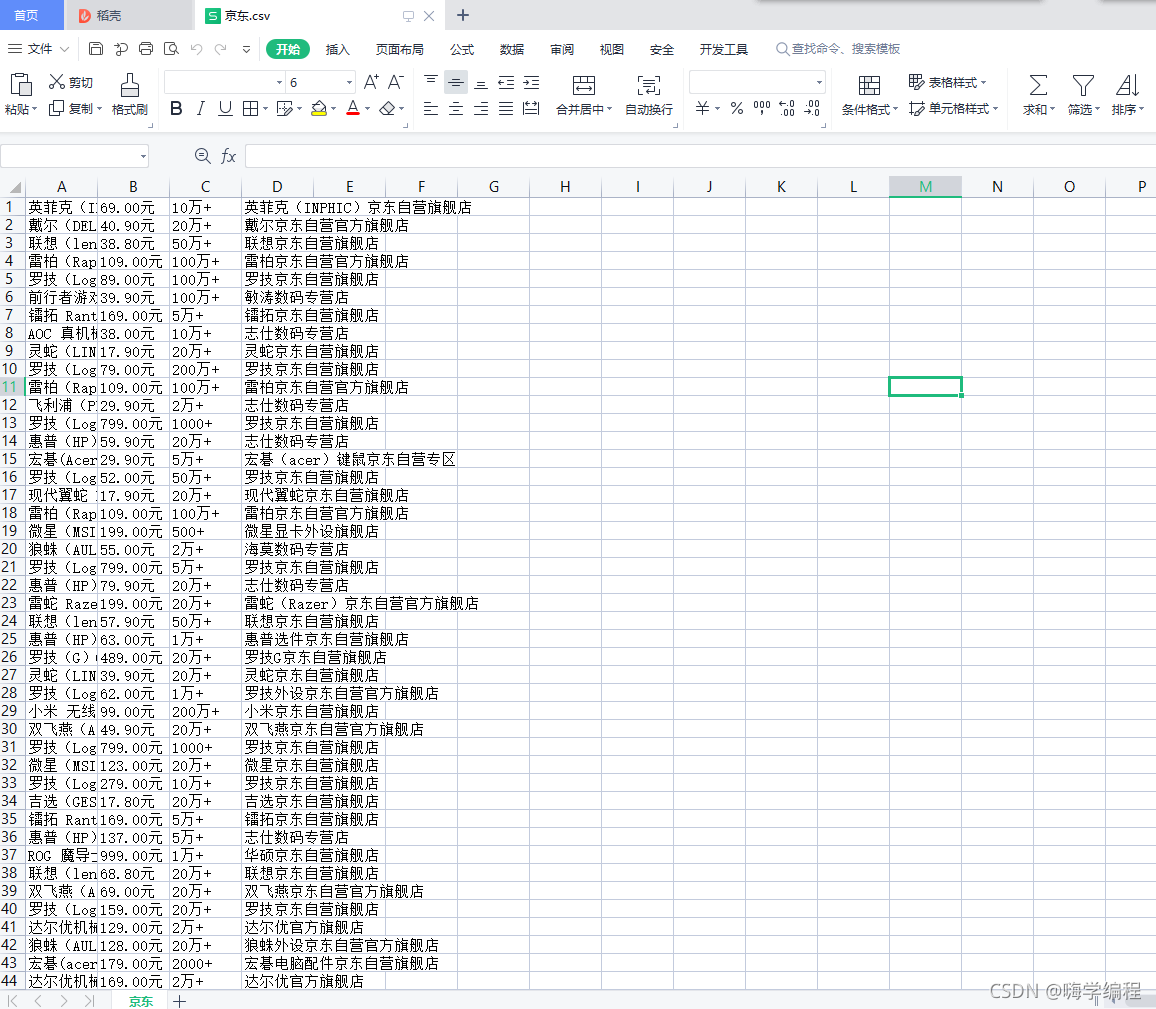
这是获取到的数据自动保存为Excel
但是当前只爬了一页,我们要实现更多的数据爬取,写一个翻页就好了。
def get_next(): """翻页""" driver.find_element_by_css_selector('#J_bottomPage > span.p-num > a.pn-next > em').click()
翻页下的逻辑需要循环执行
for page in range(100): # 调用页面下拉函数 drop_down() # 调用数据解析函数 parse_data() # 调用翻页的函数 get_next()
写在最后
好了,今天就写到这里,大家可以自己尝试,有跟本文对应的视频教程,可以一步步学习,包括本文源码也可以获取。
兄弟们的支持就是对我最大的动力,点赞三连督促我加班熬夜更新吧!
如果在学习Python遇到了问题,有空的时候都可以给大家解答。
欢迎大家阅读往期文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号